《操作系统导论》第16章读书笔记:分段


—— 杭州 2024-03-31 夜
文章目录
- 《操作系统导论》第16章读书笔记:分段
- 0.前言
- 1.分段:泛化的基址/界限
- 2.我们引用哪个段?
- 3.栈怎么办
- 4.支持共享
- 5.细粒度与粗粒度的分段、操作系统支持
- 6.小结
- 7.补充笔记:地址空间和进程空间的关系
- 8.补充笔记:一个CPU有几个基址寄存器和界限寄存器?一个CPU有几个地址空间和进程空间?一个CPU有几个MMU?
0.前言
到目前为止,我们一直假设将所有进程的地址空间完整地加载到内存中。利用基址和界限寄存器,操作系统很容易将不同进程重定位到不同的物理内存区域。但是,对于这些内存区域,你可能已经注意到一件有趣的事:栈和堆之间,有一大块“空闲”空间。
从图 16.1 中可知,如果我们将整个地址空间放入物理内存,那么栈和堆之间的空间并没有被进程使用,却依然占用了实际的物理内存。因此,简单的通过基址寄存器和界限寄存器实现的虚拟内存很浪费。另外,如果剩余物理内存无法提供连续区域来放置完整的地址空间,进程便无法运行。这种基址加界限的方式看来并不像我们期望的那样灵活。因此:
关键问题:怎样支持大地址空间?
怎样支持大地址空间,同时栈和堆之间(可能)有大量空闲空间?在之前的例子里,地址空间非常小,所以这种浪费并不明显。但设想一个 32 位(4GB)的地址空间,通常的程序只会使用几兆的内存,但需要整个地址空间都放在内存中。

1.分段:泛化的基址/界限
-
分段:这个想法很简单,
在MMU 中引入不止一个基址和界限寄存器对,而是给地址空间内的每个逻辑段(segment)一对。一个段只是地址空间里的一个连续定长的区域,在典型的地址空间里有3个逻辑不同的段:代码、栈和堆。分段的机制使得操作系统能够将不同的段放到不同的物理内存区域,从而避免了虚拟地址空间中的未使用部分占用物理内存。 -
稀疏地址空间,sparse address spaces:如图16.2所示,64KB的物理内存中放置了3个段(为操作系统保留16KB)。从图中可以看到,只有已用的内存才在物理内存中分配空间,因此可以容纳巨大的地址空间,其中包含大量未使用的地址空间(有时又称为稀疏地址空间,sparse address spaces)。
-
段错误:段错误指的是在支持分段的机器上发生了非法的内存访问。有趣的是,即使在不支持分段的机器上
这个术语依然保留。 -
段异常(segmentation violation)或段错误(segmentation fault):如果我们试图访问非法的地址,例如7KB,它超出了堆的边界呢?你可以想象发生的情况:硬件会发现该地址越界,因此陷入操作系统,很可能导致终止出错进程。这就是每个C 程序员都感到恐慌的术语的来源。
// 假设:基址寄存器值为 32KB(即 32768 字节),界限寄存器值为 2KB(即 2048 字节)
// 虚拟地址转换为物理地址的函数
function 虚拟地址转物理地址(虚拟地址, 基址寄存器, 界限寄存器) {
// 越界检查
if (虚拟地址 >= 界限寄存器) {
抛出异常("段错误"); // 越界访问
} else {
// 计算物理地址并返回
物理地址 = 虚拟地址 + 基址寄存器;
return 物理地址;
}
}
// 示例 1: 虚拟地址 100 的转换
物理地址 = 虚拟地址转物理地址(100, 32768, 2048);
// 物理地址应该是 32868
// 示例 2: 堆中的地址 4200 的转换
// 假设堆基址寄存器值为 34KB(即 34816 字节),界限寄存器值为 2KB
物理地址 = 虚拟地址转物理地址(4200 - 4096, 34816, 2048); // 偏移量是 4200 - 4096
// 物理地址应该是 34920
// 越界检查示例
try {
虚拟地址转物理地址(4400, 32768, 2048); // 假设这是一个非法地址,因为它超出了界限
} catch (异常 e) {
打印("异常: " + e); // 捕获到越界异常
}


2.我们引用哪个段?
- 硬件在地址转换时使用段寄存器。它如何知道段内的偏移量,以及地址引用了哪个段?
- 一种常见的方式,有时称为
显式(explicit)方式,就是用虚拟地址的开头几位来标识不同的段。 - 在我们的例子中,如果前两位是00,硬件就知道这是属于代码段的地址,因此使用代码段的基址和界限来重定位到正确的物理地址。如果前两位是01,则是堆地址,对应地,使用堆的基址和界限。
- 前两位(01)告诉硬件我们引用哪个段。剩下的12 位是段内偏移:0000 0110 1000(即十六进制0x068 或十进制104)。因此,硬件就用前两位来决定使用哪个段寄存器,然后用后12位作为段内偏移。偏移量与基址寄存器相加,硬件就得到了最终的物理地址。
- 请注意,偏移量也简化了对段边界的判断。我们只要检查偏移量是否小于界限,大于界限的为非法地址。
- 上面使用两位来区分段,但实际只有3个段(代码、堆、栈),因此有一个段的地址空间被浪费。因此有些系统中会将堆和栈当作同一个段,因此只需要一位来做标识。
- 硬件还有其他方法来决定特定地址在哪个段。在
隐式(implicit)方式中,硬件通过地址产生的方式来确定段。例如,如果地址由程序计数器产生(即它是指令获取),那么地址在代码段。如果基于栈或基址指针,它一定在栈段。其他地址则在堆段。 - 如果基址和界限放在数组中(每个段一项),为了获得需要的物理地址,硬件会做下面这样的事:
1 // 获取14位虚拟地址(VA)的前2位
2 Segment = (VirtualAddress & SEG_MASK) >> SEG_SHIFT
3
4 // 现在获取偏移量
5 Offset = VirtualAddress & OFFSET_MASK
6
7 // 如果偏移量超出了段的界限
8 if (Offset >= Bounds[Segment])
9 RaiseException(PROTECTION_FAULT) // 抛出保护故障异常
10 else
11 PhysAddr = Base[Segment] + Offset // 计算物理地址
12 Register = AccessMemory(PhysAddr) // 从物理地址访问内存,并将数据存入寄存器

3.栈怎么办
- 它反向增长,地址转换必须有所不同。
- 需要一点硬件支持。除了基址和界限外,硬件还需要知道段的增长方向(用一位区分,比如1代表自小而大增长,0 反之)。
- 例程1:
# 定义段寄存器的值,这里仅以栈的信息为例
# 假设栈的基址为28KB,大小为2KB
SEGMENT_BASE_STACK = 28 * 1024 # 栈段的基址(28KB转换为字节)
SEGMENT_SIZE_STACK = 2 * 1024 # 栈段的大小(2KB转换为字节)
# 虚拟地址转换函数
def convert_stack_virtual_to_physical(virtual_address):
# 如果虚拟地址不在栈的界限内,触发保护故障异常
if virtual_address >= SEGMENT_SIZE_STACK:
raise Exception("保护故障:虚拟地址超出了栈的界限")
# 计算物理地址:基址 + 虚拟地址(偏移量)
physical_address = SEGMENT_BASE_STACK + virtual_address
return physical_address
# 示例:对栈内的虚拟地址进行转换
try:
# 假设要转换的栈虚拟地址为1500字节偏移量
virtual_address = 1500
# 调用函数进行转换
physical_address = convert_stack_virtual_to_physical(virtual_address)
# 打印转换后的物理地址
print("物理地址:", physical_address)
except Exception as e:
# 捕获并打印异常信息
print(str(e))
- 例程2:
// 假设:每个段有一个基址(Base)和界限(Limit)寄存器,以及一个反向增长标志(GrowDown)
// 段寄存器的数组,每个段一个寄存器,包含基址、界限和反向增长标志
SegmentRegisters = [
{ Base: 32KB, Limit: 2KB, GrowDown: false }, // 代码段
{ Base: 34KB, Limit: 2KB, GrowDown: false }, // 堆段
{ Base: 28KB, Limit: 2KB, GrowDown: true } // 栈段
]
// 虚拟地址转换为物理地址的函数
function 虚拟地址转物理地址(虚拟地址, 段寄存器) {
// 计算段内偏移量
偏移量 = 虚拟地址 % 段的大小
// 根据段是否反向增长调整偏移量
if (段寄存器.GrowDown) {
偏移量 = 段寄存器.Limit - 偏移量 - 1
}
// 越界检查
if (偏移量 < 0 || 偏移量 >= 段寄存器.Limit) {
抛出异常("段错误"); // 越界访问
} else {
// 计算物理地址并返回
物理地址 = 段寄存器.Base + 偏移量
return 物理地址
}
}
// 示例: 虚拟地址 100 的转换(假设在代码段)
物理地址 = 虚拟地址转物理地址(100, SegmentRegisters[代码段])
// 物理地址应该是 100 + 32KB = 32868
// 示例: 虚拟地址 4200 的转换(假设在堆段)
物理地址 = 虚拟地址转物理地址(4200 - 4KB, SegmentRegisters[堆段])
// 物理地址应该是 104 + 34KB = 34920
// 越界检查示例
try {
虚拟地址转物理地址(4400, SegmentRegisters[堆段]) // 假设这是一个非法地址,因为它超出了界限
} catch (异常 e) {
打印("异常: " + e) // 捕获到越界异常
}

4.支持共享
- 具体来说,要节省内存,有时候
在地址空间之间共享(share)某些内存段是有用的。尤其是,代码共享很常见,今天的系统仍然在使用。 - 保护位(protection bit):为了支持共享,需要一些额外的硬件支持,这就是
保护位(protection bit)。基本为每个段增加了几个位,标识程序是否能够读写该段,或执行其中的代码。通过将代码段标记为只读,同样的代码可以被多个进程共享,而不用担心破坏隔离。虽然每个进程都认为自己独占这块内存,但操作系统秘密地共享了内存,进程不能修改这些内存,所以假象得以保持。 - 表16.3 展示了一个例子,是硬件(和操作系统)记录的额外信息。可以看到,代码段的权限是可读和可执行,因此物理内存中的一个段可以映射到多个虚拟地址空间。
- 有了保护位,前面描述的硬件算法也必须改变。除了检查虚拟地址是否越界,硬件还需要检查特定访问是否允许。如果用户进程试图写入只读段,或从非执行段执行指令,硬件会触发异常,让操作系统来处理出错进程。

5.细粒度与粗粒度的分段、操作系统支持
-
到目前为止,我们的例子大多针对只有很少的几个段的系统(即代码、栈、堆)。我们可以认为这种分段是
粗粒度的(coarse-grained),因为它将地址空间分成较大的、粗粒度的块。但是,一些早期系统(如Multics[CV65,DD68])更灵活,允许将地址空间划分为大量较小的段,这被称为细粒度(fine-grained)分段。 -
支持许多段需要进一步的硬件支持,并在内存中保存某种
段表(segment table)。这种段表通常支持创建非常多的段,因此系统使用段的方式,可以比之前讨论的方式更灵活。例如,像Burroughs B5000 这样的早期机器可以支持成千上万的段,有了操作系统和硬件的支持,编译器可以将代码段和数据段划分为许多不同的部分[RK68]。当时的考虑是,通过更细粒度的段,操作系统可以更好地了解哪些段在使用哪些没有,从而可以更高效地利用内存。 -
系统运行时,地址空间中的不同段被重定位到物理内存中。与我们之前介绍的整个地址空间只有一个基址/界限寄存器对的方式相比,大量节省了物理内存。具体来说,栈和堆之间没有使用的区域就不需要再分配物理内存,让我们能将更多地址空间放进物理内存。
-
然而,分段也带来了一些新的问题。我们先介绍必须关注的操作系统新问题。第一个是老问题:操作系统在上下文切换时应该做什么?你可能已经猜到了:各个段寄存器中的内容必须保存和恢复。显然,每个进程都有自己独立的虚拟地址空间,操作系统必须在进程运行前,确保这些寄存器被正确地赋值。
-
第二个问题更重要,即管理物理内存的空闲空间。新的地址空间被创建时,操作系统需要在物理内存中为它的段找到空间。之前,我们假设所有的地址空间大小相同,物理内存可以被认为是一些槽块,进程可以放进去。现在,每个进程都有一些段,每个段的大小也可能不同。
-
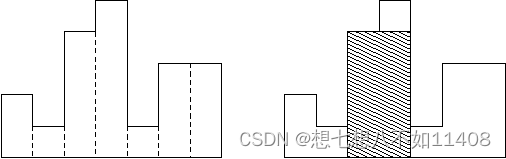
一般会遇到的问题是,物理内存很快充满了许多空闲空间的小洞,因而很难分配给新的段,或扩大已有的段。这种问题被称为·
外部碎片(external fragmentation)[R69],如图16.3(左边)所示。 -
在这个例子中,一个进程需要分配一个20KB 的段。当前有24KB 空闲,但并不连续(是3个不相邻的块)。因此,操作系统无法满足这个20KB 的请求。
-
该问题的一种解决方案是
紧凑(compact)物理内存,重新安排原有的段。例如,操作系统先终止运行的进程,将它们的数据复制到连续的内存区域中去,改变它们的段寄存器中的值,指向新的物理地址,从而得到了足够大的连续空闲空间。这样做,操作系统能让新的内存分配请求成功。但是,内存紧凑成本很高,因为拷贝段是内存密集型的,一般会占用大量的处理器时间。图16.3(右边)是紧凑后的物理内存。 -
一种更简单的做法是利用
空闲列表管理算法,试图保留大的内存块用于分配。相关的算法可能有成百上千种,包括传统的最优匹配(best-fit,从空闲链表中找最接近需要分配空间的空闲块返回)、最坏匹配(worst-fit)、首次匹配(first-fit)以及像伙伴算法(buddy algorithm)[K68]这样更复杂的算法。Wilson等人做过一个很好的调查[W+95],如果你想对这些算法了解更多,可以从它开始,或者等到第17章,我们将介绍一些基本知识。但遗憾的是,无论算法多么精妙,都无法完全消除外部碎片,因此,好的算法只是试图减小它。

6.小结
分段解决了一些问题,帮助我们实现了更高效的虚拟内存。不只是动态重定位,通过避免地址空间的逻辑段之间的大量潜在的内存浪费,分段能更好地支持稀疏地址空间。它还很快,因为分段要求的算法很容易,很适合硬件完成,地址转换的开销极小。分段还有一个附加的好处:代码共享。如果代码放在独立的段中,这样的段就可能被多个运行的程序共享。
但我们已经知道,在内存中分配不同大小的段会导致一些问题,我们希望克服。首先,是我们上面讨论的外部碎片。由于段的大小不同,空闲内存被割裂成各种奇怪的大小,因此满足内存分配请求可能会很难。用户可以尝试采用聪明的算法[W+95],或定期紧凑内存,但问题很根本,难以避免。
第二个问题也许更重要,分段还是不足以支持更一般化的稀疏地址空间。例如,如果有一个很大但是稀疏的堆,都在一个逻辑段中,整个堆仍然必须完整地加载到内存中。换言之,如果使用地址空间的方式不能很好地匹配底层分段的设计目标,分段就不能很好地工作。因此我们需要找到新的解决方案。你准备好了吗?

7.补充笔记:地址空间和进程空间的关系
地址空间和进程空间是两个相关但不同的概念,它们在操作系统中以不同的方式被管理和使用。
-
地址空间:
地址空间通常指的是一个处理器可以寻址的全部内存范围。在32位系统中,地址空间通常是4GB(2的32次方),在64位系统中则远远大于此数值。地址空间包括了所有可能的地址,这些地址可以是物理内存地址,也可以是虚拟内存地址。
- 物理地址空间:是指CPU通过其地址引脚直接访问的内存(RAM、ROM、映射的I/O等)的范围。
- 虚拟地址空间:是指通过虚拟内存管理,操作系统提供给应用程序和进程的一套地址,这些地址会通过MMU映射到物理地址空间中的实际位置。
-
进程空间:
进程空间(有时称为进程的虚拟地址空间)是指分配给单个进程的内存区域,它是进程可见的地址空间。每个进程都有自己的独立的虚拟地址空间,操作系统和MMU负责将此虚拟地址空间映射到物理地址空间上。这意味着两个不同的进程可以使用相同的虚拟地址指向不同的物理内存或者映射到相同的物理地址但是拥有不同的权限和属性。
地址空间和进程空间的关系:
-
隔离性:每个进程拥有独立的虚拟地址空间,这样即使它们的虚拟地址相同,也不会相互影响,因为这些地址映射到物理地址空间的不同部分。这提供了良好的安全性和稳定性,因为进程不能直接访问其他进程的内存。
-
映射:操作系统的内存管理系统负责将进程的虚拟地址空间映射到物理地址空间。这通常通过页表完成,页表存储了虚拟地址到物理地址的映射信息。
-
共享:尽管每个进程有自己独立的虚拟地址空间,但是有时候不同的进程需要共享内存。操作系统可以将同一块物理内存映射到多个进程的虚拟地址空间中,这通常用于进程间通信或共享库的映射。
因此,地址空间是处理器级别的内存寻址概念,而进程空间是操作系统级别的内存隔离和管理概念。操作系统通过虚拟内存管理技术,为每个进程创建了一种错觉,使其认为自己拥有连续的、独立的内存区域,而实际上它们是在共享同一个物理地址空间。
| 特性 | 地址空间 | 进程空间 |
|---|---|---|
| 定义 | CPU可以寻址的全部内存范围,包括物理和虚拟内存。 | 分配给单个进程的虚拟内存区域,是进程可见和可操作的内存范围。 |
| 类型 | 物理地址空间和虚拟地址空间。 | 每个进程的虚拟地址空间。 |
| 用途 | CPU访问内存和其他资源的能力。 | 隔离进程,确保进程内存访问的独立性和安全性。 |
| 管理 | 由CPU和MMU负责物理和虚拟地址的映射。 | 由操作系统负责管理,确保每个进程有独立的地址空间。 |
| 隔离性 | 无(物理地址空间是共享的)。 | 高(每个进程的虚拟地址空间彼此隔离)。 |
| 共享 | 物理内存可以被多个进程共享(如通过共享内存)。 | 虚拟地址空间通常是独立的,但可以有映射到相同物理内存的部分。 |
| 映射关系 | 虚拟地址空间到物理地址空间的映射由页表或段表管理。 | 进程的虚拟地址空间到物理地址空间的映射通过操作系统的内存管理器控制。 |
| 大小 | 取决于CPU架构(32位、64位等)。 | 取决于操作系统和系统配置,但通常每个进程的虚拟空间都有一个上限。 |
| 多样性 | 通常一个系统中物理和虚拟地址空间是统一的。 | 每个进程的进程空间可以不同,取决于其内存需求和操作系统的分配。 |
8.补充笔记:一个CPU有几个基址寄存器和界限寄存器?一个CPU有几个地址空间和进程空间?一个CPU有几个MMU?
CPU的基址寄存器和界限寄存器的数量,地址空间和进程空间的数量,以及MMU(内存管理单元)的数量,这些都不是固定的,而是取决于具体的CPU设计和它的用途。
-
基址寄存器和界限寄存器:
基址寄存器和界限寄存器主要用于分段内存管理。在分段内存管理系统中,每个段(segment)通过一对基址(base)和界限(limit)寄存器来描述。这样的寄存器对的数量取决于CPU的架构和设计。例如,较旧的x86架构的处理器可能只有几个用于分段的基址和界限寄存器(如CS, DS, ES, FS, GS, SS等),而更现代或者专用的处理器可能有更多或根本不使用分段内存管理。 -
地址空间和进程空间:
一个CPU通常管理一个地址空间,即它可以通过其地址线访问的全部内存范围。但这个地址空间可以通过不同的机制(如分页或分段)被映射到多个进程空间。每个进程空间可以想象成一个独立的地址空间,它是操作系统通过虚拟内存管理功能提供给单个进程的内存视图。理论上,一个操作系统可以支持任意多个进程空间,但实际上这受限于系统的物理内存、虚拟内存限制和操作系统设计。 -
MMU(内存管理单元):
大多数现代CPU会有一个内存管理单元(MMU)。MMU负责虚拟地址到物理地址的转换,并且通常支持分页或分段机制。一般情况下,每个CPU核心会有一个MMU。在多核心处理器中,每个核心可能有自己的MMU,或者有些设计可能共享一个MMU。
在讨论具体的CPU时,需要参考该CPU的技术手册或架构文档来获取准确的寄存器和硬件特性信息。