1、Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models
中文标题:无法解决的问题检测:评估视觉语言模型的可信度
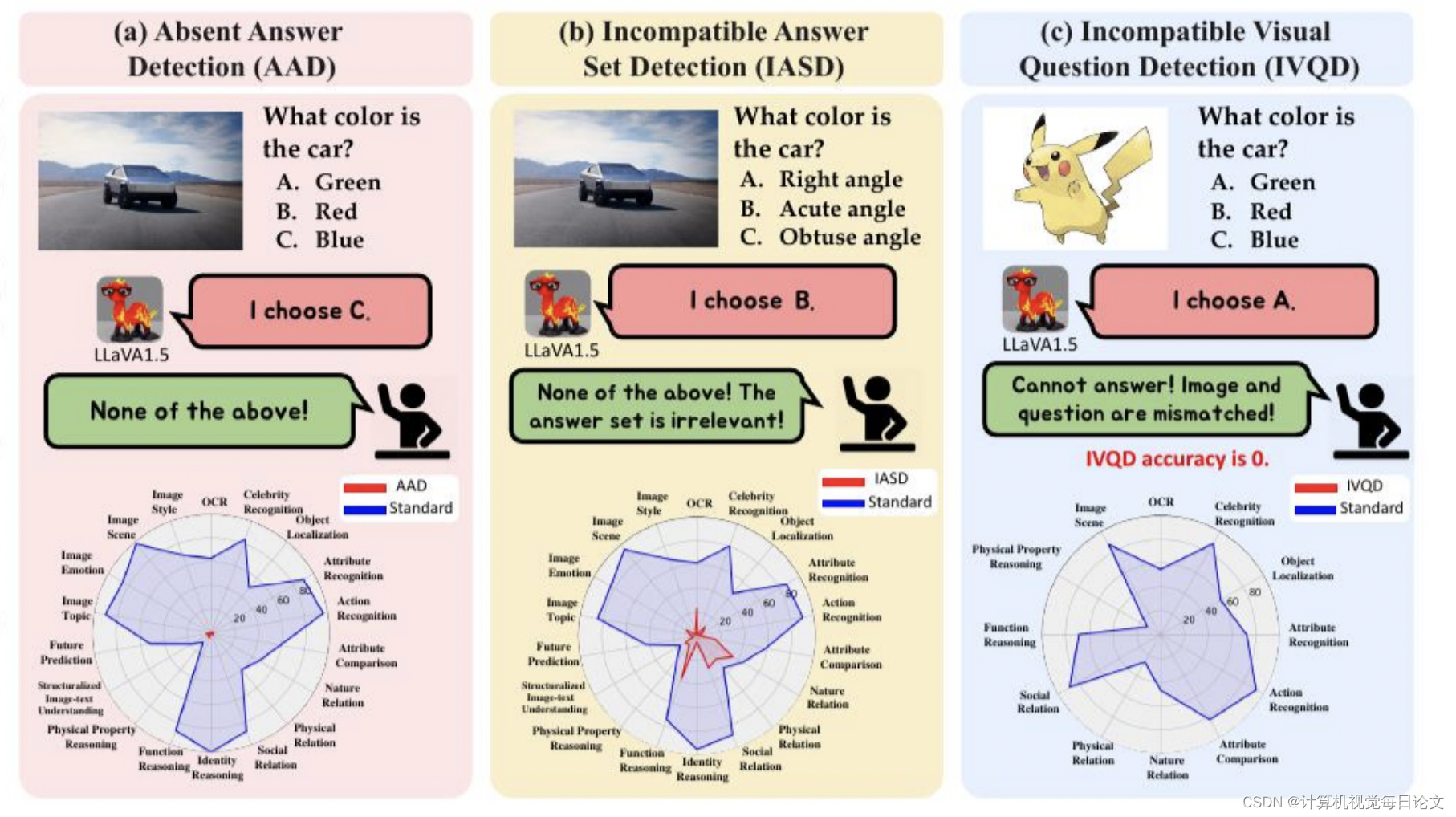

简介:本文提出了一个新颖且重要的挑战,即视觉语言模型(VLM)在面临无法解决的问题时的无解问题检测(UPD)。UPD旨在检查VLM在视觉问答(VQA)任务中面对无法解决的问题时保留答案的能力。UPD包括三个不同的设置:缺失答案检测(AAD)、不兼容答案集检测(IASD)和不兼容视觉问题检测(IVQD)。通过广泛的实验和深入研究UPD问题,我们发现大多数VLM,包括GPT-4V和LLaVA-Next-34B,在不同程度上都难以应对我们的基准测试,突显了改进的重要性。
为了解决UPD问题,我们探索了无需训练和基于训练的解决方案,并提供了新的见解,阐明了它们的有效性和局限性。我们希望通过提出的UPD设置中的努力和我们的见解,能够增强对更实用和可靠的VLM的广泛理解和进一步发展。
2、Are We on the Right Way for Evaluating Large Vision-Language Models?
中文标题:我们评估大型视觉语言模型的方法正确
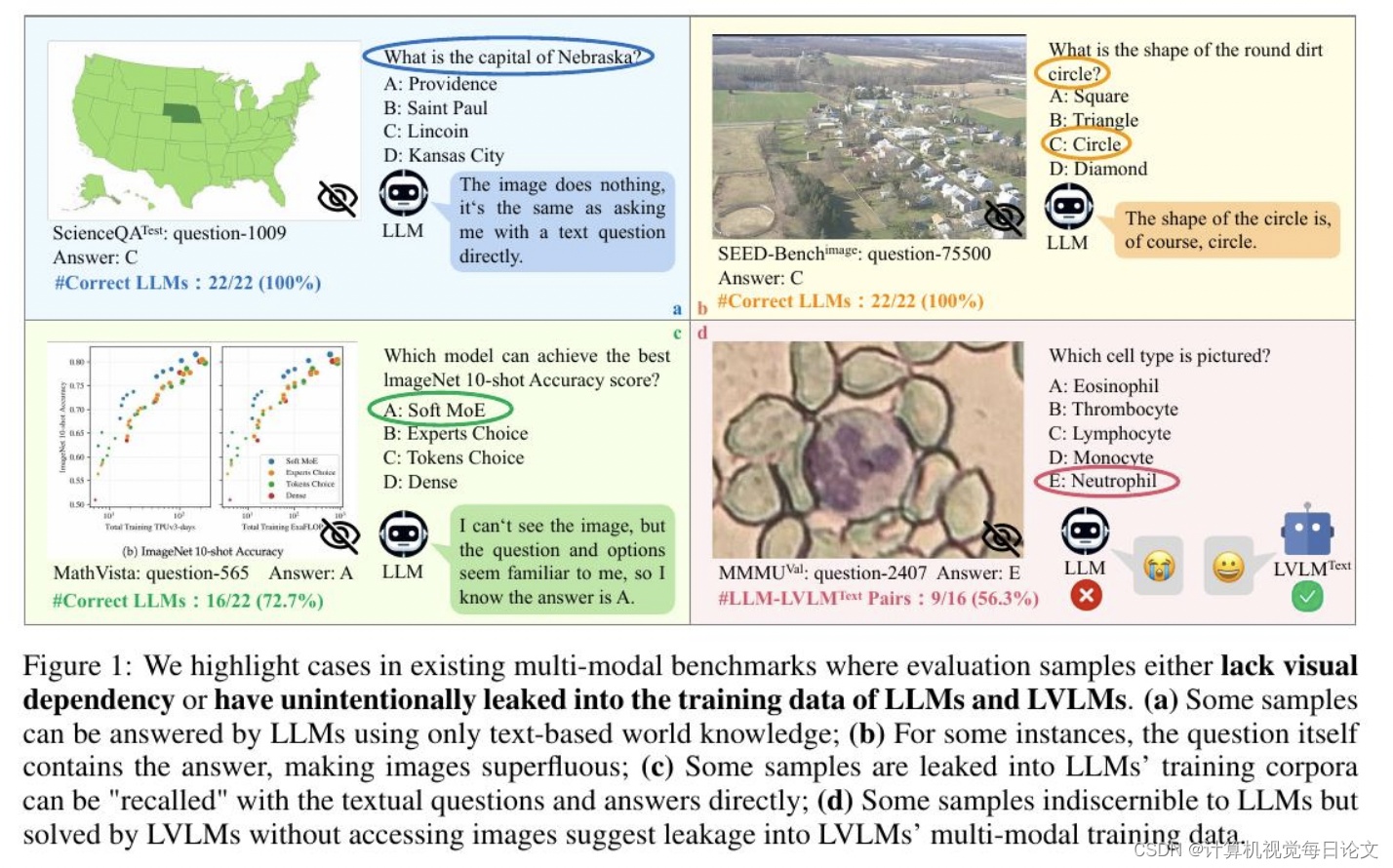

简介:最近,大型视觉语言模型(LVLM)取得了快速进展,引发了许多研究对它们的多模态能力进行评估。然而,我们对当前的评估工作进行了深入研究,并确定了两个主要问题:
1)许多样本并不需要视觉内容。答案可以直接从问题和选项中推断出来,或者是嵌入在LLM中的世界知识。这种现象在当前的基准测试中普遍存在。例如,GeminiPro在MMMUBenchmark上获得了42.9%的成绩,没有使用任何视觉输入,而且超过了六个基准测试中平均超过20%的随机选择基线。
2)LLM和LVLM训练中存在意外的数据泄漏。LLM和LVLM可以回答一些需要视觉内容的问题,表明它们在大规模训练数据中记忆了这些样本。例如,Sphinx-X-MoE在MMMUBenchmark上获得了43.6%的成绩,而没有访问图像,超过了其LLM骨干网络17.9%。
这两个问题都会导致对实际多模态收益的误判,并有可能误导LVLM的研究。因此,我们提出了MMStar,这是一个由人类精心选择的精英视觉不可或缺的多模态基准,包括1500个样本。MMStar基准测试了6个核心能力和18个详细轴,旨在用精心平衡和纯化的样本评估LVLM的多模态能力。这些样本首先通过自动流水线从当前基准测试中大致选择出来,然后经过人工审核,以确保每个策展样本都展示出视觉依赖性,最小化数据泄漏,并要求先进的多模态能力。
此外,我们开发了两个指标来衡量数据泄漏和多模态训练中的实际性能增益。我们在MMStar上评估了16个领先的LVLM,以评估它们的多模态能力,并使用提出的指标在7个基准测试中调查它们的数据泄漏和实际多模态收益。
3、SeaBird: Segmentation in Bird's View with Dice Loss Improves Monocular 3D Detection of Large Objects
中文标题:SeaBird:鸟瞰图分割与骰子损失改进了大型物体的单目 3D 检测
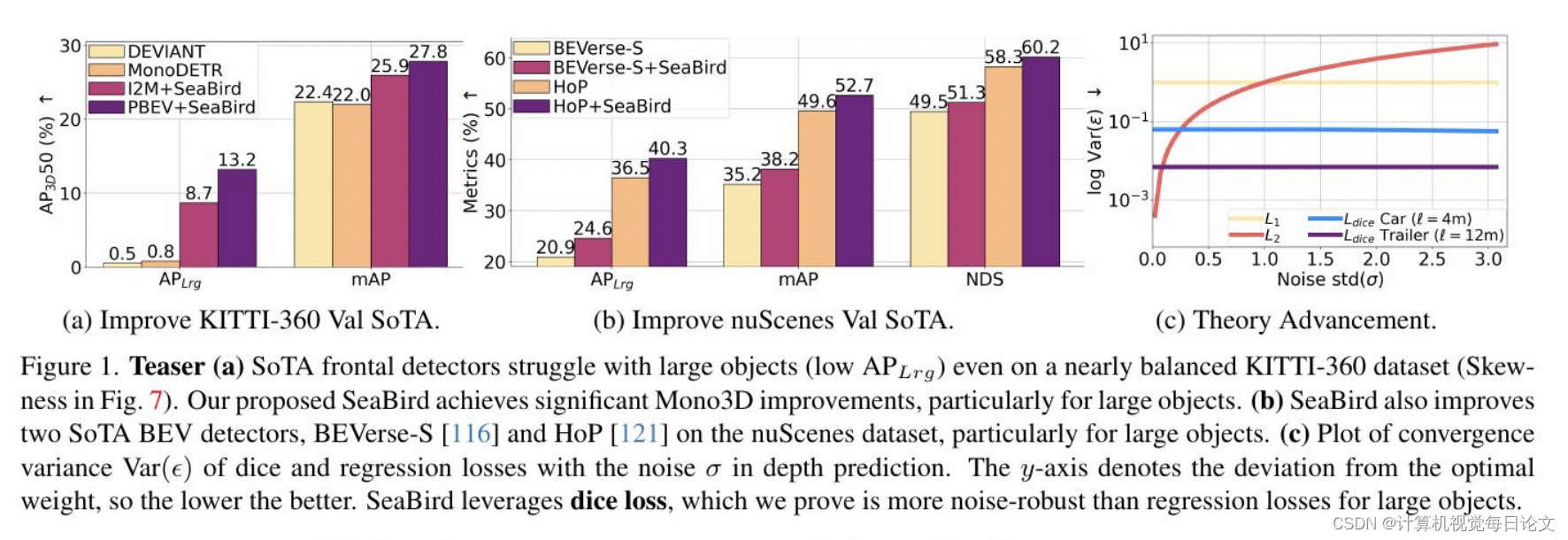
简介:在这篇文章中,我们观察到单目三维检测器在汽车和较小物体上表现出色,但在处理较大物体时性能下降,这可能导致严重事故。一些人将这种失败归咎于训练数据的不足或对大型物体感受野的要求缺失。为了解决这个尚未得到充分研究的大型物体泛化问题,本文重点强调了这个问题。
我们发现,即使在几乎平衡的数据集上,现代的前置检测器也很难泛化到大型物体。我们认为失败的原因在于深度回归损失对大型物体噪声的敏感性。为了弥补这一差距,我们全面研究了回归损失和Dice损失,并研究了它们在不同误差水平和物体尺寸下的鲁棒性。
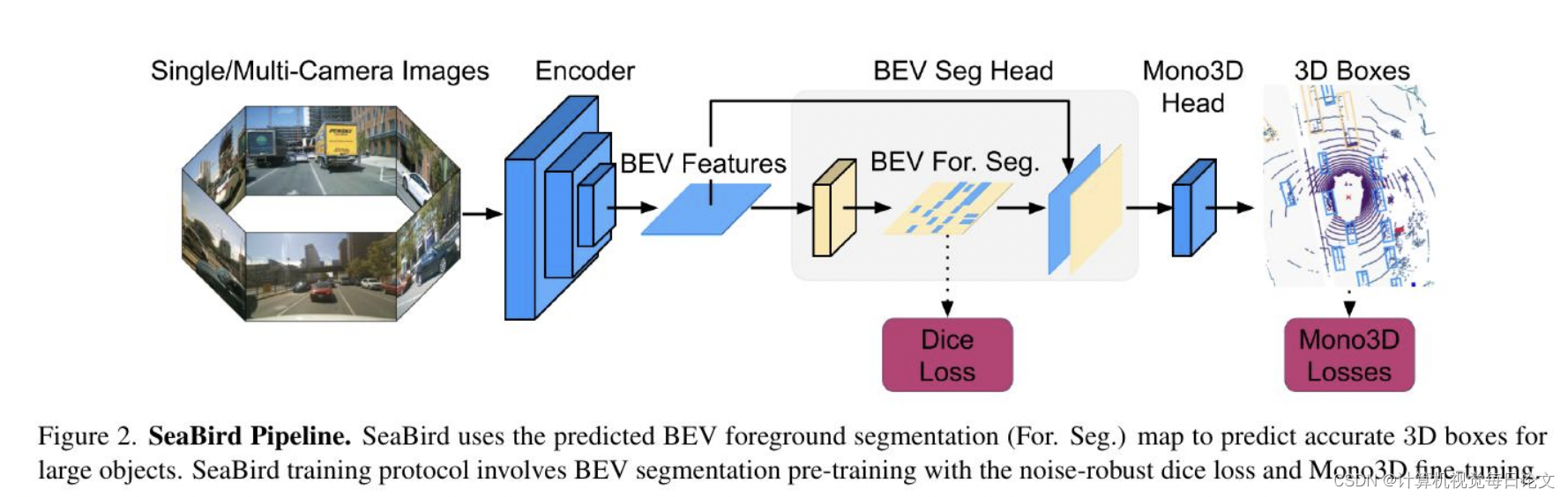
通过在一个简化的情况下进行数学证明,我们证明了相对于回归损失,Dice损失在大型物体的噪声鲁棒性和模型收敛方面具有优越性。利用我们的理论洞见,我们提出了SeaBird(鸟瞰图中的分割)作为通向大型物体泛化的第一步。SeaBird有效地将BEV分割与3D检测中的前景物体相结合,并使用Dice损失来训练分割头部。在KITTI-360排行榜上,SeaBird取得了最先进的结果,并改善了现有检测器在nuScenes排行榜上的表现,尤其是对于大型物体。
我们的代码和模型可以在https://github.com/abhi1kumar/SeaBird找到。