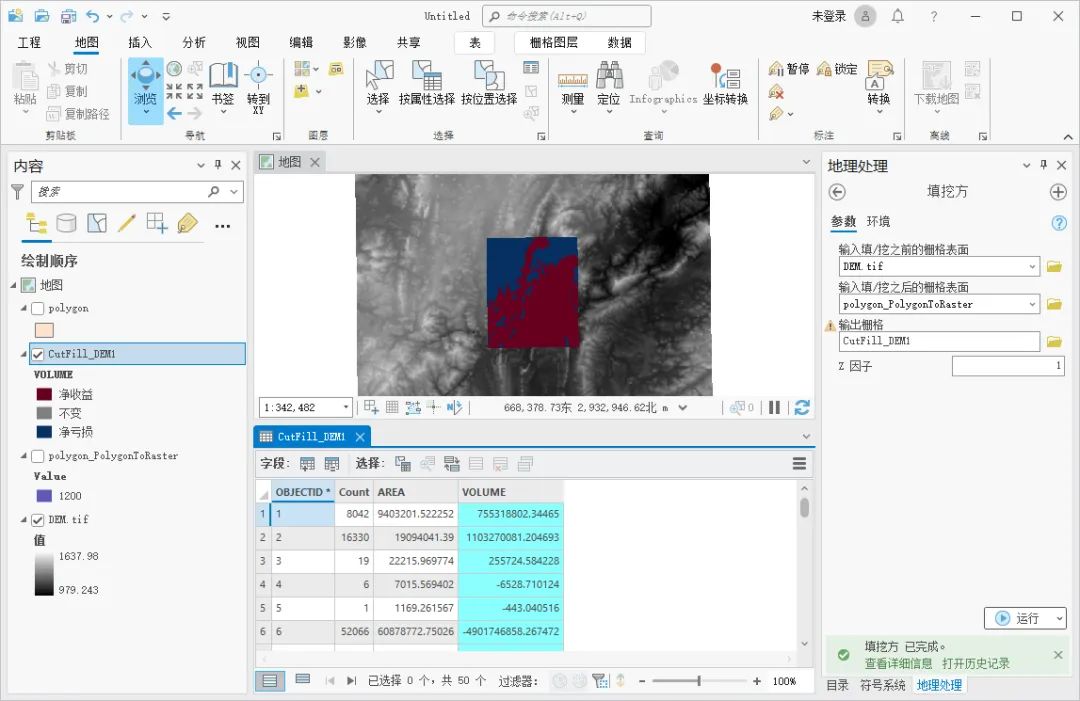
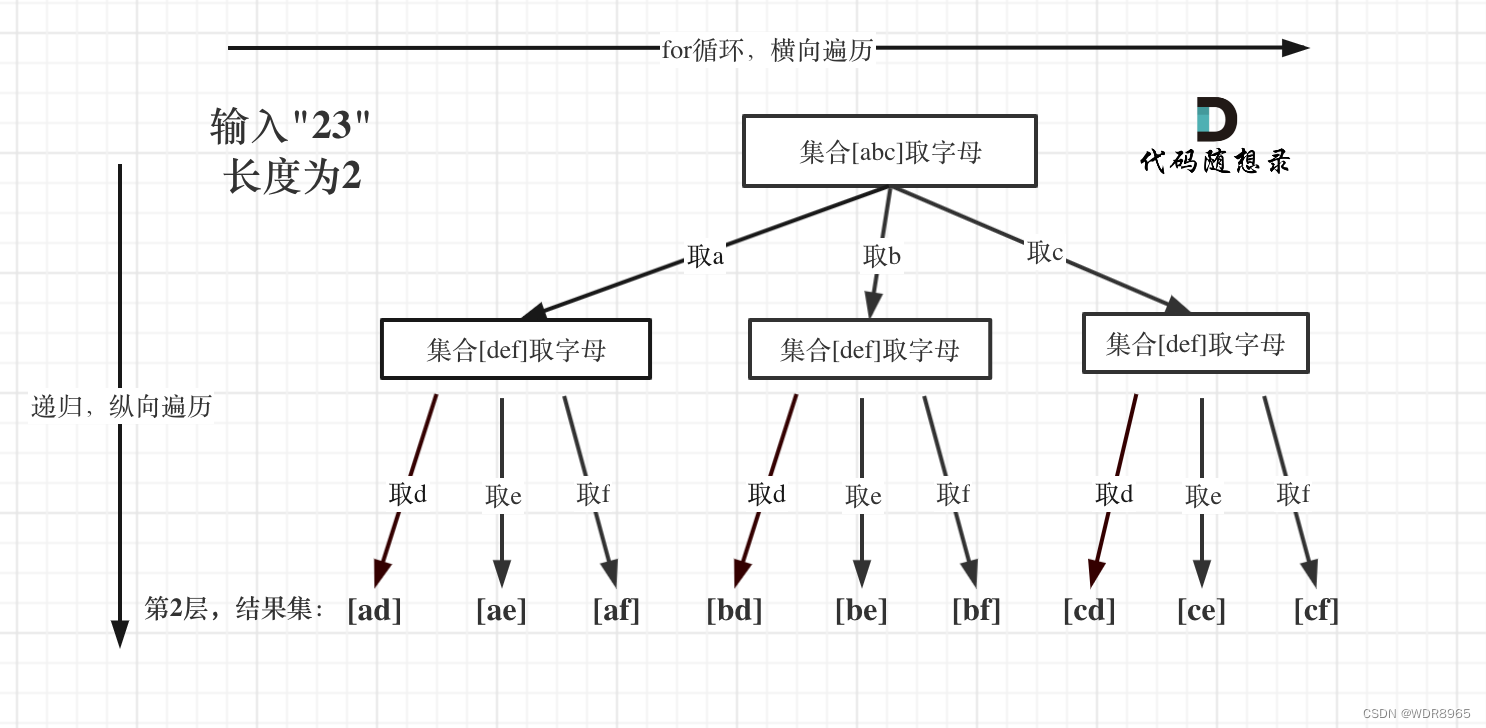
序列:存储多个值的连续空间,每个值对应一个编号————索引
包括:列表、元组、集合和字典
相加操作
s1="桂林山水"
s2='山水甲天下'
print(s1+s2)#直接相加得到新的字符串
print('_____________________________')
print((s1+s2)*5,sep="")#重复打印的乘法计算
in和not in操作:判断序列是否存在指定元素,返回值为bool值
s1="桂林山水"
s2='山水甲天下'
print("桂林"in s1)#判断“桂林”是否存在于s1中
print('北京'in s2)
m
s1="桂林山水"
s2='山水甲天下'
print(s1.index("林"))#查询指定元素在列表中的索引
print(s1.index('北京'))#如果元素在序列中不存在就会报错
s1="桂林山水"
s2='山水甲天下'
print(s1.count("桂林"))#统计指定元素在序列中出现的个数
一、列表
列表时可以改变的序列类型
创建:(1)直接创建listname=[A,B,C,..........]
(2)使用内置函数list()创建,listname=list(序列)
删除:del listname
清除列表:listname.clear()
列表的枚举:enumrate()
s1="桂林山水"
s2='山水甲天下'
s3=s1+s2
for x,y in enumerate(s3,start=0):#枚举前面的变量为列表的索引(默认值为0),后面是遍历列表的元素,
print(x,"---->",y)#默认的start的值为0
list=[1,2,3,4,5,6,7,8,9]#定义和初始化一个列表
for i in range(len(list)):#从0开始依次遍历
print(list[i],end='')
for x in range(-9,0):#反向打印
print(list[x])
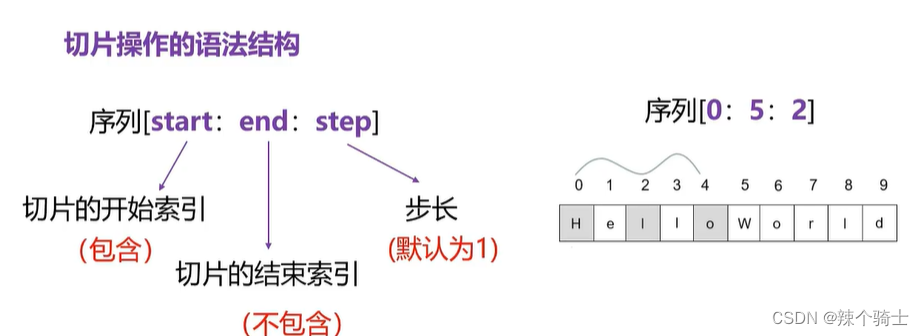
切片:对列表进行操作得到另一列表
list=[1,2,3,4,5,6,7,8,9]#定义和初始化一个列表
for i in range(len(list)):#从0开始依次遍历
print(list[i],end='')
print()
a=list[0:8:2]#list[start:end:step]获得一个新的列表从list[0]开始,list[8]结束但不包括
b=list[::-1]#从反向开始操作,等到回文
print(a)
print(b)
列表的特有操作
(1)listname.append(a)增加元素到列表末尾
listname=list([1,2,5,6,9])
listname.append(666)#增加666到列表末尾
print(listname)

(2)listname.insert(index,x)在列表第index位置增加元素x
listname=list([1,2,5,6,9])
listname.insert(0,999)
print(listname)

(3)listname.clear()清除列表中的所有元素
listname=list([1,2,5,6,9])
listname.clear()
print(listname)

(4)listname.pop(index)弹出索引的元素,并得到返回值
listname=list([1,2,5,6,9])
l=listname.pop(1)#用l接受弹出的元素
print(listname)
print(l)

(5)listname.remove(a)移除特定元素
listname=list([1,2,5,6,9])
listname.remove(9)
print(listname)

(6)listname.reverse()将列表中的元素翻转
listname=list([1,2,5,6,9888])
listname.reverse()
print(listname)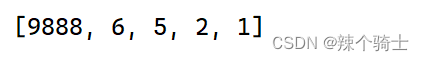
(7)listname.copy()拷贝所有元素,并生成一个新列表
listname=list([1,2,5,6,9888])
a=listname.copy()
print(listname)
print(a)
(8)列表的排序操作
listname=list([15,25,5,68,98])
listname.sort(reverse=False)#默认值为Falsse,表示顺序排序
print(listname)
listname.sort(reverse=True)#倒序排序
print(listname)
a=sorted(listname,reverse=False)#采用内置函数sorted()返回一个新的列表
print(a)

二、元组
元组是内置不可变序列,没有增删改操作
创建:(1)直接创建 tuplename=(a,b,c,.........)#如果元组只有一个元素,逗号不能省
(2)使用内置函数tuple() tuplename=tuple(序列)
删除:del tuplename
tuplename=tuple('python')
print(tuplename)
print(type(tuplename))
元组支持切片操作,得到一个新的元组
tuplename=tuple('python')
t=tuplename[::-1]
print(t)

三、字典类型
字典:根据一个信息去查找利另一个信息的方式构成键值对
字典的储存方式是无序的(采用哈希存储),字典中的键必须唯一,不能重复;键也要求是不可变序列(字符串,整数,浮点数,元组)

创建:
d={'a':11,"b":55}#直接创建冒号连接
x=dict(a=100,b=888)#内置函数用等号连接
print(d)
print(x)
s=[1,2,3]
s1=['p','p,','x']
zip(s,s1)#生成一个映射对象
print(dict(zip(s,s1)))#将对象重新转换为字典类型

查找:根据键查找值
dictname={'小名':100,'小红':95,'小刚':98}#创建一个字典
print(dictname)
#两种查询方法
print(dictname["小名"])#使用d(key)方式查找
print(dictname.get("小刚"))#d.get(key)方式查找
print(dictname.get("小王"))#如果没有key时返回None,可以修改默认值:d.get(key,'不存在')
print(dictname["小王"])#没有key会

遍历:
dictname.itemes()返回字典中的所有键值对的列表
d={1:100,2:420,3:646}
for x,y in d.items():#当变量为两个时,分别输出键和值
print(x,y)
for i in d.items():#当变量为一个时,说出键值对组成的元组
print(i)

分别遍历字典的键和值:
dictname={'小名':100,'小红':95,'小刚':98}#创建一个字典
print(dictname)
a=dictname.items()#dictname.items()会返回一个键值对的迭代器
print(a)
for i,x in a:
print(i,'---->',x)
字典的相关操作:
(1)添加元素:
dictname={'小名':100,'小红':95,'小刚':98}#创建一个字典
print(dictname)
dictname['小王']=97#dictname[key]=value表示添加一个键值对
a=dictname.items()#dictname.items()会返回一个键值对的迭代器
print(a)
for i,x in a:
print(i,'---->',x)
(2)获得键值对
dictname={'小名':100,'小红':95,'小刚':98}#创建一个字典
#查看键
key=(dictname.keys())#获得所有键组成的迭代器
print(key)
value=dictname.values()
print(value)#获得所有值组成的迭代器
(3)删除dictname.pop(key)并返回对应的值value,dictname.popitme()随机删除元素
(4)清空dictname.clear()清空字典
四、集合
集合是一个无序不重复的元素序列(不能存储字典和列表没有)
创建:
直接创建:setname={a,b,c,.......}
函数创建:setname=set(可迭代对象)