🎉欢迎大家观看AUGENSTERN_dc的文章(o゜▽゜)o☆✨✨
🎉感谢各位读者在百忙之中抽出时间来垂阅我的文章,我会尽我所能向的大家分享我的知识和经验📖
🎉希望我们在一篇篇的文章中能够共同进步!!!
🌈个人主页:AUGENSTERN_dc
🔥个人专栏:C语言 | Java | 数据结构 | 算法 | MySQL
⭐个人格言:
一重山有一重山的错落,我有我的平仄
一笔锋有一笔锋的着墨,我有我的舍得

目录
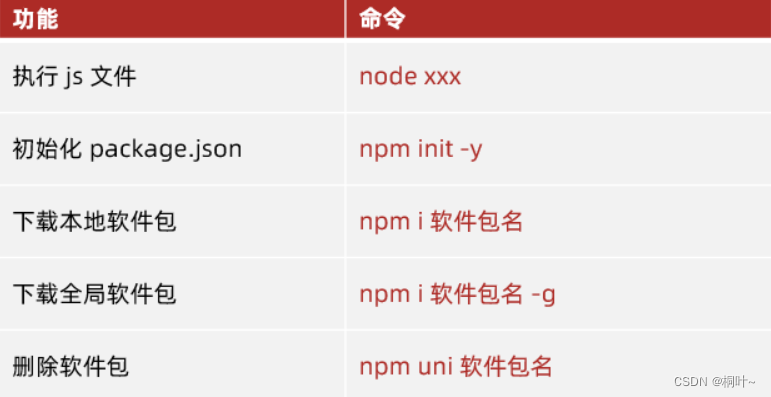
1. MySQL是如何组织数据的:
2. 显示当前的所有数据库:
2.1 语法:
2.2 示例:
2.3 说明:
3. 创建数据库:
3.1 语法:
3.2 说明:
3.3 示例:
4. 使用数据库:
4.1 语法:
4.2 示例:
5. 删除数据库:
5.1 语法:
5.2 示例:
5.3 说明:
6. 常用数据类型:
6.1 数值类型:
6.2 字符串类型:
6.3 日期类型:
7. 查看表结构:
7.1 语法:
7.2 示例:
7.3 说明:
8 创建表:
8.1 语法:
8.2 示例:
9. 查看所有表:
9.1 语法:
9.2 示例:
10. 删除表:
10.1 语法:
10.2 示例:
11. 行的新增(create):
11.1 语法:
11.2 单行数据 + 全列插入:
11.3 多行数据 + 全列插入;
11.4 多行数据 + 指定列插入:
12 行查询(Retrieve):
12.1 语法:
12.2 全列查询:
12.3 指定列查询:
12.4 查询字段为表达式:
12.5 别名:
12.6 去重查找(DISTINCT):
12.7 排序(ORDER BY):
12.8 对使用表达式和别名进行排序:
12.9 对多个字段进行排序:
12.10 条件查询(where) :
12.10.1 比较运算符:
12.10.2 基本查询:
12.10.3 IN查询:
12.10.4 LIKE模糊查询:
12.11 NULL 查询:
12.12 分页查询(LIMIT):
13 修改(UPDATE):
13.1 语法:
14 删除行(DELETE)
14.1 语法:
14.2 示例:
1. MySQL是如何组织数据的:
在MySQL中, 我们的数据库通常是存放在数据库服务器中的, 而数据库中又有数据表,数据表中悠悠数据行,最后数据行中有数据列, 整理后我们可以得到如下结构:

2. 显示当前的所有数据库:
2.1 语法:
SHOW DATABASES;
2.2 示例:
我们在MySQL中输入show databases; 就会显示目前我们MySQL中存在几个数据库:
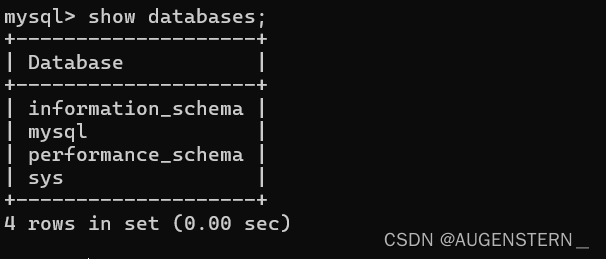
2.3 说明:
在MySQL中,sql语法是对大小写不敏感的,故使用大写和小写对代码的影响不大
上图中的四个数据库是系统库,并未包含我个人所创建的库,以上的四个系统库在使用的时候,一定要注意,避免删除了其中的数据,使得MySQL无法正常使用;
面对上述误操作,我们也无需担心,只需讲MySQL删除后重新下载即可;
3. 创建数据库:
3.1 语法:
CREATE DATABASE [IF NOT EXISTS] 表名 [create_specification [, create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name
3.2 说明:
< 1 > 大写的表示关键字
< 2 > [ ] 中的内容是可省略的
< 3 > CHARACTER SET: 指定数据库采用的字符集
< 4 > COLLATE: 指定数据库字符集的校验规则
3.3 示例:
< 1 > 创建一个名为 test1 的数据库:
CREATE DATABASE test1;

此处显示创建成功,我们用show databases来验证一下是否创建成功;

很明显,在database中,有了 test1 这一个数据库;
当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则 是:utf8_ general_ ci
MySQL的utf8编码不是真正的utf8,没有包含某些复杂的中文字符。MySQL真正的utf8是 使用utf8mb4,建议大家都使用utf8mb4
< 2 > 如果系统没有 test2 的数据库,则创建一个名叫 test2 的数据库,如果有则不创建;
CREATE DATABASE IF NOT EXISTS test2;

系统同样提示创建成功,我们用show databases来检验一下是否正确;

< 3 > 如果系统没有 test 的数据库,则创建一个使用utf8mb4字符集的 test 数据库,如果有则不创建
CREATE DATABASE IF NOT EXISTS test CHARACTER SET utf8mb4;
在这里 character set 也可以简写成 charset

用charset 和character set 的效果是一样的, 但是第二条语句由于已经存在了test这一个数据库,所以创建失败;

4. 使用数据库:
我们想要对某一个数据库进行操作,我们就需要选中该数据库,或者说是使用该数据库
4.1 语法:
USE 数据库名;
4.2 示例:

5. 删除数据库:
5.1 语法:
DROP DATABASE [IF EXISTS] 表名;
5.2 示例:

在数据库中,只要一段语句没有分号,就可以换行输入
在该示例中,由于没有test3 这个数据库,故无法进行删除操作,显示1warning;
5.3 说明:
数据库删除以后,内部看不到对应的数据库,里边的表和数据全部被删除
6. 常用数据类型:
不同的语言之间,有这不同的体系,就像 Java 比 C语言多了一个byte类型一样, sql 这个语言和C语言,Java也截然不同;
6.1 数值类型:
数值类型分为整形和浮点型
| 数据类型 | 大小 | 说明 | 对应的Java类型 |
| BIT[ (M) ] | M指定位 数,默认为1 | 二进制数,M范围从1到64, 存储数值范围从0到2^M-1 | 常用Boolean对应BIT,此时默认是1位,即只能存0和1 |
| TINYINT | 1字节 | Byte | |
| SMALLINT | 2字节 | Short | |
| INT | 4字节 | Integer | |
| BIGINT | 8字节 | Long | |
| FLOAT(M, D) | 4字节 | 单精度,M指定长度,D指定 小数位数。会发生精度丢失 | Float |
| DOUBLE(M, D) | 8字节 | Double | |
| DECIMAL(M, D) | 1字节 | 双精度,M指定长度,D表示 小数点位数。精确数值 | BigDecimal |
| NUMERIC(M, D) | 1字节 | 和DECIMAL一样 | BigDecimal |
扩展:
在sql中,类型是写在变量名的后面的
数值类型可以指定为无符号(unsigned),表示不取负数。
1字节(bytes)= 8bit。
对于整型类型的范围:
1. 有符号范围:-2^(类型字节数*8-1)到2^(类型字节数*8-1)-1,如int是4字节,就 是-2^31到2^31-1
2. 无符号范围:0到2^(类型字节数*8)-1,如int就是2^32-1
尽量不使用unsigned,对于int类型可能存放不下的数据,int unsigned同样可能存放不下,与其 如此,还不如设计时,将int类型提升为bigint类型。
6.2 字符串类型:
| 数据类型 | 大小 | 说明 | 对应Java类型 |
| VARCHAR (SIZE) | 0-65,535字节 | 可变长度字符串 | String |
| TEXT | 0-65,535字节 | 长文本数据 | String |
| MEDIUMTEXT | 0-16 777 215字节 | 中等长度文本数据 | String |
| BLOB | 0-65,535字节 | 二进制形式的长文本数据 | byte[] |
6.3 日期类型:
| 数据类型 | 大小 | 说明 | 对应Java类型 |
| DATETIME | 8字节 | 范围从1000到9999年,不会进行时区的检索及转换。 | java.util.Date、 java.sql.Timestamp |
| TIMESTAMP | 4字节 | 范围从1970到2038年,自动检索当前时区并进行转换。 | java.util.Date、 java.sql.Timestamp |
7. 查看表结构:
7.1 语法:
DESC 表名;
desc 是describe 的缩写;
7.2 示例:
为了更好的展示, 我们在test数据库中 创建一个student表, 这个语法在之后会有所介绍;
在创建表的时候,我们需先使用test数据库

我们用desc来查看表的结构:

这个就是我们表的结构;
7.3 说明:
Field 表示的是该字段的名字;
Type 表示的是该字段的类型;
Null 表示的是是否允许为空;
Default 表示的是该表中默认的值;
Extra 表示的是扩充;
8 创建表:
8.1 语法:
CREATE TABLE 表名 ( field1 datatype, field2 datatype, field3 datatype );
我们可以用comment增加字段的说明.
8.2 示例:
以刚才创建的student表为例;

我们创建了一个表, 名为student, 在表中一共有五列 分别为 int类型的id, varchar(20)类型的name,
decimal(3,1) 类型的chinese,decimal(3,1) 类型的math,decimal(3,1) 类型的english;
这里的varchar(20) 中的20指的是,只能存放20 个字符,而不是字节;
若我们在创建表的时候,不给表任何字段,则会报错:

提示我们必须至少给表提供一个字段;
9. 查看所有表:
9.1 语法:
SHOW TABLES;
9.2 示例:

10. 删除表:
10.1 语法:
DROP [TEMPORARY] TABLE [IF EXISTS] 表名 [, 表名] ...
10.2 示例:
我们将student表进行删除操作;

再查看所有的表;

显示test数据库中没有表存在了;
11. 行的新增(create):
11.1 语法:
INSERT [INTO] 表名 [(column [, column] ...)] VALUES (value_list) [, (value_list)] ... value_list: value, [, value] ...
我们再次在test数据库中创建一个student表;

11.2 单行数据 + 全列插入:
我们在这个表中新增一行:

当然,我们不一定非要按照id, name, chinese, math, english这个创建表的顺序来输入,我们可以自己进行更换;

11.3 多行数据 + 全列插入;
我们在增加行的时候,我们可以一次性添加多行,这样的效率比多次添加效率会更高;


这两种输入方式都是可以的,但是第二种换行输入不能去修改上一行的代码,不建议这样操作;
11.4 多行数据 + 指定列插入:
在进行插入的时候,我们不仅可以选择多行插入,我们还可以选择只插入某几列;

这一次我们就没有对id这一列进行新增操作,那么id的值就会被赋值成默认值;
在上述的代码中,我们发现into是可以省略的, 同时name在输入的时候,可以用 ' , 也可以用 "
12 行查询(Retrieve):
12.1 语法:
SELECT [DISTINCT] {* | {column [, column] ...} FROM 表名 [WHERE ...] [ORDER BY column [ASC | DESC], ...] LIMIT ...
12.2 全列查询:
对表中的所有的列进行查询操作
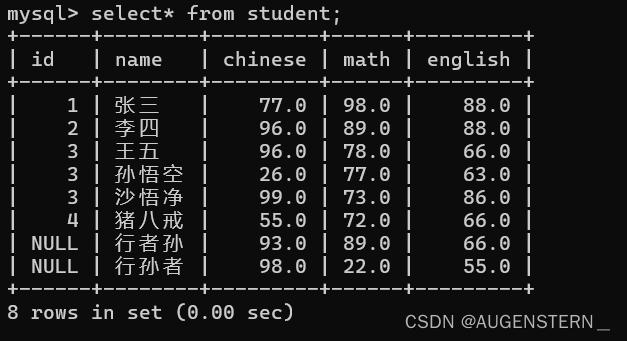
这里的 * 是sql中的通配符, 也就是所有的意思, 和Java中的 * 很相似;
12.3 指定列查询:
指定列的查询也不需要按照表的定义的顺序去写;
只需要在from和select之间输入想查询的列即可;

12.4 查询字段为表达式:

在我们查询的时候,我们可以将字段写成表达式, 如上图所示;
通过上图我们发现,对NULL进行表达式操作, 他的结果还是NULL;
但我们再次查询表的内容的时候
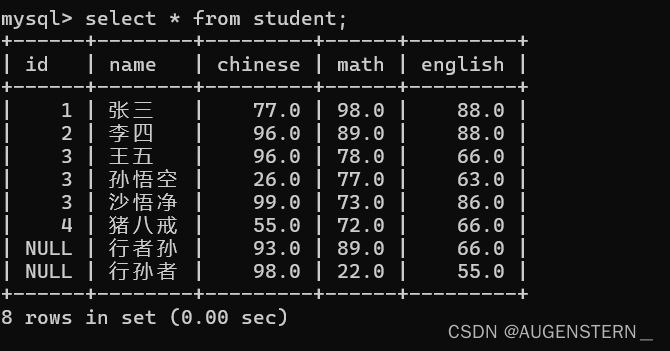
我们发现,其chinese列和id列的值并没有被修改,说明,在查询的时候,字段表达式不影响数据库中的数据的值;
12.5 别名:
在查询的时候,假如我们想要查询chinese + math + english我们可以这样写:
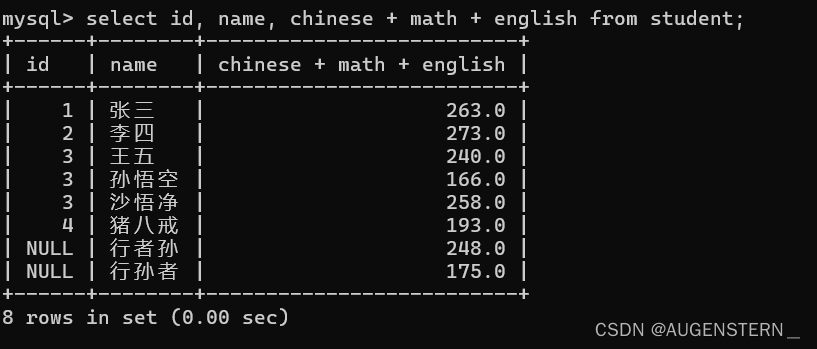
但是 chinese + math + english 这一行太长了, 我们想给他换个名字, 这时候我们可以使用我们的别名:
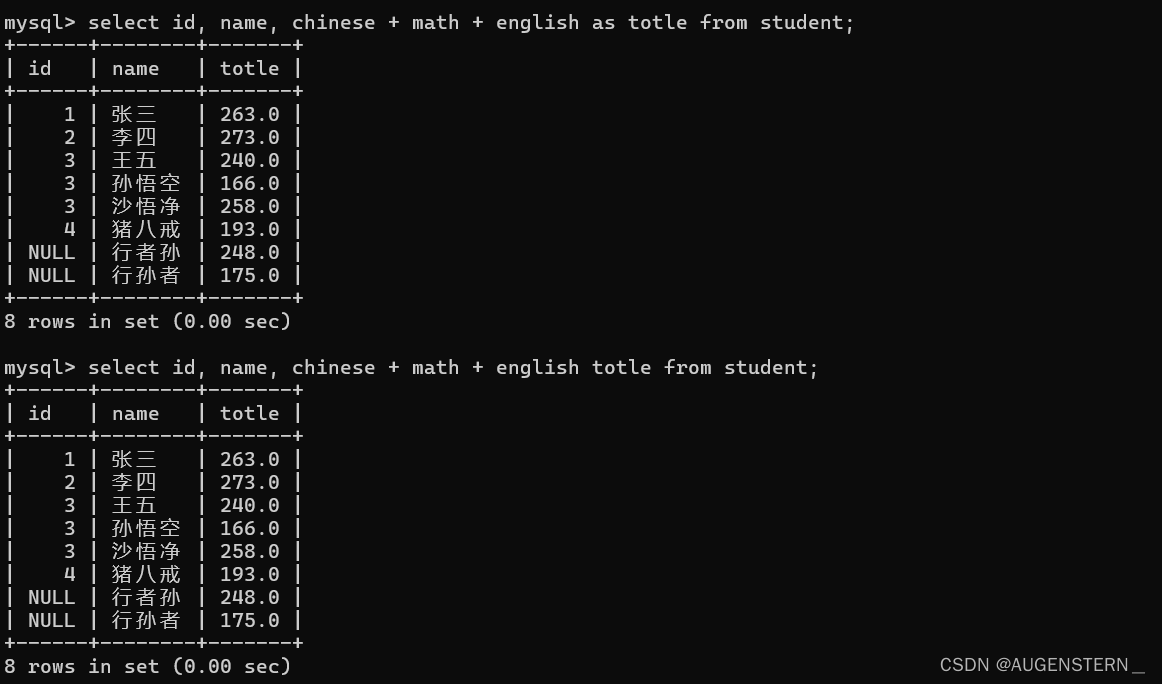
在这两行代码中,我们发现,只要在chinese + math + english后 + as + 新的名字,就可以在显示的时候,显示新的名字,这里的as我们是可以省略的;
12.6 去重查找(DISTINCT):
在某些时候,我们查找的过程中,不希望出现重复的数据,我们可以使用去重查找:

这是原本的表的数据;
对id进行去重操作:

但如果我们对id 和 name 都进行去重的话:
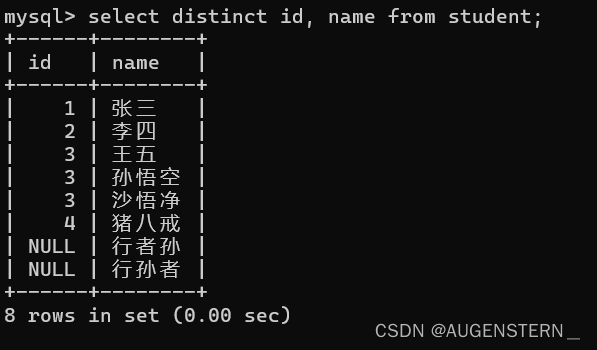
我们会发现,并没有那一行缺少了, 因为我们同时对id 和 name 进行了去重的操作, 只有当id 和 name都相同的时候,才会被去重;
同时,我们的去重不能这么写

我们只需在第一个字段的最前面 + distinct 即可, 会对后面所有的字段进行去重;
12.7 排序(ORDER BY):
我们可以对math这一列进行排序

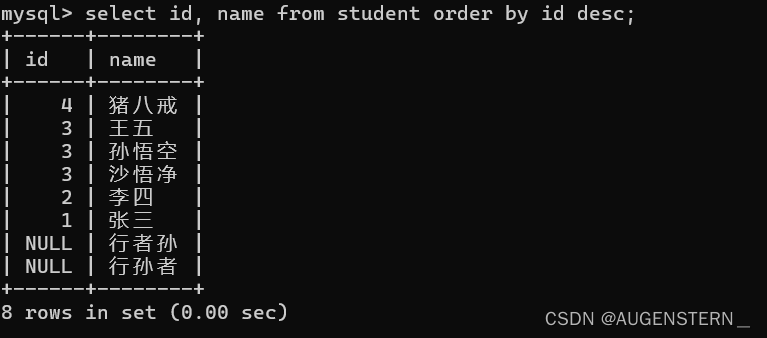
同时,我们也可以进行降序排序

只需order by + 字段 + desc即可, 此处的desc 和上面的查询表结构的desc不同
查询表结构的desc 是 describe的缩写
降序排序的desc 是 descend 的缩写
由于order by 的默认排序是升序, 所以我们没必要order by + 字段 + asc,这个asc是可以省略的;
若我们对有NULL的列进行排序, 则默认NULL的值最小;
12.8 对使用表达式和别名进行排序:

如果我们这么去写的话,查询的结果会是正确的结果,同理,我们将排序的字段写成别名的话也正确;

12.9 对多个字段进行排序:
在我们查询表的时候,我们可能会根据多列的结果来进行排序, 比如:

我们会发现, 首先我们比较的是英语的成绩, 若英语成绩相同,则比较数学成绩的大小;
这就是对多个字段进行排序;
12.10 条件查询(where) :
12.10.1 比较运算符:
| 运算符 | 说明 |
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, ...) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字 符 |
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0),反之 |
注:
1. WHERE条件可以使用表达式,但不能使用别名。
2. AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分
12.10.2 基本查询:
查询英语成绩> 80分的同学;

这里需要注意, 我们的where应该要写在 order by 的前面;
查询总分 > 200 的同学:

这里如果我们将where后面的 english + math + chinese 写成别名的话:

系统会进行报错,因为sql中的语句也是有优先级的where语句的优先级 > 别名的优先级,所以where语句无法识别别名;
查询英语成绩 > 语文成绩 并且 数学成绩及格的同学:

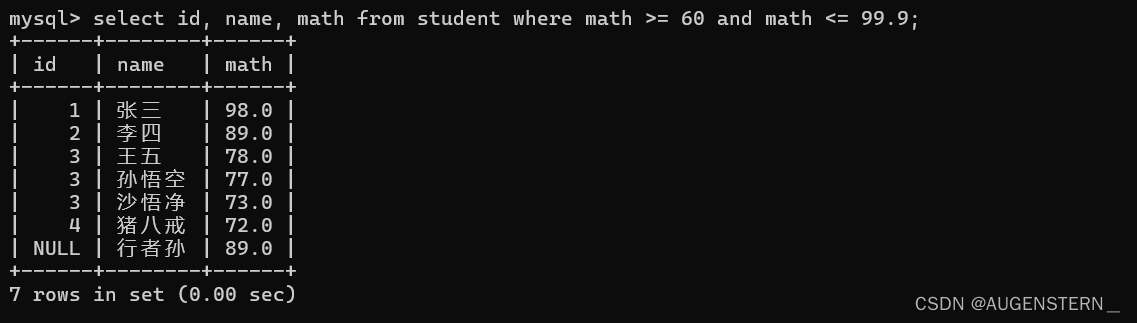
查询数学成绩在60 - 99.9 之间的同学;

这里也可以用and 来代替:
12.10.3 IN查询:
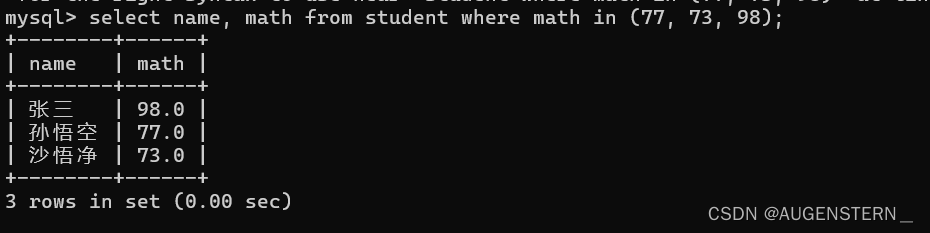
查询数学成绩为77, 73, 98的同学:
此处同样可以用OR来代替:

12.10.4 LIKE模糊查询:
这里先简单介绍两个操作符:
% 匹配任意多个(包括 0 个)字符
_ 匹配严格的一个任意字符
首先我们先对student表新增几行,方便后续展示:

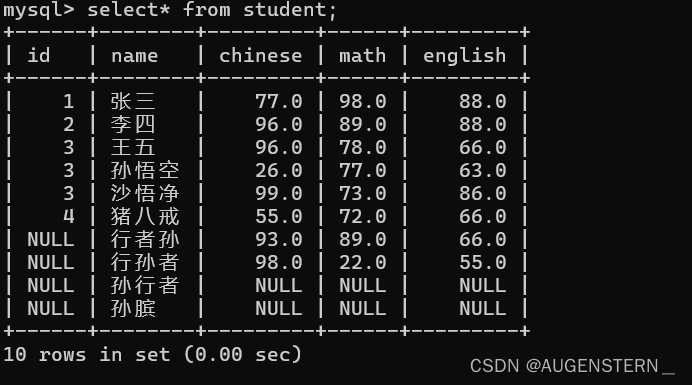
这是表此时的内容:
我们对表进行模糊查找操作:
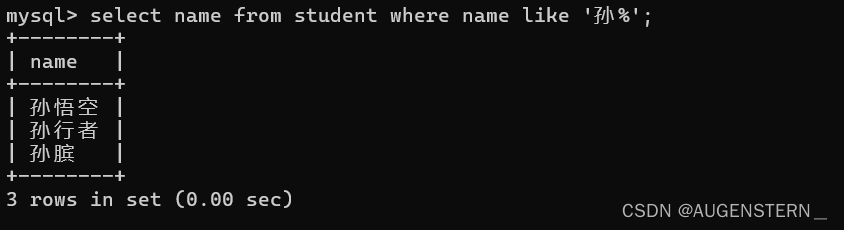
会发现匹配了三个name 都是以 孙 开头的
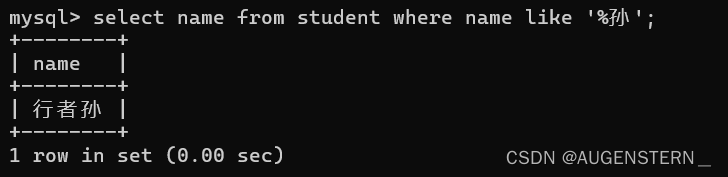
这次匹配则是以孙结尾的name

这次则是查找name中有孙的行
若我们将%换成_

此时的一个_ 则对应一个字符;
若想找到行者孙 则需写成:

12.11 NULL 查询:
查找id为null 或者id 不为null 的行:

12.12 分页查询(LIMIT):
查找数学前三名的同学:

在最后 + limit 3 表示只查找前三个
查找数学成绩4 - 6 名:

其中的offset表示偏移量, offset 3 的意思就是从第四个开始查找,不查找前三个;
上述代码也可以写成
但此时的第一个3表示的是偏移量, 第二个三才是限制查询个数
13 修改(UPDATE):
13.1 语法:
UPDATE 表名 SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]
修改张三和李四的语文成绩, 分别 -10:
原表内容如下:
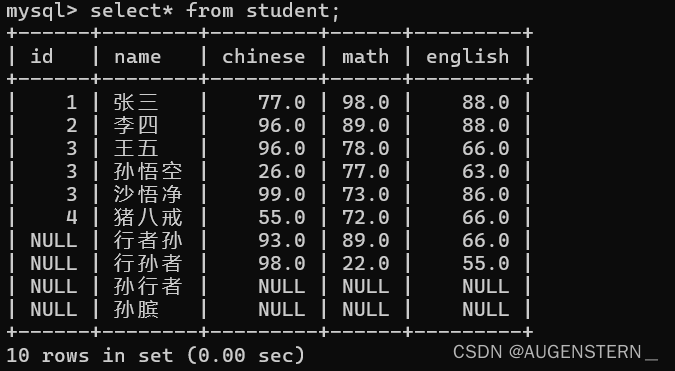
update student set math = math - 10 where name = '李四' or name = '张三';
修改后成绩

很明显,张三和李四的数学成绩都被 - 10;
修改语文最后三名的成绩为0分;
update student set chinese = 0 order by chinese limit 3;
修改后

14 删除行(DELETE)
14.1 语法:
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
14.2 示例:
删除孙悟空同学的成绩:
delete from student where name = '孙悟空';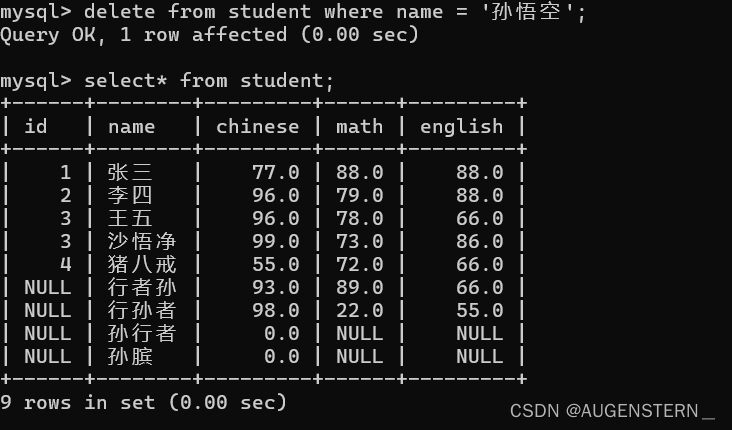
我们会发现,表中已经没有了孙悟空这一行的数据;
以上就是本篇文章的全部内容,感谢大家观看!!!!!!
如果觉得文章不错的话,麻烦大家三连支持一下ಠ_ಠ
制作不易,三连支持谢谢!!!
以上代码都是内容都是本人的思路,若有错误或不足,望多多包涵!!!
最后送给大家一句话,同时也是对我自己的勉励:
繁花锦簇,硕果累累,都需要过程!!!!!!