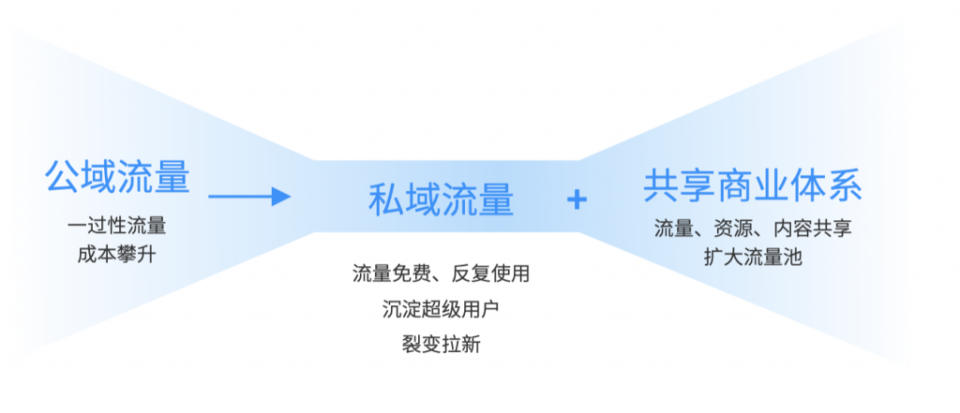
大模型产业仿佛如同一场盛宴,虽然AGI的菜肴还没有上桌,但掩盖不住的香味已经让所有人垂涎,都希望自己将来在餐桌上能够“吃饱饱”。这也是一场没有邀请函的宴席,从尚在学校的学生到公司的决策层,都能在生成式AI的相关研究、实践、应用中扮演重要的角色。
同样的,正如同一场晚宴会有前菜、主菜、甜点一般,大模型的产业也有对应的上游、中游、下游的产业,所有人得找准自己在产业中的定位,发挥自己过往所积累的优势,毕竟餐桌前的位置并不够所有人坐。
由此,了解菜单,明确每道菜肴的分量、上菜时间和餐桌上的摆位,想必对于在座的各位老饕也是十分关键,为此,让我们一同来解析整个大模型产业链,从上游的基础算力设施,到中游的基础模型与数据产业,再到下游的应用与评测。

上游:基础算力资源与云服务
AI芯片,算力的Building Blocks
如果将计算资源比作电力,那基础算力设施如同电力设施,算力中心就如同发电厂。遗憾的是,大模型并不能自己“用爱推理”或者“用爱训练”,必须要有足够的算力资源来驱动。算力是大模型的核心驱动力,就像电力驱动了我们现在使用的手机或者电脑等设备。在这当中,AI 芯片(AI 加速卡)是算力的核心来源,是大模型进行训练和推理的关键组件,其每秒能处理多少万亿次的 INT8的整型运算或 FP32单精度浮点运算是衡量AI芯片算力的重要标准。
AI芯片卡是上游产业中的重要组成部分,在算力设施的构建中具有原子性,也是硬件厂商售卖的基础AI计算单元。基于AI芯片卡以及CPU、内存等其他组件,AI服务器也在市场中占有重要的地位。AI服务器中,大模型一体机以其集成化和高效性脱颖而出,在简化部署和运维方面具有显著优势,其即插即用特性使得即便是非专业人员也能轻松设置和维护。在这样的市场环境中,放眼全球,英伟达在算力资源这块吃到了大部分的市场份额,根据TIRIAS Research 首席分析师 Kevin Krewell 表示,英伟达以 80% 至 95% 的市场份额主导着全球的 AI 计算市场[1]。

但由于AI芯片相关禁令以及国产化进程的推进,国外芯片厂商,即使像诸如英伟达、AMD这样的巨头,也难以吃下国内的芯片市场。由此,中国的芯片市场滋养了众多中国本土的AI 芯片的新老厂商,如华为、海光、寒武纪、壁韧、燧原、昆仑芯等等。这些本土企业正快速发展,旨在填补市场的需求空缺,并挑战国际厂商在高端AI芯片领域的垄断地位。这些厂商不仅在追求性能提升和能效优化,而且在芯片的功能性、兼容性以及对特定应用的定制化方面做出努力。
智算中心
在搭建智算中心方面,这种市场多元化为中国的AI发展带来了新的机遇。智算中心,作为集算力、数据处理和智能分析于一体的重要基础设施,越来越多地依赖于这些本土AI芯片的创新和性能。随着中国AI芯片制造商的崛起,智算中心能够更好地适应本土市场需求,同时提高对全球供应链波动的抵抗力。这些本土智算中心的建设,不仅集成了国产AI芯片,还紧密结合了本土化的软件生态和定制化的AI解决方案。这样的组合不仅促进了智算中心的性能优化,还提高了对各行各业特定需求的适应性。例如,在智慧城市、智能制造和医疗健康等领域,智算中心可以提供更加精准和高效的服务。
中游:大模型与训练数据
AK47与原子弹共存的时代
如今,基础模型众多厂商还处于抢板凳的状态,既有“AK47”也有“原子弹”,既有开源、可靠、专业的小参数大模型,也有闭源、强大、泛用的大参数大模型,形成了多样化的大模型生态。其中我们可以看到小模型持续做小,如今已经出现了小于1 GB的大模型。与此同时,大模型是否会持续做大并不确定,540B的谷歌PaLM2可能仍然是近期参数量最大的模型。
在这样的背景下,我们看到了一些趋势的形成。以OpenAI为首的一些公司采取了先开源后闭源的商业模式,以此作为快速获取市场认可和社区反馈的手段,然后转向闭源以实现商业化。这种做法允许他们在早期发展阶段利用开源社区的力量,同时在商业化阶段保护自己的技术优势。同时,大模型展现出越来越明显的“网红属性”,其对流量的依赖性也日益显著。随着大模型的商业应用日益增加,用户流量和交互数据成为了支撑这些模型不断进步的关键。这种依赖流量的特性在一定程度上也推动了大模型向更多用户友好和广泛应用的方向发展。
千万羊驼,入我梦来
开源的模型当中,虽然很多模型都在评测中得到了超过LLaMA2的评分,但LLaMA(羊驼)系列模型仍然是众多开源模型的比较标准,对标的对象,表现出人们对LLaMA系列模型的信任程度,展现出LLaMA系列在行业的影响力。在LLaMA 1代的权重参数流出的时候,LLaMA模型就中国本土化诞生了许多不同类型的项目,例如 Chinese-LLaMA-Alpaca,Llama-Chinese,BELLE-LLaMA,openbuddy-llama,firefly(流萤),YaYi(雅意),YuLan-Chat(玉兰),Ziya(姜子牙)等等。很多的LLaMA的微调项目在当时都受到了人们的广泛关注,这些项目不仅在本地化语言处理方面做出了贡献,也在各自的特定领域中展现了创新性和实用性;

然而,许多LLaMA项目在发布之后缺乏更新与维护,尤其是在Meta官方发布了LLaMA2的模型权重之后,我们仍然看见有不少的LLaMA相关微调项目在GitHub上最后更新时间是在 5 - 6 months ago,对此只能很遗憾地说,有很多小羊驼没有坚持下来。这种情况可能是由多种因素造成的:一方面,资源限制、技术挑战或市场定位的问题可能使得一些初期项目难以持续更新,特别是对于那些个人或小型团队来说,有许多LLaMA系列的相关项目是个人或小型团队完成的。其次,AI领域的快速发展也意味着新模型和技术不断涌现,这可能导致一些项目的开发者转而关注更新的技术或模型。有许多团队在大模型产业中都会尝试挤进模型训练的圈子,但在经过不断的尝试之后,一些团队明确了自己在大模型产业链中的定位,选择转向产业链中的其他组成部分,通常是更加下游的位置。这反映了大模型领域的竞争激烈和不断变化的特性,同时也表明了在这个领域中找到适合自己的位置是关键。
转动数据飞轮
训练过程对大模型的最终表现非常重要,这就和人类对孩子的教育一样,双胞胎可能会因为后天的教育方式不同而变成两个截然不同的人。在训练过程中,训练所用的数据是关键的,而数据的质量更是关键中的关键。自相矛盾,内部逻辑无法自洽的数据难以训练出好的模型。由此,数据获取、数据治理与数据标注是中游产业链中重要的组成部分。
这几个部分大型公司通常会有专门的团队来负责,而小型公司通常可能会使用开源的数据集。从商业和产业的角度看,这种区别在数据的质量和定制化程度上造成了明显的分层。大型公司能够投入更多资源进行数据的收集、清洗、标注和管理,从而获得更高质量、更针对性的数据集,这直接影响到训练出的模型的质量和适用范围。此外,大型公司还能够根据特定的业务需求定制数据集,这使得他们在特定行业或应用中拥有竞争优势。大型公司有了好的数据能训练出好的模型,由此获得更多用户,收集到更多数据与受益,数据飞轮由此转动。而对于小型公司和初创企业来说,虽然开源数据集提供了一个成本较低的替代方案,但这些数据集可能在质量、相关性和定制化方面不如专门收集和处理的数据。因此,这些公司在使用开源数据时可能需要额外的工作来提升数据质量,或者寻找合适的方式来增强数据的适用性。
在整个大模型产业链中,数据获取、治理和标注成为了一个重要的细分市场。随着大模型技术的发展,对高质量数据的需求日益增长,促使数据服务成为一个增长迅速的行业。这也为专门从事数据服务的公司提供了发展机会,包括数据收集、处理、标注和管理等服务。除此之外,人们也在尝试使用生成式AI的方法自动完成训练数据的相关工作,包括数据集合成、数据集自动标注、数据集自动清洗等技术。先前Meta公司的Humpback座头鲸项目就是一种通过自增强(Self-Augment)、自管理(Self-Curation)、自微调(Self-Tune)的方式,使用AI自动生成指令来自动标记人类编写的文本。这种方法不仅提高了构建训练集的效率,也为训练更高质量的模型提供了可能。
图片来源:《Self-Alignment with Instruction Backtranslation》
下游:ToB与ToC应用
中美行业竞争
在上游的基础算力资源,以及中游的大模型与数据的前提,我们沿河而下,来到了大模型产业链的下游,其中主要是模型的各种应用。中国与美国在大模型行业的比赛中,大模型行业上的应用是中国的优势。
中国在大模型应用方面的优势主要体现在几个方面。首先,中国市场对于AI和大模型的应用有着庞大的需求和快速增长的用户基础,这为大模型应用提供了广阔的市场空间。中国企业在响应这些需求时展现出了强大的创新能力,推出了多种大模型应用,从智能客服、自然语言处理到个性化推荐系统等。其次,中国在数据收集和处理方面具有独特优势。由于市场规模庞大且用户多样,中国企业能够收集到大量多样化的数据,这些数据对于训练和优化大模型至关重要。此外,中国在数据治理方面也有着较为成熟的体系,这有助于提高数据质量,从而提升模型的性能。
相比之下,美国在大模型的研发和算力资源方面处于领先地位。美国的技术公司在算法研究、计算资源和模型创新方面拥有强大的实力,推动了大模型技术的快速发展。然而,在具体的应用落地方面,中国的快速市场响应和大规模的应用场景提供了强有力的竞争优势。

图片来源:ITIF,西部证券研发中心
Beyond 提示模板
大模型的潜力正在被人们挖掘。这种潜力远不止于文本生成和处理各种模态数据,更包括了模型的规划能力、记忆能力以及上下文学习能力。这些能力共同构成了如智能体、RAG(Retrieval-Augmented Generation)等多种高效的应用组合,我愿称之为“丝滑小连招”。
这些小连招的核心在于它们能够协同工作,为企业和用户带来更加智能和流畅的体验。例如,大模型在智能体中的应用不仅仅局限于响应查询,还能进行复杂的任务规划和决策支持。它们能够根据以往的交互和学习,不断优化对话策略和响应内容,提供更加精准和个性化的服务。
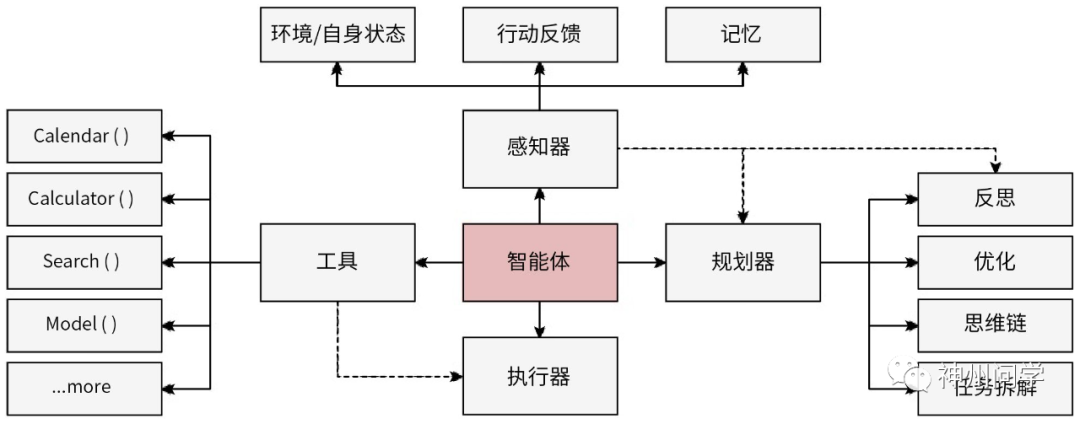
同样,RAG技术通过结合检索和生成能力,能够从海量数据中提取相关信息,并基于这些信息生成富有洞察力的内容。这种能力使得大模型能够回答本身知识范围之外的问题。此外,大模型的记忆能力也是一个关键因素。不同于传统模型的短时记忆,某些大模型能够长期保存和利用关键信息,这对于持续的学习和改进尤为重要。这意味着模型能够在长期互动中积累经验,为用户提供更加精准的建议和服务。
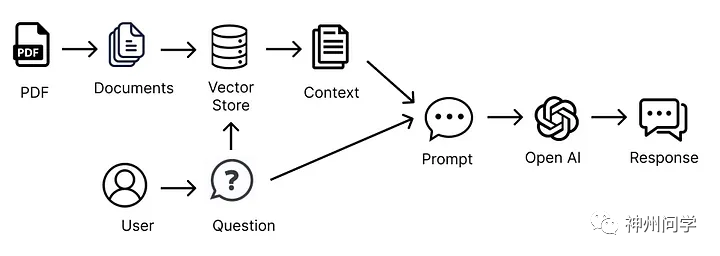
图片来源:Medium 博客
这些小连招展现出强大的应用潜力,这不仅推动了人工智能技术的发展,也为企业和用户创造了实实在在的价值。随着技术的不断进步和应用的深入,我们可以预见到一个更加智能和高效的未来。
稳扎稳打、步步为营的ToB应用产业
在大模型行业下游,To Business 方面的应用正在迅速发展,展现出多样化和深度应用的趋势。大模型技术已经开始在各种行业中发挥重要作用,从改善业务流程到提供新的服务和解决方案,大模型正成为企业创新的重要驱动力。目前应用广泛集中于五个方面:客户服务和支持、数据分析和洞察、自动化和效率优化、个性化营销和推荐以及风险管理和合规:
1. 客户服务和支持
大模型被广泛应用于客户服务和支持领域,尤其是在自动化和智能化客服系统中。通过使用大模型处理自然语言,企业能够提供更快速、更准确的客户响应,同时减少人力成本。智能聊天机器人和虚拟助理能够处理常见问题,提供定制化建议,甚至在复杂场景中进行交互,从而提高客户满意度和忠诚度。
2. 数据分析和洞察
大模型也在数据分析和商业智能中发挥着重要作用。大模型的代码能力能够让其进行基础的数据分析,从而敏捷地获得商业洞察和预测。这些洞察帮助企业做出更明智的决策,识别市场趋势,优化运营,甚至预测客户行为。
3. 自动化和效率优化
在运营自动化方面,大模型正在帮助企业优化工作流程。从自动化文档处理到优化供应链管理,大模型通过减少手动工作和提高流程效率,帮助企业节省时间和成本。在应对复杂场景时,智能体(Agent)技术的应用尤为关键。这些智能体能够自动化地编排和执行复杂的工作流程,提高决策的速度和准确性,从而在企业运营中发挥着至关重要的作用。
4. 个性化营销和推荐
大模型技术在营销和推荐系统中的应用也日益增加。通过分析消费者数据和行为模式,大模型能够为每个客户提供个性化的产品推荐和营销内容。这不仅增加了销售机会,也提高了客户的购物体验。
5. 风险管理和合规
在金融、法律和医疗等高度规范化的行业,大模型正在被用来提高风险管理和合规的效率。通过精确分析复杂的数据集,大模型可以帮助识别潜在风险,提供合规建议,甚至预测未来的法律和监管趋势。
大模型在ToB领域的应用正在快速发展,从文本、图像、音频、视频、代码等诸多方面为各行各业提供了更智能、更高效的解决方案。随着技术的不断进步和企业对大模型应用的深入理解,预计这些应用将会更加广泛和深入,为企业创造更多价值。
五彩斑斓,危机四伏的ToC应用产业
在大模型产业链的下游,面向消费者(ToC)的应用产业正呈现出一种五彩斑斓却危机四伏的局面。这个领域多样且充满创意,但同时竞争激烈,企业间的对抗常常无情且残酷。

ToC应用产业由于其直接面向最终用户的特性,催生了大量创新和多样化的产品。这些产品涵盖了从智能个人助理、个性化推荐系统到互动娱乐和教育应用等多个领域。利用大模型的强大处理能力,这些应用能够提供高度定制化和互动性的体验,满足消费者的个性化需求。例如,基于用户的浏览习惯和购物历史,个性化推荐系统能够推送符合用户口味的商品或内容。除此之外,创意也是吸引用户的关键。开发者利用大模型的能力,设计出独特的应用,如通过语音互动创作故事的工具,或者是能够根据用户情绪播放音乐的智能应用。这种创意的爆发不仅丰富了市场,也为用户带来了前所未有的体验。
然而,ToC应用市场的竞争异常激烈。由于进入门槛相对较低,市场上涌现了大量的参与者,包括初创公司和大型企业。在这个充满竞争的环境中,即使是最具创意和技术优势的应用也可能面临失败的风险。市场需求的快速变化、用户喜好的不断演进以及竞争对手的创新都可能迅速改变游戏规则。在这个多变的市场中,ToC应用的生命周期通常较短。一些应用虽然一经推出就风靡一时,但很快就会被新的、更吸引人的产品所取代。此外,由于市场的不确定性和竞争压力,一些应用可能会在没有获得足够回报之前就结束生命周期。
大模型下游的ToC应用产业呈现出一幅多彩且充满活力的画面,但背后却隐藏着激烈的竞争和不可预测的风险。对于企业和开发者而言,如何在这个竞争激烈的市场中脱颖而出,同时管理好风险,是他们面临的一大挑战。然而,正是这种挑战和竞争,推动了技术的不断进步和应用的创新,为消费者带来了越来越丰富和有趣的产品选择。
图片来源:《中国AIGC产业全景报告》
评测榜单
除了大模型的产品之外,对模型的能力进行评测也是产业中重要的一环,模型需要有说服力的榜单来证明其优秀的能力。评测榜单是展示和比较不同大模型性能的主要工具。一个有说服力的榜单不仅反映了模型在特定任务上的表现,还能展示模型的综合实力。在商业环境中,一个优秀的排名可以显著提升模型的市场认可度和吸引力。
国内的评测榜单,如SuperCLUE、智源的FlagEval和OpenCompass,展现出了评测数据的多样性。尽管某些数据集如C-Eval、CMMLU和MMLU在这些榜单中有所交集,但每个榜单都有其独特的数据集特点。这种多样性意味着不同的榜单可能对模型的不同方面进行更深入的评估。例如,某个榜单可能侧重于模型的语言理解能力,而另一个则可能更注重模型在特定领域,如医疗或法律的应用效果。评测榜单的多样性对于大模型产业具有深远的影响,鼓励开发者优化模型以适应不同的评测标准和应用场景,从而推动技术的综合发展。此外,多样化的评测榜单也为企业提供了展示其技术实力的机会,有助于在竞争激烈的市场中脱颖而出。
写在最后
大模型产业就如一场暂未开始的盛宴,虽然AGI尚未完全成熟,但已经展现出令人振奋的前景。大模型产业链涵盖了上游的基础算力资源、中游的模型与数据,以及下游的应用和评测,每个环节都至关重要。大模型产业链呈现出蓬勃的生命力和无限的潜力,各个环节紧密相连,共同推动着整个行业的前行。
引用
[1] TIRIAS Research: https://www.reuters.com/technology/amd-likely-offer-details-ai-chip-challenge-nvidia-2023-06-13/
* 本文部分插图使用 AI 生成