文章目录
- 一、什么是CRUD?
- 二、新增(Create)
- 1、单行数据 + 全列插入
- 2、多行数据 + 指定列插入
- 3、插入特殊类型
- 三、查询(Retrieve)
- 1、全列查询
- 2、指定列查询
- 3、表达式查询
- 4、指定别名
- 5、去重
- 6、排序
- 7、条件查询
- 基本查询:
- AND与OR:
- 范围查询:
- 模糊查询:LIKE
- NULL 的查询:IS [NOT] NULL
- 8、分页查询:LIMIT
- 四、修改(Update)
- 五、删除(Delete)
- 六、数据库约束
- 1、约束类型
- 2、NULL约束
- 3、UNIQUE:唯一约束
- 4、DEFAULT:默认值约束
- 5、PRIMARY KEY:主键约束
- 6、FOREIGN KEY:外键约束
- 7、逻辑删除
- 七、表的设计
- 1、一对一
- 2、一对多
- 3、多对多
- 4、两个实体毫不相关
- 八、查询(进阶)
- 1、 查询搭配插入
- 2、 聚合查询
- 3、GROUP BY子句
- 4、联合查询/多表查询
- 5、内连接
- 6、外连接
- 7、自连接
- 8、子查询
- 9、合并查询
一、什么是CRUD?
大家肯定跟我一样,看到CRUD这四个字母一头雾水,什么是CRUD呀?
这里我就为大家一一讲解:
CRUD 即增加(Create)、查询(Retrieve)、更新(Update)、删除(Delete)四个单词的首字母缩写
是数据库操作最基本的操作
也是未来我们进入公司实习,最开始的最日常的工作
由此可见,对我们未来涞水非常的重要
所以,接下来就让我们来看看具体什么是CRUD吧
二、新增(Create)
在MySQL中 使用 insert 来往表里插入数据
但是大前提是,选中数据库,并且创建好对应的表
inse into 表名 values (列,列......)
括号里面的给出的数目和类型,都是要和表结构匹配的

那么这里就有人要问了,能不能插入字符串呢?
sql中,字符串是可以使用的
很多编程语言都没有“字符”类型,这种情况一般 ’ 和 " 都能表示字符串
但是MySQL 5,默认字符集是拉丁文,无法直接插入中文的,都需要在创建数据库的时候显示设定好的字符集
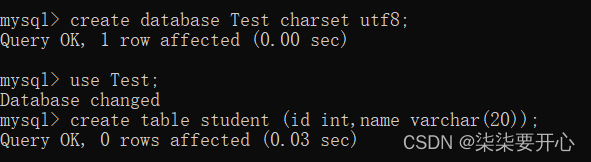

1、单行数据 + 全列插入
插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
如果列的类型不匹配MySQL会尝试自动把字符串转成整数,就会报错

这个时候,可以通过特殊的写好,让这种操作可以成功,比如指定列进行插入
2、多行数据 + 指定列插入
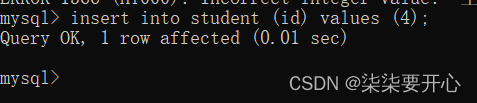
这个时候,在name 列是没有数据的
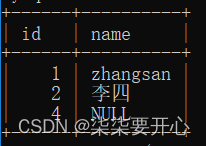
当然也可以一行插入多组数据

这个时候有的人就会想:一次插入十个数据 和 十次分别插入一个,哪个执行效率会比较高呢?
显然是一次插入十个数据
因为MySQL是通过客户端去找服务器,服务器接收到sql之后再进行处理的
因此,每个sql都涉及上述这样的交互过程
所以显然第一种情况会更好
3、插入特殊类型
上述我么都是进行了插入数字、字符串,相对于来说就比较简单
接下来我们进行插入datetime 类型
比较简单的写法,直接使用特定的格式化字符串,表示时间日期

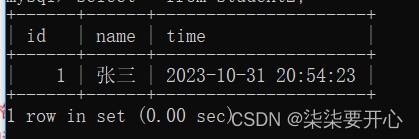
这属于MySQL支持的一种标准化格式
这是一个“标准化时间字符串”,MySQL会自动解析这个字符串,转换成8个字节的时间戳
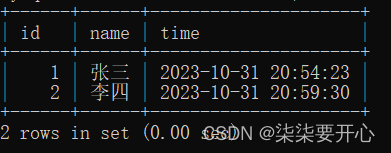
当然也可使用 now() 这样的函数,直接获取当前的时间日期

三、查询(Retrieve)
查询是数据库操作中最常见的用法
学好查询非常重要
接下来就让我们一起进入查询的学习
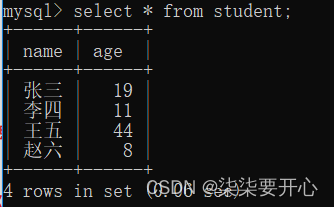
1、全列查询
select * from 表名;
这里 * 被称为通配符
注意:
select * from 表名; 这个操作非常危险
一旦表中数据量过大,就会导致整个数据库崩盘
并且可能会影响到索引的使用
2、指定列查询
select 列名, 列名...... from 表名;

在查询的时候 要确保列的名字 和 表的列的名字是一致的(顺序是随意的)
3、表达式查询
可以在查询的过程中,指定表达式(把查询出来的每一行,都带入表达式进行运算)
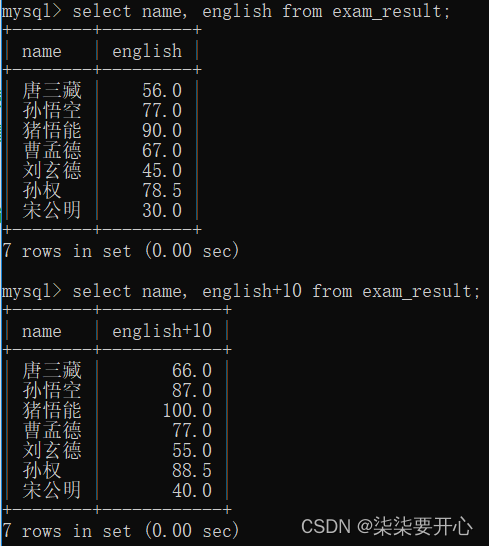
有的人在看到新查的表会有疑惑,这是个新的表吗?会在数据库中改变表吗?
在当前的表达式查询中,并没有修改服务器上硬盘存储的数据本题,只是在查询结果的基础上进行运算的,得到的是一个**“临时表”**
此处查询出来的临时表,每个列的类型不在受限于原始表
这个临时表在查询炒作结束的时候,数据就消失了,数据的本题内容不会发生任何改变
select 进行的任意操作,都不会修改数据本体!!!
4、指定别名
select 表达式 as 别名 from 表名:
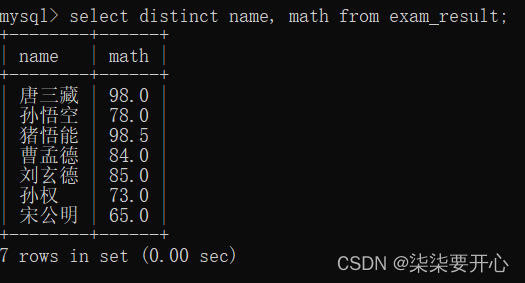
5、去重
查询的视乎,进行去重
查询结果中如果存在重复的元素,就只保留一个
select distinct 列名 from 表名;
6、排序
查询的同时,进行排序
select 列名 from 表名 order by 列名;
最后面那个列名,就是排序的一句(列名不一定出现在 select 的列名中)
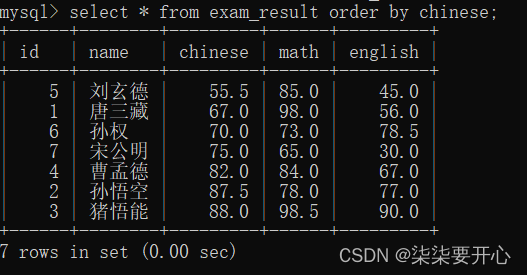 这样就构成了升序排序
这样就构成了升序排序
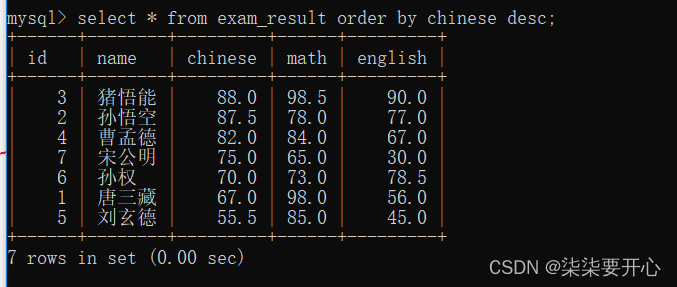
这样就是降序排序 就是在后面加了dese
字符串虽然也可以排序,但是这个时候排序大部分情况 不符合需求
“字典序”中文字典序是没有意义的
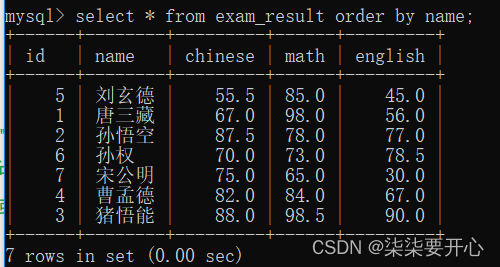
order by 可以指定多个列来进行排序
指定多个列的时候,就也是带有“优先级”的
前面的列,优先级高,后面的优先级低
优先级高的列值相同,才会比较优先级低的列

先按照数学成绩排序,如果数学成绩相同,在按照语文成绩排序
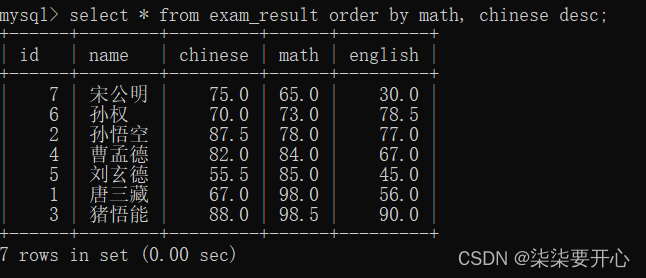
先按照数学成绩升序排,如果数学相同,再按照语文成绩降序排
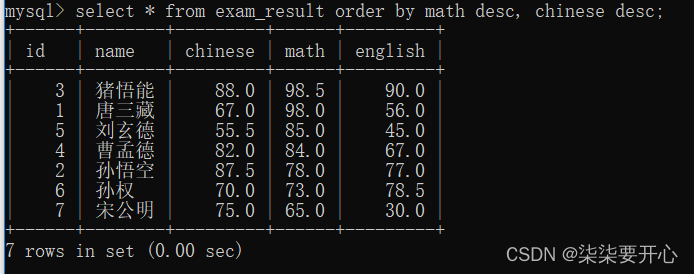
先按照数学成绩降序排,数学相同,再按照语文成绩降序排
7、条件查询
查询的时候,指定筛选条件
条件满足,这个数据就被保留(最为结果集,最终的结果集,就是所有满足条件)
不满足,这个数据直接跳过
执行条件查询的时候,就会遍历整个表,把每个记录都带入到条件中,看条件是否满足
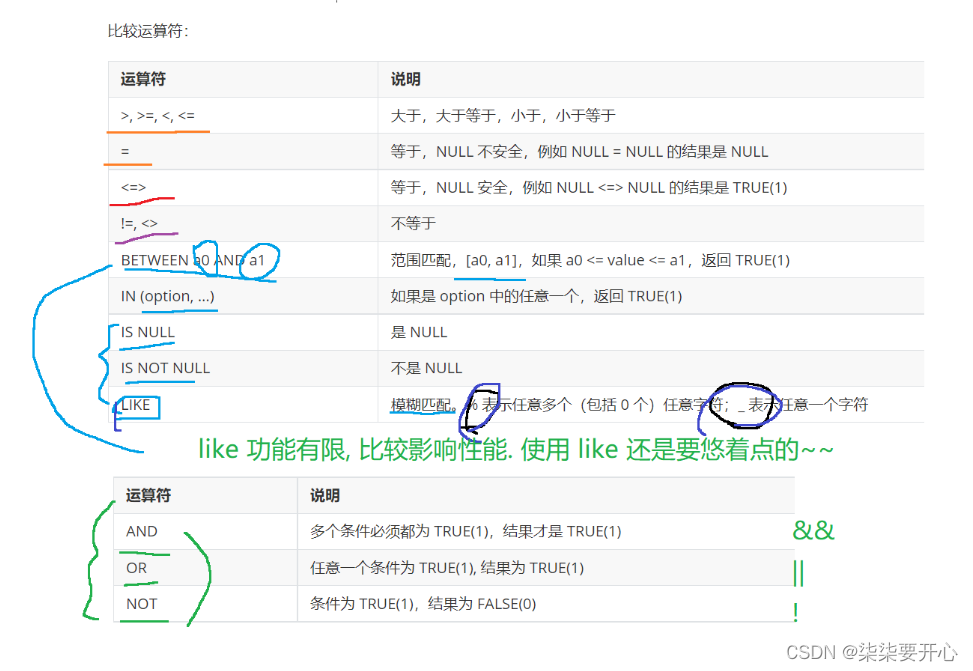
基本查询:
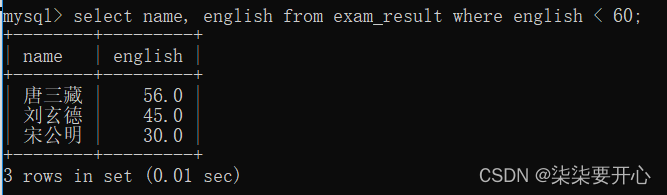
- 查询英语成绩不及格的同学即英语成绩(< 60)
- 查询语文成绩好于英语成绩的同学
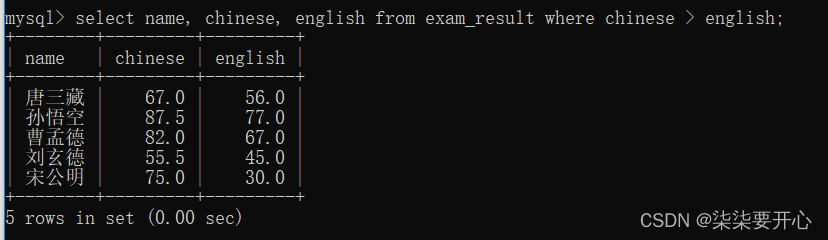
- 查询总分在200 分以下的同学

在这里不可以取别名来进行查询
AND与OR:
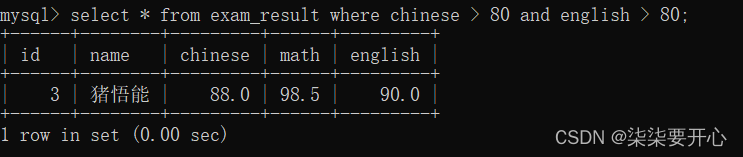
- 查询语文成绩大于80分,且英语成绩大于80分的同学
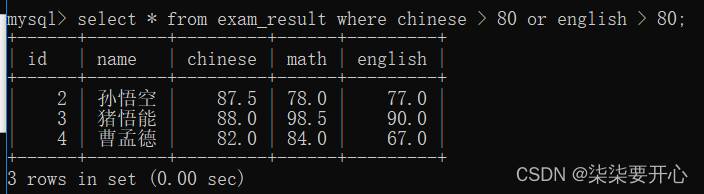
- 查询语文成绩大于80分,或英语成绩大于80分的同学
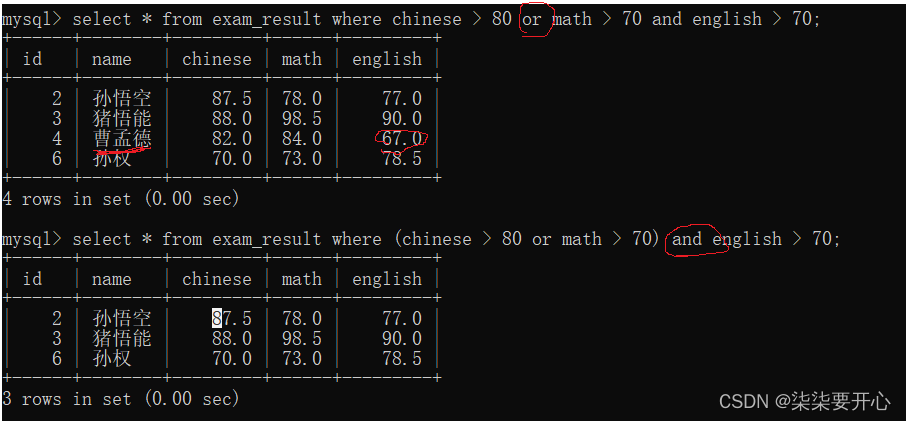
- 观察AND 和 OR 的优先级
AND 的 优先级高于 OR
一个where 中,有and 也有 or,此时会先执行 and,后执行 or
范围查询:
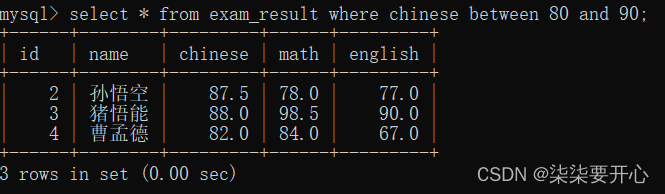
- BETWEEN … AND…
查询语文成绩在 [80, 90] 分的同学及语文成绩
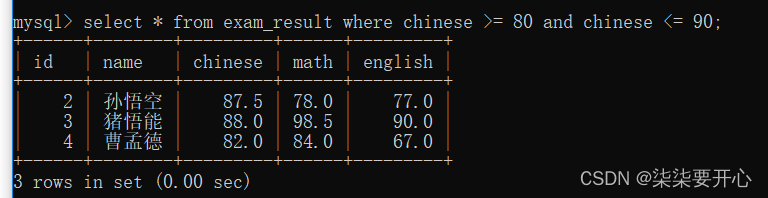
使用 AND 也可以实现
2. IN
查询数学成绩是 78 或者 59 或者 98 或者 99 分的同学及数学成绩
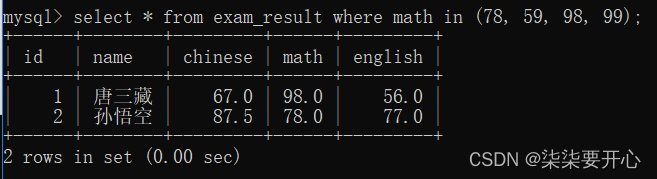
使用 OR 也可以实现

模糊查询:LIKE
在这里用到了通配符
%:匹配任意个任意字符
_:匹配一个字符
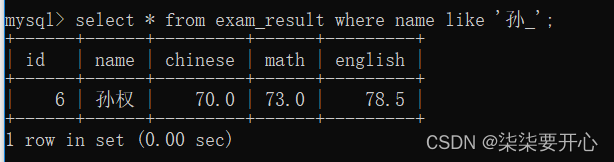
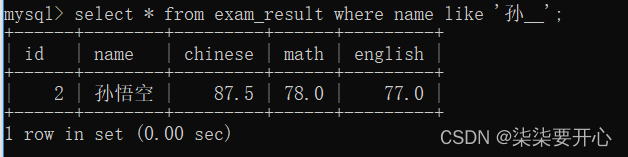
匹配名字中以孙 开头的同学
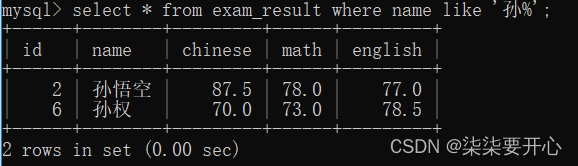
‘孙%’ 以孙开头
‘%孙’ 以孙结尾
‘%孙%’ 包含孙的
_ 只能匹配到一个任意字符
NULL 的查询:IS [NOT] NULL
MySQL支持的模糊查询,规则是比较简单的
除了各种编程语言,还有一种模糊匹配的方式,“正则表达式”

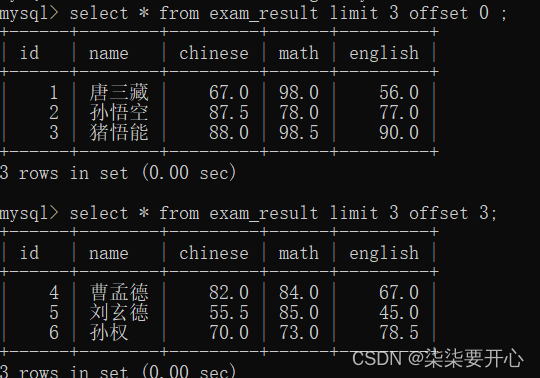
8、分页查询:LIMIT
select * 比较危险,一次查出来的内容太多了
分页查询则是最适合的能解决上述问题的方案
可以限制这一次查询,最多可以查多少记录
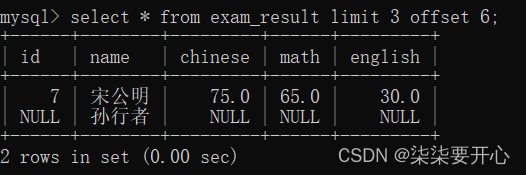
在操作生产环境数据库的时候
最好在查询的时候都加上limit
四、修改(Update)
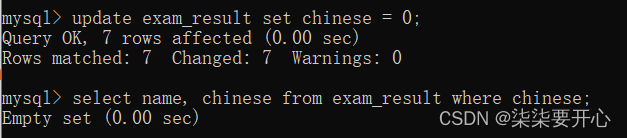
update 表名 set 列名 = 值 where 条件;
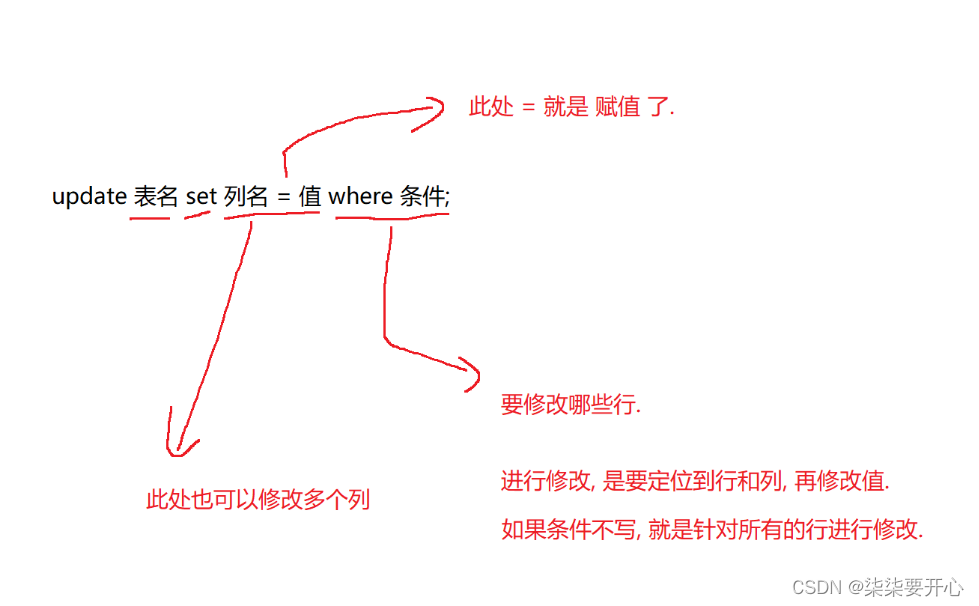
update 的操作是修改硬盘数据
将孙悟空同学的数学成绩变更为 80 分
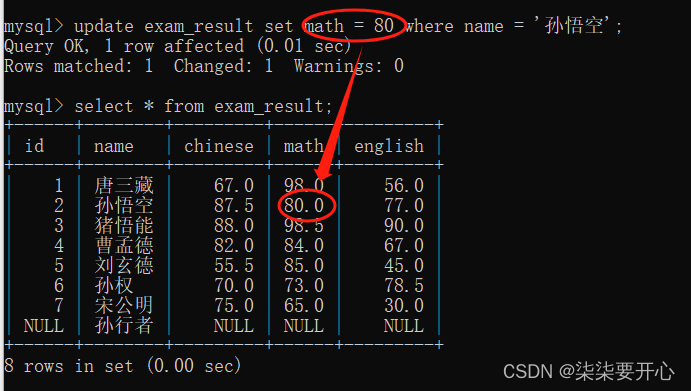
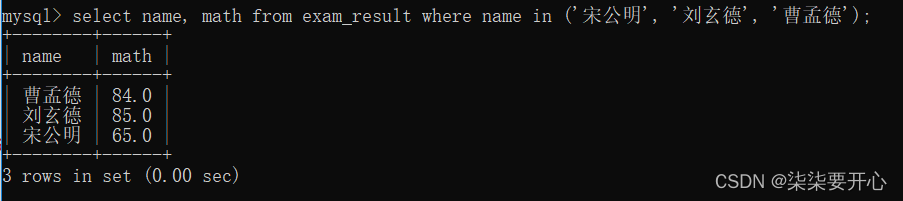
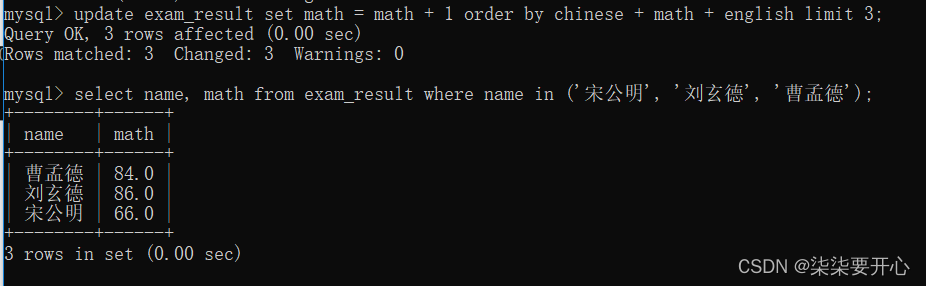
将总成绩倒数前三的 3 位同学的数学成绩加上 1 分
这个时候我们先查看一下总成绩倒数三名

由于空值在排序的时候,会被当做最小
所以先删了
再次查询

接下来就要将这三个人的数学成绩加1
修改语文成绩,改成0
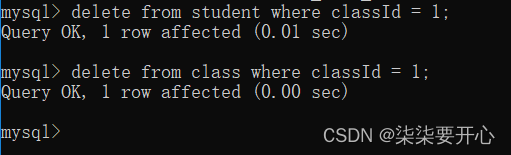
五、删除(Delete)
delete from 表名 where 条件 / order by / limit;
把条件匹配出来的符合要求的记录,给删除掉
删除行者孙的成绩

如果删除语句没有指定任何条件,就会删除表里的所有数据
删除所有记录 和 删表 还是有一些差别的
drop table 是把表本身 和 表里的数据都删掉了
delete 则只是删除了表里面的数据
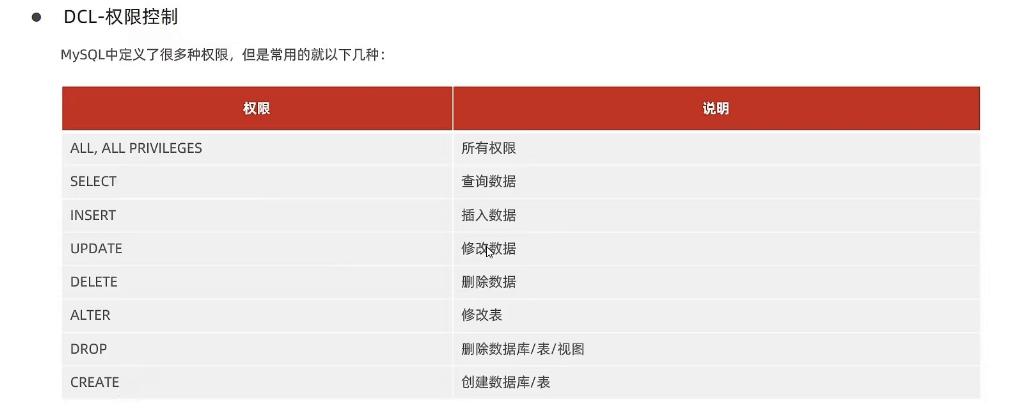
六、数据库约束
1、约束类型

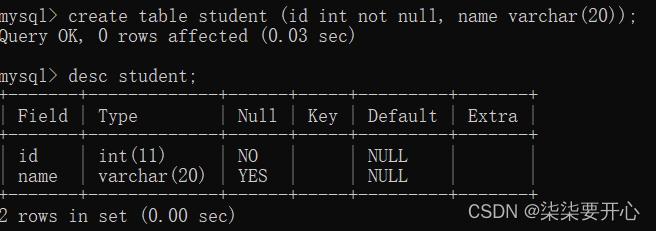
2、NULL约束
创建表时,可以指定某列不为空


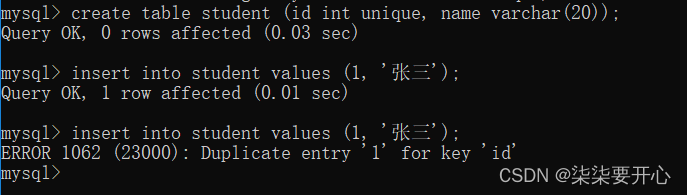
3、UNIQUE:唯一约束
加上 unique 约束之后,后续进行插入/修改的时候,都会先进行查询,看看当前这个值是否已经存在
约束,能够引入更多的检查操作,也会增加系统的开销
4、DEFAULT:默认值约束
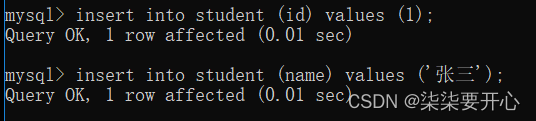
默认情况下 默认值就是 NULL
进行指定列插入,其他未被指定的列就会被设为默认值
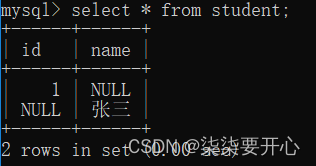
接下来让我们加上约束条件
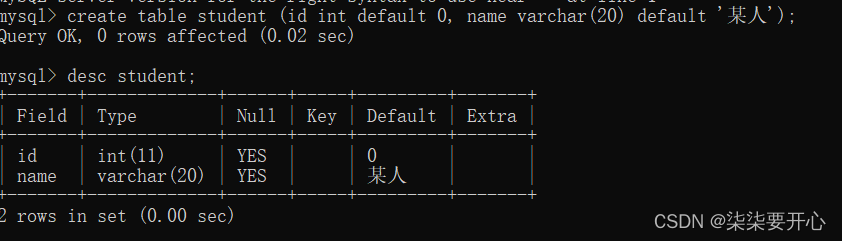
这个时候默认值就会改变
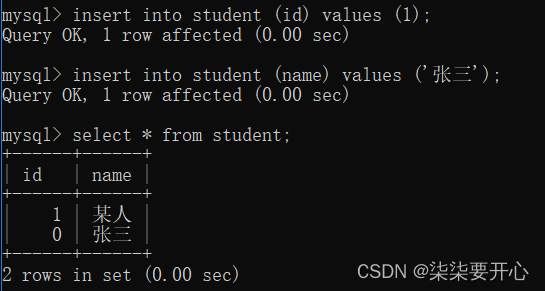
这样操作是因为,很多时候,如果返回一个null,是一个不好的体验
尤其不应该把null 这样的字眼,呈现到普通用户眼前
5、PRIMARY KEY:主键约束
主键,用来作为一个记录的身份标识

一个表里只有一个主键
通常会使用像图上 xxx id这样的列作为主键
但是还有一种情况,叫做联合主键,只有一个主键是由多个列联合构成的
主键是非空并且是唯一的
一旦插入错误就会插入失败

主键是不允许重复的,但是怎么确保它不重复呢?
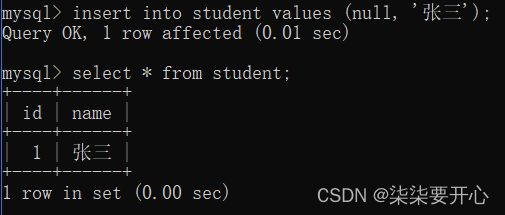
MySQL自身给我们提供了一种机制,“自增主键”
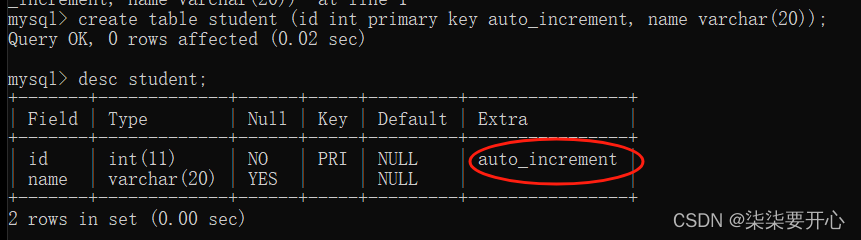
红色圈起来的地方,只是当前这个id,不需要用户自己指定了,可以交给数据库,让数据库自行进行分配
如下图所示:
注意:
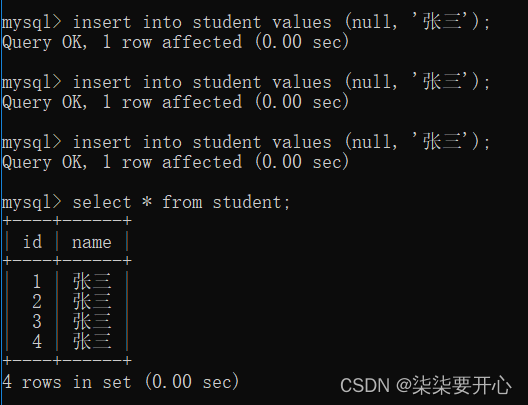
每次使用null 的方式插入自增主键的时候
都是数据库会根据当前这一列的最大值,在这个基础上,继续进行递增
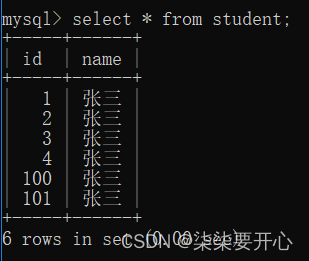
这里的递增不会重复使用之前的值的
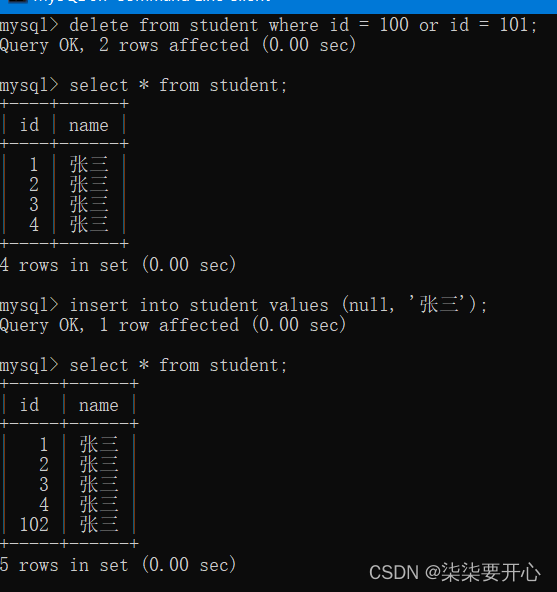
上述自增主键,只能在单个数据库下生效
如果数据库是由多个MySQL服务器构成的“集群”,此时,自增主键就无法生效了
当表里面的数据挺特别多,一台机器存不下,就需要使用多个机器,把表里面的数据一分为二,每台机器存一半
此时,这两个机器的主键,就是各自自增各自的了
这就可能导致,第一个机器中的数据的id 和 第二个机器的数据 id 重复了
实际上在业务中引入“主键”是希望不会重复的
确保一个分布式系统中,能够存在唯一的 id,业界也有一些分布式系统生成唯一的 id 算法。如下:
把这个主键,设置成字符串类型(里面包括一个时间戳,主机的编号,随机因子)
按照这个思路,生成的主键字符串,就可以确保分布式系统下,也是唯一的
6、FOREIGN KEY:外键约束
外键约束是存在于两个表之间的,因此我们目前需要两个表

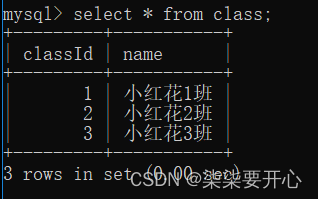
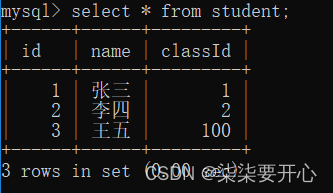
这个时候王五同学不在班级表中存在,因此这是一个不太科学的非法数据
引入外键约束,就是为了解决这样的问题
希望学生表中的classId 都要在班级表中存在,就可以使用外键约束来进行校验
语法:
foreign key (字段名) references 主表(列)


前面的约束,都是在定义表的时候,哪一列需要学术,就创建到哪一列的后面
外键约束,则是写到最后,把所有前面的列都定义好了之后,在最后面通过 foreign key 创建外键约束
这种情况下,也可以认为,班级表,约束了学生表
把班级表这种约束别人的表,称为“父表”
把学生表这种被别人约束的表,称为“子表”
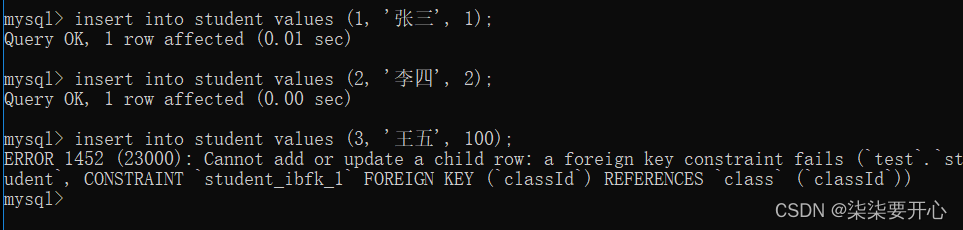
引入外键约束之后,新增一个记录,就会先在对应的父表中查询,看看是否存在,如果不存在,就会报错

修改也是不可以的
注意:
外键约束,是双向的
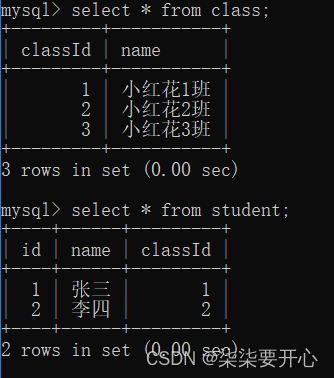
这个时候如果想删除父表的数据,就可能有问题

先要删除父表的这个数据,就必须先删除子表中的对应的数据,确保子表中没有数据
这样引用父表的记录,再能真正删除
尝试删除/修改父表中的记录,也会先查询子表,看看当前这个结果是否在子表中被引用,如果被引用,就会删除失败
使用外键约束的时候,操作子表,要查询父表;操作父表,也要查询子表
如果表数据很多,查询操作就会非常低效
为了让上述查询更加高效一些,往往就需要要求 子表中的列和父表中被引用的列,都要带有“索引”

7、逻辑删除
在实际的数据库应用中,我们经常会遇到一些问题:
比如:在淘宝买东西时之后,商品会有订单表,但是如果商品下架了,订单表还在,但是商品表就消失了
此处是可以用外键约束的,但是引入外键约束后,后续这个商品如何下架呢?
其最终的问题是,如何在使用外键约束的前提下,删除商品表中的数据,但是不影响订单表
这个时候,就需要进行逻辑删除

这个时候,用户想要查询商品列表,就可以通过where isOnlin = 1 就可以确保不会把下线的商品查询出去
如果需要下线,就直接把 isOnline 改成 0
上述做法,书没有真正删除(硬盘空间依然被占用),只是“逻辑上”标记无效了
不仅仅在数据库,其实很多场景也会用到逻辑删除的思路
电脑上的文件,进行删除也是逻辑删除,不是正在的删了
你把文件删掉,其实就是在系统中,把硬盘对应的盘块数据标记无效了,理论上都是可以恢复数据的
七、表的设计
对于“数据库设计”就是根据需求,把你需要的表创建出来
对此有两点要求:
-
先根据需求,找到实体
对于一些关键性质的对象,要梳理清楚需求,提取出关键的名字
一般来说,每个实体,都需要安排一个表 -
梳理清楚实体之间的关系
多个实体之间,需要理清楚关系,不同的关系下,有不同的设计表的方式
1、一对一
一个学生只有一个学号,一个学号也只对应一个学生,这就是一对一的关系

在一对一的关系下,表结构就有以下几种设计方案:
方案一:创建一个大表,把需要的所有信息都放在一起
但是,如果这两个表都很简单(列很少)可以烤炉合并,如果这两个表都很复杂(列很多)不建议合并
方案二:分两个表,使用 id 来引用过来,建立联系


2、一对多
在学校教务系统,有一个实体,学生,还有一个实体,班级
一个班级可以包含多个学生,一个学生只能属于一个班级

针对一对多,设计表结构,也存在两种方案:
方案一:

方案二:

由于MySQL 的类型中,不支持“数组”这样的类型,方案一是行不通的,只能使用方案二
3、多对多
在教务系统中,学生是一个实体,课程是一个实体
一个学生可以选择多种课程,一个课程也可以被多个学生选择
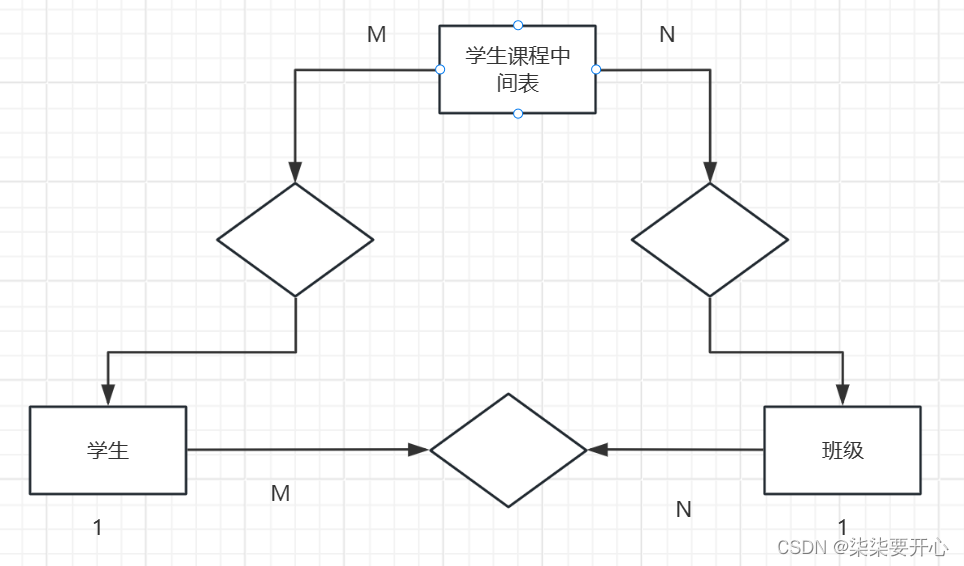
设计数据库也有定式

4、两个实体毫不相关
八、查询(进阶)
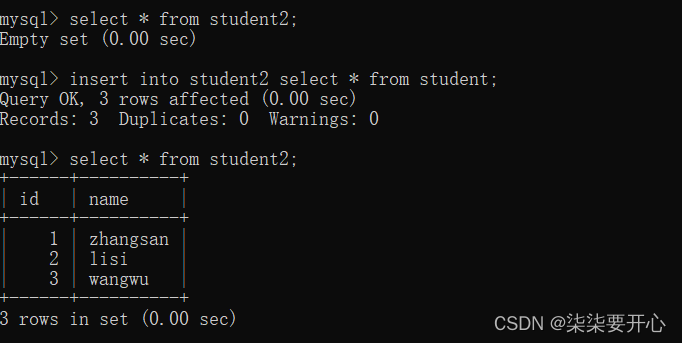
1、 查询搭配插入
查询可以搭配插入使用
把查询语句的查询结果,作为插入的数值
此处要求 查询出来的结果集合,列数/类型 要和插入的这个表匹配
2、 聚合查询
表达式查询,是针对 列和列 之间进行运算的
聚合查询,相当于是在 行 和 行 之间进行运算的
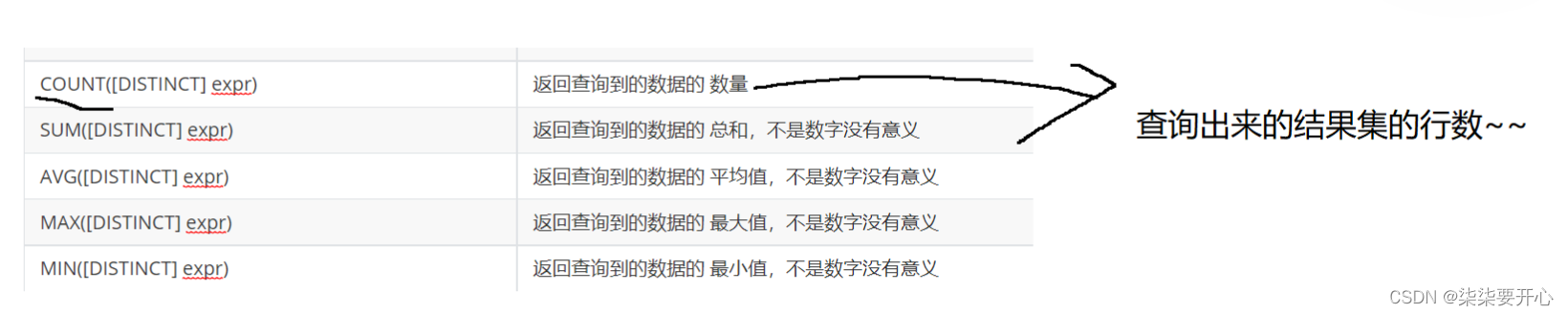
sql 中提供了一些“聚合函数”来完成上述行之间的运算
先执行 select * ,再针对结果集合进行统计(看看具体有几行)
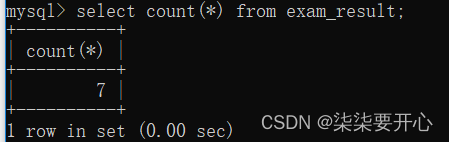
在页面中我们是可以看到行数的为什么还要使用 count 呢?
因为这是 mysql 客户端内置的功能,如果通过代码来操作 mysql 服务器,就没有这个功能了
另外,count(*) 得到的结构还可以参与各种算数运算,还可以搭配其他 sql 使用
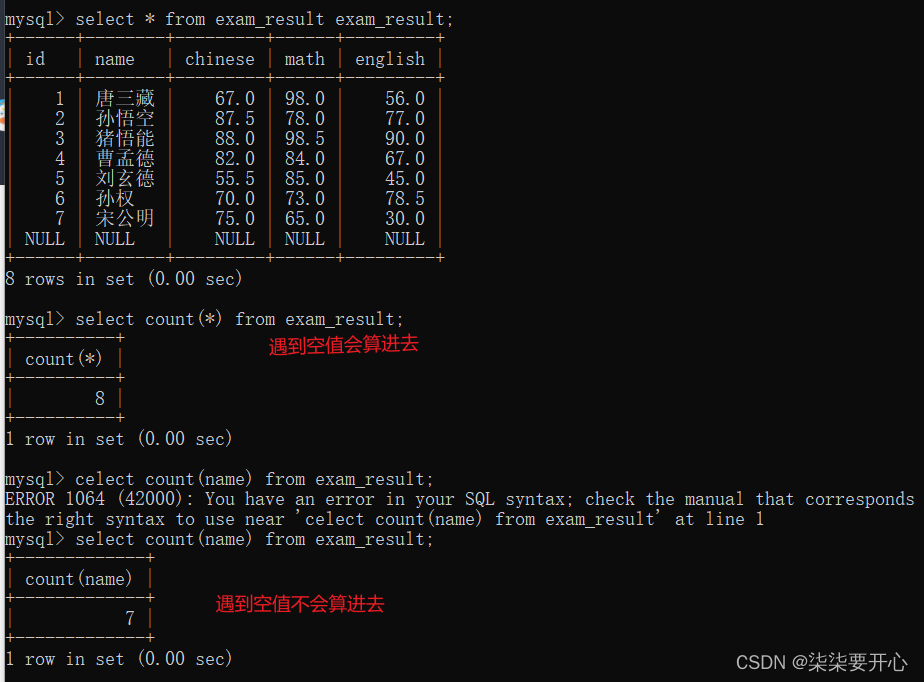
指定列进行去重
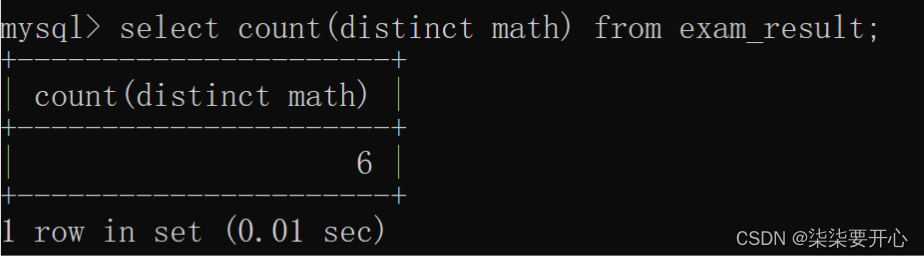
SUM([DISTINCT] expr)
把这一列的若干行,给进行求和(算数运算)
只能针对数字类型使用
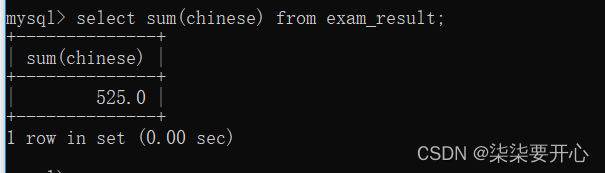
在这里 null 不会进行相加
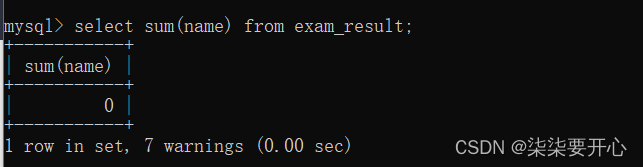
字符串不能相加,会有警告

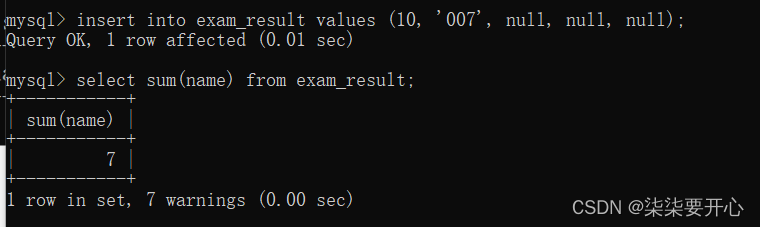
这里就是把 007 当做数字,转换成了 double 类型
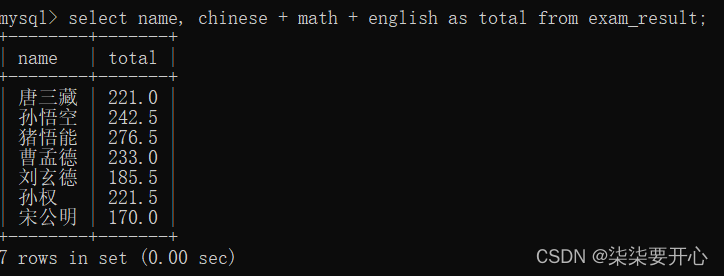
sum(表达式):
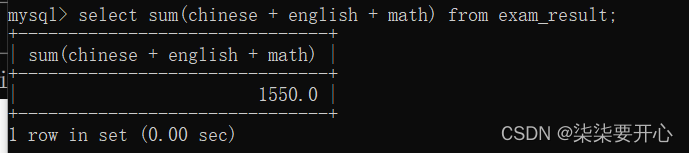
- select chinese + math +english
把对应的列相加,得到一个临时表 - 在把这个临时表的结果进行行和行相加
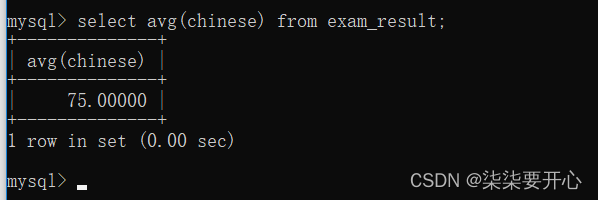
AVG([DISTINCT] expr)
返回查询到的数据的 平均值,不是数字没有意义
MAX([DISTINCT] expr)
返回查询到的数据的 最大值,不是数字没有意义
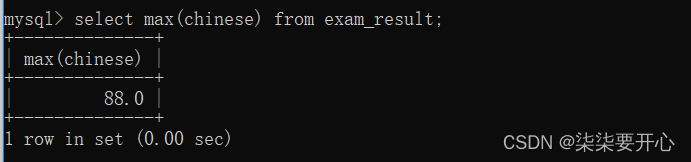
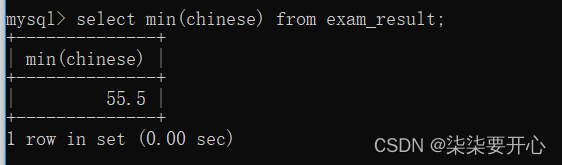
MIN([DISTINCT] expr)
返回查询到的数据的 最小值,不是数字没有意义
3、GROUP BY子句
使用 group by 进行分组,针对每个分组,再进行聚合查询
针对指定的列进行分组,把这一列中,值相同的行,分到一组中
这样就会得到若干个组,针对这些组,分别使用聚合函数
如果直接查询,就会出现线吗这种情况
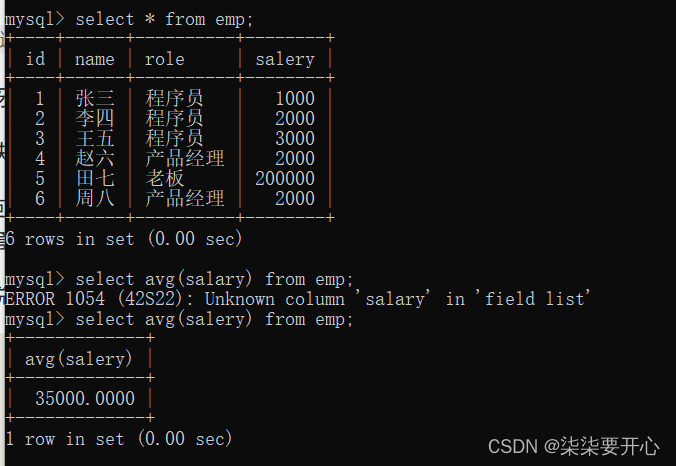
导致信息不准确
这里我们就需要把每种岗位进行分组
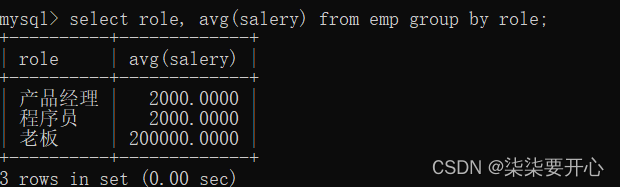
使用 group by 的时候,还可以搭配条件
需要区分清楚,该条件是分组之前的条件,还是分组之后的条件
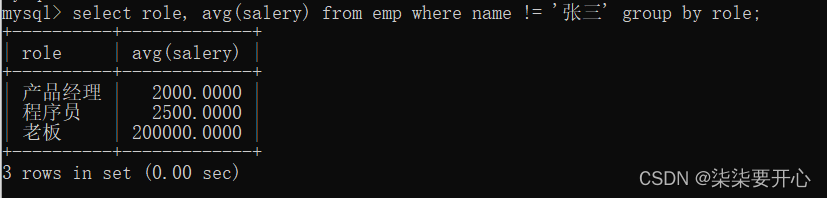
- 查询每个岗位的平均工资,但是排除张三
直接使用 where 即可,where 子句 一般写在 group by 的前面
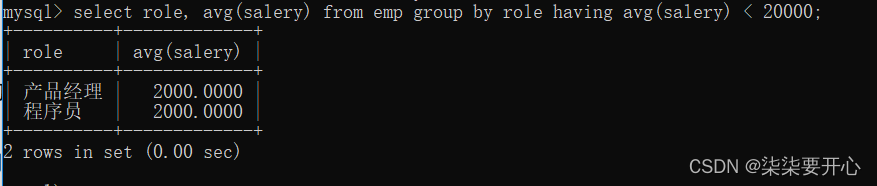
- 查询每个岗位的平均薪资,但是排除平均薪资超过 2w 的结果
使用 having 描述条件,having 子句一般写在 group by 的后面
- 在 group by 中,可以一个 sql 同时完成这两类条件的筛选
查询每个岗位的平均薪资,不算张三,并且保留平均薪资超过 2w 的结果

4、联合查询/多表查询
前面的查询,都是针对一个表
相比之下,则是一次性需要从过个表中进行查询
联合查询,关键思路,在于理解“笛卡尔积”工作过程
准备表
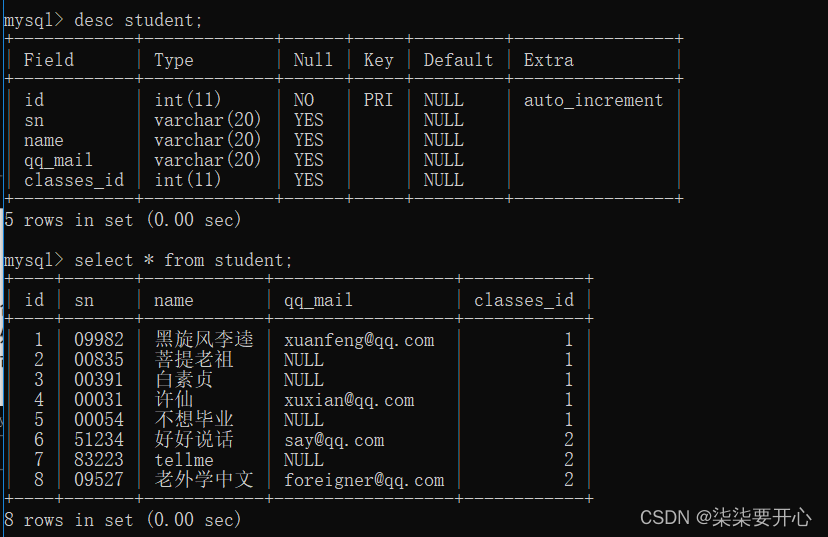
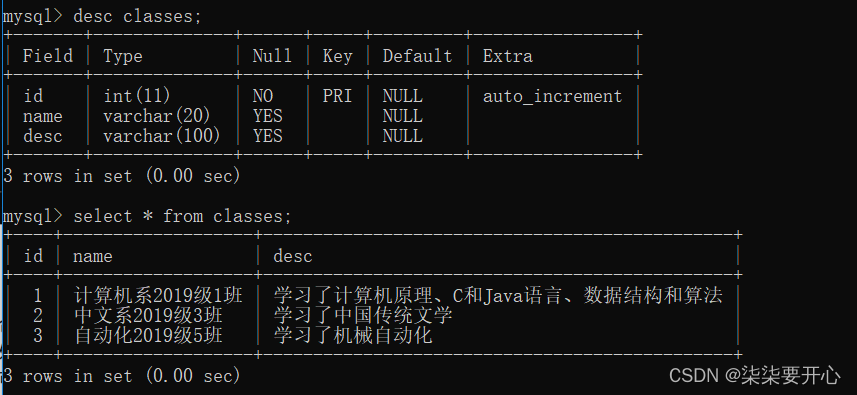
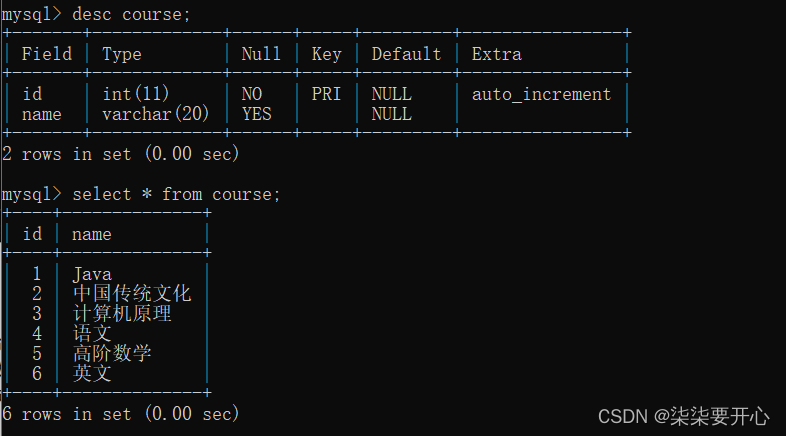
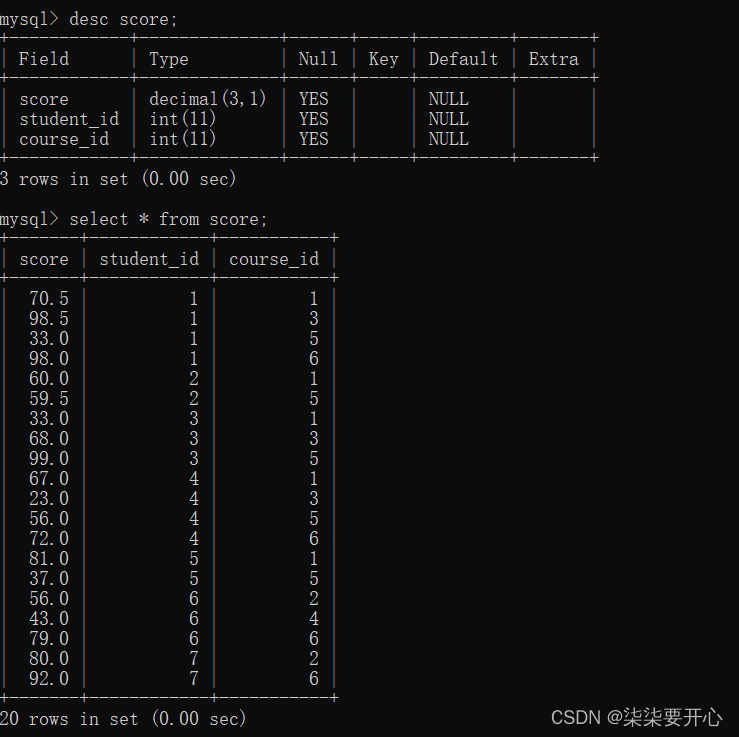
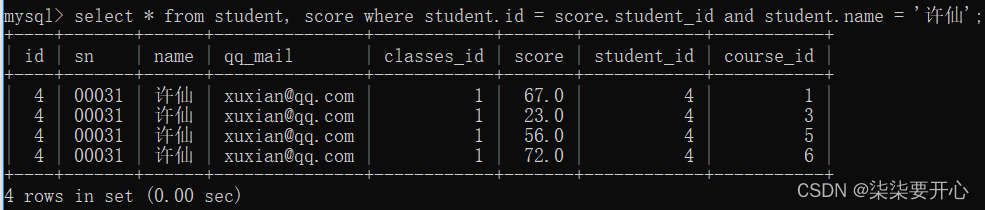
查询“许仙”同学的成绩
通过 student 和 score 表进行联合查询
- 先把这两个表,进行笛卡尔积
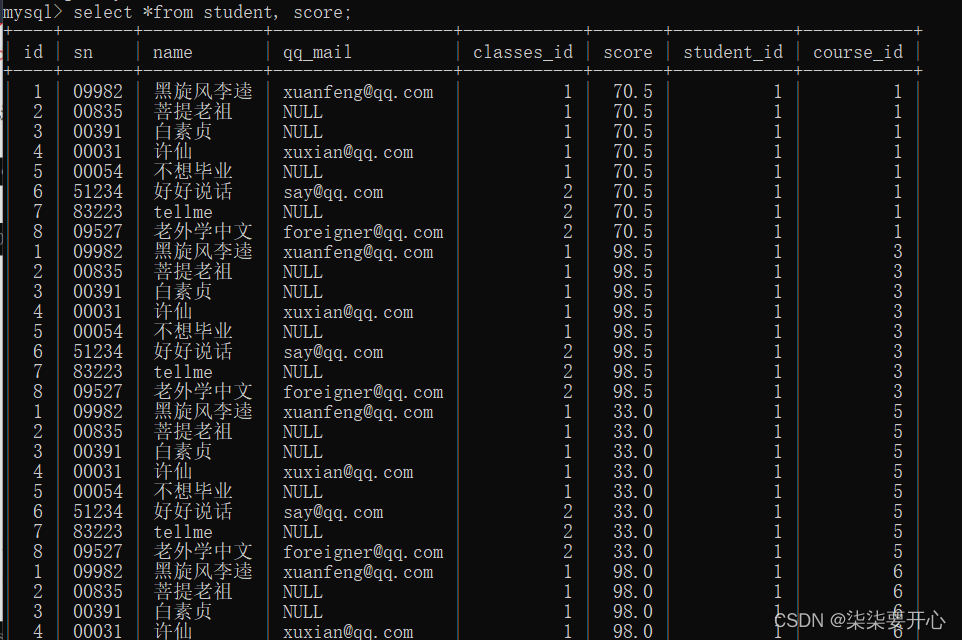
- 加上连接条件,筛选出有效数据
学生表的 id = 分数表的 student_id
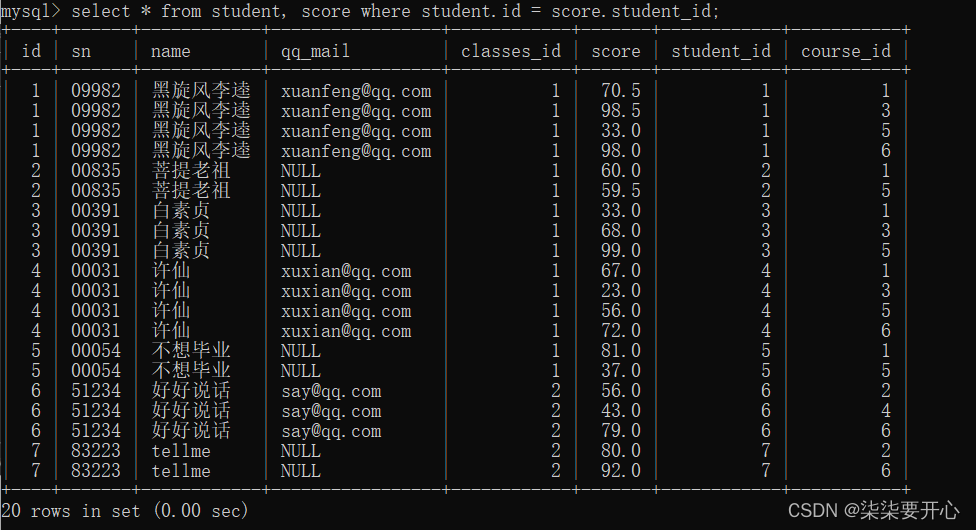
- 结合需求,进一步添加条件,针对结构进行筛选
此处是 查询 许仙的成绩
就可以加上一个 student.name = ‘许仙’
- 针对查询到的列进行精简,只保留需求中关心的列

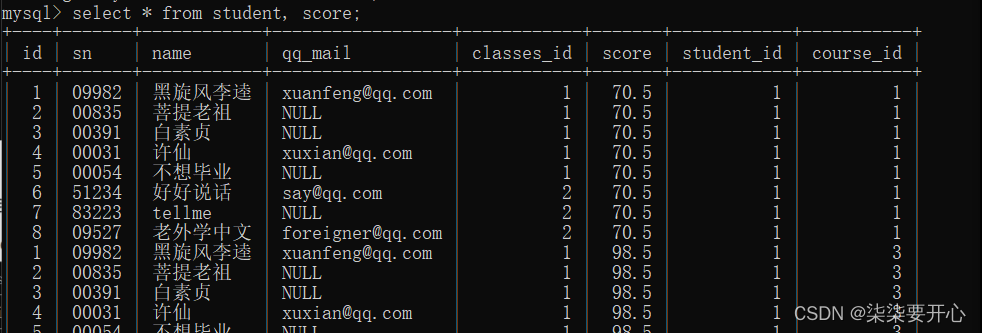
查询所有同学的总成绩,及同学的个人信息
此时同学成绩是按照 行 来组织的
此处就是多行数据进行嘉禾,使用聚合函数 sum
还需要按照同学进行分组
基于多表查询和聚合查询综合运用
- 先进行笛卡尔积
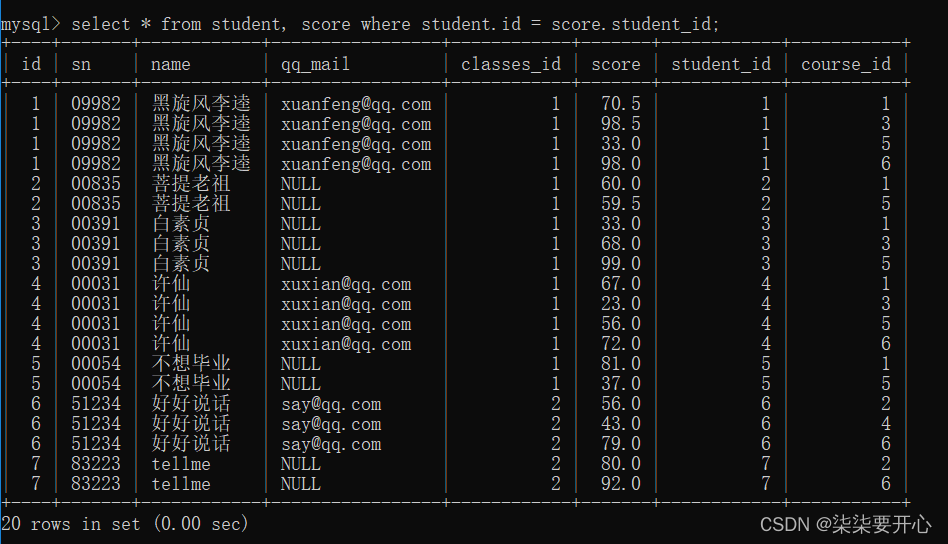
- 指定连接条件
student.id = score.student_id
- 精简列
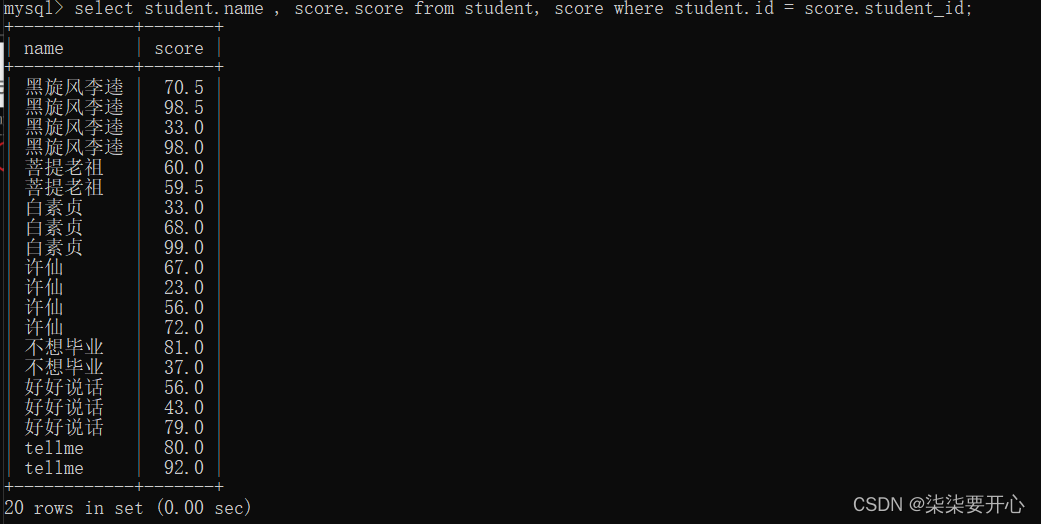
- 针对上述结果,再进行 group by 聚合查询
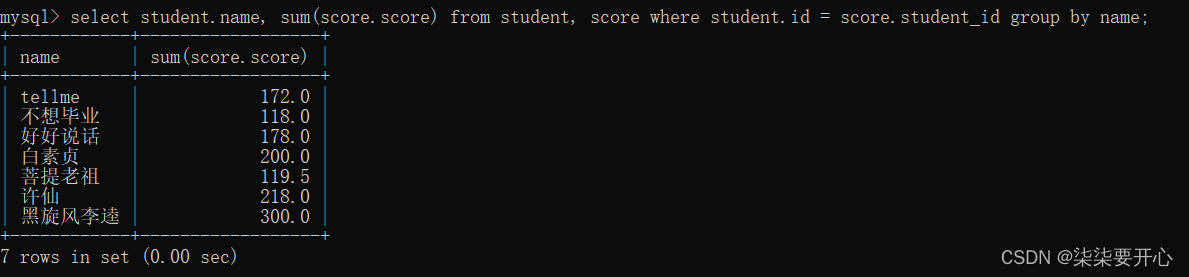
列出所有同学,每门课程名字,和分数
这包含了三张表(学生表,课程表,分数表)
- 先进行笛卡尔积
三张表的笛卡尔积得到的结果非常多
因此,如果进行数据大的表进行笛卡尔积(多表查询),就会产生大量的临时结果,这个工程是非常消耗时间的
如果多表产需涉及到的表数目比较多的时候,此时,sql 就会非常复杂,可读性也大大降低了
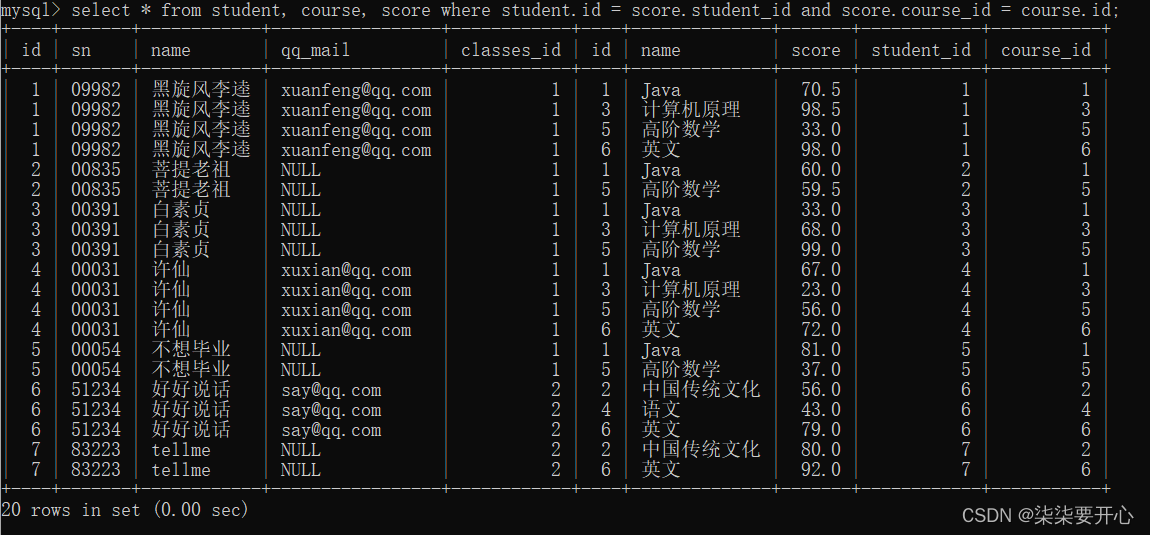
- 指定连接条件筛选数据
三个表,涉及到两个连接条件
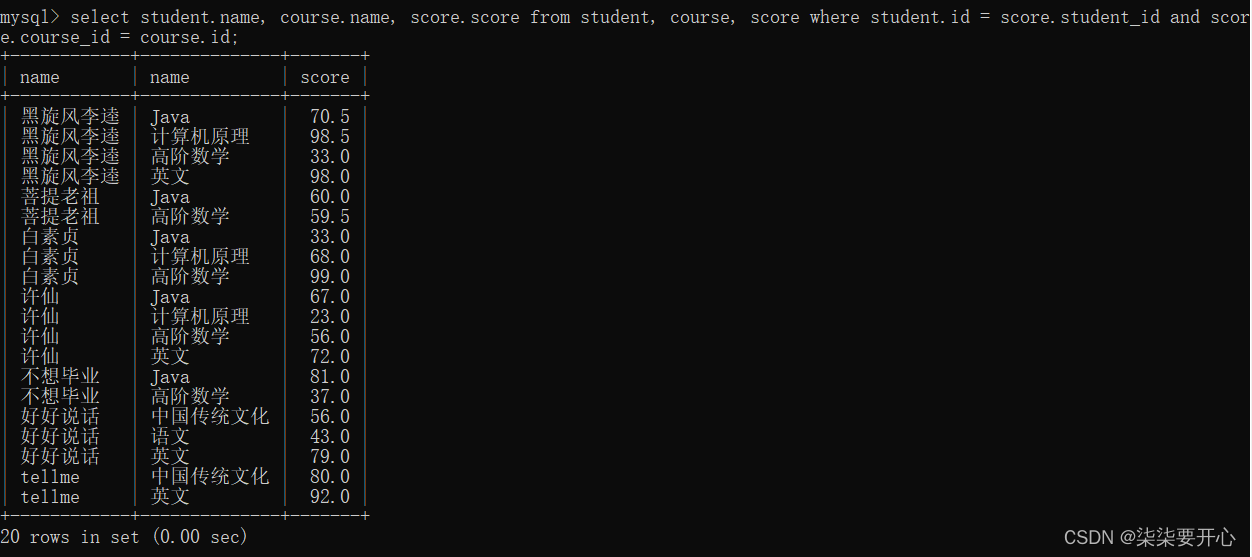
- 精简列
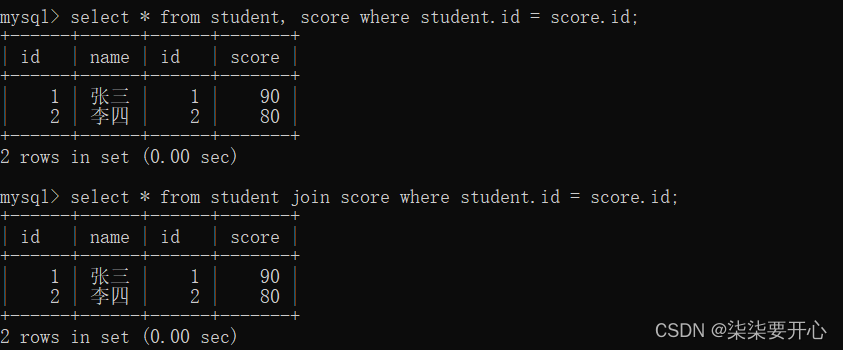
5、内连接
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
6、外连接
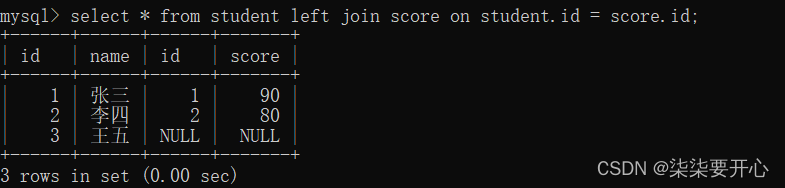
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
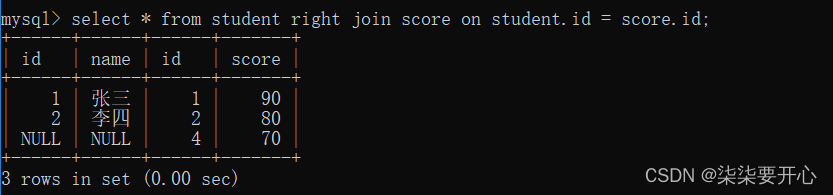
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
- 左外连接
- 右外连接
7、自连接
自连接是指在同一张表连接自身进行查询
- 显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
要把行转换成列,自己和自己笛卡尔积即可
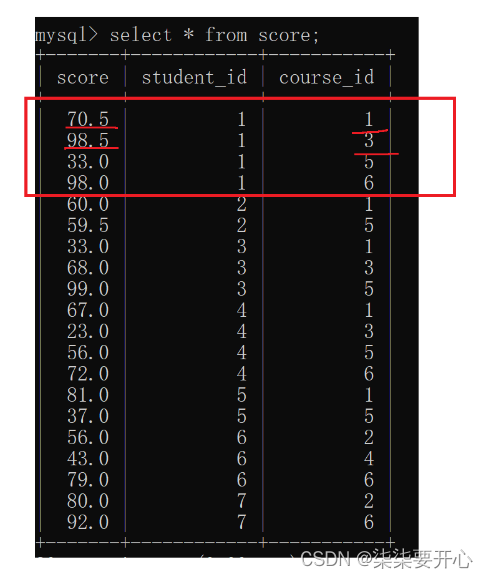
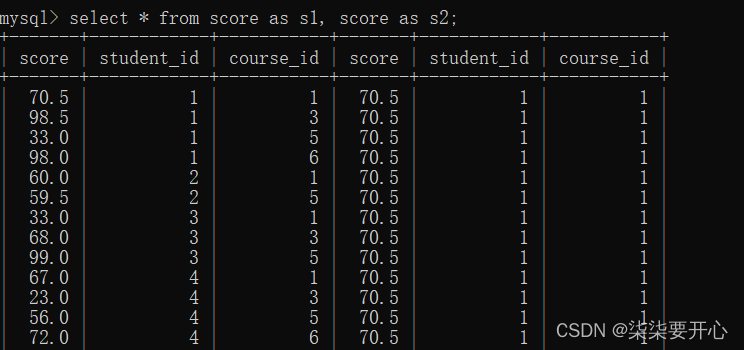
这里根据学生信息筛选
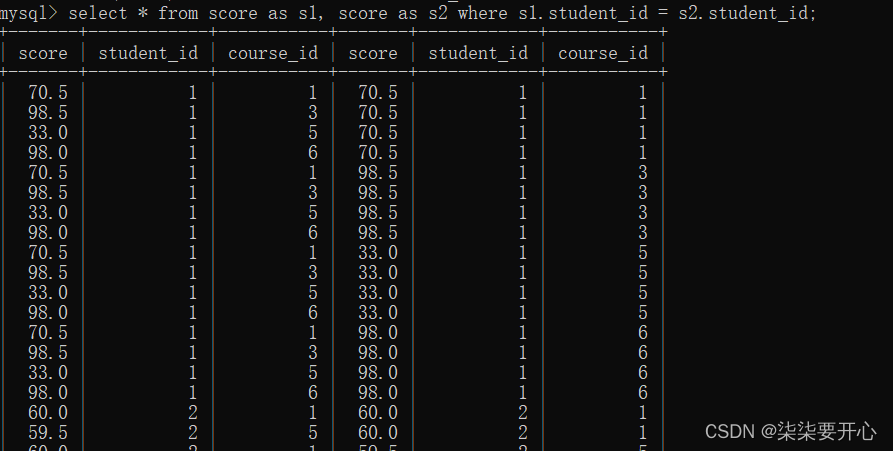


如果想要学生姓名,就可以那上述表和学生表进行笛卡尔积
8、子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询:返回一行记录的子查询
查询与“不想毕业” 同学的同班同学:

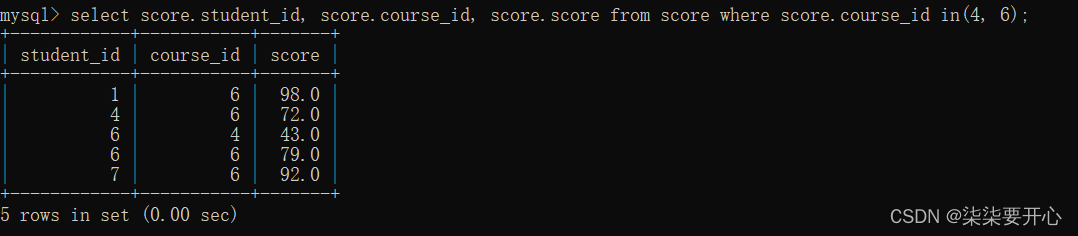
多行子查询:返回多行记录的子查询
查询“语文”或“英文”课程的成绩信息

- [NOT] IN关键字
9、合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。
使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致
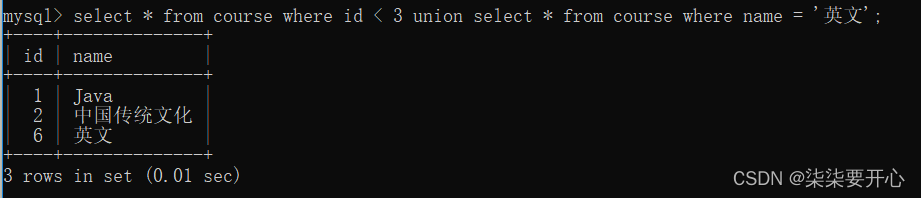
这里 union 允许把两个不同的表,查询结合合并在一起
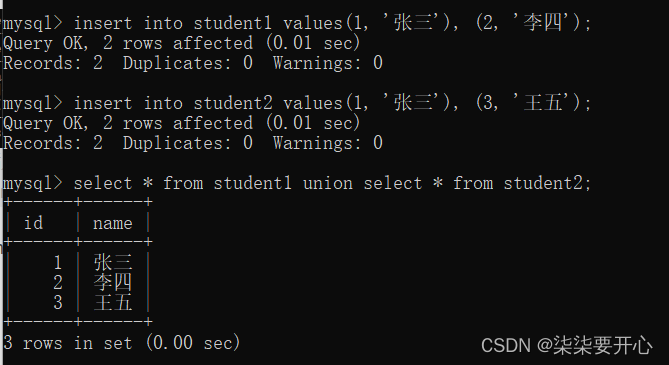
在合并的时候,是会去重的
如果不想去重,使用 union all







![[ruby on rails] ruby使用vscode做开发](https://img-blog.csdnimg.cn/direct/40aea98db16944baa4f5ba521698d97d.png)