ICLR 2024 reviewer 评分 35668
1 intro
1.1 地理空间预测
- 地理空间预测在各个领域都有广泛的应用
- 包括贫困估算,公共卫生,粮食安全,生物多样性保护,环境保护。。。
- 这些预测中使用的变量包括地理坐标、遥感数据、卫星图像、人类移动数据和手机元数据
- 尽管获取高质量协变量至关重要,但由于空间时间覆盖范围有限、成本高昂和获取障碍,这可能会面临挑战
1.2 论文背景
- LLM压缩了其训练语料库中包含的知识,其中包括来自互联网的数十亿或数万亿的数据令牌
- 论文寻求理解LLM是否拥有地理空间知识,并探索提取此类知识的方法,以提供一套新的地理空间协变量,从而增强各种地理空间ML任务
- 如图1a所示,仅通过查询LLM来描述一个地址,就可以揭示出LLM中包含的大量地理空间知识

- 然而,从LLM中提取这些知识并非易事。
- 虽然最自然的接口涉及使用地理坐标,如纬度和经度来检索特定位置信息,但如图1b所示,这通常会产生不佳的结果。
- 困难在于LLM能否理解并解释这些数字坐标与实际位置之间的关系

1.3 论文思路
- 介绍了GeoLLM,一种新颖的方法
- 通过对LLM进行微调,利用构建的提示与OpenStreetMap的辅助地图数据,有效提取LLM中包含的丰富地理空间知识
- 通过在图1b中展示的提示策略,可以精确定位一个位置,并为LLM提供足够的空间上下文信息,从而使其能够访问并利用其广泛的地理空间知识
- 在提示中包括来自附近位置的信息,可以将GPT-3.5的性能提高3.3倍,相比仅提供目标位置的坐标
3 方法
- 抽象地说,论文希望将地理坐标(纬度、经度)和附加特征映射到响应变量,如人口密度或资产财富
- 目标是确定LLM对这些坐标了解多少,以及我们如何使用这些知识更好地预测感兴趣的响应变量
3.1 最小可行地理空间提示

- 一个最小可行的提示需要指定位置和预测任务
- 描述包括任务的名称和指示可能标签范围的规模
- 论文发现添加任务名称有帮助,但更具体的信息,如数据集名称,通常没有帮助
3.1.1 接近回归的分类任务
- 由于必须通过文本为LLM指定标签,论文使用分类而不是回归
- 论文发现更接近回归的分类任务(例如,0.0到9.9而不是1到5)是有益的,尽管LLM使用softmax
- 如果原始数据集已经具有近似均匀分布,则简单地将值缩放到0到9.9的范围,并四舍五入到一位小数
- 如果数据集本身不是均匀的,则将值均匀地分布在100个桶中,以维持均匀分布。然后,每个桶与0.0到9.9的值范围相关联。
3.2 带地图数据的提示
- 上述提示有一个主要限制——LLM难以识别坐标的位置
- ——>确保提示包含额外的上下文,帮助模型理解坐标的位置
- ——>使用地图数据构建了两个额外组件:
- 地址:详细的反向地理编码描述,包括从邻域级别到国家本身的地点名称
- 使用Nominatim进行反向地理编码生成地址
- 附近地点:在100公里半径内最近的10个位置及其各自的名称、距离和方向列表
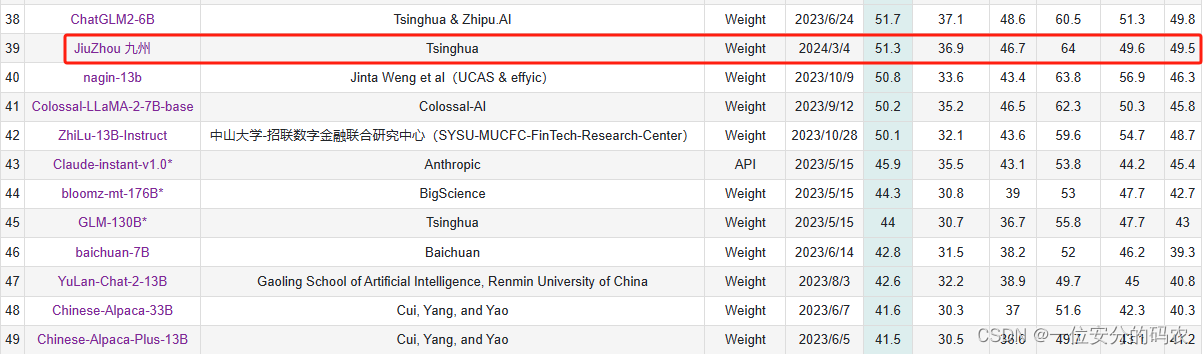
- 从Overpass API获取附近地点的名称和位置
- 地址:详细的反向地理编码描述,包括从邻域级别到国家本身的地点名称


3.3 使用语言模型进行微调和推理
- RoBERTaBASE
- 对模型进行了微调,其所有参数均可训练。
- 它接受整个提示并输出一个连续值,将其四舍五入到最近的桶
- Llama 2 7B
- 尽管不适合回归任务,但由于训练了更多数据,它有潜力表现良好
- 类似于预训练模式,将prompt和label连接,使用无监督学习对Llama 2进行微调
- 将prompt和对应的ground-truth标签作为一个整体,使用自回归的方式进行微调
- 论文发现这种无监督学习比使用监督微调效果更好
- 这意味着模型正在学习生成提示和标签
- 学习给定坐标生成地址或使用坐标和地址生成附近地点是有益的
- 推理时:提供提示,并让它生成预测所需的三个令牌(例如,“9”、“。”和“9”)
- QLoRA能够大大降低计算成本,并仅用3300万可训练参数有效进行微调
- 由于它还将冻结模型量化为4位,这带来了可能稀释权重中包含的知识
- GPT-2
- 使用与Llama 2相同的微调和推理过程
- GPT-3.5
- 通过OpenAI的微调API对GPT-3.5进行微调
- 与Llama 2类似,提供它提示,并让它生成完成所需的三个令牌
4 实验
4.1 任务
4.1.1 人口密度
- WorldPop提供空间人口数据,覆盖了全世界的人口密度任务
- 使用了他们的2020年全球无约束拼图,其分辨率为30弧秒(赤道上约1km)
- 为了确保全面代表人口,采用了按人口加权的重要性抽样。这使我们能够捕获广泛的人口范围
- 如果没有重要性抽样,样本将主要由人口稀少的地区组成
4.1.2 人口相关指数
- 包括了从人口与健康调查(DHS)计划中派生的任务
- 供了48个国家家庭层面的、全国代表性的有关资产、住房条件和教育水平等属性的数据
- 使用资产财富指数、女性教育成就、卫生指数和女性BMI
4.1.3 美国人口普查
- USCB 美国人口普查局所称的邮政编码制表区域的人口、平均收入和西班牙裔与非西班牙裔比例的任务
4.1.4 住房价值指数
- 反映了35%到65%百分位范围内房屋的典型价值
- 也在邮政编码级别使用这些数据
- 这个数据集也只覆盖美国
4.1.5 数据集的处理
- 当数据集中没有给出明确的坐标时,通过确定相关区域的中心来近似它们
- 近似每个邮政编码区域的中心
- 使用平方皮尔逊相关系数r²来评估性能
4.2 实验结果
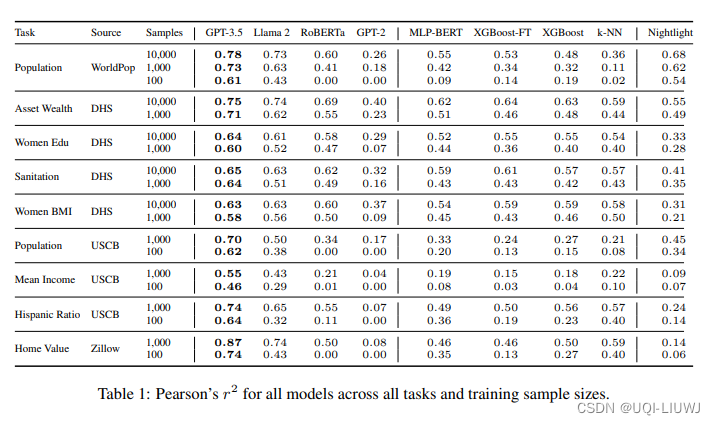
4.2.1 预测结果
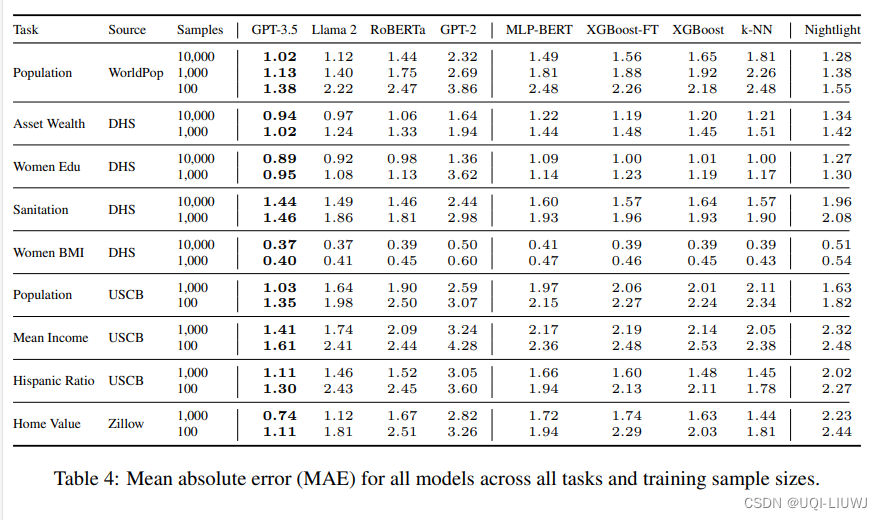



4.2.2 关于提示的消融研究

4.2.3 finetune 是否需要?
【部分来源于paper的rebuttal】
- 使用未经微调的基于聊天的LLMs的主要问题是,它们经常拒绝给出答案,特别是在偏远或不太发达的地区
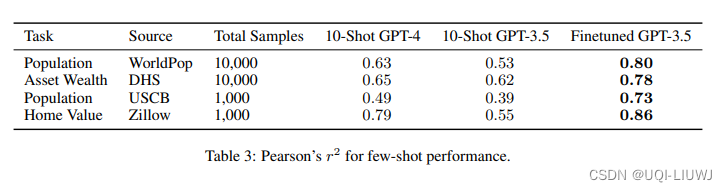
- 零样本(zero-shot)是不可靠的,所以论文补充测试了一下few-shot的内容
- 通过为每个测试示例提供10个物理距离最近的训练样本序列,来展示它们的few-shot性能
- 为了进一步防止模型拒绝回答,我们在提供10个示例之前使用系统消息“你是一个详尽且知识渊博的地理学家”和“你用预测/估计来完成数据序列”
- 微调后的GPT-3.5大幅度超过了GPT-3.5甚至GPT-4






![[Python] 如何导出PDF文件中的图片](https://img-blog.csdnimg.cn/direct/16265d42e9534caa818210d235dc0de6.png#pic_center)