文章目录
- 总结部署流程
- Alertmanager 三大核心
- 1. 分组告警
- 2. 告警抑制
- 3. 告警静默
- 报警过滤
- 静默通知
- 方案一:
- 方案二:
- 抑制报警规则
- 案例一
- 参考文档
- 自定义路由告警,分来自不同路由的告警,艾特不同的人员进行区分
- 修改 alertmanager 配置有俩种方法
- Alertmanager CRD
- **案例介绍**
- **环境概述**
- **快速开始**
- 1-查看现有的规则配置文件
- 1-secret方式
- 1.2-修改 secret alertmanager-main
- 1.2.1查看日志看看有没有报错
- 查看生成的 secret alertmanager-main
- 1.3- 查看Alertmanager——ui页面
- 1.4查看报警
- 1.2 配置告警模板
- 1.2.1创建 wechat.tmpl模板
- 1.2.2创建 configmap
- 1.3查看企业微信报警
- 分级别告警
- 设置告警监控所有命名空间pod
- 1.1修改 alertmanager.yaml
- 1.2更新 secret
- 1.3配置告警规则
- 1.4查看报警
- 优化
- 优化一:
- 优化二
- 优化三
- 2.1-AlertmanagerConfig方式
- 这个方式我没有做出来,如果有大佬 做出来可以私信我
- 详解一
- 详解二:
- 方案选择:
- 方案需求
- 第二种方案:创建 Webhook 服务
- 2.1创建webhook服务
总结部署流程
部署Alertmanager
配置Prometheus与Alertmanager通信
配置告警
prometheus指定rules目录 ,创建告警yaml
configmap存储告警规则
configmap挂载到容器rules目录
增加alertmanager告警配置,有俩种方式下面注意下
这里是定义谁发送这个告警信息的,谁接收这个邮件
Alertmanager 三大核心
1. 分组告警
分组告警是指:prometheus的告警规则是对所有监控实例都生效的,当同一种类型的告警触发后会汇聚一起,并且发送一个告警消息,降低告警噪音。
AlertManager告警分组参数
route:
//根据标签进行分组,alertname就是告警规则的名称,多个标签可以以逗号隔开
group_by: ['alertname']
//发送告警等待时间,也就是一个时间范围内,如果同一组中有其他报警则一并发送
group_wait: 10s
//当触发了一组告警后,下一组报警触发的间隔
group_interval: 10s
//告警产生没有修复重复报警的时间间隔
repeat_interval: 10m
2. 告警抑制
通过抑制可以避免产生大量的告警风暴,当一个节点宕机设置标签为serverity=critical,而节点上的应用告警设置为serverity=warning,当节点宕机后可以使用抑制的方法,仅发送一条节点宕机的信息,而不是发送多条信息。
aertManager告警抑制参数
inhibit_rules:
- source_match:
// 源标签警报触发时抑制含有目标标签的警报,在当前警报匹配serverity=critical
serverity: 'critical'
target_match:
// 抑制`serverity=warning`类型告警
serverity: 'warning'
// 告警中包含的分组名称。标签内容相同才会抑制,也就是说警报中三个标签值相同才会被抑制。equal: ['alertname', 'dev', 'instance']
Prometheus 告警级别
告警级别分为warning、critical和emergency。严重等级依次递增。
3. 告警静默
静默是指定周期时间内不再触发某一个报警。alertManager将检查传入警报是否与活动静默的所有相等或正则表达式匹配。匹配静默规则,则不会为该警报发送任何通知。
Alertmanager Web UI 设置静默告警规则
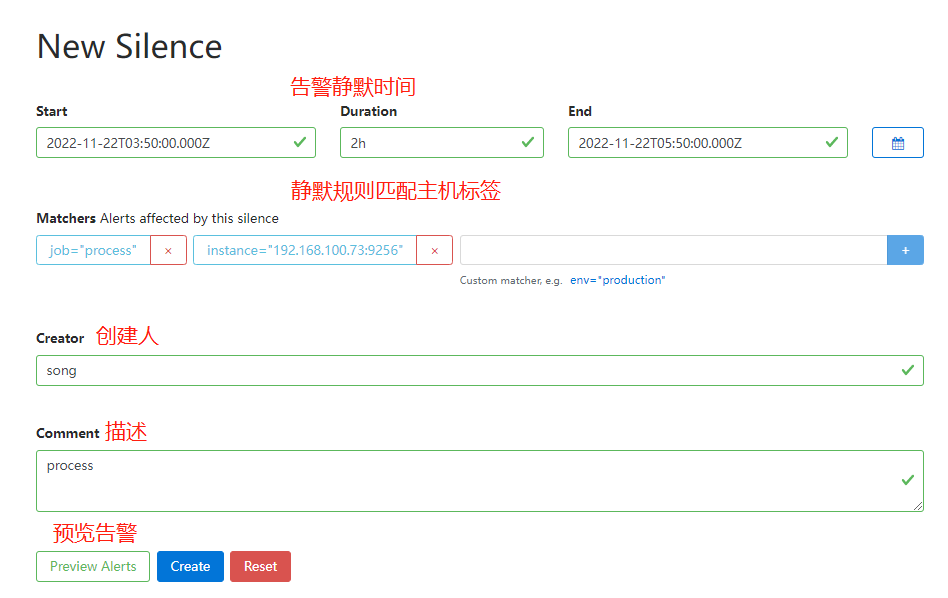
报警过滤
有的时候可能报警通知太过频繁,或者在收到报警通知后就去开始处理问题了,这个期间可能报警还在频繁发送,这个时候我们可以去对报警进行静默设置。
静默通知
方案一:
在 Alertmanager 的后台页面中提供了静默操作的入口。
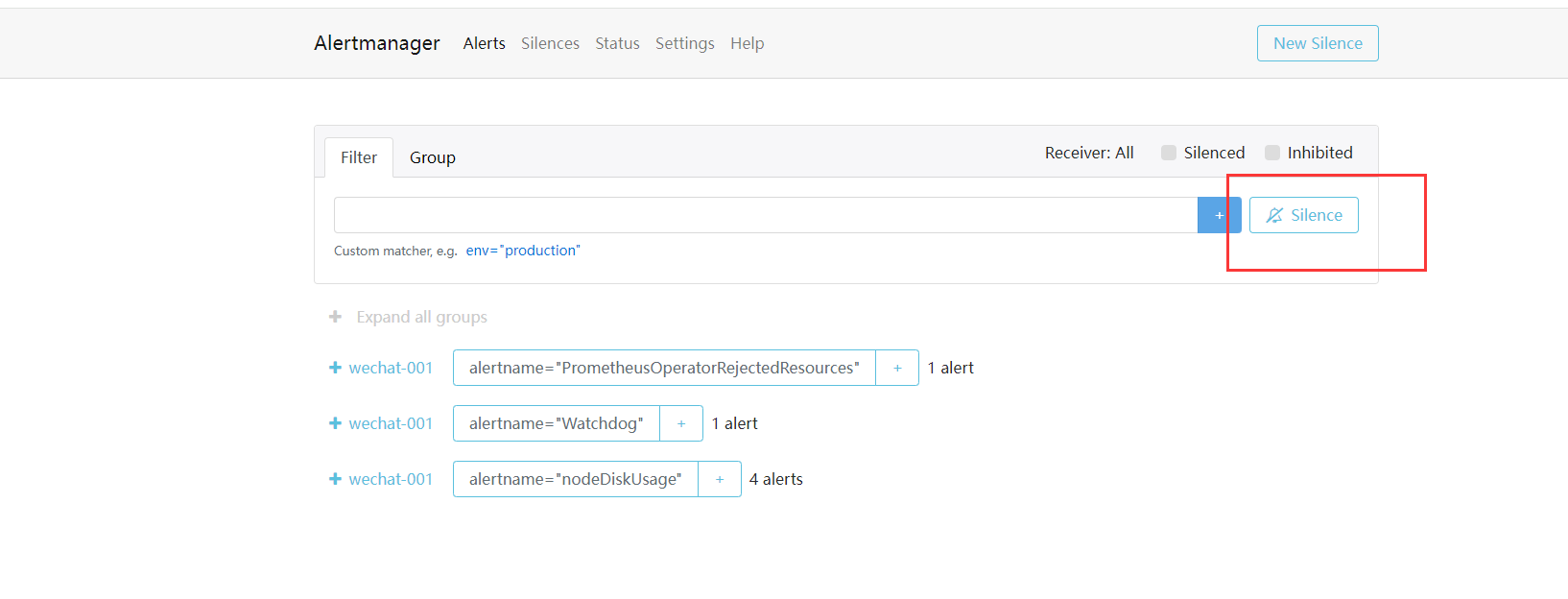
可以点击右上面的 New Silence 按钮新建一个静默通知
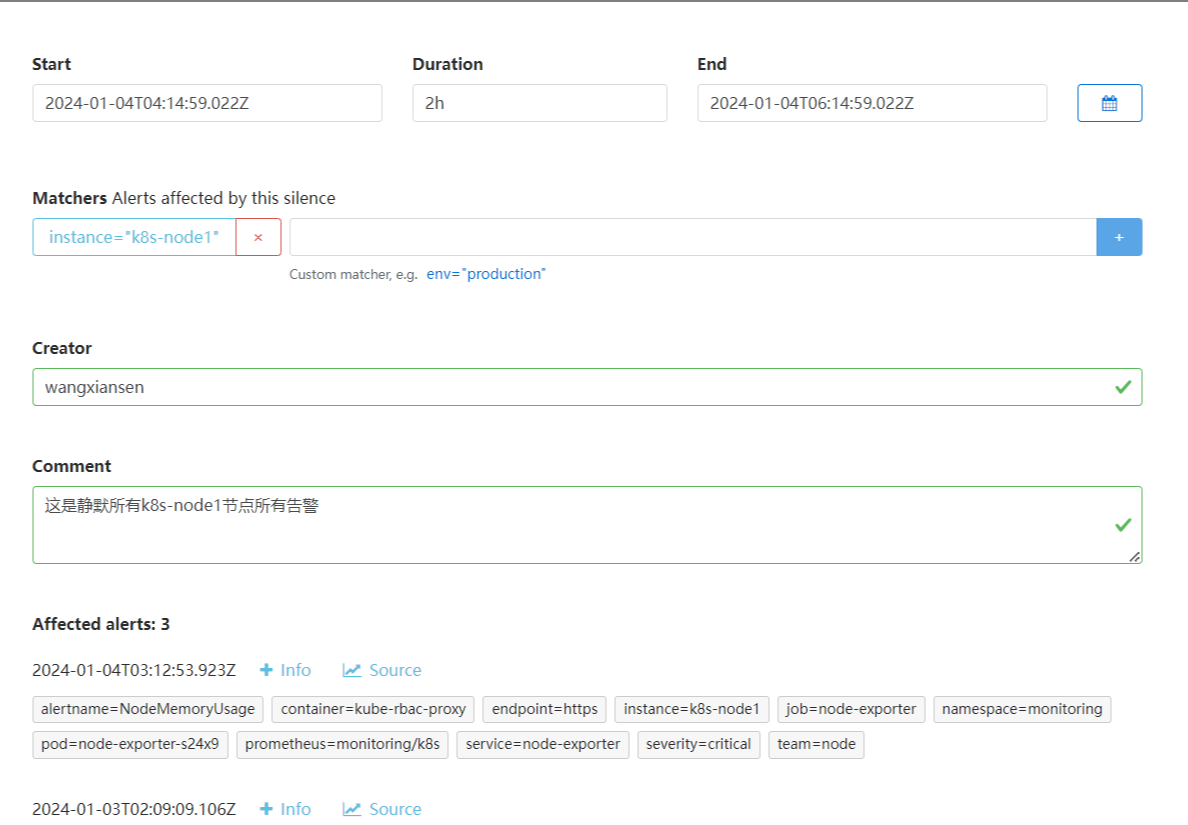
我们可以选择此次静默的开始时间、结束时间,最重要的是下面的 Matchers 部分,用来匹配哪些报警适用于当前的静默,比如这里我们设置 instance=k8s-node1 的标签,则表示具有这个标签的报警在 2 小时内都不会触发报警,点击下面的 Create 按钮即可创建:

方案二:

抑制报警规则
除了上面的静默机制之外,Alertmanager 还提供了抑制机制来控制告警通知的行为。抑制是指当某次告警发出后,可以停止重复发送由此告警引发的其他告警的机制,比如现在有一台服务器宕机了,上面跑了很多服务都设置了告警,那么肯定会收到大量无用的告警信息,这个时候抑制就非常有用了,可以有效的防止告警风暴。
要使用抑制规则,需要在 Alertmanager 配置文件中的 inhibit_rules 属性下面进行定义,每一条抑制规则的具体配置如下:
target_match:
[ <labelname>: <labelvalue>, ... ]
target_match_re:
[ <labelname>: <regex>, ... ]
target_matchers:
[ - <matcher> ... ]
source_match:
[ <labelname>: <labelvalue>, ... ]
source_match_re:
[ <labelname>: <regex>, ... ]
source_matchers:
[ - <matcher> ... ]
[ equal: '[' <labelname>, ... ']' ]
# 当有新的告警规则如果满足 `source_match` 或者 `source_match_re` 的匹配规则,并且已发送的告警与新产生的告警中
`equal` 定义的标签完全相同,则启动抑制机制,新的告警不会发送。
# 当已经发送的告警通知匹配到 `target_match` 和 `target_match_re` 规则
案例一
比如现在我们如下所示的两个报警规则 NodeMemoryUsage 与 NodeLoad
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: node
namespace: default
spec:
groups:
- name: node-mem
rules:
- alert: NodeMemoryUsage
annotations:
description: '{{$labels.instance}}: 内存使用率高于 30% (当前值为: {{ printf "%.2f" $value }}%)'
summary: '{{$labels.instance}}: 检测到高内存使用率'
expr: |
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) /
node_memory_MemTotal_bytes * 100 > 30
for: 1m
labels:
team: node
severity: critical
- name: node-load
rules:
- alert: NodeLoad
annotations:
summary: '{{ $labels.instance }}: 低节点负载检测'
description: '{{ $labels.instance }}: 节点负载低于 1 (当前值为: {{ $value }})'
expr: node_load5 < 1
for: 2m
labels:
team: node
severity: normal
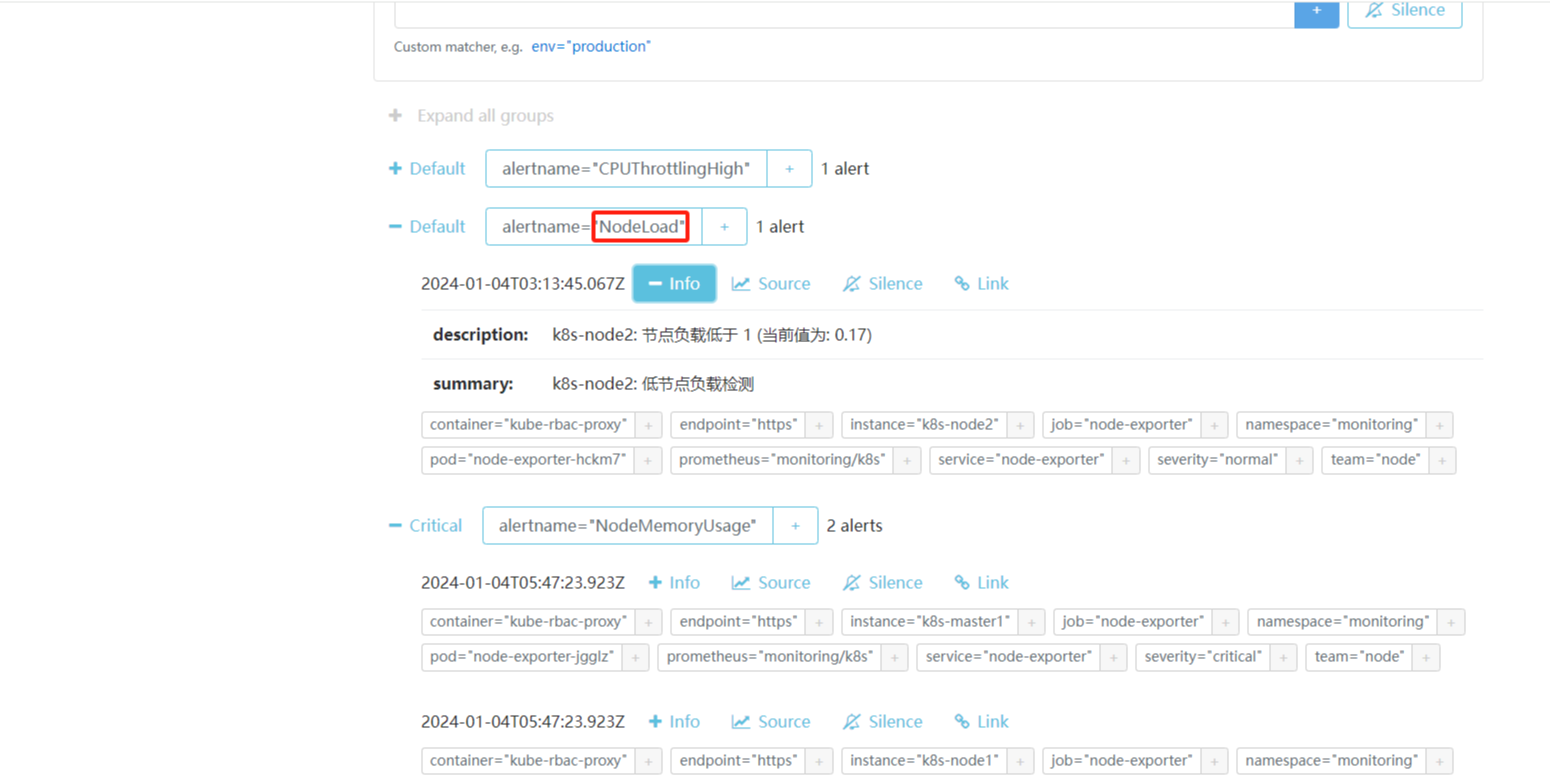
当前我们系统里面普通(severity: normal)的告警有三条,k8s-node1、k8s-node2 和 k8s-master 三个节点,另外一个报警也有俩条,k8s-node1和 k8s-master 三个节点:
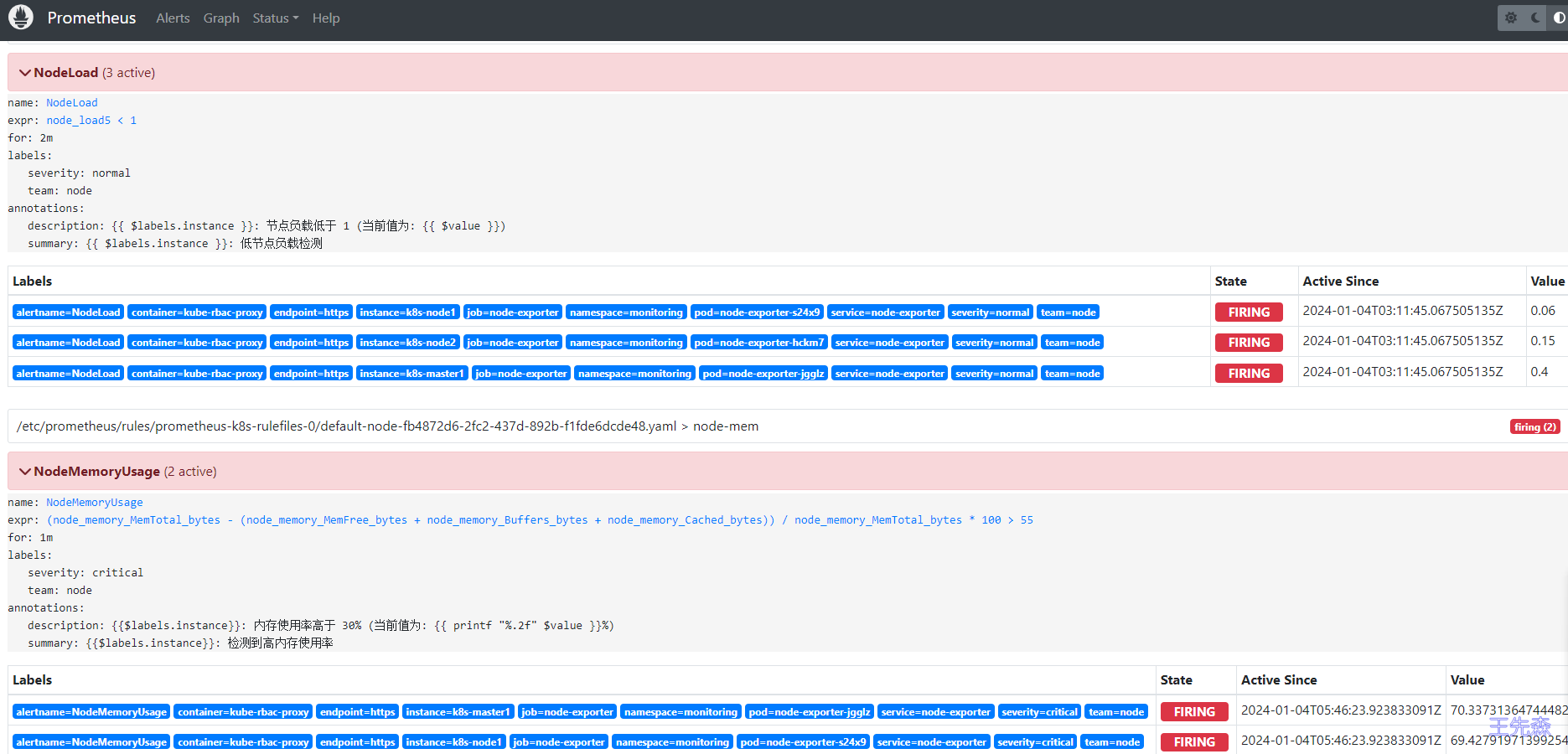
现在我们来配置一个抑制规则,如果 NodeMemoryUsage 报警触发,则抑制 NodeLoad 指标规则引起的报警,我们这里就会抑制 k8s-master 和 k8s-node1 节点的告警,只会剩下 k8s-node2 节点的普通告警。
通过修改Alertmanager 配置文件中添加如下所示的抑制规则
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: email-config
namespace: monitoring
labels:
alertmanagerConfig: wangxiansen
spec:
route:
groupBy: ['alertname']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'Critical'
continue: false
routes:
- receiver: 'Critical'
match:
severity: critical
receivers:
- name: Critical
emailConfigs:
- to: '@boysec.cn'
html: '{{ template "email.html" . }}'
sendResolved: true
inhibitRules:
- equal: ['instance']
sourceMatch:
- name: alertname
value: NodeMemoryUsage
- name: severity
value: critical
targetMatch:
- name: severity
value: normal
更新报警规则
kubectl create secret generic alertmanager-main -n monitoring --from-file=alertmanager.yaml --dry-run=client -o yaml > alertmanager-main-secret.yaml
kubectl apply -f alertmanager-main-secret.yaml
更新配置后,最好重建下 Alertmanager,这样可以再次触发下报警,可以看到只能收到 k8s-node2 节点的 NodeLoad 报警了,另外两个节点的报警被抑制了:
参考文档
1-alertmanager 实现不同的告警级别发送给不同的接收人
文章参考 https://cloud.tencent.com/developer/article/2216582?areaId=106001
2-自定义路由告警,分来自不同路由的告警,艾特不同的人员进行区分
文章参考 https://cloud.tencent.com/developer/article/2327646?areaId=106001
3-根据不同告警级别设置发送接受器
文章参考 https://blog.51cto.com/u_12965094/2689914
自定义路由告警,分来自不同路由的告警,艾特不同的人员进行区分
修改 alertmanager 配置有俩种方法
Alertmanager CRD
Prometheus Operator 为 alertmanager 抽象了两个 CRD资源:
可以理解为俩中方式更新alertmanager,
alertmanagerCRD: 基于 statefulset, 实现 alertmanager 的部署以及扩容缩容
这种方式是新建 `alertmanager.yaml` 配置文件,生成 secret更新替代默认的。
注意,这个相当于总配置文件,需要在`alertmanager.yaml`填写的东西比较多,模板,分组什么的。。。。。
- **如果您的需求比较简单,或者不需要分割配置权限**,直接使用 `alertmanager.yaml` 并通过 Secret 应用,如您所做的,就足够了。这种方式简单直接,适用于许多场景。
alertmanagerconfigCRD: 实现模块化修改 alertmanager 的配置
如果您使用的是较新版本的 Prometheus Operator**,它支持 `AlertmanagerConfig` 资源,这是一种更为声明式的方法来定义 Alertmanager 的配置。通过使用AlertmanagerConfig资源,您可以更方便地在多个团队之间分割告警配置,每个团队可以管理自己的告警路由、接收器等,而不需要直接编辑 `alertmanager.yaml` 文件。这对于多租户环境非常有用。简单一点就是更新内容上去,不会改变默认的
global:
resolve_timeout: 5m # 该参数定义了当Alertmanager持续多长时间未接收到告警后标记告警状态为resolved
http_config: {} # HTTP 配置,此处为空对象,表示没有特定的配置
smtp_hello: localhost # SMTP 邮件发送时使用的 HELO 消息
smtp_require_tls: true # SMTP 邮件发送是否需要使用 TLS
pagerduty_url: https://events.pagerduty.com/v2/enqueue # PagerDuty API URL
opsgenie_api_url: https://api.opsgenie.com/ # Opsgenie API URL
wechat_api_url: https://qyapi.weixin.qq.com/cgi-bin/ # 微信企业号 API URL
victorops_api_url: https://alert.victorops.com/integrations/generic/20131114/alert/ # VictorOps API URL
route:
receiver: Default # 默认的接收器名称
group_by: # 分组字段,用于将警报按照指定字段进行分组
- namespace # 按照命名空间分组
routes: # 路由规则列表
- receiver: Watchdog # 接收器名称为 Watchdog 的路由规则
match: # 匹配条件
alertname: Watchdog # 匹配警报名称为 Watchdog 的警报
- receiver: Critical # 接收器名称为 Critical 的路由规则
match: # 匹配条件
severity: critical # 匹配严重程度为 critical 的警报
group_wait: 30s # 在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内发送报警。
group_interval: 5m # 如果组内内容不变化,合并为一条警报信息,5m后发送。
repeat_interval: 12h # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
inhibit_rules: # 抑制规则列表,用于控制警报传播的行为
- source_match: # 源警报匹配条件
severity: critical # 源警报的严重程度为 critical
target_match_re: # 目标警报匹配条件(使用正则表达式进行匹配)
severity: warning|info # 目标警报的严重程度为 warning 或 info
equal: # 需要匹配相等的字段
- namespace # 命名空间字段需要相等
- alertname # 警报名称字段需要相等
- source_match: # 源警报匹配条件
severity: warning # 源警报的严重程度为 warning
target_match_re: # 目标警报匹配条件(使用正则表达式进行匹配)
severity: info # 目标警报的严重程度为 info
equal: # 需要匹配相等的字段
- namespace # 命名空间字段需要相等
- alertname # 警报名称字段需要相等
receivers: # 接收器列表
- name: Default # 默认接收器
- name: Watchdog # Watchdog 接收器
- name: Critical # Critical 接收器
templates: [] # 模板列表,此处为空列表,表示没有定义任何模板
案例介绍
基于自定义路由告警,我们依旧使用prometheusAlert作为告警渠道,为了方便区分来自不同路由的告警,我们这里使用不同分组进行告警
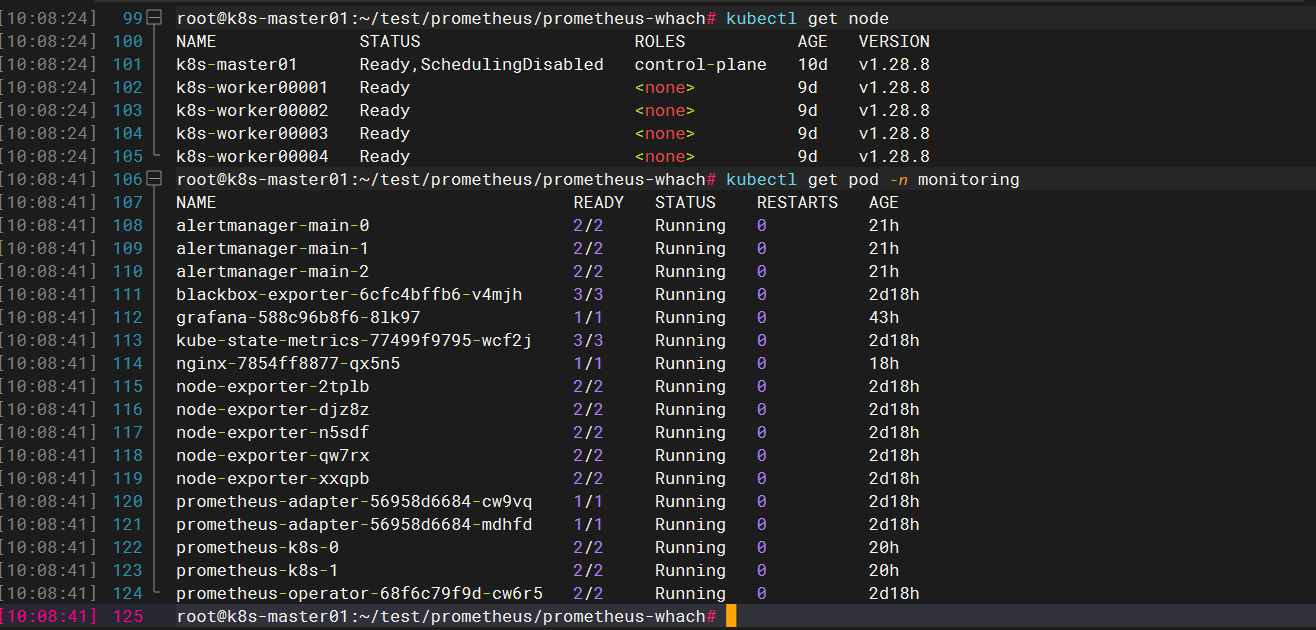
环境概述
root@k8s-master01:~/test/prometheus/prometheus-whach# kubectl get pod -n monitoring
root@k8s-master01:~/test/prometheus/prometheus-whach# kubectl get node
快速开始
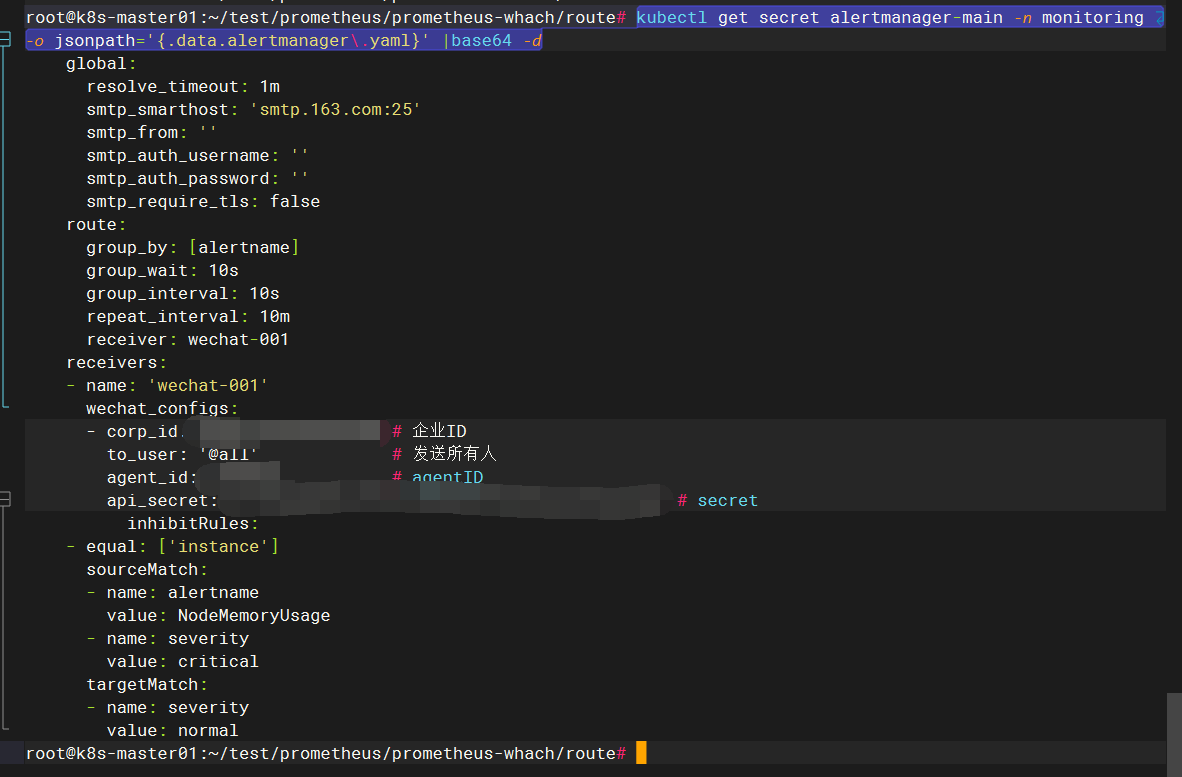
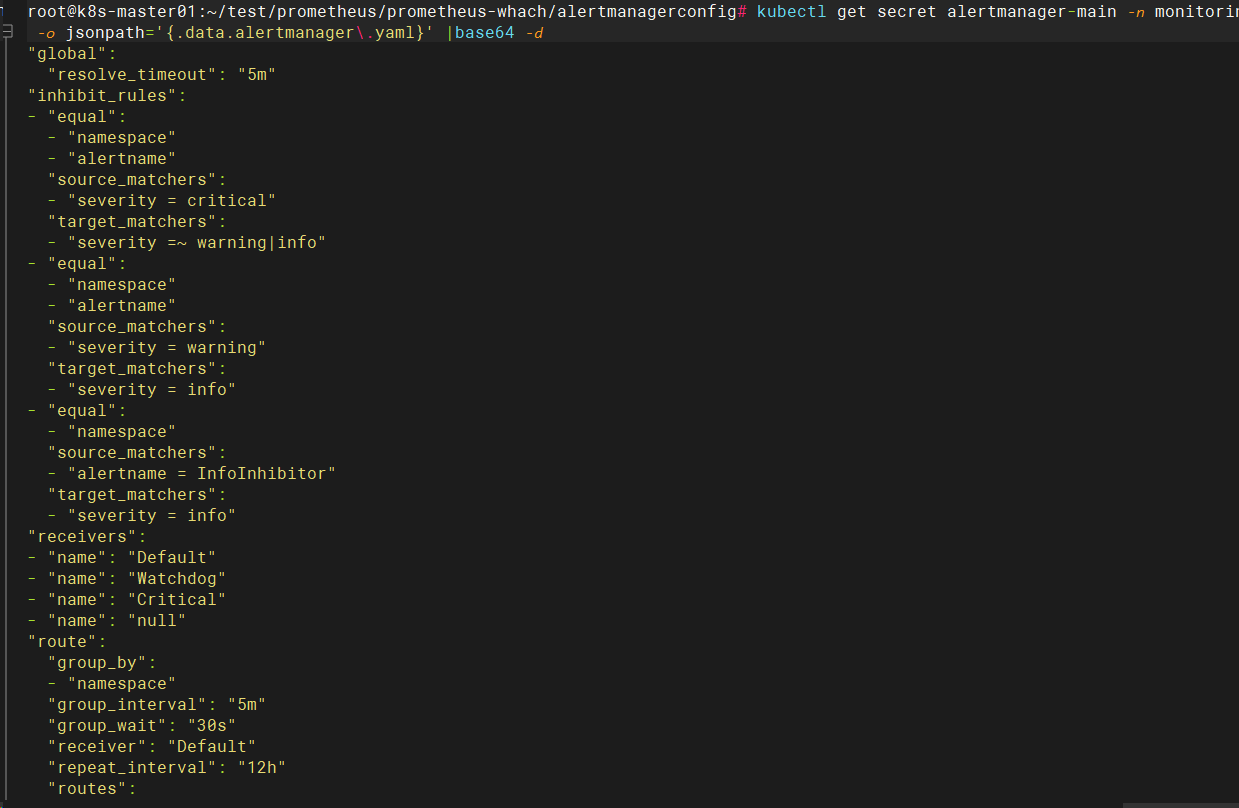
1-查看现有的规则配置文件
kubectl get secret alertmanager-main -n monitoring -o jsonpath='{.data.alertmanager\.yaml}' |base64 -d
1-secret方式
新建 alertmanager.yaml 配置文件
相当于总配置文件,需要填写的东西比较多
只需要三个文件

global:
resolve_timeout: 1m # 解决超时时间,指定Alertmanager标记告警状态为已解决(resolved)之前等待的时间
templates:
- '/etc/alertmanager/configmaps/alertmanager-templates/*.tmpl'
route:
receiver: 'ops-err' # 默认的接收器名称
group_wait: 30s # 在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内发送报警。
group_interval: 1m # 如果组内内容不变化,合并为一条警报信息,5m后发送。
repeat_interval: 10m # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
group_by: [alertname, instance] # 报警分组
routes: # 子路由的匹配设置
- matchers:
- severity = warning
receiver: 'ops-err'
continue: true
# 使用新的 matchers 语法匹配严重级别为 warning 的告警,并发送到 ops-err 接收器
- matchers:
- severity =~ error|critical
receiver: 'devops'
continue: true
# 使用新的 matchers 语法和正则表达式匹配严重级别为 error 或 critical 的告警,并发送到 devops 接收器
receivers:
- name: 'devops'
wechat_configs:
- corp_id: '' # 企业ID
to_user: '@all' # 发送所有人
agent_id: '1000002' # agentID
api_secret: '' # secret
# 使用企业微信发送消息
- name: 'ops-critical'
wechat_configs:
- corp_id: '' # 企业ID
to_user: '@all' # 发送所有人
agent_id: '1000005' # agentID
api_secret: '' # secret
# 使用企业微信发送消息
- name: 'ops-err'
wechat_configs:
- corp_id: '' # 企业ID
to_user: '@all' # 发送所有人
agent_id: '1000003' # agentID
api_secret: '' # secret
# 使用企业微信发送消息
1.2-修改 secret alertmanager-main
kubectl create secret generic alertmanager-main -n monitoring --from-file=alertmanager.yaml --dry-run=client -o yaml > alertmanager-main-secret.yaml
kubectl apply -f alertmanager-main-secret.yaml
1.2.1查看日志看看有没有报错
kubectl logs -f prometheus-operator-68f6c79f9d-24fcm -n monitoring

查看生成的 secret alertmanager-main
kubectl get secret alertmanager-main -n monitoring -o jsonpath='{.data.alertmanager\.yaml}' |base64 -d
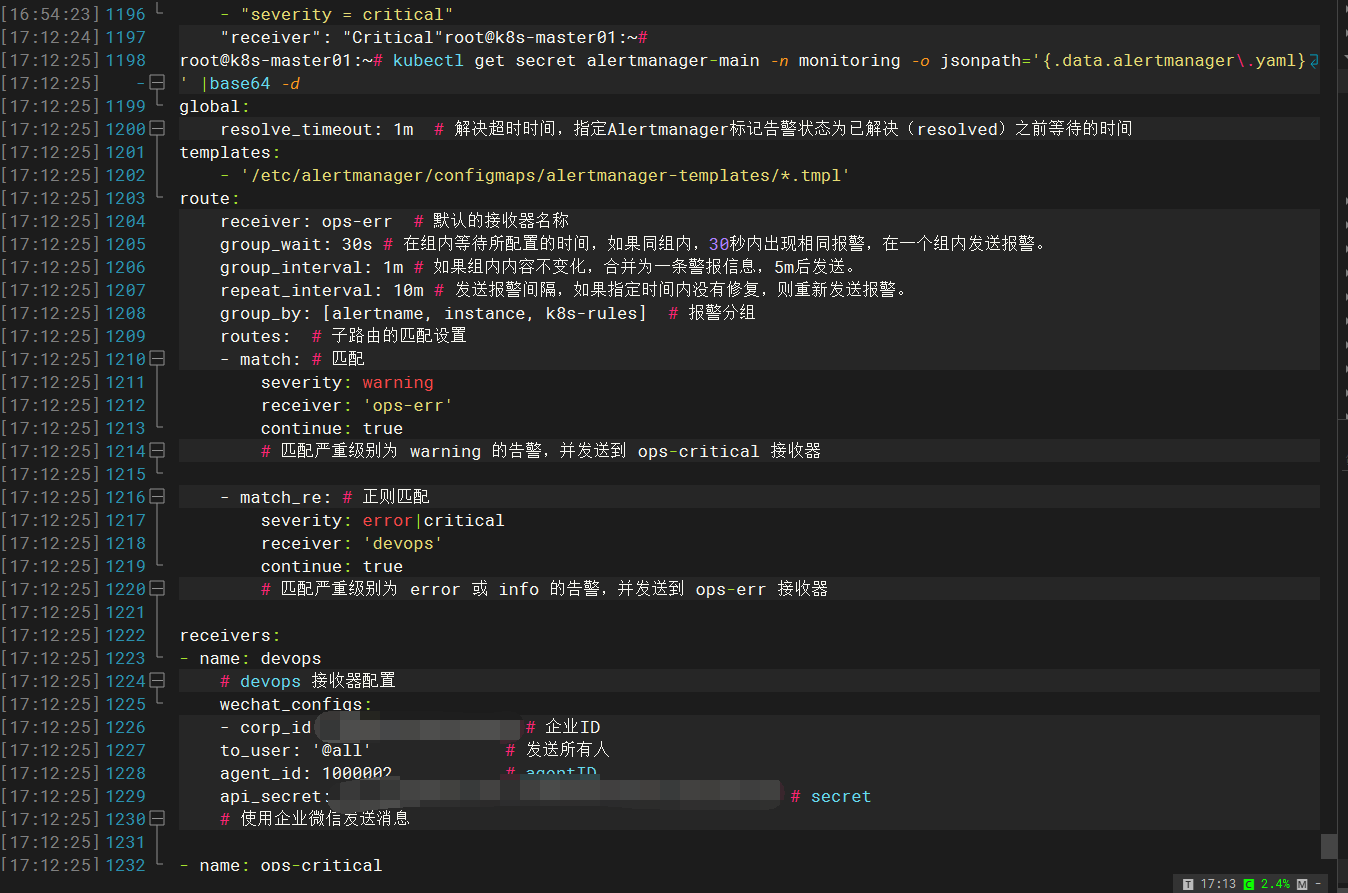
之后 prometheus-operator 会自动更新 alertmanager 的配置
# kubectl logs -n monitoring -l app.kubernetes.io/name=prometheus-operator | tail -1
level=info ts=2023-04-30T11:43:01.104579363Z caller=operator.go:741 component=alertmanageroperator key=monitoring/main msg="sync alertmanager"
1.3- 查看Alertmanager——ui页面
规则变成你定义的拉
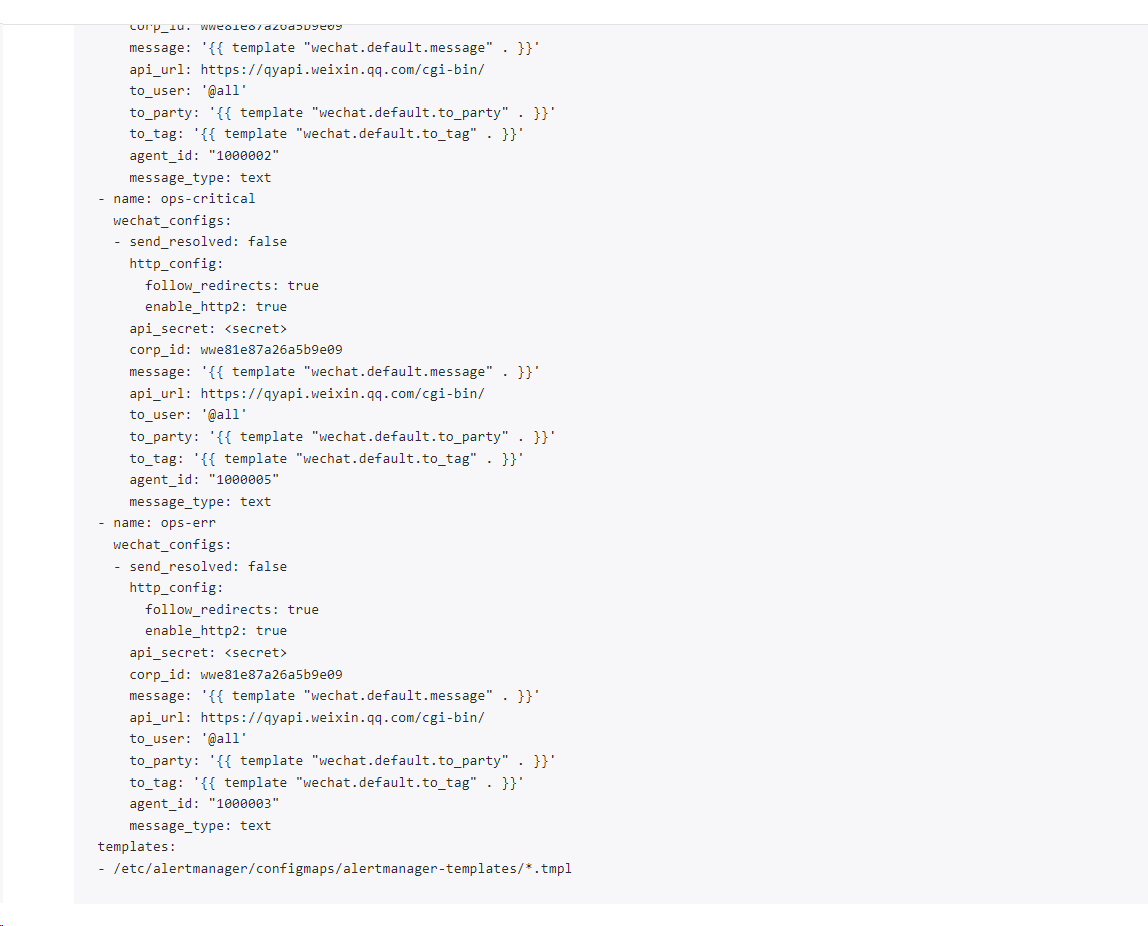
查报警的分组也变成你得定义的路由规则
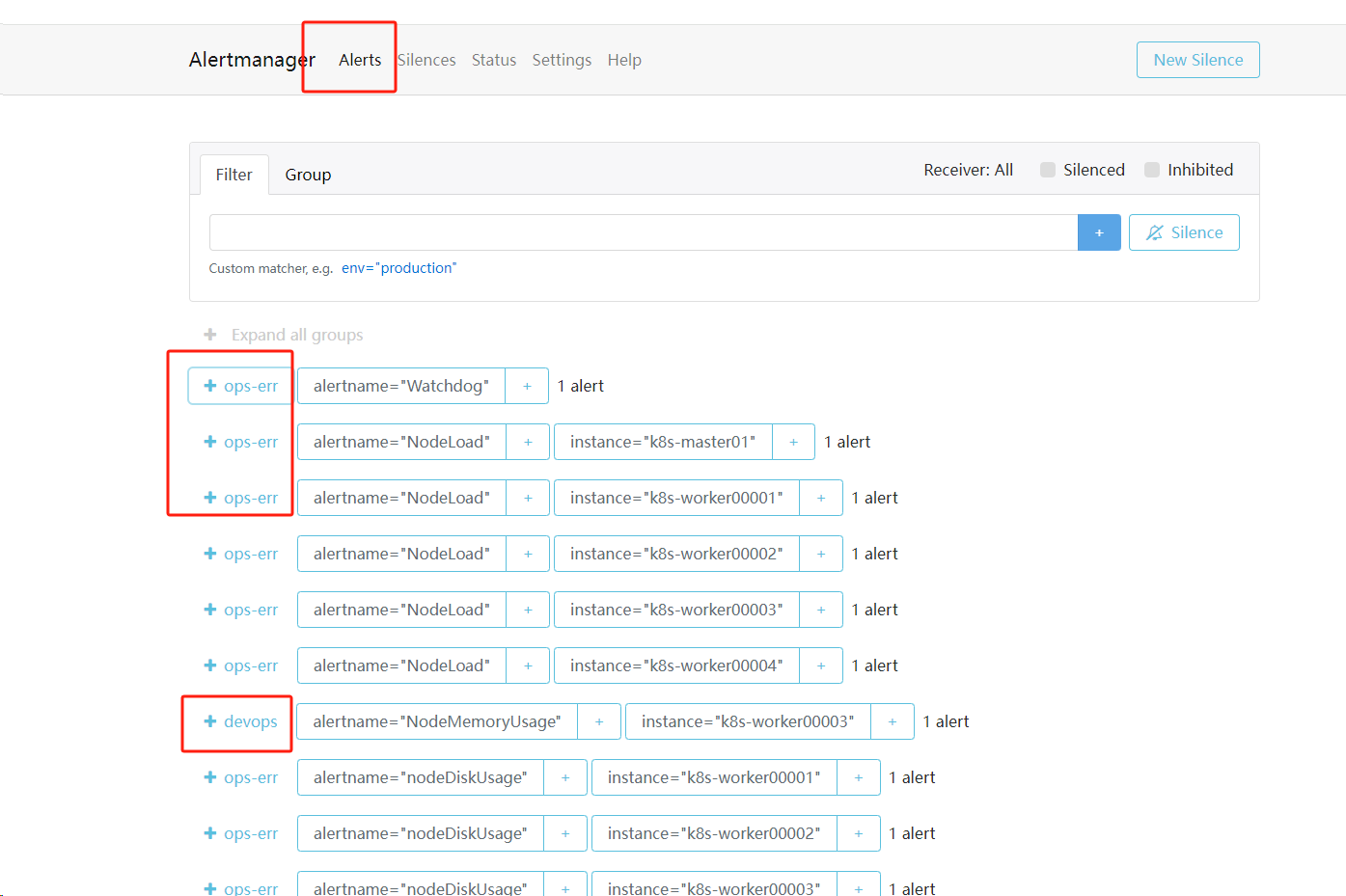
1.4查看报警
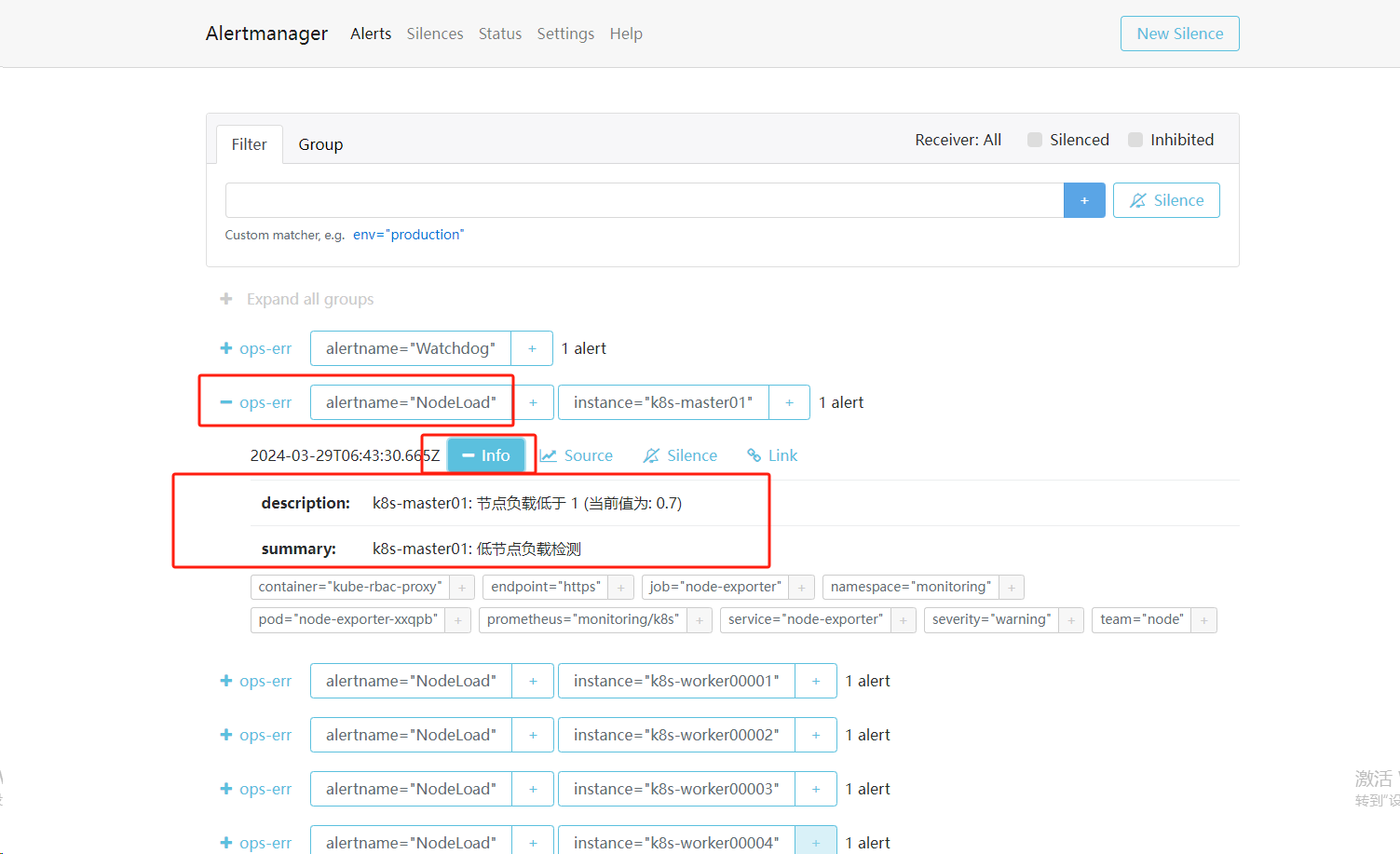
1.2 配置告警模板
1.2.1创建 wechat.tmpl模板
vim WeChat.tmpl
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
=========xxx环境监控报警 =========
告警状态:{{ .Status }}
告警级别:{{ .Labels.severity }}
告警类型:{{ $alert.Labels.alertname }}
故障主机: {{ $alert.Labels.instance }} {{ $alert.Labels.pod }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
触发阀值:{{ .Annotations.value }}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
=========xxx环境异常恢复 =========
告警类型:{{ .Labels.alertname }}
告警状态:{{ .Status }}
告警主题: {{ $alert.Annotations.summary }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
========= = end = =========
{{- end }}
{{- end }}
{{- end }}
{{- end }}
1.2.2创建 configmap
kubectl create configmap alertmanager-templates --from-file=wechat.tmpl --dry-run=client -o yaml -n monitoring > alertmanager-configmap-templates.yaml
kubectl apply -f alertmanager-configmap-templates.yaml
查看挂载
root@k8s-master01:~/test/prometheus/prometheus-whach/route# kubectl get pod -n monitoring alertmanager-main-0 -o jsonpath="{.spec.volumes[?(@.name=='configmap-alertmanager-templates')]}" | python3 -m json.tool
{
"configMap": {
"defaultMode": 420,
"name": "alertmanager-templates"
},
"name": "configmap-alertmanager-templates"
}
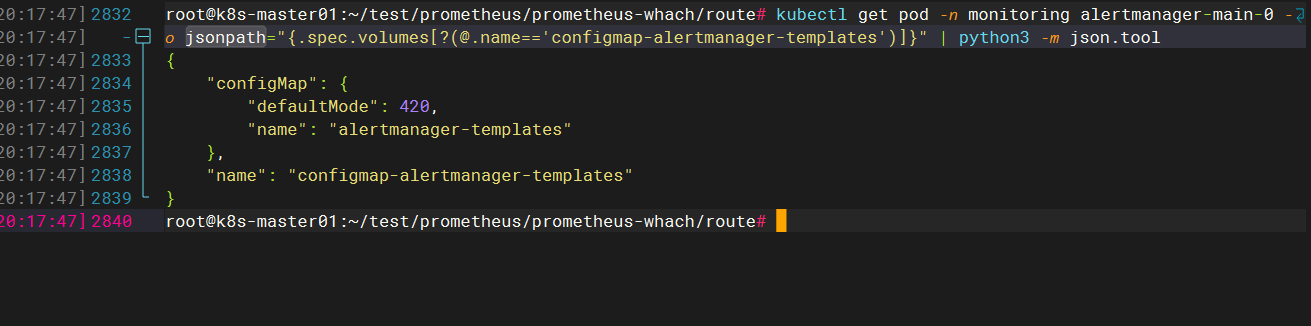
查看容器内的路径
# kubectl exec -it alertmanager-main-0 -n monitoring -- cat /etc/alertmanager/configmaps/alertmanager-templates/wechat.tmpl
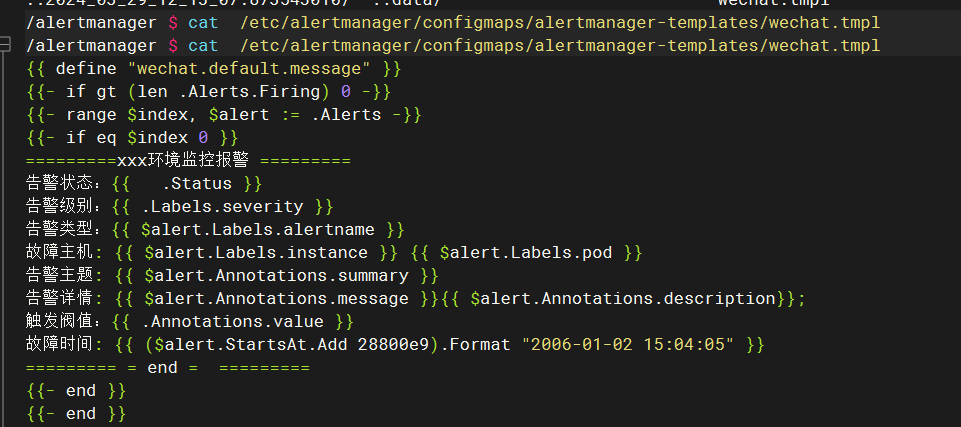
1.3查看企业微信报警
分级别告警
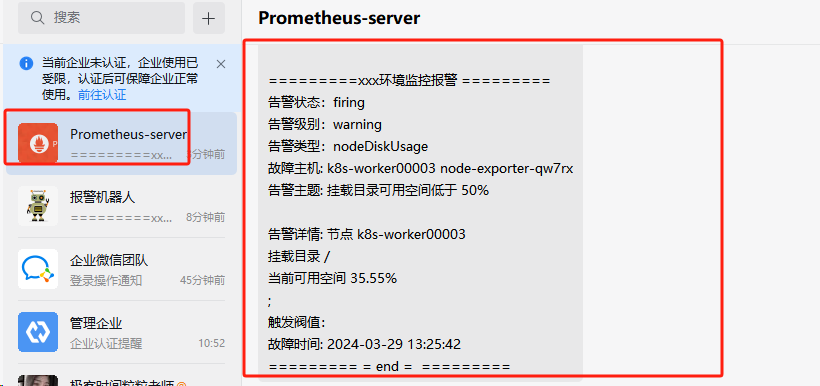
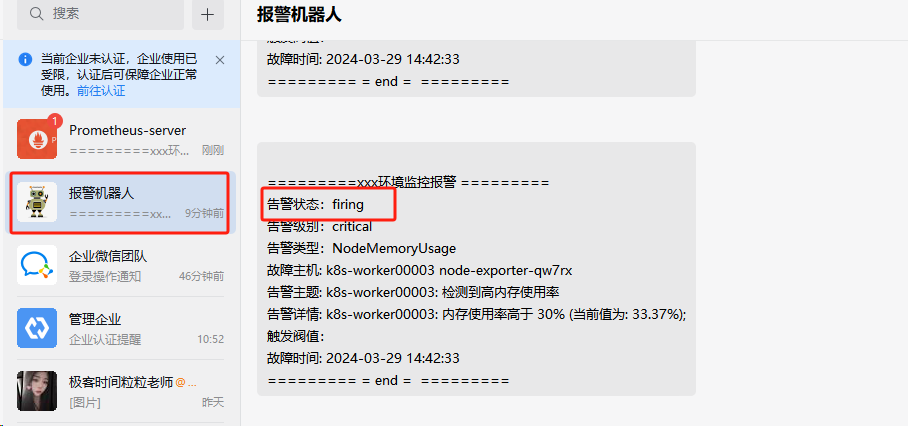
设置告警监控所有命名空间pod
1.1修改 alertmanager.yaml
增加命名空间跟pod
global:
resolve_timeout: 1m
templates:
- '/etc/alertmanager/configmaps/alertmanager-templates/*.tmpl'
route:
receiver: 'ops-err'
group_wait: 10s
group_interval: 30s
repeat_interval: 30s
group_by: [alertname, instance, pod, namespace]
routes:
- matchers:
- severity = warning
receiver: 'ops-err'
continue: true
- matchers:
- severity =~ error|critical
receiver: 'devops'
continue: true
receivers:
- name: 'devops'
wechat_configs:
- corp_id: ''
to_user: '@all'
agent_id: '1000002'
api_secret: ''
- name: 'ops-critical'
wechat_configs:
- corp_id: ''
to_user: '@all'
agent_id: '1000005'
api_secret: ''
- name: 'ops-err'
wechat_configs:
- corp_id: ''
to_user: '@all'
agent_id: '1000003'
api_secret: ''
详解
在你的配置中,`group_by: [alertname, instance, pod, namespace]` 的含义是:
- `alertname`: 告警的名称。这通常是在 Prometheus 告警规则中定义的告警类型,例如 `PodNotRunning`。
- `instance`: 发生告警的实例。在 Kubernetes 监控中,这通常是 Pod 的 IP 地址或者节点的 IP 地址。
- `pod`: 发生告警的 Pod 的名称。
- `namespace`: 发生告警的 Pod 所在的命名空间。
只有当这四个标签都相同时,告警才会被归为同一组。这意味着,即使是同一种告警(`alertname`)和同一节点(`instance`),只要是不同的 Pod 或者命名空间,也会被视为不同的告警组,会单独触发一个告警。
例如,如果有两个告警:
- 告警 A: `{alertname="PodNotRunning", instance="10.0.0.1", pod="pod-1", namespace="ns-1"}`
- 告警 B: `{alertname="PodNotRunning", instance="10.0.0.1", pod="pod-2", namespace="ns-1"}`
尽管它们的 `alertname` 和 `instance` 都相同,但是 `pod` 不同,所以它们会被视为两个不同的告警组,会分别触发两个告警。

1.2更新 secret
kubectl create secret generic alertmanager-main -n monitoring --from-file=alertmanager.yaml --dry-run -oyaml > alertmanager-main-secret.yaml kubectl apply -f alertmanager-main-secret.yaml
1.3配置告警规则
vim prometheus-pod-rules.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: node
namespace: default
labels:
group: frem-k8s # 添加全局分组标签
spec:
groups:
- name: pod-status
rules:
- alert: PodNotRunning
annotations:
summary: 'Pod状态异常'
description: 'Pod {{$labels.pod}} 在命名空间 {{$labels.namespace}} 中不在 Running 状态'
expr: |
kube_pod_status_phase{phase!="Running"} > 0
for: 1m
labels:
team: k8s-cluster
severity: error
创建规则 kubectl apply -f prometheus-pod-rules.yaml
1.4查看报警
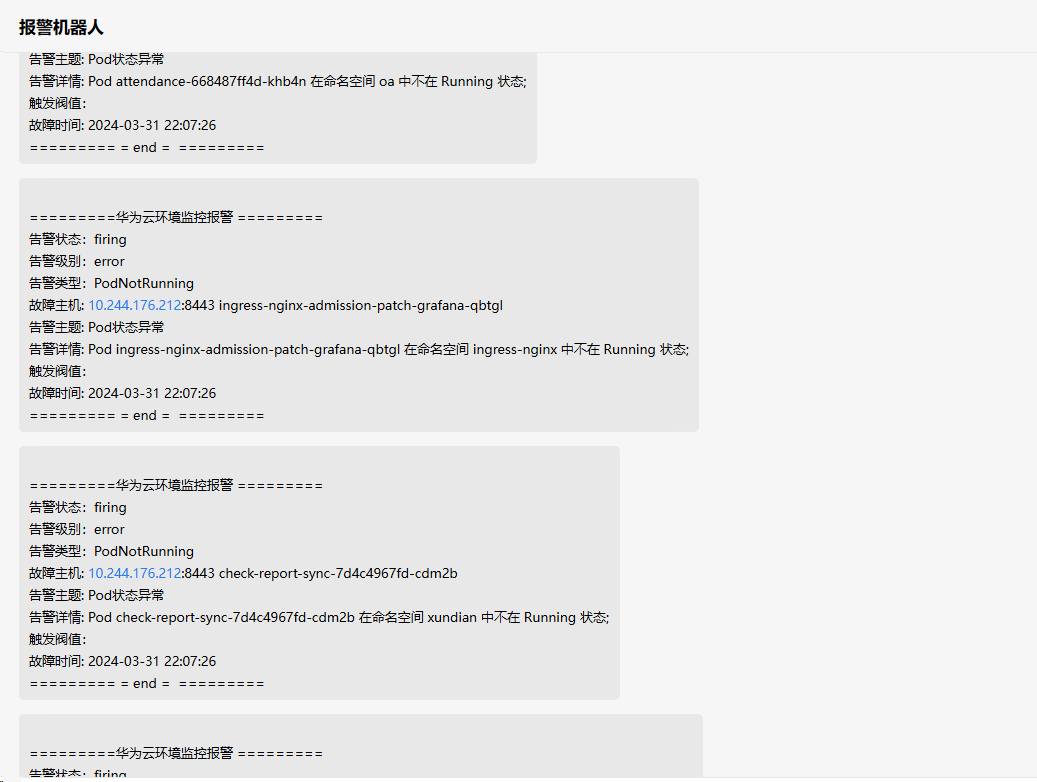
这样,每个不在 Running 状态的 Pod 都会触发一个单独的告警。
优化
如果有很多pod处于!="Running状态,会产生很多条告警
优化一:
例如,你可以将 group_by 参数设置为 [alertname, instance, namespace],这样,只要是同一种告警(alertname)、同一节点(instance)和同一命名空间(namespace),即使是不同的 Pod,也会被视为同一组告警。
route:
receiver: 'ops-err'
group_wait: 10s
group_interval: 30s
repeat_interval: 30s
group_by: [alertname, instance, namespace]
优化二
例如,你可以定义一个抑制规则,当同一命名空间中有多个 Pod 发生告警时,只发送一条告警通知:
route:
receiver: 'ops-err'
group_wait: 10s
group_interval: 30s
repeat_interval: 30s
group_by: [alertname, instance, pod, namespace]
routes:
- matchers:
- severity = warning
receiver: 'ops-err'
continue: true
- matchers:
- severity =~ error|critical
receiver: 'devops'
continue: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'namespace']
优化三
定义告警规则的抓取时间,或者检测pod的时间
route:
receiver: 'ops-err'
group_wait: 10s
group_interval: 30s
repeat_interval: 10m ## 时间改长
group_by: [alertname, instance, pod, namespace]
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: node
namespace: default
labels:
group: frem-k8s # 添加全局分组标签
spec:
groups:
- name: pod-status
rules:
- alert: PodNotRunning
annotations:
summary: 'Pod状态异常'
description: 'Pod {{$labels.pod}} 在命名空间 {{$labels.namespace}} 中不在 Running 状态'
expr: |
kube_pod_status_phase{phase!="Running"} > 0
for: 1m #时间改长
labels:
team: k8s-cluster
severity: error
2.1-AlertmanagerConfig方式
这个方式我没有做出来,如果有大佬 做出来可以私信我
详解一
在 Prometheus Operator 的 AlertmanagerConfig 资源中,目前还不支持直接定义企业微信告警。在 AlertmanagerConfig 中,接收器(receivers)只支持以下类型的配置:webhookConfigs,emailConfigs,pagerdutyConfigs,opsgenieConfigs,slackConfigs,victorOpsConfigs,wechatConfigs 并未在 AlertmanagerConfig 资源的接收器配置中被直接支持。
但是,您可以通过 webhook 的方式来实现。您需要自己搭建一个 webhook 服务,这个服务接收到 Alertmanager 的告警后,再将告警信息发送到企业微信。在 AlertmanagerConfig 中,您可以定义一个 webhookConfigs,其 url 指向您的 webhook 服务。
下面是一个简单的示例:
在这个配置中,http://your-webhook-service-address/ops-err 和 http://your-webhook-service-address/devops 应该是您自己的 webhook 服务地址,这个服务需要能够接收告警信息并将告警发送到企业微信。
对于如何搭建这样的 webhook 服务,您可以参考一些开源项目,如 prometheus-webhook-dingtalk(虽然这是一个针对钉钉的项目,但是其实现方式对于企业微信也是适用的)。
详解二:
由于企业微信更新问题,现在已经无法直接使用创建应用后在alertmanager的配置文件中定义企业id及secret就可以发送告警信息了,除非填写备案后域名;为了我们这种个人开发者非常的不便,所以本文档是为了解决想使用企业微信告警但又无法备案的朋友
方案选择:
第一种方案:PrometheusAlert + Prometheus + Alertmanager 实现各种类型告警
第二种方案:创建 Webhook 服务,用于转发 Alertmanager 的告警消息到企业微信机器人
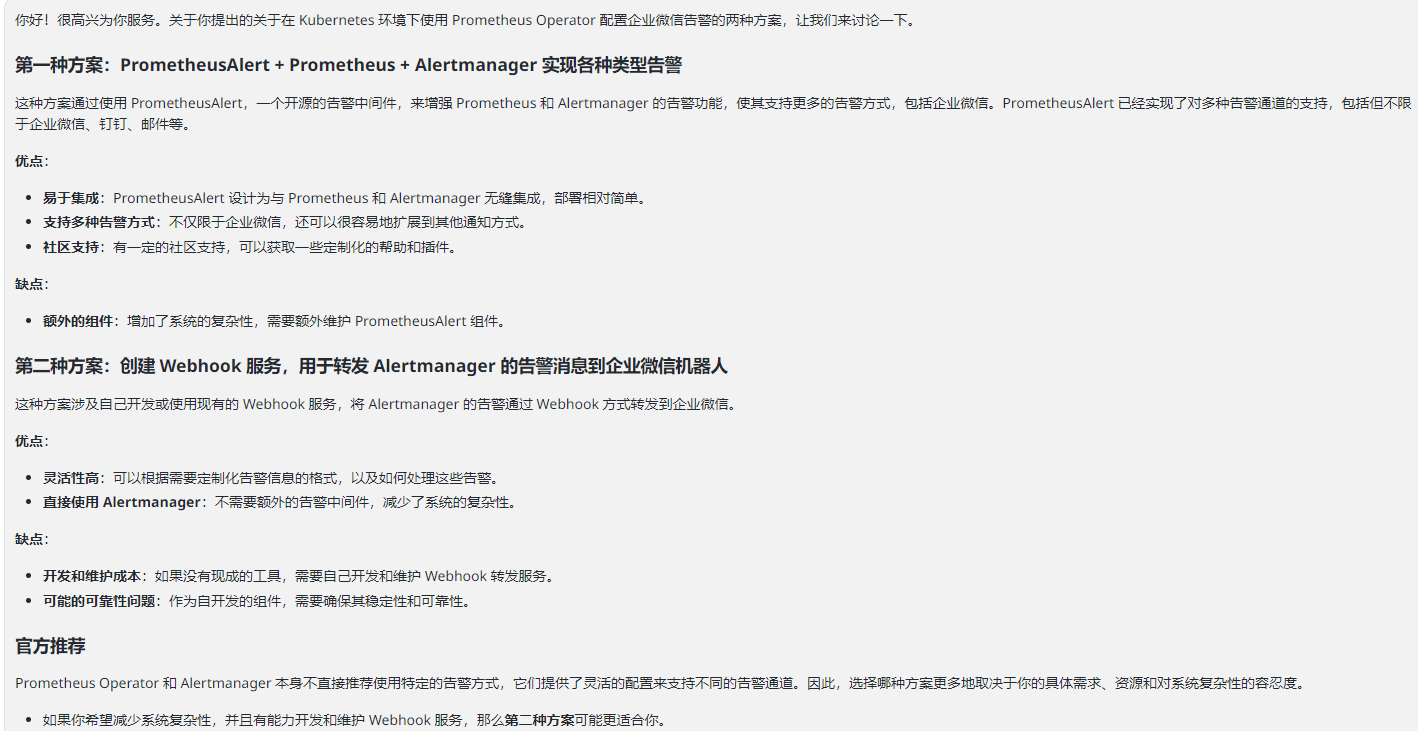
方案需求
我后面希望是通过子路由匹配告警级别,去分发到不同的告警接收器,上面那个方案更适合我
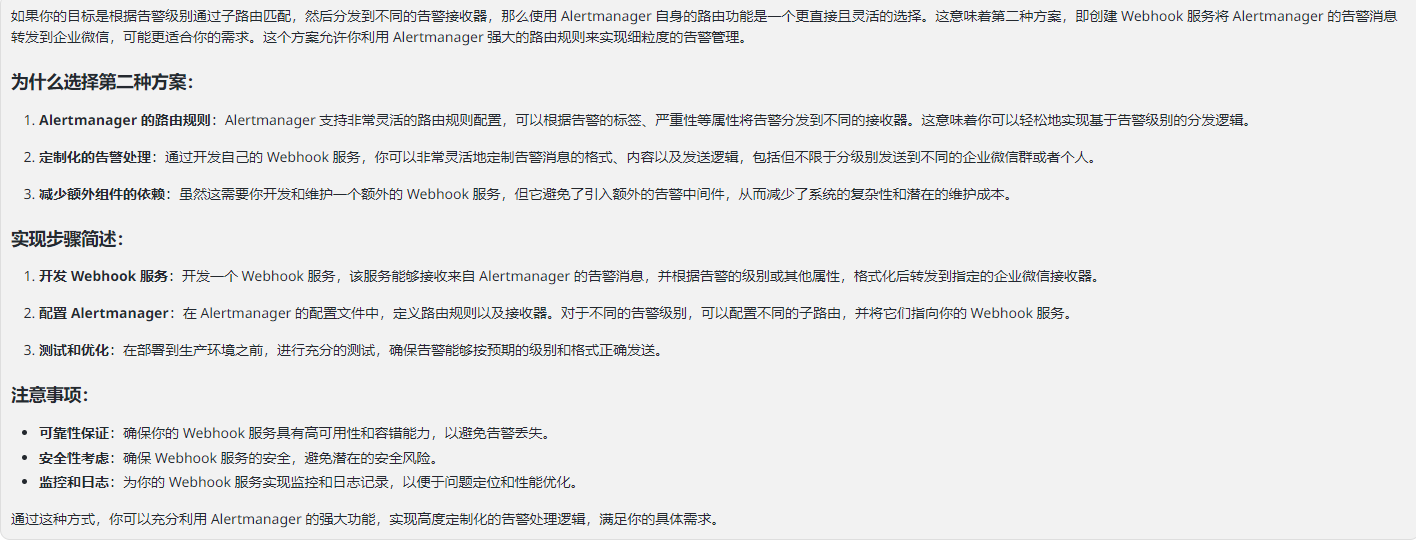
为什么第一种方案:PrometheusAlert + Prometheus + Alertmanager 实现各种类型告警这个不适合

第二种方案:创建 Webhook 服务
这里我都给你们推荐参考文档第一种,第二种你们可以进行测试
参考文档
第一种
[Prometheus接入AlterManager配置邮件告警(基于K8S环境部署)_prometheus配置邮箱告警-CSDN博客](https://blog.csdn.net/weixin_45310323/article/details/133965945)
[Alertmanager实现企业微信机器人webhook告警 - k-free - 博客园 (cnblogs.com)](https://www.cnblogs.com/k-free-bolg/p/17965930)
第二种
[kube-prometheus实现企业微信机器人告警_alertmanager企微告警-CSDN博客](https://blog.csdn.net/rendongxingzhe/article/details/127498349)
首先恢复你默认的配置
kube-prometheus-0.13.0/manifests# kubectl apply -f alertmanager-secret.yaml
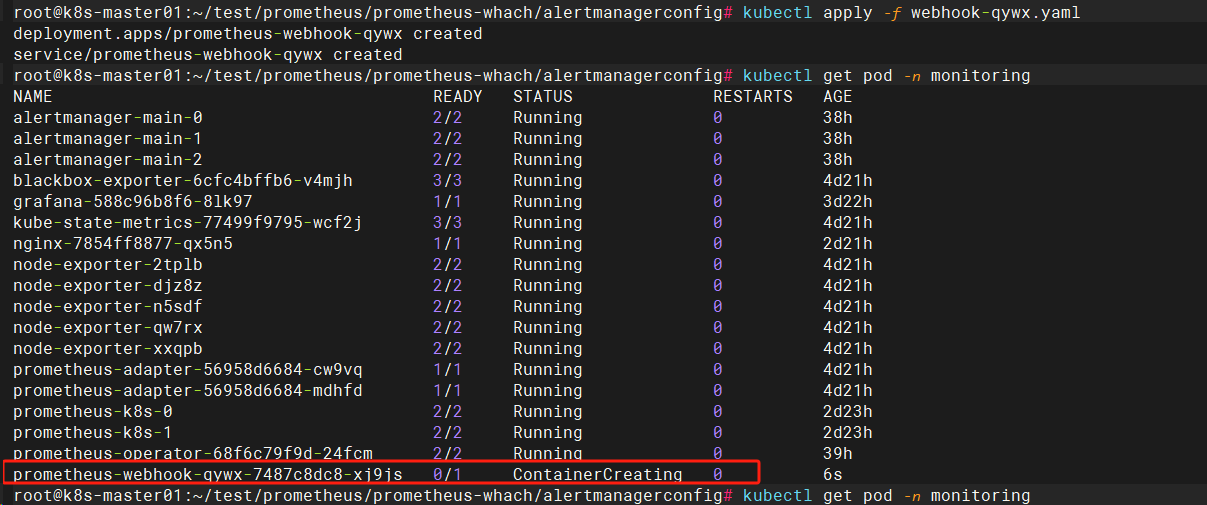
2.1创建webhook服务
用于转发alertmanager的告警消息到企业微信机器人
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: prometheus-webhook-qywx
name: prometheus-webhook-qywx
namespace: monitoring
spec:
selector:
matchLabels:
run: prometheus-webhook-qywx
template:
metadata:
labels:
run: prometheus-webhook-qywx
spec:
containers:
- args: # 企业微信的webhook-key如何获取可以google一下;很简单,这里不说明了;
- --adapter=/app/prometheusalert/wx.js=/adapter/wx= #注意变更这个地址,即企业微信机器人的webhook地址
image: registry.cn-hangzhou.aliyuncs.com/guyongquan/webhook-adapter
name: prometheus-webhook-dingtalk
ports:
- containerPort: 80
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
run: prometheus-webhook-qywx
name: prometheus-webhook-qywx
namespace: monitoring
spec:
ports:
- port: 8060
protocol: TCP
targetPort: 80
selector:
run: prometheus-webhook-qywx
type: ClusterIP
备注:
adapter=/app/prometheusalert/wx.js=/adapter/wx=https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=c3578c16-1a8e-ssssdddd8888888 #注意变更这个地址,即企业微信机器人的webhook地址