基本使用
- Elasticsearch(简称ES): 是一个开源的高扩展的分布式全文搜索引擎
Docker安装Elasticsearch1
version: "3.1"
services:
elasticsearch:
image: elasticsearch:7.13.3
container_name: elasticsearch
privileged: true
environment:
- "cluster.name=elasticsearch" #设置集群名称为elasticsearch
- "discovery.type=single-node" #以单一节点模式启动
- "ES_JAVA_OPTS=-Xms512m -Xmx1096m" #设置使用jvm内存大小
- bootstrap.memory_lock=true
volumes:
- ./es/plugins:/opt/docker/elasticsearch/plugins #插件文件挂载
- ./es/data:/opt/docker/elasticsearch/data:rw #数据文件挂载
- ./es/logs:/opt/docker/elasticsearch/logs:rw
ports:
- 9200:9200
- 9300:9300
deploy:
resources:
limits:
cpus: "2"
memory: 1000M
reservations:
memory: 200M
kibana:
image: kibana:7.13.3
container_name: kibana
depends_on:
- elasticsearch #kibana在elasticsearch启动之后再启动
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200 #设置访问elasticsearch的地址
I18N_LOCALE: zh-CN
ports:
- 5601:5601
然后启动
docker-compose up -d
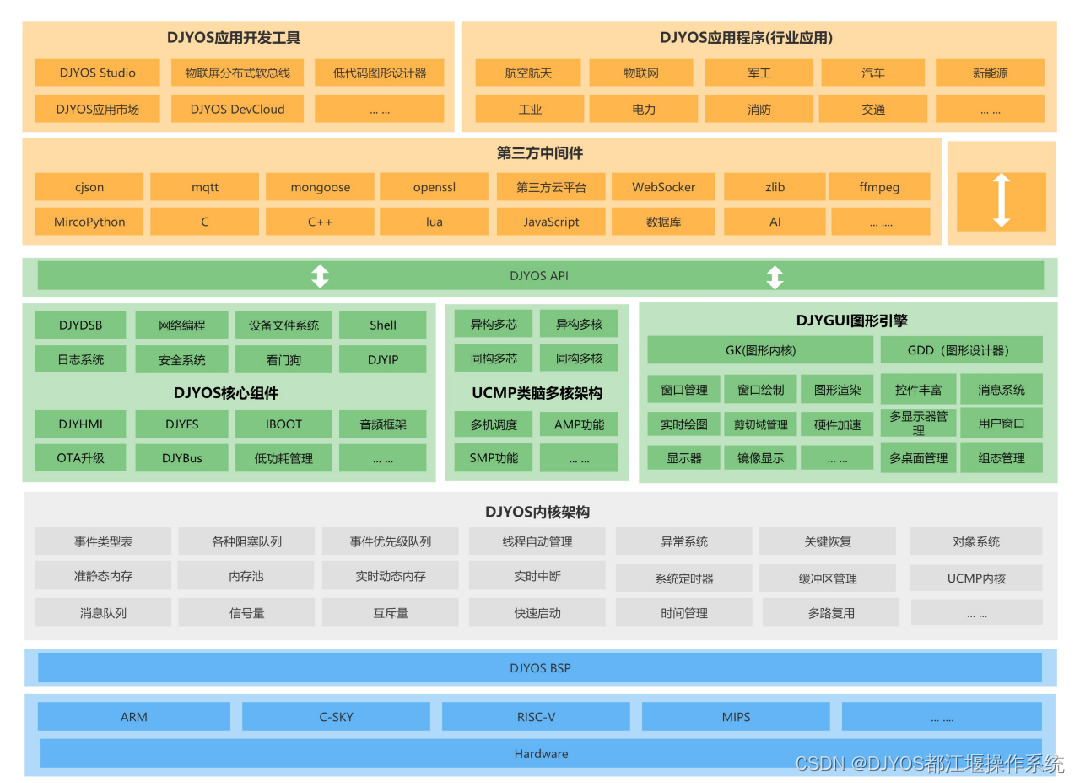
系统架构
- 数据格式: Elasticsearch是面向文档型的数据库, 一条数据就是一个文档, Elasticsearch与MySQL的对应如下图
-

-
因为Elasticsearch更强调全文索引, 因此在新版本中, Type的概念已经被移除
-
基本使用
环境准备
url = "http://server.passnight.local:9200"
import requests
索引操作
创建索引
In [5]: requests.put(f"{url}/shopping").text
Out[5]: '{"acknowledged":true,"shards_acknowledged":true,"index":"shopping"}'
# put请求有幂等性, 不可以重复请求
In [8]: requests.put(f"{url}/shopping").json()
Out[8]:
{'error': {'root_cause': [{'type': 'resource_already_exists_exception',
'reason': 'index [shopping/Pxr9PA93ThaGmVHeYsbcOQ] already exists',
'index_uuid': 'Pxr9PA93ThaGmVHeYsbcOQ',
'index': 'shopping'}],
'type': 'resource_already_exists_exception',
'reason': 'index [shopping/Pxr9PA93ThaGmVHeYsbcOQ] already exists',
'index_uuid': 'Pxr9PA93ThaGmVHeYsbcOQ',
'index': 'shopping'},
'status': 400}
In [3]: requests.delete(f"{url}/shopping").json()
Out[3]: {'acknowledged': True}
文档操作
创建文档
In [15]: requests.post(f"{url}/shopping/_doc", json={"title":"华为手机", "category":"华为","price":8848}).json()
Out[15]:
{'_index': 'shopping',
'_type': '_doc',
'_id': 'R6kgxIwBJszNCAI73RvT',
'_version': 1,
'result': 'created',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 0,
'_primary_term': 1}
# 创建文档, 并自定义id
In [16]: requests.post(f"{url}/shopping/_doc/1", json={"title":"华为手机", "category":"华为","price":8848}).json()
Out[16]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 1,
'result': 'created',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 1,
'_primary_term': 1}
查询文档
In [20]: requests.get(f"{url}/shopping/_doc/1").json()
Out[20]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 1,
'_seq_no': 1,
'_primary_term': 1,
'found': True,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}}
# 对于不存在的数据, 会返回{"found": false}
In [21]: requests.get(f"{url}/shopping/_doc/no-exists").json()
Out[21]: {'_index': 'shopping', '_type': '_doc', '_id': 'no-exists', 'found': False}
#可以通过`_search`来查询所有数据
In [22]: requests.get(f"{url}/shopping/_doc/_search").json()
Out[22]:
{'took': 530,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 2, 'relation': 'eq'},
'max_score': 1.0,
'hits': [{'_index': 'shopping',
'_type': '_doc',
'_id': 'R6kgxIwBJszNCAI73RvT',
'_score': 1.0,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}},
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_score': 1.0,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}}]}}
修改文档
修改文档分为完全修改和部分修改
# 全量修改
In [23]: requests.put(f"{url}/shopping/_doc/1", json={"title":"华为手机", "category":"华为","price":18848}).json()
Out[23]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 2,
'result': 'updated',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 2,
'_primary_term': 1}
# 查询可以发现数据已经发生改变了
In [24]: requests.get(f"{url}/shopping/_doc/1").json()
Out[24]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 2,
'_seq_no': 2,
'_primary_term': 1,
'found': True,
'_source': {'title': '华为手机', 'category': '华为', 'price': 18848}}
# 通过`post`请求`_update`路径可以实现局部修改
In [25]: requests.post(f"{url}/shopping/_update/1", json={"doc":{"price":8848}}).json()
Out[25]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 3,
'result': 'updated',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 3,
'_primary_term': 1}
In [26]: requests.get(f"{url}/shopping/_doc/1").json()
Out[26]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 3,
'_seq_no': 3,
'_primary_term': 1,
'found': True,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}}
删除文档
In [27]: requests.delete(f"{url}/shopping/_doc/1").json()
Out[27]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 4,
'result': 'deleted',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 4,
'_primary_term': 1}
# 第二次删除显示`not_found`
In [28]: requests.delete(f"{url}/shopping/_doc/1").json()
Out[28]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 5,
'result': 'not_found',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 5,
'_primary_term': 1}
查询
基本查询
REST风格可以通过get查询
In [9]: requests.get(f"{url}/shopping").json()
Out[9]:
{'shopping': {'aliases': {},
'mappings': {},
'settings': {'index': {'routing': {'allocation': {'include': {'_tier_preference': 'data_content'}}},
'number_of_shards': '1',
'provided_name': 'shopping',
'creation_date': '1704096812988',
'number_of_replicas': '1',
'uuid': 'Pxr9PA93ThaGmVHeYsbcOQ',
'version': {'created': '7130399'}}}}}
# 如果要查询所有索引, 可以通过以下地址
In [10]: requests.get(f"{url}/_cat/indices?v").text
Out[10]: 'health status index uuid pri rep docs.count docs.deleted store.size pri.store.size\ngreen open .kibana_7.13.3_001 zyqQO8vfQHuf5sRKb5lhOw 1 0 14 15 2.1mb 2.1mb\ngreen open .kibana-event-log-7.13.3-000001 ZSaKH8K4Tf2-sREY-W2pAQ 1 0 2 0 11kb 11kb\ngreen open .apm-custom-link DcnQnCxfQievZaqAS5pOFQ 1 0 0 0 208b 208b\ngreen open .apm-agent-configuration T8gVN9U7RgSUEru5b3CnoA 1 0 0 0 208b 208b\nyellow open shopping Pxr9PA93ThaGmVHeYsbcOQ 1 1 0 0 208b 208b\ngreen open .tasks ZMXu_QfQTymuCAkC0YVzoA 1 0 2 0 7.8kb 7.8kb\ngreen open .kibana_task_manager_7.13.3_001 r3uPanyMR6eW-eVePJpeWA 1 0 10 395 169.9kb 169.9kb\n'
# 查询`category=华为`的数据
In [48]: requests.get(f"{url}/shopping/_search", params={"q":"category:华为"}).json()
Out[48]:
{'took': 2,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 2, 'relation': 'eq'},
'max_score': 0.36464313,
'hits': [{'_index': 'shopping',
'_type': '_doc',
'_id': 'R6kgxIwBJszNCAI73RvT',
'_score': 0.36464313,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}},
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_score': 0.36464313,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}}]}}
# 查询不仅可以放在query parameter中, 还可以放在body中
In [53]: requests.get(f"{url}/shopping/_search", json={"query":{"match": {"category": "华为"}}}).json()
Out[53]:
{'took': 0,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 2, 'relation': 'eq'},
'max_score': 0.36464313,
'hits': [{'_index': 'shopping',
'_type': '_doc',
'_id': 'R6kgxIwBJszNCAI73RvT',
'_score': 0.36464313,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}},
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_score': 0.36464313,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}}]}}
分页查询
In [59]: requests.get(f"{url}/shopping/_search", json={"query":{"match_all": {}}, "from": 0, "size": 1}).json()
Out[59]:
{'took': 0,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 2, 'relation': 'eq'},
'max_score': 1.0,
'hits': [{'_index': 'shopping',
'_type': '_doc',
'_id': 'R6kgxIwBJszNCAI73RvT',
'_score': 1.0,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}}]}}
列投影
In [61]: requests.get(f"{url}/shopping/_search", json={"query":{"match_all": {}}, "_source": ["title"]}).json()
Out[61]:
{'took': 0,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 2, 'relation': 'eq'},
'max_score': 1.0,
'hits': [{'_index': 'shopping',
'_type': '_doc',
'_id': 'R6kgxIwBJszNCAI73RvT',
'_score': 1.0,
'_source': {'title': '华为手机'}},
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_score': 1.0,
'_source': {'title': '华为手机'}}]}}
排序
In [62]: requests.get(f"{url}/shopping/_search", json={"query":{"match_all": {}}, "_source": ["title"], "sort": {"price"
...: : {"order": "desc"}}}).json()
Out[62]:
{'took': 0,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 2, 'relation': 'eq'},
'max_score': None,
'hits': [{'_index': 'shopping',
'_type': '_doc',
'_id': 'R6kgxIwBJszNCAI73RvT',
'_score': None,
'_source': {'title': '华为手机'},
'sort': [8848]},
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_score': None,
'_source': {'title': '华为手机'},
'sort': [8848]}]}}
复杂条件查询
In [80]: queryParams = {
...: "query": {
...: "bool": {
...: "must": [
...: {
...: "match": {
...: "category": "华为"
...: }
...: }
...: ]
...: }
...: }
...: }
...:
In [81]: requests.get(f"{url}/shopping/_search", json=queryParams).json()
Out[81]:
{'took': 0,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 2, 'relation': 'eq'},
'max_score': 0.36464313,
'hits': [{'_index': 'shopping',
'_type': '_doc',
'_id': 'R6kgxIwBJszNCAI73RvT',
'_score': 0.36464313,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}},
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_score': 0.36464313,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}}]}}
分组查询
In [73]: requests.get(f"{url}/shopping/_search", json=queryParams).json()
Out[73]:
{'took': 1,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 2, 'relation': 'eq'},
'max_score': 1.0,
'hits': [{'_index': 'shopping',
'_type': '_doc',
'_id': 'R6kgxIwBJszNCAI73RvT',
'_score': 1.0,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}},
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_score': 1.0,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848}}]},
'aggregations': {'price_group': {'doc_count_error_upper_bound': 0,
'sum_other_doc_count': 0,
'buckets': [{'key': 8848, 'doc_count': 2}]}}}
映射
创建people索引
In [106]: requests.put(f"{url}/people").json()
Out[106]: {'acknowledged': True, 'shards_acknowledged': True, 'index': 'people'}
创建mapping
In [98]: body = {
...: "properties": {
...: "name": {
...: "type": "text",
...: "index": True
...: },
...: "sex": {
...: "type": "keyword", # 不能分词, 需要完整匹配
...: "index": True
...: },
...: "tel": {
...: "type": "keyword",
...: "index": False # 不创建索引, 因此不能查询
...: }
...: }
...: }
In [86]: requests.put(f"{url}/people/_mapping", json=body).text
Out[86]: '{"acknowledged":true}'
# 修改完之后就能查到了
In [109]: requests.get(f"{url}/people/_mapping").json()
Out[109]:
{'people': {'mappings': {'properties': {'name': {'type': 'text'},
'sex': {'type': 'keyword'},
'tel': {'type': 'keyword', 'index': False}}}}}
之后添加文档
In [110]: requests.post(f"{url}/people/_create/1", json={"name":"小米", "sex": "男", "tel":12345678}).json()
Out[110]:
{'_index': 'people',
'_type': '_doc',
'_id': '1',
'_version': 1,
'result': 'created',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 0,
'_primary_term': 1}
查询刚刚添加的数据
# 查询`小`这一个字可以查到; 说明`小米`被分词了
In [111]: requests.get(f"{url}/people/_search", json={"query":{"match":{"name":"小华为"}}}).json()
Out[111]:
{'took': 257,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 1, 'relation': 'eq'},
'max_score': 0.2876821,
'hits': [{'_index': 'people',
'_type': '_doc',
'_id': '1',
'_score': 0.2876821,
'_source': {'name': '小米', 'sex': '男', 'tel': 12345678}}]}}
# keyword标注的没有分词效果, 因此`男性`不能匹配`男`
In [113]: requests.get(f"{url}/people/_search", json={"query":{"match":{"sex":"男性"}}}).json()
Out[113]:
{'took': 0,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 0, 'relation': 'eq'},
'max_score': None,
'hits': []}}
In [114]: requests.get(f"{url}/people/_search", json={"query":{"match":{"sex":"男"}}}).json()
Out[114]:
{'took': 0,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 1, 'relation': 'eq'},
'max_score': 0.2876821,
'hits': [{'_index': 'people',
'_type': '_doc',
'_id': '1',
'_score': 0.2876821,
'_source': {'name': '小米', 'sex': '男', 'tel': 12345678}}]}}
#
而无索引的数据不能查询
In [115]: requests.get(f"{url}/people/_search", json={"query":{"match":{"tel":12345678}}}).json()
Out[115]:
{'error': {'root_cause': [{'type': 'query_shard_exception',
'reason': 'failed to create query: Cannot search on field [tel] since it is not indexed.',
'index_uuid': 'qy9xGKlDTkWf7WBYhwoxaA',
'index': 'people'}],
'type': 'search_phase_execution_exception',
'reason': 'all shards failed',
'phase': 'query',
'grouped': True,
'failed_shards': [{'shard': 0,
'index': 'people',
'node': '06gxMBq9QO6_Q5qg0ip-KA',
'reason': {'type': 'query_shard_exception',
'reason': 'failed to create query: Cannot search on field [tel] since it is not indexed.',
'index_uuid': 'qy9xGKlDTkWf7WBYhwoxaA',
'index': 'people',
'caused_by': {'type': 'illegal_argument_exception',
'reason': 'Cannot search on field [tel] since it is not indexed.'}}}]},
'status': 400}
java API
索引操作
环境准备
private final static RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("server.passnight.local", 9200, "http")
));
@AfterClass
public static void tearDownClass() throws IOException {
client.close();
}
增删查索引
/**
* 增加索引
*/
@Test
public void createIndex() throws IOException {
CreateIndexResponse response = client.indices()
.create(new CreateIndexRequest("user"), RequestOptions.DEFAULT);
// 索引操作成功
Assert.assertTrue(response.isAcknowledged());
}
/**
* 查询索引
*/
@Test
public void queryIndex() throws IOException {
GetIndexResponse response = client.indices()
.get(new GetIndexRequest("user"), RequestOptions.DEFAULT);
System.out.println(response.getAliases());
System.out.println(response.getMappings());
System.out.println(response.getSettings());
}
/**
* 删除索引
*/
@Test
public void deleteIndex() throws IOException {
AcknowledgedResponse response = client.indices()
.delete(new DeleteIndexRequest("user"), RequestOptions.DEFAULT);
// 索引删除成功
Assert.assertTrue(response.isAcknowledged());
}
文档操作
环境准备
准备pojo
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
public class User {
private String name;
private String sex;
private Integer age;
}
准备session和工具
private final static RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("server.passnight.local", 9200, "http")
));
private final static ObjectMapper objectMapper = new ObjectMapper();
@AfterClass
public static void tearDownClass() throws IOException {
client.close();
}
文档增删查改
@Test
public void createIndex() throws IOException {
User user = User.builder()
.name("张三")
.age(30)
.sex("男")
.build();
// 注意, es插入数据必须转成json格式
IndexResponse response = client.index(new IndexRequest()
.index("user")
.id("1")
.source(objectMapper.writeValueAsString(user), XContentType.JSON),
RequestOptions.DEFAULT);
System.out.println(response.getResult());
}
@Test
public void updateIndex() throws IOException {
UpdateResponse response = client.update(new UpdateRequest()
.index("user")
.id("1")
.doc(Map.of("sex", "男"), XContentType.JSON),
RequestOptions.DEFAULT);
System.out.println(response.getResult());
}
@Test
public void getIndex() throws IOException {
GetResponse response = client.get(new GetRequest()
.index("user")
.id("1"),
RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
}
@Test
public void deleteIndex() throws IOException {
DeleteResponse response = client.delete(new DeleteRequest()
.index("user")
.id("1"),
RequestOptions.DEFAULT);
System.out.println(response);
}
批量增删
/**
* 批量增加
*/
@Test
public void batchInsert() throws IOException {
User user1 = User.builder()
.name("张三")
.age(30)
.sex("男")
.build();
User user2 = User.builder()
.name("李四")
.age(30)
.sex("男")
.build();
User user3 = User.builder()
.name("王五")
.age(30)
.sex("男")
.build();
// 注意, es插入数据必须转成json格式
BulkResponse response = client.bulk(new BulkRequest()
.add(new IndexRequest().index("user")
.id("1")
.source(objectMapper.writeValueAsString(user1), XContentType.JSON))
.add(new IndexRequest().index("user")
.id("2")
.source(objectMapper.writeValueAsString(user2), XContentType.JSON))
.add(new IndexRequest().index("user")
.id("3")
.source(objectMapper.writeValueAsString(user3), XContentType.JSON)),
RequestOptions.DEFAULT);
System.out.println(response.getTook());
System.out.println(Arrays.toString(response.getItems()));
}
/**
* 批量删除
*/
@Test
public void batchDelete() throws IOException {
BulkResponse response = client.bulk(new BulkRequest()
.add(new DeleteRequest().index("user")
.id("1"))
.add(new DeleteRequest().index("user")
.id("2"))
.add(new DeleteRequest().index("user")
.id("3")),
RequestOptions.DEFAULT);
System.out.println(response.getTook());
System.out.println(Arrays.toString(response.getItems()));
}
复杂查询
环境准备
private final static RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
new HttpHost("server.passnight.local", 9200, "http")
));
private final static ObjectMapper objectMapper = new ObjectMapper();
@AfterClass
public static void tearDownClass() throws IOException {
client.bulk(new BulkRequest()
.add(new DeleteRequest().index("user")
.id("1"))
.add(new DeleteRequest().index("user")
.id("2"))
.add(new DeleteRequest().index("user")
.id("3"))
.add(new DeleteRequest().index("user")
.id("4"))
.add(new DeleteRequest().index("user")
.id("5")),
RequestOptions.DEFAULT);
client.close();
}
/**
* 增加一些数据, 用于后续高级操作的测试
*/
@BeforeClass
public static void setUpClass() throws IOException {
User user1 = User.builder()
.name("张三")
.age(30)
.sex("男")
.build();
User user2 = User.builder()
.name("李四")
.age(40)
.sex("女")
.build();
User user3 = User.builder()
.name("王五")
.age(50)
.sex("男")
.build();
User user4 = User.builder()
.name("赵六")
.age(60)
.sex("女")
.build();
User user5 = User.builder()
.name("钱七")
.age(20)
.sex("男")
.build();
// 注意, es插入数据必须转成json格式
client.bulk(new BulkRequest()
.add(new IndexRequest().index("user")
.id("1")
.source(objectMapper.writeValueAsString(user1), XContentType.JSON))
.add(new IndexRequest().index("user")
.id("2")
.source(objectMapper.writeValueAsString(user2), XContentType.JSON))
.add(new IndexRequest().index("user")
.id("3")
.source(objectMapper.writeValueAsString(user3), XContentType.JSON))
.add(new IndexRequest().index("user")
.id("4")
.source(objectMapper.writeValueAsString(user4), XContentType.JSON))
.add(new IndexRequest().index("user")
.id("5")
.source(objectMapper.writeValueAsString(user5), XContentType.JSON))
// es不会立即写入数据, 因此需要设置刷入策略
// 见: https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-refresh.html
.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE),
RequestOptions.DEFAULT);
}
全量查询
/**
* 查询全量数据
*/
@Test
public void simpleQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery())),
RequestOptions.DEFAULT);
response.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
}
该查询输出了全量数据
{"name":"张三","sex":"男","age":30}
{"name":"李四","sex":"女","age":40}
{"name":"王五","sex":"男","age":50}
{"name":"赵六","sex":"女","age":60}
{"name":"钱七","sex":"男","age":20}
条件查询
/**
* 查询{@code age=30}的数据
*/
public void conditionQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.termQuery("age", 30))),
RequestOptions.DEFAULT);
response.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
}
只输出了年龄为30的数据
{"name":"张三","sex":"男","age":30}
分页查询
/**
* 分页查询
*/
@Test
public void pageQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery())
.from(2)
.size(2)),
RequestOptions.DEFAULT);
response.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
}
只输出了区间 [ 2 × ( 2 − 1 ) , 4 ] [2\times(2-1),4] [2×(2−1),4]的数据
{"name":"王五","sex":"男","age":50}
{"name":"赵六","sex":"女","age":60}
结果排序
/**
* 对查询结果根据年龄降序排序
*/
@Test
@Test
public void sortedQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery())
.sort("age", SortOrder.DESC)),
RequestOptions.DEFAULT);
response.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
}
输出结果根据年龄降序排序
{"name":"赵六","sex":"女","age":60}
{"name":"王五","sex":"男","age":50}
{"name":"李四","sex":"女","age":40}
{"name":"张三","sex":"男","age":30}
{"name":"钱七","sex":"男","age":20}
字段投影
/**
* 过滤部分字段
*/
@Test
public void projectionQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.matchAllQuery())
.fetchSource(new String[]{"name"}, new String[]{})),
RequestOptions.DEFAULT);
response.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
}
只输出了字段name
{"name":"张三"}
{"name":"李四"}
{"name":"王五"}
{"name":"赵六"}
{"name":"钱七"}
组合条件查询
/**
* 组合条件查询
*/
@Test
public void boolQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("age", 30))
.must(QueryBuilders.matchQuery("sex", "男")))),
RequestOptions.DEFAULT);
response.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
}
只输出了age=30 and sex='男'的数据
{"name":"张三","sex":"男","age":30}
范围查询
/**
* 范围查询
*/
@Test
public void rangeQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.rangeQuery("age")
.gte(30)
.lt(50))),
RequestOptions.DEFAULT);
response.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
}
这样只输出 a g e ∈ [ 30 , 50 ) age \in [30,50) age∈[30,50)的数据
{"name":"张三","sex":"男","age":30}
{"name":"李四","sex":"女","age":40}
模糊查询
/**
* 模糊查询
*/
@Test
public void fuzzyQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.fuzzyQuery("name", "王")
.fuzziness(Fuzziness.ONE))), // 只能差一个字
RequestOptions.DEFAULT);
response.getHits().forEach(hit -> System.out.println(hit.getSourceAsString()));
}
输出为
{"name":"王五","sex":"男","age":50}
{"name":"张三","sex":"男","age":30}
{"name":"李四","sex":"女","age":40}
{"name":"赵六","sex":"女","age":60}
{"name":"钱七","sex":"男","age":20}
高亮查询
/**
* 高亮查询
*/
@Test
public void highlightQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.query(QueryBuilders.termQuery("name", "王"))
.highlighter(new HighlightBuilder()
// 添加html标签高亮(只在浏览器中生效)
.preTags("<font color='red'>")
.postTags("</font>")
.field("name"))),
RequestOptions.DEFAULT);
response.getHits().forEach(hit -> System.out.println(hit.getHighlightFields()));
}
匹配部分被打上了html标签, 以高亮显示
{name=[name], fragments[[<font color='red'>王</font>五]]}
聚合查询
求最大年龄
/**
* 聚合查询; 求最大年龄
*/
@Test
public void maxAggQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.aggregation(AggregationBuilders.max("ageAge")
.field("age"))),
RequestOptions.DEFAULT);
response.getAggregations()
.asMap()
.forEach((key, value) -> System.out.printf("%s:%s", key, ((NumericMetricsAggregation.SingleValue) value).getValueAsString()));
}
输出为最大年龄
ageAge:60.0
求各个分组的数量
/**
* 聚合查询: 求各个年龄的数量
*/
@Test
public void groupQuery() throws IOException {
SearchResponse response = client.search(new SearchRequest()
.indices("user")
.source(new SearchSourceBuilder()
.aggregation(AggregationBuilders.terms("ageGroup")
.field("age"))),
RequestOptions.DEFAULT);
System.out.println(response);
}
聚合查询结果局部的输出为
"aggregations": {
"lterms#ageGroup": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{ "key": 20, "doc_count": 1 },
{ "key": 30, "doc_count": 1 },
{ "key": 40, "doc_count": 1 },
{ "key": 50, "doc_count": 1 },
{ "key": 60, "doc_count": 1 }
]
}
}
系统架构
核心概念
- 索引: 索引是一个拥有共性的文档的集合 例如有一个订单数据的索引, 存储了订单数据
- 类型: 在一个索引当中, 可以定义一种或多种类型 5.x版本之前一个索引支持多个类型, 6.x只有一种type, 而7.x默认不再支持自定义索引类型, 因为es和关系型数据库还是有本质上的区别
- 文档: 文档是一个可以被索引的基础信息单元, 也就是一条数据 在一个index/type里面, 可以存储任意多的文档
- 字段(Field): 相当于数据表的字段, 对文档根据不同属性进行分类和标识
- 映射(Mapping): 映射是处理数据的方式, 用于对数据做一些限制 如数据的类型/是否要添加索引
- 分片(Shards): 一个索引可以存储超出单个节点硬件限制的大量数据, 为了解决这个问题, ES提供了将索引划分为多分的能力, 每一份就是一份分片
- 副本(replicas): ES允许对分片创建一份或多份拷贝, 这些拷贝就是副本 副本即提高了系统的可用性, 也提高了系统的吞吐
- 分配(Allocation): 数据有主分片和副本之分, 而该管理是由master节点管理的 例如住分片和副本不能在同一个节点上, 否则不能发挥副本的优势
集群模式架构
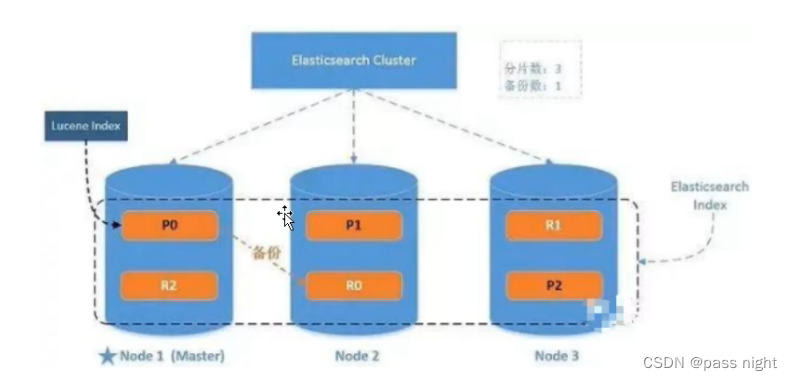
集群模式下会有一下特性:
故障转移
故障转移: 当集群中有多个节点 他们的cluster.name一致, 则可以为数据创建副本; 当某个节点宕机后, 数据并不会丢失
-
对于
2.4中的node-1001宕机后, 主分片和主节点会发生转移 -

-
当
node-1001重新加入集群后,node-1001依旧可以提供服务:
水平扩容
水平扩容: 对于正在增长中的数据按需扩容, 当新的节点加入时, 数据会为了分散负载而对分片重新分配
-
如添加从两个节点扩容到三个节点, 数分布的变化(假设一个索引有两个三个分片, 且有一个副本):
-

-
然后再讲副本数
+1:
分片路由
分片路由: 当有数据写入时, 数据会根据一下路由规则选择写入位置
- 数据会优先写入主分片, 然后才会写副本; 主分片的位置 = h a s h ( i d ) % n u m 主分片 =hash(id) \% num_{主分片} =hash(id)%num主分片
- 数据查询不一定要查询主分片, 因此可以随便选择需要访问的分片
集群模式下的读写流程
写流程
ES写入时一致性可以通过consistency配置, 取值有
one: 表示主分片写完后响应all: 所有分片写完后完成响应quorum: 大于一半的分片写完后响应 这个是默认值
下图中, 使用红色代表主节点, 绿色代表主分片
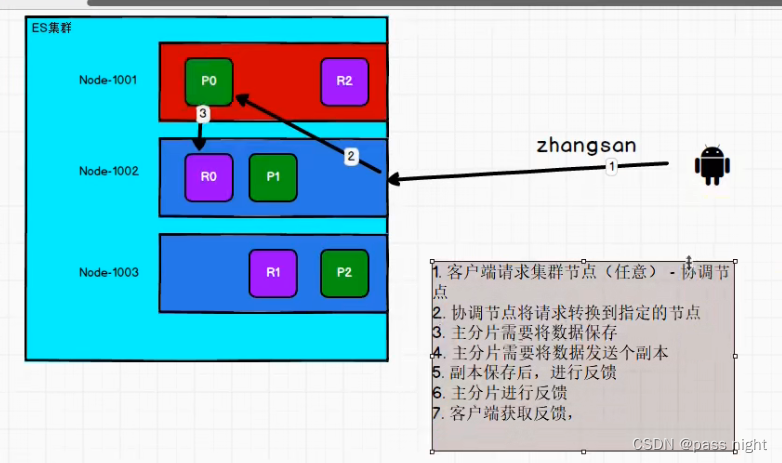
- 客户端请求任意一个集群节点 该节点被称为协调节点
- 协调节点会将请求转发到指定节点
- 主分片保存数据, 并将数据发送给副本
- 副本保存后反馈主分片
- 主分片保存后反馈协调节点
- 协调节点反馈用户
读流程
ES可以从主分片和任意副本读取数据, 其流程为:
- 客户端请求任意一个集群节点
- 协调节点以轮询策略选择真正执行查询操作的分片
- 协调节点会将请求转发给执行节点, 执行节点查询结果并将结果返回给客户端
更新流程
- 客户端请求任意一个节点
- 协调节点会将请求转发到主分片所在的节点, 并写入数据
- 之后再执行副本同步的流程
多文档操作流程
ES提供bulk和mgetapi提供多文档操作, 批量处理与单节点操作一样, 只是ES会自动对批量操作进行分配, 然后执行
分片原理
分片事ES最小的工作单元, 多个分片组成一个索引; 而分片索引的数据结构是倒排索引
倒排索引
- 词条: 索引中最小的存储单元和查询单元 英文中一般是一个单词, 而中文中一般是一个词
- 词典: 是词条的集合 一般用B+Tree或HashTable实现
- 倒排表: 每个词条对应的文档id 查询会先根据词典判断是否在倒排表当中, 以判断是否要进行后续查询
文档搜索
- 倒排索引被写入磁盘之后是不可改变的, 因此有以下优势
- 不需要锁: 不能修改的东西无需担心多线程更新的问题
- 缓存容易: 因为索引不变, 所以缓存一直有效; 且基于该数据建立的更高层次的缓存也一直有效 如filter缓存
- 可压缩: 单个大倒排索引因为不变的缘故所以可以被压搜, 进而减少磁盘IO和内存使用量
- 因此也有以下劣势:
- 不变值难以修改, 修改成本高
- 为了解决上述问题, ES引入了动态更新索引: 用更新索引来反应变化, 空闲时用动态更新索引来更新倒排索引
- ES基于Lucene, 因此具有段的概念, 每个段是一个倒排索引, 而查询时基于段的查询
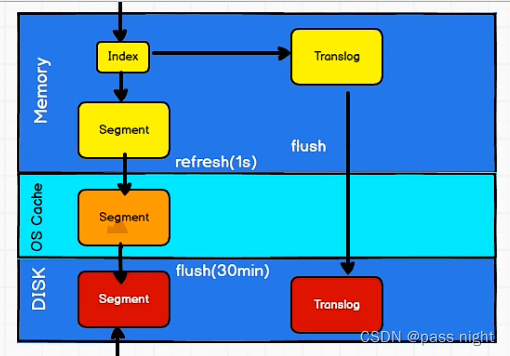
近实时搜索
- 因为ES是根据段进行搜索的, ES的段落盘之后才能完成搜索; 因此写入性能高但会导致查询延迟 这里的查询延迟指延迟一段时间后才能获取最新的数据
- 延时产生的原因是: 主分片写入的演示+并行写入副本分片的延时
- 为了防止断点导致数据写入不完整, 类似于数据库的redo log; ES 引入了Translog保存写入的片段 和数据库不同的是, 数据库是先写log再落盘; 而es因为写内存具有大量逻辑很容易失败, 所以是先写内存再写日志
- 为了提高实时性, 当数据写入到操作系统文件缓存之后就可以提供服务, 这个过程称为refresh, 之后再flush到磁盘中 默认情况下, fresh时间为1s, 而flush时间间隔为30min
文档分析
分析包括以下过程:
- 将文本分成适合于倒排索引的独立词条
- 将词条转化为统一格式以提高他们的可搜索性
- 分析器包含以下三个组件
- 字符过滤器: 在分词前整理字符串 如将
&转化为and; 或过滤掉html的标签等 - 分词器: 将字符串分为多个词条 最简单的情况下, 就是通过空白分隔字符
- token过滤器: 将词条转为统一格式 *如小写化所有单词, 删除
and,a,the等无用的单词, 或增加词条, 类似jump,leap这样的同义词
- 字符过滤器: 在分词前整理字符串 如将
内置分析器
ES软件内置了一些分析器
- 标准分析器: 删除绝大部分的标点, 并将词条小写化
- 简单分析器: 在任何不是字母的地方分隔文本
- 空格分析器: 在空格地方分隔文本
- 语言分析器: 根据特定的语言进行分词 如英语语言分析器就会删掉无意义的
the
分析器使用
例如以下是标准分析器, 它保留了token及其类型/位置值等基本信息
In [9]: requests.get(f"{url}/_analyze", json={"analyzer":"standard","text":"Text to analyze"}).json()
Out[9]:
{'tokens': [{'token': 'text',
'start_offset': 0,
'end_offset': 4,
'type': '<ALPHANUM>',
'position': 0},
{'token': 'to',
'start_offset': 5,
'end_offset': 7,
'type': '<ALPHANUM>',
'position': 1},
{'token': 'analyze',
'start_offset': 8,
'end_offset': 15,
'type': '<ALPHANUM>',
'position': 2}]}
中文分词
默认的分词器会将所有中文当做象形文字分词, 即将每个字都分开
In [11]: requests.get(f"{url}/_analyze", json={"text":"测试单词"}).json()
Out[11]:
{'tokens': [{'token': '测',
'start_offset': 0,
'end_offset': 1,
'type': '<IDEOGRAPHIC>',
'position': 0},
{'token': '试',
'start_offset': 1,
'end_offset': 2,
'type': '<IDEOGRAPHIC>',
'position': 1},
{'token': '单',
'start_offset': 2,
'end_offset': 3,
'type': '<IDEOGRAPHIC>',
'position': 2},
{'token': '词',
'start_offset': 3,
'end_offset': 4,
'type': '<IDEOGRAPHIC>',
'position': 3}]}
IK分词器是一个中文分词器, 可用于分词中文文本; IK 分词器需要单独安装
passnight@passnight-s600:~$ docker exec -it elasticsearch bash
[root@f10b92eeb7c9 elasticsearch]# bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.13.3/elasticsearch-analysis-ik-7.13.3.zip
# 之后再宿主机上重启容器
passnight@passnight-s600:~/tmp$ docker restart elasticsearch
安装完成之后就可以使用中文分词器分词, 可以看到符合中文语义
其中, ik分词器有两个模式:
ik_max_word: 按照文本最细粒度拆分ik_smart: 按照文本最粗粒度拆分
In [17]: requests.get(f"{url}/_analyze", json={"analyzer":"ik_max_word","text":"中国人"}).json()
Out[17]:
{'tokens': [{'token': '中国人',
'start_offset': 0,
'end_offset': 3,
'type': 'CN_WORD',
'position': 0},
{'token': '中国',
'start_offset': 0,
'end_offset': 2,
'type': 'CN_WORD',
'position': 1},
{'token': '国人',
'start_offset': 1,
'end_offset': 3,
'type': 'CN_WORD',
'position': 2}]}
In [18]: requests.get(f"{url}/_analyze", json={"analyzer":"ik_smart","text":"中国人"}).json()
Out[18]:
{'tokens': [{'token': '中国人',
'start_offset': 0,
'end_offset': 3,
'type': 'CN_WORD',
'position': 0}]}
中文分词器也允许自己扩展词汇; 如下面的弗雷尔卓德表示一个词
In [19]: requests.get(f"{url}/_analyze", json={"analyzer":"ik_max_word","text":"弗雷尔卓德"}).json()
Out[19]:
{'tokens': [{'token': '弗',
'start_offset': 0,
'end_offset': 1,
'type': 'CN_CHAR',
'position': 0},
{'token': '雷',
'start_offset': 1,
'end_offset': 2,
'type': 'CN_CHAR',
'position': 1},
{'token': '尔',
'start_offset': 2,
'end_offset': 3,
'type': 'CN_CHAR',
'position': 2},
{'token': '卓',
'start_offset': 3,
'end_offset': 4,
'type': 'CN_CHAR',
'position': 3},
{'token': '德',
'start_offset': 4,
'end_offset': 5,
'type': 'CN_CHAR',
'position': 4}]}
完成这个操作需要修改分词器的配置文件, 添加自定义分词2
passnight@passnight-s600:~$ docker exec -it elasticsearch bash
[root@f10b92eeb7c9 elasticsearch]# cd config/analysis-ik
# 配置自定义词典
[root@f10b92eeb7c9 analysis-ik]# vi IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<!-- <entry key="ext_stopwords">custom/ext_stopword.dic</entry> -->
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">http://xxx.com/xxx.dic</entry> -->
</properties>
# 将自定义分词添加到自定义词典中
[root@f10b92eeb7c9 analysis-ik]# vi custom.dic
弗雷尔卓德
# 重启es, 使配置生效
passnight@passnight-s600:~/tmp$ docker restart elasticsearch
之后再请求, 可以看到自定义分词已经生效了
In [24]: requests.get(f"{url}/_analyze", json={"analyzer":"ik_max_word","text":"弗雷尔卓德"}).json()
Out[24]:
{'tokens': [{'token': '弗雷尔卓德',
'start_offset': 0,
'end_offset': 5,
'type': 'CN_WORD',
'position': 0}]}
自定义分词器
如上文所说, 自定义分词器需要定义: 字符过滤器/分词器和token过滤器三个模块
文档处理
文档冲突
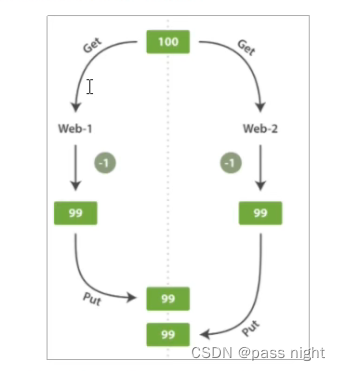
两个用户同时读取原始文档, 并更新, 此时es会重新索引整个文档, 这样只有后被索引的文档才会被保存在es中; 而前面一个更新操作会被丢失 类似与SQL事务的丢失更新, 上图两个用户同时请求-1
乐观并发控制
- 使用版本号来判断更新是否能够提交, 若不能提交的话, 会返回操作失败
下面华为手机被更新了一次 而请求附带参数version=0, 可以看到因为乐观并发控制, 无法成功修改
In [7]: In [3]: requests.get(f"{url}/shopping/_doc/1").json()
Out[7]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 2,
'_seq_no': 1,
'_primary_term': 1,
'found': True,
'_source': {'title': '华为手机', 'category': '华为', 'price': 18848}}
# 因乐观锁无法更新
In [8]: requests.post(f"{url}/shopping/_update/1", json={"doc":{"price":8848}}, params={"if_seq_no":0,"if_primary_term":
...: 0}).json()
Out[8]:
{'error': {'root_cause': [{'type': 'action_request_validation_exception',
'reason': 'Validation Failed: 1: ifSeqNo is set, but primary term is [0];'}],
'type': 'action_request_validation_exception',
'reason': 'Validation Failed: 1: ifSeqNo is set, but primary term is [0];'},
'status': 400}
# 序号为1, 说明拿到的时最新的版本, 可以正常更新
In [9]: requests.post(f"{url}/shopping/_update/1", json={"doc":{"price":8848}}, params={"if_seq_no":1,"if_primary_term":
...: 1}).json()
Out[9]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 3,
'result': 'updated',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 2,
'_primary_term': 1}
es还支持外部版本控制, 可以自定义版本号;
In [11]: requests.post(f"{url}/shopping/_doc/1", json={"price":8848}, params={"version":4,"version_type":"external"}).js
...: on()
Out[11]:
{'_index': 'shopping',
'_type': '_doc',
'_id': '1',
'_version': 4,
'result': 'updated',
'_shards': {'total': 2, 'successful': 1, 'failed': 0},
'_seq_no': 3,
'_primary_term': 1}
# 不指定自定义版本号的话会报错
In [12]: requests.post(f"{url}/shopping/_doc/1", json={"price":8848}, params={"version":4}).json()
Out[12]:
{'error': {'root_cause': [{'type': 'action_request_validation_exception',
'reason': 'Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;'}],
'type': 'action_request_validation_exception',
'reason': 'Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;'},
'status': 400}
悲观并发控制
- 操作数据时将该数据锁住, 禁止其他请求操作该数据索引都是存储在磁盘当中
优化
硬件优化
- es是基于Lucene开发的, 因此磁盘在现代服务器上通常都是瓶颈, 为了优化es磁盘的性能可以采用以下方案
- 使用SSD: SSD的性能要远远由于hhd
- 使用raid: raid尤其是raid0可以显著提高磁盘性能
- 使用多块硬盘: ES设置多个
path.data目录就可以将数据条带化分配在他们上面 - 尽量少使用远程挂载存储: 远程存储的性能要低于本地存储
分片策略
- 设置合理的分片数: 分片不是越大越好的, 每个分片都是有代价的
- 一个分片底层是一个Lucene索引, 会消耗一定的文件句柄/内存/CPU
- 每个搜索请求都要命中索引中的每一个分片, 若分片处于同一节点, 可能会导致单节点的资源竞争
- 计算相关度的词频统计信息是基于分片的, 若有过多的分片, 每个分片的都只有很少的数据, 进而会导致数据都只有很低的相关度
- 一般有以下经验:
- 每个分片占用的硬盘容量不超过JVM堆大小一般不超过32G, 这样若索引总量在500G左右, 则分片大小在16个左右
- 分片数一般不超过节点数的三倍: 若分片数大大多于节点数, 则无法享受到多节点带来的高可用及高性能优势
- 节点数 ≤ 主分片数 × ( 副本数 + 1 ) 节点数\le主分片数\times(副本数+1) 节点数≤主分片数×(副本数+1)
- 推迟分片分配: 若某个节点宕机, 会发生分片重分配的问题
- 当某个节点宕机后, 集群会等待一段时间来判断节点是否重新加入, 若重分配等待时间太短, 节点可能只是暂时失去响应就导致了重分配进而影响性能
数据路由
- 查询文档时, es是通过以下公式计算分片
s
h
a
r
d
=
h
a
s
h
(
r
o
u
t
i
n
g
)
m
o
d
n
u
m
b
e
r
_
o
f
_
p
r
i
m
a
r
y
_
s
h
a
r
d
s
shard=hash(routing)\mod number\_of\_primary\_shards
shard=hash(routing)modnumber_of_primary_shards, 这里
routing的默认值是文档id, 但也可以使用自定义值 如用户id, 这样在某些场景下可以提升性能 - 实际情况下有以下两种查询方式:
- 不带路由的查询: 查询不需要知道数据在那个分片上, 因此只有以下两个步骤
- 分发: 请求到达协调节点后, 协调节点将查询分发到每个分片上
- 聚合:协调节点收集到每个分片上的查询结果, 并对查询结果排序, 返回用户
- 带路由的查询:
- 可以直接根据routing信息定位到某个分片, 而不需要查询所有的节点
- 查询结果依旧是经过协调节点聚合后返回给用户 这样不需要将请求广播而是有明确目标的多播
- 不带路由的查询: 查询不需要知道数据在那个分片上, 因此只有以下两个步骤
写入速度优化
- es的默认配置考虑了数据的可靠性/写入速度/搜索实时性等因素, 因此在实际使用中, 需要根据特定的场景进行有偏向性的优化, 对于搜索要求不高写入要求高的场景, 可以进行以下优化
- 加大Translog Flush: 降低Iops, Writeblock
- 增大Index Refresh : 减少segment merge次数
- 调整Bulk线程池和队列: 提高bulk操作的并行度
- 优化节点间的任务分布
- 优化Lucene层的索引建立, 降低CPU和IO负载
- 批量数据提交: es提供了Bulk api支持批量操作 注意一般单批次的数据量不应超过100M, 且批次大小的增大有边界效应, 不应无限制扩大
- 优化存储设备
- 合理使用合并: Lucene使用段合并, 当有新的索引写入时, Lucene就会创建新的段, 因此es采取默认保守的策略, 后台定期合并
- 减少Refresh 次数: Lucene会将数据先写入到内存中, 没
refresh_interval周期会刷新一次, 若对实时性要求不高可以增大这个参数 - 加大flush设置: 一般当Translog达到
index.translog.flush_threshold_size=521MB会触发flush, 若增大flush配置, 可以减少flush的次数 - 减少副本的数量: es集群写入过程要保证副本也成功写入, 若副本数量少, 这个速度的期望值也会加快
内存设置
- es的默认内存设置是
1GB, 其主要内存分配主要有以下两个原则:- 不要超过物理内存的 50 % 50\% 50%, 太大操作系统的磁盘缓存就不够用了, 这样会增大落盘次数
- 堆内存大小最好不要大于
32Gjava使用内存压缩的技术节省内存, 这样就只需要使用32位指针; 若堆内存过大, 该技术就会失效, 这样指针大小就会变为64位, 极大地影响性能; 其中多出来的内存可以分配给lucence3
重要配置
| 参数名 | 参数值 | 说明 |
|---|---|---|
cluster.name | elasticsearch | 配置es的集群名称, 同一网段下集群名称相同的节点会组成集群 |
node.name | node-1 | 集群中的节点名, 同一集群中不能重复, 一旦设置就不能修改 |
node.master | true | 该节点是否有资格被选举为master 不代表该节点就是master |
node.data | true | 该节点是否存储数据 数据的增删查改都是在数据节点上完成的 |
index.number_of_shards | 1 | 分片数量, 影响性能, 原因见前面 |
index.number_of_replicas | 1 | 副本数量, 越高可用性越高, 但写入性能越差 |
transport.tcp.comporess | true | 窜出数据时是否压缩 |
discovery.zen.minimun_master_nodes | 1 | 选举master需要有的候选人的最少数量, 需要大于半数节点参与, 若按照默认配置可能会导致脑裂 |
discovery.zen.ping.timeout | 3s | 集群中发现其他节点ping的超时时间, 网络较差时需要设置得大一点, 以防误判节点下线而导致分片转移 |
文档评分机制
- 查询的数据会评分, 查询结果会根据评分排序, 评分是查询结果中的
_score字段 - 其中计算公式为:
_
s
c
o
r
e
=
b
o
o
s
t
×
i
d
f
×
t
f
\_score=boost\times idf \times tf
_score=boost×idf×tf 其中
boost是权重
文档得分
es采用的是tf-idf公式评分
- TF(Term Frequency, 词频): 文本中词条出现的次数, 词条出现次数越多, 该评分越高
- IDF(Inverse Document Frequency, 逆文档频率):文本中各个词条在整个索引的所有文档中出现了多少次, 出现次数越多说明越不重要, 因此该项得分越低 如the在所有文档都频繁出现, 因此其IDF低且不重要
在查询中, 可以通过添加explain=true来查看评分计算结果
In [16]: requests.get(f"{url}/shopping/_search", params={"explain": "true"}, json={"query":{"match": {"title": "华为"}}}
...: ).json()
Out[16]:
{'took': 1,
'timed_out': False,
'_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0},
'hits': {'total': {'value': 2, 'relation': 'eq'},
'max_score': 0.26706278,
'hits': [{'_shard': '[shopping][0]',
'_node': 'TflZy_0kSd2KsD11vajpsg',
'_index': 'shopping',
'_type': '_doc',
'_id': 'AHdB44wBL8fZAkJalBsr',
'_score': 0.26706278,
'_source': {'title': '华为手机', 'category': '华为', 'price': 8848},
'_explanation': {'value': 0.26706278,
'description': 'sum of:',
'details': [{'value': 0.13353139,
'description': 'weight(title:华 in 0) [PerFieldSimilarity], result of:',
'details': [{'value': 0.13353139,
'description': 'score(freq=1.0), computed as boost * idf * tf from:',
'details': [{'value': 2.2, 'description': 'boost', 'details': []},
{'value': 0.13353139,
'description': 'idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:',
'details': [{'value': 3,
'description': 'n, number of documents containing term',
'details': []},
{'value': 3,
'description': 'N, total number of documents with field',
'details': []}]},
{'value': 0.45454544,
'description': 'tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:',
'details': [{'value': 1.0,
'description': 'freq, occurrences of term within document',
'details': []},
{'value': 1.2,
'description': 'k1, term saturation parameter',
'details': []},
{'value': 0.75,
'description': 'b, length normalization parameter',
'details': []},
{'value': 4.0,
'description': 'dl, length of field',
'details': []},
{'value': 4.0,
'description': 'avgdl, average length of field',
'details': []}]}]}]},
{'value': 0.13353139,
'description': 'weight(title:为 in 0) [PerFieldSimilarity], result of:',
'details': [{'value': 0.13353139,
'description': 'score(freq=1.0), computed as boost * idf * tf from:',
'details': [{'value': 2.2, 'description': 'boost', 'details': []},
{'value': 0.13353139,
'description': 'idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:',
'details': [{'value': 3,
'description': 'n, number of documents containing term',
'details': []},
{'value': 3,
'description': 'N, total number of documents with field',
'details': []}]},
{'value': 0.45454544,
'description': 'tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:',
'details': [{'value': 1.0,
'description': 'freq, occurrences of term within document',
'details': []},
{'value': 1.2,
'description': 'k1, term saturation parameter',
'details': []},
{'value': 0.75,
'description': 'b, length normalization parameter',
'details': []},
{'value': 4.0,
'description': 'dl, length of field',
'details': []},
{'value': 4.0,
'description': 'avgdl, average length of field',
'details': []}]}]}]}]}},
{'_shard': '[shopping][0]',
'_node': 'TflZy_0kSd2KsD11vajpsg',
'_index': 'shopping',
'_type': '_doc',
'_id': 'AXdB44wBL8fZAkJauxsr',
'_score': 0.26706278,
'_source': {'title': '华为公司', 'category': '华为'},
'_explanation': {'value': 0.26706278,
'description': 'sum of:',
'details': [{'value': 0.13353139,
'description': 'weight(title:华 in 1) [PerFieldSimilarity], result of:',
'details': [{'value': 0.13353139,
'description': 'score(freq=1.0), computed as boost * idf * tf from:',
'details': [{'value': 2.2, 'description': 'boost', 'details': []},
{'value': 0.13353139,
'description': 'idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:',
'details': [{'value': 3,
'description': 'n, number of documents containing term',
'details': []},
{'value': 3,
'description': 'N, total number of documents with field',
'details': []}]},
{'value': 0.45454544,
'description': 'tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:',
'details': [{'value': 1.0,
'description': 'freq, occurrences of term within document',
'details': []},
{'value': 1.2,
'description': 'k1, term saturation parameter',
'details': []},
{'value': 0.75,
'description': 'b, length normalization parameter',
'details': []},
{'value': 4.0,
'description': 'dl, length of field',
'details': []},
{'value': 4.0,
'description': 'avgdl, average length of field',
'details': []}]}]}]},
{'value': 0.13353139,
'description': 'weight(title:为 in 1) [PerFieldSimilarity], result of:',
'details': [{'value': 0.13353139,
'description': 'score(freq=1.0), computed as boost * idf * tf from:',
'details': [{'value': 2.2, 'description': 'boost', 'details': []},
{'value': 0.13353139,
'description': 'idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:',
'details': [{'value': 3,
'description': 'n, number of documents containing term',
'details': []},
{'value': 3,
'description': 'N, total number of documents with field',
'details': []}]},
{'value': 0.45454544,
'description': 'tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:',
'details': [{'value': 1.0,
'description': 'freq, occurrences of term within document',
'details': []},
{'value': 1.2,
'description': 'k1, term saturation parameter',
'details': []},
{'value': 0.75,
'description': 'b, length normalization parameter',
'details': []},
{'value': 4.0,
'description': 'dl, length of field',
'details': []},
{'value': 4.0,
'description': 'avgdl, average length of field',
'details': []}]}]}]}]}}]}}
tf计算公式
t f = f r e q f r e q + k 1 ( 1 − b + b ⋅ d l a v g d l ) tf=\frac{freq}{freq+k1(1-b+\frac{b\cdot dl}{avgdl})} tf=freq+k1(1−b+avgdlb⋅dl)freq
其中:
freq为关键词在当前文档中出现的次数k1: 关键词的饱和参数 默认为1.2b: 长度系数参数 文档中可能越长的单词越重要dl: 分词后分词的个数avgdl: 所有文档中, 分词的平均个数
idf计算公式
i d f = ln ( 1 + N − n + 0.5 n + 0.5 ) idf=\ln(1+\frac{N-n+0.5}{n+0.5}) idf=ln(1+n+0.5N−n+0.5)
N: 文档中字段的总数量 这里的字段是上面的title而不是分词n: 文档中包含的关键词的数量
得分计算公式
s c o r e = b o o s t ⋅ t f ⋅ i d f score=boost \cdot tf \cdot idf score=boost⋅tf⋅idf
boost是权重, 默认值为2.2
引用
docker-compose安装elasticsearch及kibana - 陈远波 - 博客园 (cnblogs.com) ↩︎
medcl/elasticsearch-analysis-ik: The IK Analysis plugin integrates Lucene IK analyzer into elasticsearch, support customized dictionary. (github.com) ↩︎
JVM内存不要超过32G - CharyGao - 博客园 (cnblogs.com) ↩︎