这块的知识点比较零碎也是看到了就过来记录一点,可能是之前没有特别注意的,会持续补充
集合
1 通用实现
- List
- Set
- SortedSet(如果表达是有序的,返回签名使用有序set来表达)
- NavigableSet(since 1.6)
- Queue (since 1.5)
- Deque(since 1.6)
- SortedMap
- NavigableMap(since 1.6)
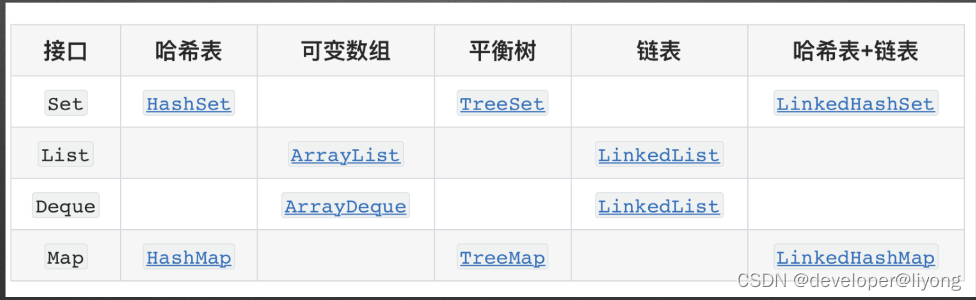
Map允许为空的的value
ConcurrentHashMap value 不允许为空,如果value为空在查询数据时会产生歧义,到底是值为空还是线程不可见
2 并发实现
- ConcurrentMap(since 1.5)
- ConcurrentNavigableMap(since 1.6)
- BlockingQueue
- TransferQueue
- BlockingDeque
- LinkedBlockingQueue
- ArrayBlockingQueue
- PriorityBlockingQueue
- DelayQueue
- SynchronousUqueu
- LinkedBlockingDeque
- LinkedTransferQueue
- CopyOnWriteArrayList
- CopyOnWriteArraySet
- ConcurrentSkipListSet
- ConcurrentSkipListMap
3 遗留实现
- Vector
vector 是数组实现线程安全的,他也是实现了List,一般对标的是ArrayList
如果在一个方法里面使用vector 几乎没有同步的消耗,因为它不存在资源竞争。 - Stack
- Hashtable
- Enumeration
- BitSet
这里Vector,Stack,Hashtable都是线程安全的
Collection 顶层接口
这里只对值得记录的知识点做一个记录,其它平时比较熟悉的基础知识这里不再记录。
- int size();
public interface Collection<E> extends Iterable<E> {
// 这个size最多为Integer.MAX_VALUE
int size();
}
为什么不用Long类型呢?
因为Long和double 是非线程安全的,有两个四字节,高位和地位。
补充知识:
// 这两个都是true
System.out.println(Integer.MAX_VALUE + 1 == Integer.MIN_VALUE);
System.out.println(Integer.MAX_VALUE + 2 == Integer.MIN_VALUE + 1);
Object[] toArray() 与 T[] toArray(T[] a) 的区别
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 区别转换为对象数组
Object[] one = list.toArray();
System.out.println("length : " + one.length);
Arrays.stream(one).forEach(System.out::println);
System.out.println("========>");
// 允许我们指定输出的类型,并且如果我们指定的数组比真实数据多,后面的空间全赋值为null
Integer[] two = list.toArray(new Integer[10]);
// 并且如果我们指定了数组的长度我们的长度以指定的数组为准
System.out.println("length : " + two.length);
Arrays.stream(two).forEach(System.out::println);
System.out.println("========>");
// 如果我们指定的数组长度小于原始,它会以原始的数据为准,也就是说不会少数据
Integer[] three = list.toArray(new Integer[3]);
System.out.println("length : " + three.length);
Arrays.stream(three).forEach(System.out::println);
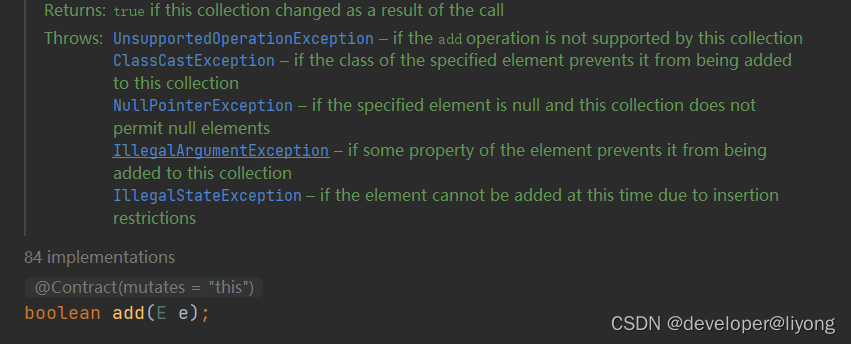
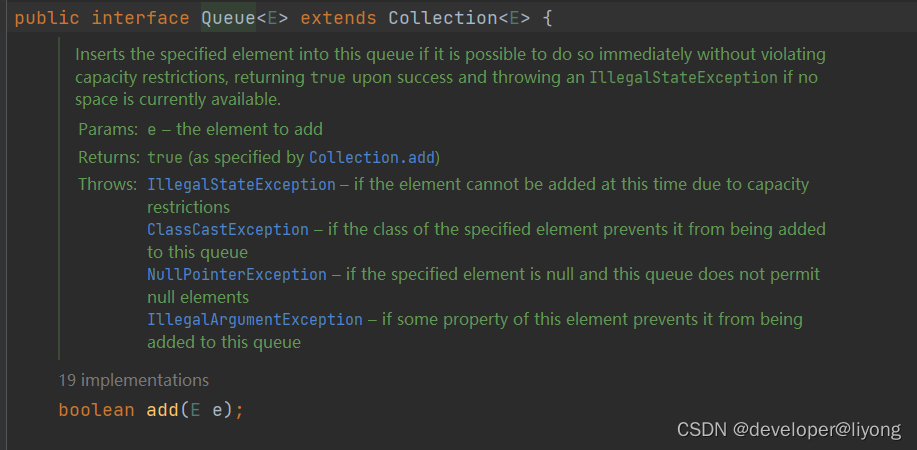
为什么Collection里面有add 队列里面还有自己的add方法呢?
我们看到这个约束其实是不一样的,集合可能是只读的,所以有UnsupportedOperationException异常。
Set 与 Map
1 set是map key 的实现,Set底层调用Map实现。
// 我们还可以看到如果是set其实他的value都是指向同一个对象
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
2 treeSet底层用了TreeMap
public TreeSet() {
this(new TreeMap<E,Object>());
}
3 LinkedHashMap
// 有一个这个属性 其实就是实现的LRU算法
final boolean accessOrder;
在插入元素以后:
//执行了这个方法 LinkedHashMap 是有实现的
afterNodeInsertion()
// 而HashMap没有实现这个方法里面是空的什么也没有做
void afterNodeInsertion(boolean evict) { }
为什么HashSet不能保证有序?
public class TT {
public static void main(String[] args) {
// 不能保证有序
Set<String> values = new HashSet<>();
values.add("a");
values.add("b");
values.add("c");
values.forEach(System.out::println);
values.clear();
values.add("1");
values.add("2");
values.add("3");
values.forEach(System.out::println);
// 上面的这两个场景之所以能保证有序是因为这些例子都是 ASCII码
// 字符数组底部就是一个char数组
// char 的 hash 转换为了int
public static int hashCode(char value) {
return (int)value;
}
// String hash 按照下面规则进行计算所以看起来是有序的样子
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
}
}
设计贴士:
// 这里之所以要设计为传对象是兼容多维数组
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
List有两种实现(ArrayList 是数组实现,LinkedList)