第一章.机器学习的前期准备
1.1 第一章.机器学习的前期准备
1.jupyter软件的安装
说明:可以使用Anaconda软件中的jupyter软件
1).jupyter 更换文件路径的方法:
①.查找电脑中是否存在 jupyter_notebook_config.py 文件,若不存在,通过命令提示符(快捷键:windows+R 执行cmd指令)执行jupyter notebook --generate-config指令,生成 jupyter_notebook_config.py文件
②.打开jupyter_notebook_config.py 文件,查找c.NotebookApp.notebook_dir = ‘’ 字符串, 取消注释,路径前要加 u ,‘’ 中添加需要更改的路径,例如:

③.如果之前是用快捷键打开的jupyter软件,找到快捷键所在位置,右键属性修改目标(T)和起始位置(S)的路径
·目标(T):删除 jupyter-notebook-script.py 文件后面的所有字符串,输入"需修改的文件夹"
·起始位置(S):输入"需修改的文件夹",没有 “”

注意:如果之前的打开方式是固定到任务栏上 jupyter图标,请修改jupyter快捷方式属性后重新固定任务栏,若不重新固定,会出现新建jupyter文件默认地址还是C盘管理员文件夹的情况
2).jupyter使用方法:
①.创建界面
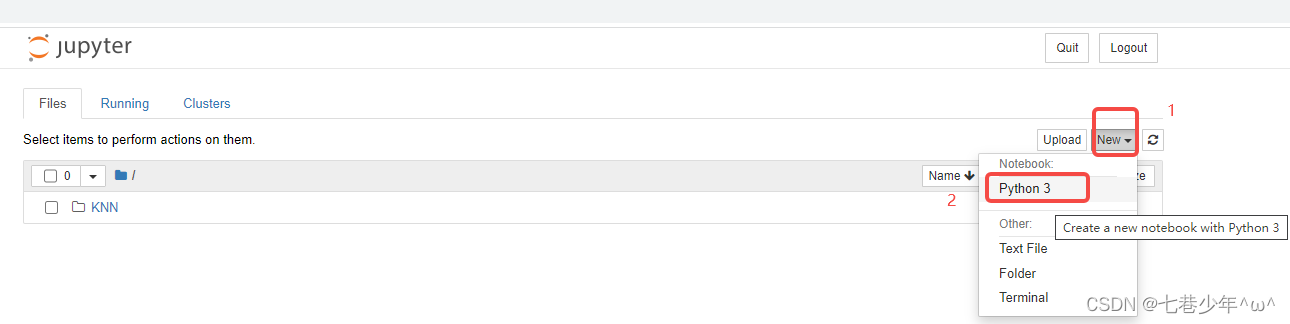
②.执行代码

③.导出方式

2.训练数据/验证数据/测试数据的概念
在建模之前,我们可以把数据分成三部分:训练集(Training data),验证集(Validation data),测试集(Test Data)。
1).训练集:
·用于训练,构建模型
2).验证集:
·用来在模型训练阶段测试模型的好坏(调参过程中使用,这个操作过程通常都省略了,直接用测试集进行评估模型好坏)
3).测试集:
·等模型训练好之后,再用测试机来评估模型的好坏
3.学习方式
学习方式通常分为三种:有监督学习,无监督学习,半监督学习
1).有监督学习:
·有标签,在训练集中找规律,然后对测试数据运用这种规律
2).无监督学习:
·无标签,没有训练集,只有一组数据,在该组数据集内寻找规律
3).半监督学习:
·是有监督学习和无监督学习相结合的一种学习方式,主要是用来解决使用少量带标签的数据和大量没有标签的数据进行训练和分类的问题。
4.常见应用
常见的应用:回归,分类,聚类。
1).回归:
·预测数据为连续型数据

2).分类:
·预测数据为类别型数据,并且类型已知

3).聚类:
·预测数据为类别型数据,但是类型未知











![[Android]View的事件分发机制(源码解析)](https://img-blog.csdnimg.cn/07e8dbac2f8c4bf98169a8afacecb9a4.png)