一、代码
方法简单介绍
RANSAC(随机采样一致性)是一种常用的分割算法,通常用于从点云中分割出最大的平面(如地面、墙壁等)。RANSAC速度相对较快,特别是当点云数据量不是很大时。在物体与背景之间存在明显的平面界限时效果较好,但如果背景复杂或物体表面也较平坦,则可能无法有效分割。
DBSCAN(基于密度的空间聚类的噪声应用)是一个无监督的聚类算法,能够根据密度将数据分割成多个子集群。DBSCAN的运行时间主要取决于点云的密度和大小。对于大型点云,DBSCAN可能会比较慢。对于分离具有不同密度分布的物体和背景,DBSCAN通常效果不错。参数选择对结果有很大影响。
Python
import open3d as o3d
import matplotlib.pyplot as plt
import numpy as np
def ransacDbscanPlaneSeg(pointcloud):
plane_model, inliers = pointcloud.segment_plane(distance_threshold=0.001,
ransac_n=3,
num_iterations=1000)
# 提取平面点云和非平面点云
plane_pcd = pointcloud.select_by_index(inliers)
objects_pcd = pointcloud.select_by_index(inliers, invert=True)
# 对非平面部分进行欧几里得聚类分割
with o3d.utility.VerbosityContextManager(o3d.utility.VerbosityLevel.Debug) as cm:
labels = np.array(objects_pcd.cluster_dbscan(eps=0.05, min_points=10, print_progress=True))
# 根据标签为每个聚类赋予不同颜色
max_label = labels.max()
label, counts = np.unique(labels, return_counts=True)
# 忽略噪声点,其标签为-1
counts = counts[label != -1]
label = label[label != -1]
# 找到点数最多的聚类的标签
max_points_cluster_label = label[counts.argmax()]
colors = plt.get_cmap("tab20")(labels / (max_label if max_label > 0 else 1))
colors[labels < 0] = 0 # 为噪声点赋予黑色
objects_pcd.colors = o3d.utility.Vector3dVector(colors[:, :3])
most_points_cluster_indices = np.where(labels == max_points_cluster_label)[0]
most_points_cluster_pcd = objects_pcd.select_by_index(most_points_cluster_indices)
return plane_pcd, most_points_cluster_pcd
def dbscanPlaneSeg(pointcloud):
# 进行DBSCAN聚类分割
# eps参数定义了领域的半径,min_points定义了形成一个聚类所需的最小点数
labels = np.array(pointcloud.cluster_dbscan(eps=0.001, min_points=20, print_progress=True))
# 获取最大的标签值(最大的聚类索引)
max_label = labels.max()
# print("point cloud has %s clusters" % (max_label + 1))
# 为了找到点数最多的聚类,我们将统计每个聚类标签出现的次数
label, counts = np.unique(labels, return_counts=True)
# 忽略噪声点,其标签为-1
counts = counts[label != -1]
label = label[label != -1]
# 找到点数最多的聚类的标签
max_points_cluster_label = label[counts.argmax()]
# 将聚类结果转换成不同颜色
colors = plt.get_cmap("tab20")(labels / (max_label if max_label > 0 else 1))
colors[labels < 0] = 0 # 将未分类的点(噪声)设置成黑色
pointcloud.colors = o3d.utility.Vector3dVector(colors[:, :3])
# 可视化聚类分割的点云
# o3d.visualization.draw_geometries([pointcloud])
# 可选:根据标签提取特定聚类
# cluster_indices = np.where(labels == 0)[0] # 提取标签为0的聚类
# cluster_pcd = pcd.select_by_index(cluster_indices)
# o3d.visualization.draw_geometries([cluster_pcd])
# 提取点数最多的聚类
most_points_cluster_indices = np.where(labels == max_points_cluster_label)[0]
most_points_cluster_pcd = pointcloud.select_by_index(most_points_cluster_indices)
return pointcloud, most_points_cluster_pcd
def ransacPlaneSeg(pointcloud):
# RANSAC平面分割
plane_model, inliers = pointcloud.segment_plane(distance_threshold=0.001,
ransac_n=4,
num_iterations=1000)
# 提取平面内的点云
inlier_cloud = pointcloud.select_by_index(inliers)
# 提取平面外的点云
outlier_cloud = pointcloud.select_by_index(inliers, invert=True)
return inlier_cloud, outlier_cloud
if __name__ == "__main__":
# 加载点云
pcd = o3d.io.read_point_cloud("res/1.ply")
o3d.visualization.draw_geometries([pcd])
# _, result = ransacPlaneSeg(pcd)
_, result = dbscanPlaneSeg(pcd)
o3d.visualization.draw_geometries([result])
关键代码解析:
def ransacDbscanPlaneSeg(pointcloud):
plane_model, inliers = pointcloud.segment_plane(distance_threshold=0.001,
ransac_n=3,
num_iterations=1000)
# 提取平面点云和非平面点云
plane_pcd = pointcloud.select_by_index(inliers)
objects_pcd = pointcloud.select_by_index(inliers, invert=True)
# 对非平面部分进行欧几里得聚类分割
with o3d.utility.VerbosityContextManager(o3d.utility.VerbosityLevel.Debug) as cm:
labels = np.array(objects_pcd.cluster_dbscan(eps=0.05, min_points=10, print_progress=True))
# 根据标签为每个聚类赋予不同颜色
max_label = labels.max()
label, counts = np.unique(labels, return_counts=True)
# 忽略噪声点,其标签为-1
counts = counts[label != -1]
label = label[label != -1]
# 找到点数最多的聚类的标签
max_points_cluster_label = label[counts.argmax()]
colors = plt.get_cmap("tab20")(labels / (max_label if max_label > 0 else 1))
colors[labels < 0] = 0 # 为噪声点赋予黑色
objects_pcd.colors = o3d.utility.Vector3dVector(colors[:, :3])
most_points_cluster_indices = np.where(labels == max_points_cluster_label)[0]
most_points_cluster_pcd = objects_pcd.select_by_index(most_points_cluster_indices)
return plane_pcd, most_points_cluster_pcd
def dbscanPlaneSeg(pointcloud):
# 进行DBSCAN聚类分割
# eps参数定义了领域的半径,min_points定义了形成一个聚类所需的最小点数
labels = np.array(pointcloud.cluster_dbscan(eps=0.001, min_points=20, print_progress=True))
# 获取最大的标签值(最大的聚类索引)
max_label = labels.max()
# print("point cloud has %s clusters" % (max_label + 1))
# 为了找到点数最多的聚类,我们将统计每个聚类标签出现的次数
label, counts = np.unique(labels, return_counts=True)
# 忽略噪声点,其标签为-1
counts = counts[label != -1]
label = label[label != -1]
# 找到点数最多的聚类的标签
max_points_cluster_label = label[counts.argmax()]
# 将聚类结果转换成不同颜色
colors = plt.get_cmap("tab20")(labels / (max_label if max_label > 0 else 1))
colors[labels < 0] = 0 # 将未分类的点(噪声)设置成黑色
pointcloud.colors = o3d.utility.Vector3dVector(colors[:, :3])
# 可视化聚类分割的点云
# o3d.visualization.draw_geometries([pointcloud])
# 可选:根据标签提取特定聚类
# cluster_indices = np.where(labels == 0)[0] # 提取标签为0的聚类
# cluster_pcd = pcd.select_by_index(cluster_indices)
# o3d.visualization.draw_geometries([cluster_pcd])
# 提取点数最多的聚类
most_points_cluster_indices = np.where(labels == max_points_cluster_label)[0]
most_points_cluster_pcd = pointcloud.select_by_index(most_points_cluster_indices)
return pointcloud, most_points_cluster_pcd
def ransacPlaneSeg(pointcloud):
# RANSAC平面分割
plane_model, inliers = pointcloud.segment_plane(distance_threshold=0.001,
ransac_n=4,
num_iterations=1000)
# 提取平面内的点云
inlier_cloud = pointcloud.select_by_index(inliers)
# 提取平面外的点云
outlier_cloud = pointcloud.select_by_index(inliers, invert=True)
return inlier_cloud, outlier_cloud这段代码包含了三个函数,它们分别使用基于欧几里得距离的DBSCAN算法与RANSAC平面分割算法来处理三维点云数据。
-
ransacDbscanPlaneSeg(pointcloud):-
这个函数首先利用RANSAC算法分割出点云中的一个平面。
-
然后将点云分成属于平面的点与不属于平面的点。
-
对不属于平面的点云进行DBSCAN聚类。
-
找到包含点数最多的那个聚类,并将其返回。
-
-
dbscanPlaneSeg(pointcloud):-
仅使用DBSCAN算法对整个点云进行聚类。
-
找到并返回包含点数最多的那个聚类。
-
-
ransacPlaneSeg(pointcloud):-
仅使用RANSAC算法分割出点云中的平面,并返回属于平面的点和不属于平面的点。
-
每个函数中都有一些参数可以调整,这些参数会对算法的结果产生影响:
-
distance_threshold: RANSAC算法中,一个点被认为是平面上的点的最大距离。这个值越小,认定为平面上点的条件越严格。 -
ransac_n: RANSAC算法中,用于估计平面模型的点的最小数量。这个数值通常设置为3,因为理论上3个非共线的点可以确定一个平面。 -
num_iterations: RANSAC算法的迭代次数,迭代次数越多,找到最佳模型的概率越大,但计算时间也会增加。 -
eps: DBSCAN算法中领域的半径,也就是用来确定其他点是否与某一点处在同一邻域的距离阈值。这个值越小,形成簇的条件越严格,可能会得到更多的、更小的簇。 -
min_points: DBSCAN算法中,定义了一个点要成为核心点所需的邻域内邻近点的最小数量。这个数值越大,算法识别出的核心点越少,簇的数量也越少。
在实际应用中,需要根据点云的密度以及您想要识别的对象的大小和分布特征来调整这些参数。例如,点云数据中的物体距离彼此非常近,您可能需要减小eps以避免将多个物体错误地合并到同一个簇中。
最后,这些函数通常会返回两个点云:一个包含平面点的点云,另一个是聚类后点数最多的那个物体的点云。如果您需要可视化这些点云以检查分割和聚类的效果,可以使用o3d.visualization.draw_geometries函数进行可视化。
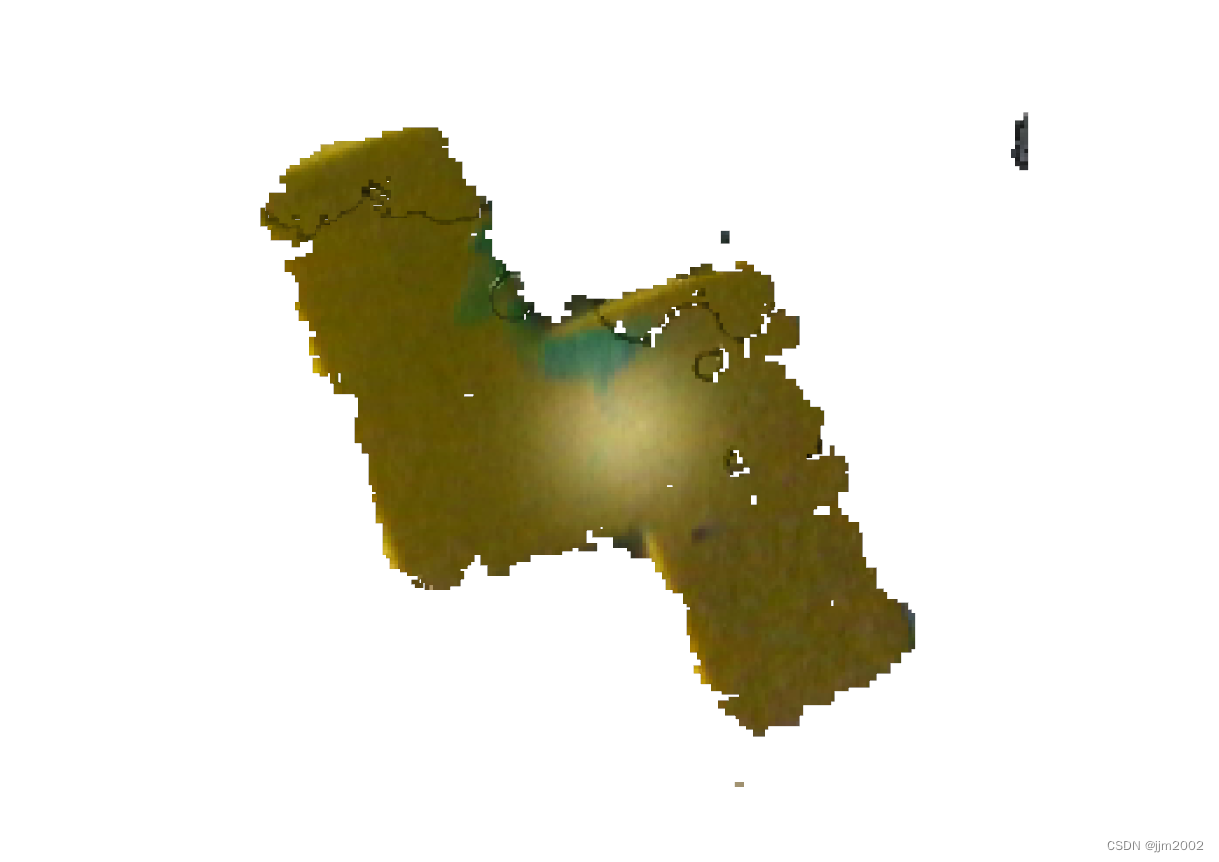
结果:
处理前
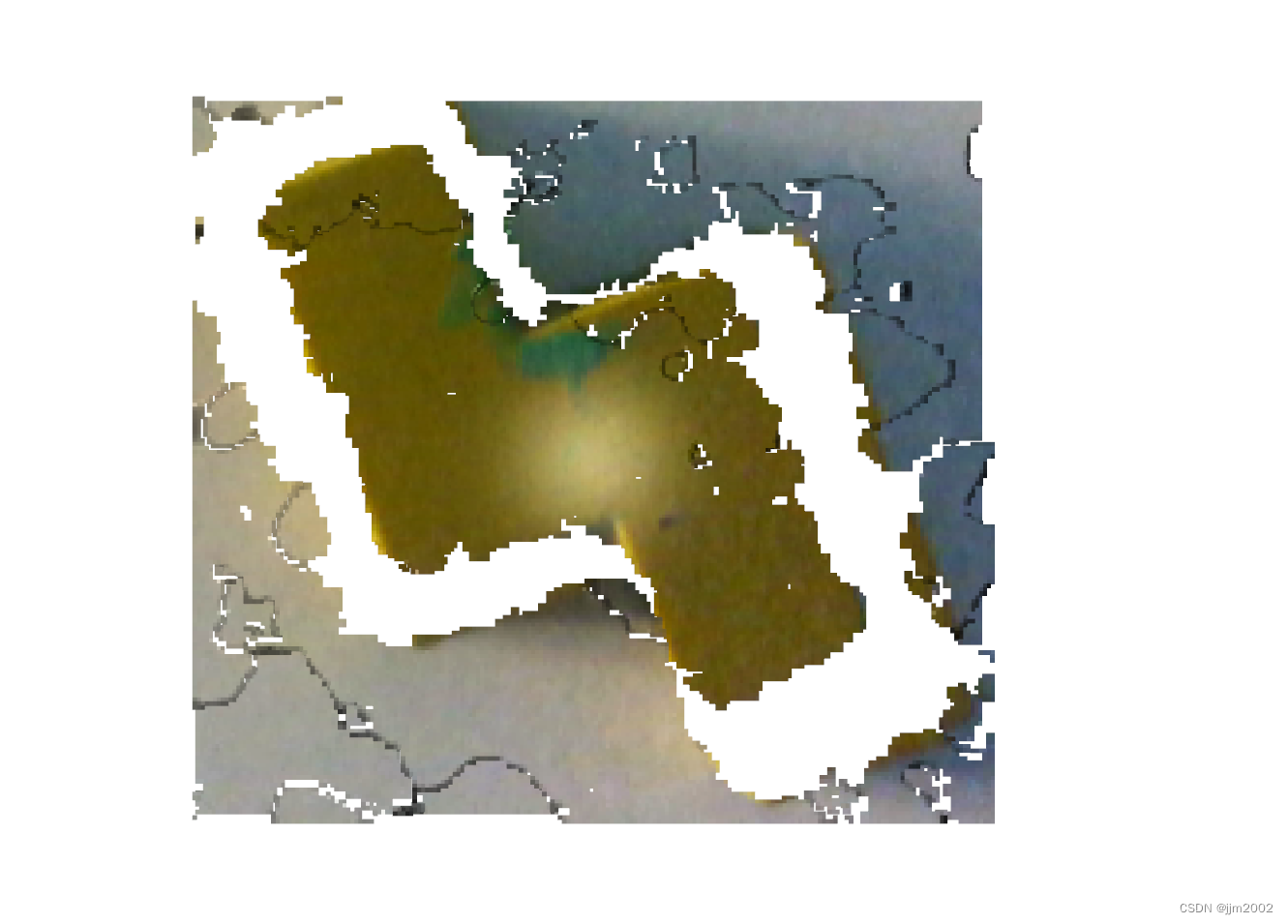
处理后