文章目录
5.14 理解转置卷积与棋盘效应
5.14.1 标准卷积
5.14.2 转置卷积
5.15 卷积神经网络的参数设置
5.16 提高卷积神经网络的泛化能力
5.17 卷积神经网络在不同领域的应用
5.17 .1 联系
5.17.2 区别
5.14 理解转置卷积与棋盘效应
5.14.1 标准卷积
在理解转置卷积之前,需要先理解标准卷积的运算方式。
首先给出一个输入输出结果。

那是怎样计算的呢?
卷积的时候需要对卷积核进行180的旋转,同时卷积核中心与需计算的图像像素对齐,输出结构为中心对齐像素的一个新的像素值,计算例子如下:

这样计算出左上角(即第一行第一列)像素的卷积后像素值。
给出一个更直观的例子,从左到右看,原像素经过卷积由1变成-8。

通过滑动卷积核,就可以得到整张图片的卷积结果。
5.14.2 转置卷积
图像的deconvolution过程如下:

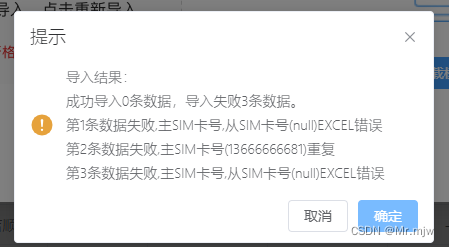
输入:,卷积核:
,滑动步长:3,输出
。
过程如下:
输入图片每个像素进行一次full卷积,根据full卷积大小计算可以知道每个像素的卷积后大小为1+4-1=4,即大小的特征图,输入有4个像素,所以4个
的特征图。
将4个特征图进行步长为3的相加;输出的位置和输入的位置相同。步长为3是指每隔3个像素进行相加,重叠部分进行相加,即输出的第1行第4列是由红色特征图的第一行第四列与绿色特征图的第一行第一列相加得到,其他如此类推。
可以看出反卷积的大小是由卷积核大小与滑动步长决定,in是输入大小,k是卷积核大小,s是滑动步长,out是输出大小,得到out=(in - 1)*s + k,上图过程就是,(2-1)*3 + 4=7。
5.15 卷积神经网络的参数设置
卷积神经网络中常见的参数在其他类型的神经网络中也是类似的,但是参数的设置还得结合具体的任务才能设置在合理的范围,具体的参数列表如表5.8所示。
| 参数名 | 常见设置 | 参数说明 |
|---|---|---|
| 学习率 (Learning Rate) | 反向传播网络中更新权值矩阵的步长,在一些常见的网络中会在固定迭代次数或模型不再收敛后对学习率进行指数下降(如 | |
| 批次大小 (Batch Size) | 批次大小指定一次性流入模型的数据样本个数,根据任务和计算性能限制判断实际取值,在一些图像任务中往往由于计算性能和存储容量限制只能选取较小的值。在相同迭代次数的前提下,数值越大模型越稳定,泛化能力越强,损失值曲线越平滑,模型也更快地收敛,但是每次迭代需要花费更多的时间。 | |
| 数据轮次 (Epoch) | 数据轮次是指定所有训练数据在模型中训练的次数,根据数据集规模和分别情况会设置不同的值。当模型较为简单或训练数据规模较小时,通常轮次不宜过高,否则模型容易过拟合;模型较为复杂或训练数据规模足够大时,可适当提高数据的训练轮次。 | |
| 权重衰减系数 (Weight Decay) | 模型训练过程中反向传播权值更新的权重衰减值 |
5.16 提高卷积神经网络的泛化能力
卷积神经网络与其他类型的神经网络类似,在采用反向传播进行训练的过程中比较依赖输入的数据分布,当数据分布较为极端的情况下容易导致模型欠拟合或过拟合,表5.9记录了提高卷积网络泛化能力的方法。
| 方法 | 说明 |
|---|---|
| 使用更多数据 | 在有条件的前提下,尽可能多地获取训练数据是最理想的方法,更多的数据可以让模型得到充分的学习,也更容易提高泛化能力。 |
| 使用更大批次 | 在相同迭代次数和学习率的条件下,每批次采用更多的数据将有助于模型更好的学习到正确的模式,模型输出结果也会更加稳定。 |
| 调整数据分布 | 大多数场景下的数据分布是不均匀的,模型过多地学习某类数据容易导致其输出结果偏向于该类型的数据,此时通过调整输入的数据分布可以一定程度提高泛化能力。 |
| 调整目标函数 | 在某些情况下,目标函数的选择会影响模型的泛化能力,如目标函数 |
| 调整网络结构 | 在浅层卷积神经网络中,参数量较少往往使模型的泛化能力不足而导致欠拟合,此时通过叠加卷积层可以有效地增加网络参数,提高模型的表达能力;在深层卷积网络中,若没有充足的训练数据则容易导致模型过拟合,此时通过简化网络结构减少卷积层数可以起到提高模型泛化能力的作用。 |
| 数据增强 | 数据增强又叫数据增广,在有限数据的前提下通过平移、旋转、加噪声等一系列变换来增加训练数据,同类数据的表现形式也变得更多样,有助于模型提高泛化能力,需要注意的是数据变化应尽可能不破坏元数数据的主体特征(如在图像分类任务中对图像进行裁剪时不能将分类主体目标裁出边界)。 |
| 权值正则化 | 权值正则化就是通常意义上的正则化,一般是在损失函数中添加一项权重矩阵的正则项作为惩罚项,用来惩罚损失值较小时网络权重过大的情况,此时往往是网络权值过拟合了数据样本。 |
| 屏蔽网络节点 | 该方法可以认为是网络结构上的正则化,通过随机性地屏蔽某些神经元的输出让剩余激活的神经元作用,可以使模型的容错性更强。 |
对大多数神经网络模型同样通用。
5.17 卷积神经网络在不同领域的应用
卷积神经网络中的卷积操作是其关键组成,而卷积操作只是一种数学运算方式,实际上对不同类型的数值表示数据都是通用的,尽管这些数值可能表示的是图像像素值、文本序列中单个字符或是语音片段中单字的音频。只要使原始数据能够得到有效地数值化表示,卷积神经网络能够在不同的领域中得到应用,要关注的是如何将卷积的特性更好地在不同领域中应用,如表5.10所示。
| 应用领域 | 输入数据图示 | 说明 |
|---|---|---|
| 图像处理 |  | 卷积神经网络在图像处理领域有非常广泛的应用,这是因为图像数据本身具有局部完整性 |
| 自然语言处理 |  | |
| 语音处理 |  |
5.17 .1 联系
自然语言处理是对一维信号(词序列)做操作。计算机视觉是对二维(图像)或三维(视频流)信号做操作。
5.17.2 区别
自然语言处理的输入数据通常是离散取值(例如表示一个单词或字母通常表示为词典中的one hot向量),计算机视觉则是连续取值(比如归一化到0,1之间的灰度值)。CNN有两个主要特点,区域不变性(location invariance)和组合性(Compositionality)。
- 区域不变性:滤波器在每层的输入向量(图像)上滑动,检测的是局部信息,然后通过pooling取最大值或均值。pooling这步综合了局部特征,失去了每个特征的位置信息。这很适合基于图像的任务,比如要判断一幅画里有没有猫这种生物,你可能不会去关心这只猫出现在图像的哪个区域。但是在NLP里,词语在句子或是段落里出现的位置,顺序,都是很重要的信息。
- 局部组合性:CNN中,每个滤波器都把较低层的局部特征组合生成较高层的更全局化的特征。这在CV里很好理解,像素组合成边缘,边缘生成形状,最后把各种形状组合起来得到复杂的物体表达。在语言里,当然也有类似的组合关系,但是远不如图像来的直接。而且在图像里,相邻像素必须是相关的,相邻的词语却未必相关。