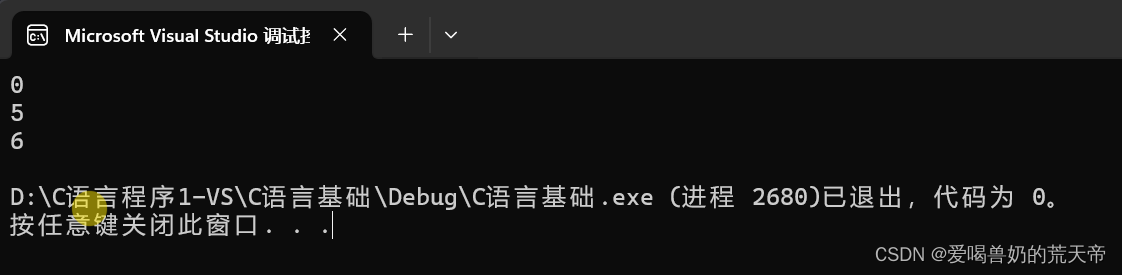
前言:预处理是我们的c语言源代码成为可执行程序的第一个步骤。而宏和预处理指令都是在这个阶段完成。本节内容就是关于宏和预处理指令相关知识点的解析。
目录
宏
预定义符号
#define定义常量
#define定义符号
#define定义宏
带副作用的宏参数
宏的替换规则
宏相对于函数的特点
#和##
#
##
命名约定
undef
命令行定义
条件编译
头文件包含
如何防止头文件被多次包含:
宏
预定义符号
在c语言之中, 定义了下面这几个宏定义符号。同样的, 因为预定义符号是宏, 它也是在预处理阶段进行处理。
__LINE__代表文件当前位置的行号;
__FILE__代表当前的源文件;
__DATE__代表文件被编译的日期;
__TIME__代表了文件被编译的时间;
__STOC__如果编译器遵循标准c语言也就是ANSI C, 那么这个值就是1, 否则就是未定义。
#define定义常量
#define可以定义常量, 具体做法如下
#include<iostream>
using namespace std;
#define MAX 10//定义常量
int main()
{
for (int i = 0; i < MAX; i++)
{
cout << i << endl;
}
return 0;
} 这里就是#define定义常量, 常量值应该在常量名后边 。
#define定义常量的本质其实就是一种替换, 预处理阶段, 编译器会将源代码中的#define定义的常量进行替换。 什么意思?如下:
现在我们还是看上面一串代码: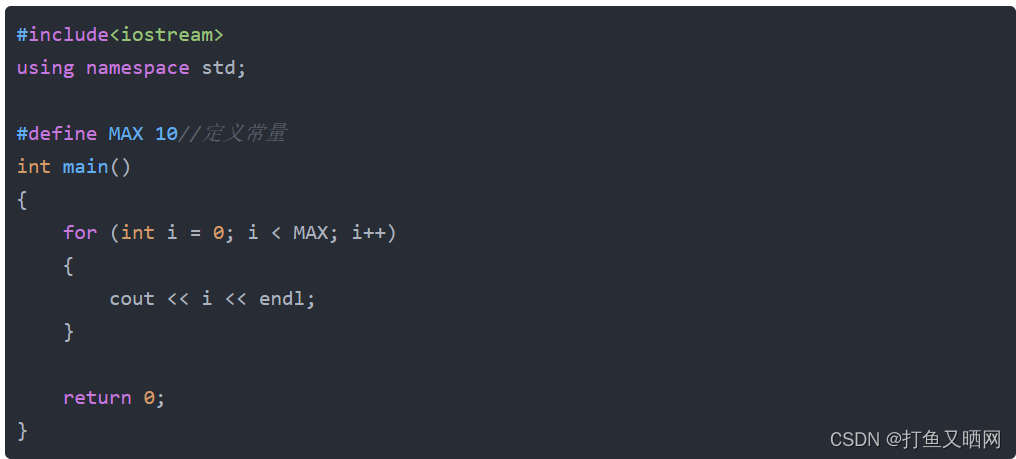
当预处理之后, 这串代码就变成了:
#include<iostream>
using namespace std;
int main()
{
for (int i = 0; i < 10; i++)
{
cout << i << endl;
}
return 0;
} 这里的MAX进行了替换。 
既然#define定义常量的本质是完成替换, 那么在进行#define定义常量的时候需不需要在末尾加上分号?
答案是不需要, 因为加上分号可能出现以下这种情况:
这里就出现了一个问题, 当MAX被替换后, for的括号里变成了: “int i = 0; i < 10;;i++", 第二个判断条件和第三个变化条件之间有了两个分号, 相当于for括号里有了四条语句。这就出现了问题。所以, 当我们使用#define定义常量的时候, 不要再末尾加上分号!
当然, 这里的常量也包括常量字符串
#include<iostream>
using namespace std;
#define STR "sdfsd"
int main()
{
cout << STR << endl;
return 0;
}#define定义符号
#define也可以定义符号, 比如:
#include<iostream>
using namespace std;
#define FOR for(;;)
int main()
{
FOR;
return 0;
}注意, 这串代码就是一个死循环。 因为FOR是#define定义的符号。 在预处理的时候, FOR被替换成了for(;;),这里面判断条件为空, 恒为真,所以就是一个死循环。
#define也可以定义一串很长的代码:
#include<iostream>
using namespace std;
#define MYFILE printf("name:%s, line:%s, data:%s",\
__FILE__, __LINE__, __DATE__)
int main()
{
MYFILE;
return 0;
} 
这个红色箭头指向的其实是续行符, 后面不能加空格, 否则续行符无效。续行符之后直接回车换行。
#define定义宏
什么是宏, 宏和上面的定义符号和定义常量有什么区别?
同样的, 宏也是#define定义的一串代码, 但是它和上面的区别是宏是有参数的。定义宏的时候, 参数列表必须紧紧挨着宏名, 否则, 参数列表会被当成宏体。
如下就是一个宏定义:
#include<iostream>
using namespace std;
#define ADD(x, y) x + y
int main()
{
int ret = ADD(1, 2);
return 0;
}这个宏定义的工作原理是这样的, 首先1先传给x, 2传给y, 然后ADD参数列表的x, y的值传给宏体。 再完成替换。
替换后就是这样的
#include<iostream>
using namespace std;
int main()
{
int ret = 1 + 2;
return 0;
}现在想一个问题。既然宏是在预处理阶段就完成替换, 那么他是不是比函数的速度快。 因为函数需要在运行的时候调用, 而宏是在预处理阶段就完成替换, 宏体的代码就在相应的位置展开了。
答案是是的, 宏确实要比函数快。宏在预处理阶段直接完成替换, 不需要去建立栈帧消耗时间。而且, 宏的参数也没有类型:
参数没有了类型, 就相当于没有了类型检查。 这样有好处也有缺点, 好处是参数没有了类型, 更加的灵活。 但缺点也是如此, 因为宏的参数没有了类型, 没有了类型检查, 代码就容易出现问题。 这说明了宏不易调试的缺点。
这里说明宏也不全是优点, 他也是有缺点的。
另外,宏还有另外一个不可忽视的缺点——优先级问题。 现在我们来看这么一串代码。
#include<iostream>
using namespace std;
#define Mul(x, y) x * y
int main()
{
int ret = Mul(1 + 3, 2 + 3);
return 0;
}这一串代码, 宏替换后是这样的: 1 + 3 * 2 + 3;
这显然与我们的预期不符。如果这里是一个函数的话。 那么参数传送过去就应该是:4 * 5;这样的优先级问题可以成为内部的优先级问题。
那么, 外部的优先级问题呢?
#include<iostream>
using namespace std;
#define ADD(x, y) x + y
int main()
{
int ret = ADD(1, 2) * 4;
return 0;
}如图就是一个外部的优先级问题。 宏替换后代码是这样的: 1 + 2 * 4; 与我们的预期同样不符。我们的预期是这样的: 1 + 2 等于三, 然后3 * 4;
所以, 这里也涉及到了优先级的问题。
我们要解决上面的问题, 那么定义的宏体就应该解决内部和外部的优先级问题。 可以这样定义:
#define ADD(x, y) ((x) + (y))带副作用的宏参数
有一些表达式是有副作用的。
比如说++, --符号。
int main()
{
int a = 0;
int b = 1;
int a = ++b;
return 0;
}看这串代码, 前置++对于b来说就是有副作用的。 虽然给a赋值了一个b + 1, 但是b自身的值也发生了改变。
我们定义一个求最大值的宏:
#define MAX(x, y) x > y ? x : y
在这个表达式中, 看似是没有问题的。 但是如果我们使用自增自减符号的时候就有问题。
#include<iostream>
using namespace std;
#define MAX(x, y) x > y ? x : y
int main()
{
int a = 3;
int b = 4;
int ret = MAX(a++, b++);
cout << a << endl;
cout << b << endl;
cout << ret << endl;
return 0;
}这个参数是如何进行的呢
其实, 替换之后应该是这样的:a++ > b++ ? a++ : b++;
这里的a++和b++都出现了两份
这里都是后置加加, a++ > b++这里是a的值3和b的值4进行比较。 比较完之后a加一编程4, b加一变成5。然后3 小于4, 执行b++, b的值进行返回, 返回的是五, 但是b此时还进行了一次++, 所以b变成了6. 所以ret为5, a为4, b为6.
所以如果宏的参数在代码中不知出现一次, 而且宏的参数带有副作用。 那么代码就可能出现问题。 因为宏的参数不是计算之后再传进去, 而是直接进行替换。
宏的替换规则
1、在调用宏时, 首先对参数进行检查,看是否包含任何#define定义的符号。如果是, 首先 被替换。 如图:
#include<iostream>
using namespace std;
#define MAX(x, y) x > y
#define M 10
int main()
{
int a = 3;
MAX(a, M);
return 0;
}这里先进行替换的就是M, 将M替换为10之后再替换MAX, 替换后就是a > 10
注意, 宏参数和#define定义中可以出现其他#define定义的符号, 但是宏不能出现递归。 宏不支持递归。
#include<iostream>
using namespace std;
#define MAX(x, y) x > y
#define M 10
int main()
{
int a = 3;
MAX(a, MAX(a, 1));
return 0;
}注, 这里并不会进行递归。 他只是将a和1先传参, 替换掉里面的宏定义。 然后得到的结果和a再进行传参, 替换掉外面的宏。
并且, 字符串中的宏并不会被检测为宏。比如:
#include<iostream>
using namespace std;
#define MAX(x, y) x > y
#define M 10
int main()
{
int a = 3;
const char* a = "dsfsM";
return 0;
}这里字符串中的M就不会被检测为宏, 不会被替换掉。
宏相对于函数的特点
相比于函数, 宏的特点有这些:1、首先宏不能调试
2、宏不能进行递归
3、宏的速度很快, 它是直接代码替换,而不是在运行时建立栈帧。
4、宏的参数没有类型, 不会进行类型检查
5、宏展开会增加代码长度。
6宏的参数可以出现类型, 但是函数做不到,例如:
#include<iostream>
using namespace std;
#include<stdlib.h>
#define Malloc(n, type) (type*)malloc(n * sizeof(type))
int main()
{
int* ptr = Malloc(1, int);
return 0;
}在这串代码中, 宏Malloc将1和int这个类型传过去, 但是函数一定做不到。
#和##
#
#运算符将宏的一个参数, 直接转化为字符串字面值。 它仅允许出现在待参数的宏的替换列表之中。
#运算符所执行的操作符可以理解为”字符串化“。
意思就是说我们可以这样定义一个宏:
#include<iostream>
using namespace std;
#include<stdlib.h>
#define Print(a, format) printf("the value of " #a " is "format, a);
int main()
{
int a = 10;
Print(a, "%d");
return 0;
} 
在这个宏中, #a预处理阶段会被转化为“a", #的作用就是这样, 将一个宏参数转变为字符串字面量形式。
##
##可以把位于两边的符号变成一个符号。 但是这样的链接必须是合法的标识符, 否则结果就是未定义的。

如图, 如果我们想要求处某个类型的最大值, 但是int类型和float的类型都要定义一个求取最大值函数。 这样就很麻烦, 这个时候如果我们定义这样的一个宏, 就可以解决问题。
#define GEN_MAX(type) \
type type##_max(type x, type y)\
{ \
return x > y ? x : y ;\
}这个宏其实就可以生成一个函数。 而且type##_max中##将两边的链接, 其实就相当于是type_max。
假如我这里这样传参: 
红色箭头就相当于生成了两个函数。
这里我们使用这两个函数: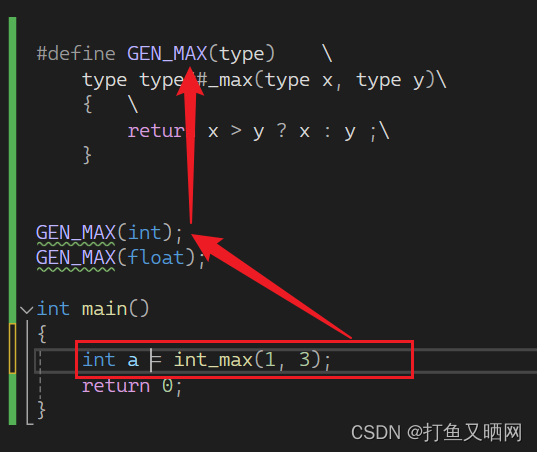
这其实就像模板一样。
命名约定
一般我们宏都是定义为全大写, 不是宏不会定义为全大写。 但这些也不是一定的。 比如offsetof。
(offsetof 的作用是结构体成员相较于结构体其实位置的偏移量。)
undef

undef的功能就是取消undef对应行之后的宏定义。
命令行定义
某些c语言编译器,允许在命令行进行定义符号。当我们要使用一个代码的不同版本的时候, 就可能用到这个命令行定义。 一些机器中大一些, 就可以开大一点的数组。 一些机器种小一些, 就可以开小一点的数组。
条件编译
条件编译, 最重要的就是这几个命令:1、#if #endif
比如: #define ……
#if
#endif
2、多分支:
#if
#elif
#elif
#endif
3、判断是否被定义
#if defined
或者
#ifdef
或者
if !defined
或者
ifndef
条件编译就是满足条件就进行编译, 如果不满足条件,就不要进行编译。
比如if和endif的使用
#if 0
#define MAX 10
int main()
{
printf("%d", MAX);
#undef MAX
printf("%d", MAX);
return 0;
}
#endif这里面这一串代码在预处理阶段就会被销毁, 相当于被注释掉了。
#if 1
#define MAX 10
int main()
{
printf("%d", MAX);
#undef MAX
printf("%d", MAX);
return 0;
}
#endif如果改成1就又会变回来。
又或者if, elif, endif的使用
#define MAX 0
int main()
{
#if MAX == 0
printf("%d", MAX);
#elif MAX != 0
printf("%d", MAX);
return 0;
}
#endif根据MAX的值, 就会选择编译第一个打印还是第二个打印。
头文件包含
头文件的包含有两种形式。 一种是双引号“”的形式进行头文件包含。 一种是<>的形式进行头文件包含。
双引号的头文件包含形式,是先从原文件目录处寻找, 如果未找到头文件, 那么编译器就像查找库函数头文件一样在标准位置查找头文件。 如果再找不到, 那么就会报错。
标准头文件的路径, 再linux环境下, linux标准库的头文件是在/user/include/的路径底下。
vs2022环境的标准头文件路径是略杂乱的。 一般它是在windowssdk路径之下,这里放的一般是贴近操作系统相关的头文件。 还有一些和c语言语法比较贴近的头文件, 放在了vs2022的路径底下。
库文件直接去标准路径底下去查找, 如果找不到, 直接报错。
为什么不让库文件也用“”包含呢?因为库文件是放在标准库里面的, 虽然库文件也可以使用“”进行包含, 但是这样效率就会变低,而且这样不容易区分本地文件和库文件了。
如何防止头文件被多次包含:
当一个项目中文件数过多, 可能出现头文件重复包含的情况。 如何处理这种情况呢?有两种方法。
一种就是#pragma once。其实这就是vs之中当我们创建一个头文件时自己加在第一行的一个函数。
另一种就是使用刚刚讲过的条件编译。
如图:
#ifndef __TEST_H__
#define __TEST_H__
//……代码
#endif 意思就是如过没有定义__TEST_H__, 那么第一行之后的代码就参与编译。 那么第一次我们包含头文件的时候就没有包含__TEST_H__。 这个时候他就会参与编译。然后__TEST_H__被定义。 那么下一次我们再进行这个头文件的包含的时候, 因为__TEST_H__已经被编译过了。 那么第一行代码就为假, 第一行以后的代码就不会被编译。 所以就实现了头文件只包含一次的情况。
以上, 就是预处理指令的全部内容