神行太保戴宗报信,关胜人马直奔梁上泊,请宋江早早收兵,解梁山之难。宋江派了花荣到飞虎峪左边埋伏,林冲到右边埋伏,再叫呼延灼带着凌振,在离城十里附近布置了火炮,然后才令大军撤退。
李成闻达来追,被宋江杀败。到了梁山泊附近,正好丑郡马宣赞的人马拦住去路。

晚上张横去劫营,被关胜抓住。张顺和三阮去救,也中了埋伏,三阮被抓,张顺被混江龙李俊带领童威童猛拼死救了回去。
次日,宣赞和花荣对阵,花荣射了宣赞三箭,宣赞慌忙跑回阵内。关胜一人战秦明和林冲,宋江叫鸣金收兵。晚上呼延灼来找关胜,制定了里应外和的计划。第二天呼延灼阵前(假装)打死镇三山黄信,黄昏时引着关胜去抓宋江。结果关胜中了计中计,被拿下,宣赞和郝思文也都被抓住。
水浒众人大乱斗,大模型也是大乱斗。
大模型BERT、ERNIE、GPT和GLM的前世今生
BERT
在Transformer刚刚诞生不久的时候,谷歌有人考虑到只用编码器是不是也能完成自然语言训练任务,于是就试验了一下,效果出奇的好,顺手写了一篇小论文,这就是2018.10月BERT1.0模型 的诞生。后面不断加大模型规模和训练数据集规模,效果也越来越好,一直到BERT3.0都是自然语言训练的排头兵。
ERNIE
百度看到BERT的成功,有样学样的开发了ERNIE模型,模型基本思路一样,也是只使用编码器,但是在数据集训练方面结合中文进行了创新,使其中文能力要好于同时期的BERT模型。于是也发论文,这就是2019年的ERNIE1.0,后面一直升级到3.0版本。
GPT
OPENAI的人想,我只用解码器是不是也可以? 后来一实验,果然可以,于是也写了论文,这就是GPT1.0。其实GPT是早于BERT模型的,但是GPT相对BERT有劣势,就是同版本、同规模模型效果比不过BERT。所以作者在论文中,不像其它论文那样说这是业内最佳等等语句,而是承认GPT不是业内最好的,但研究发现GPT随着训练数据集的增大其效果也变好,且没有尽头的样子,值得继续研究。于是GPT耐着性子一直在发展,到GPT3.5的时候,随着ChatGPT的问世而一鸣惊人。
GLM
清华的团队想,我把编码器和解码器都使用了会怎么样呢?于是有了GLM模型。在ChatGPT问世不久,ChatGLM也问世了,当时在6B大小的中文模型里,效果是最好的。
在ChatGPT问世后,谷歌的Gemma,百度的文心一言,清华的ChatGLM很快问世。ChatGLM是开源较早,效果也较好的中文大语言模型,目前开源界影响最大的是Meta的羊驼。就市场占有率来说,国外是ChatGPT、国内是文心一言最大。
就像传统的CV模型一样(再复杂的CV模型,最终是由神经网络卷积、线性变换等组成),尽管大模型超乎寻常的大,但其核心主要还是Transformer的编解码模块,甚至只用了编码或解码模块。
ERNIE源码学习
现在我们可以拿到ERNIE1.0 2.0 和3.0模型的源码以及训练说明,所谓读万卷书不如行万里路,读源码+实操是最佳的学习大模型的方法之一。
学习ERNIE代码可以学习这个项目:ERNIE源码学习与实践:为超越ChatGPT打下技术基础! - 飞桨AI Studio星河社区
在飞桨星河社区学习的优势是,可以fork之后一键执行,环境都配好了,还每天提供一定时间的免费GPU使用,是英伟达V100 计算卡哦!
学习BERT代码可以学习这个项目:14.8. 来自Transformers的双向编码器表示(BERT) — 动手学深度学习 2.0.0 documentation
这是李沐老师的动手学深度学习课程,14.8-14.10都是讲的BERT,这个课程也是可以免费使用GPU来学习的。
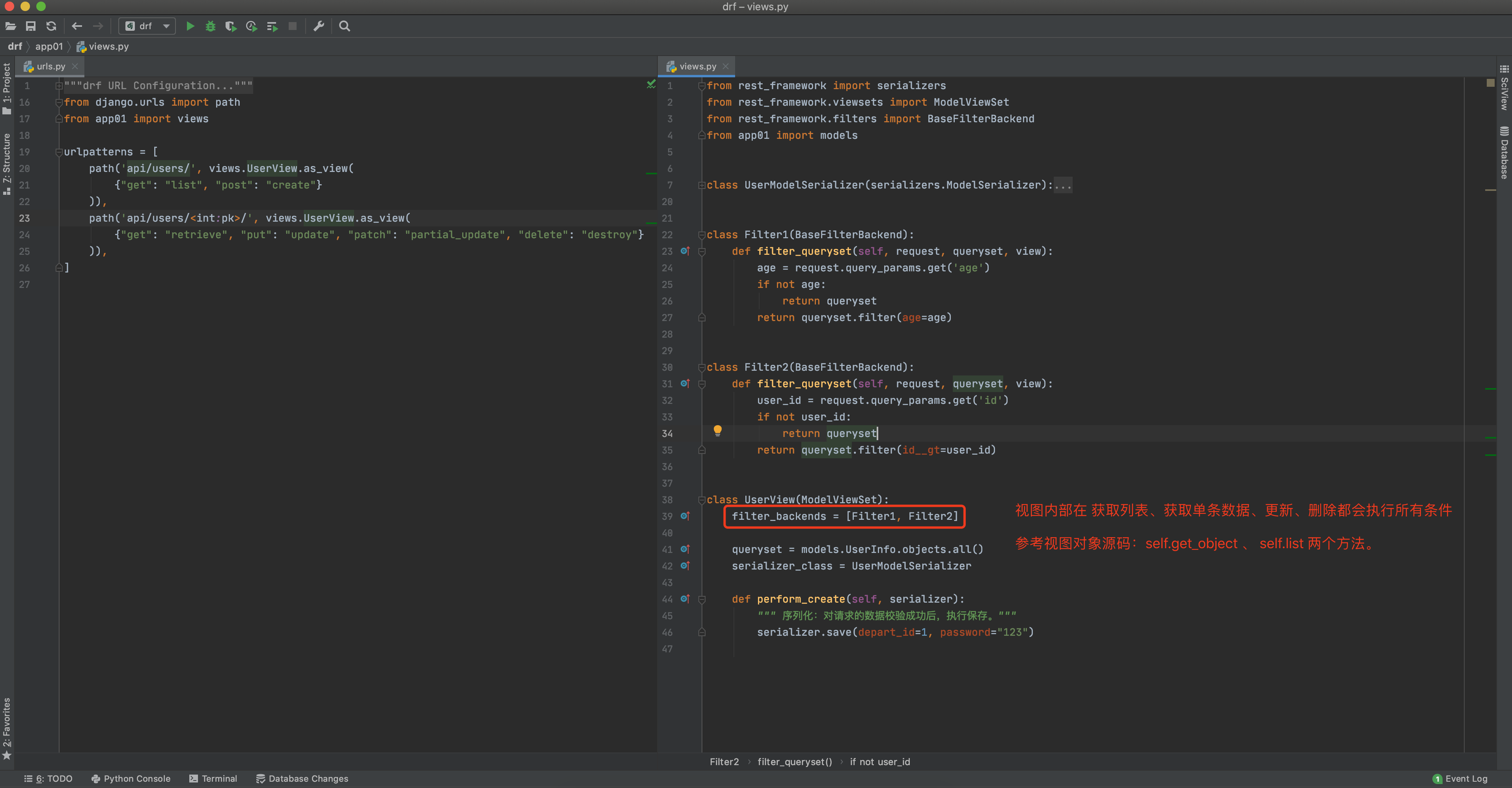
具体ERNIE1.0的部分代码如下:
class ErnieModel(nn.Layer): r""" The bare ERNIE Model transformer outputting raw hidden-states. This model inherits from :class:`~paddlenlp.transformers.model_utils.PretrainedModel`. Refer to the superclass documentation for the generic methods. This model is also a Paddle `paddle.nn.Layer <https://www.paddlepaddle.org.cn/documentation /docs/en/api/paddle/fluid/dygraph/layers/Layer_en.html>`__ subclass. Use it as a regular Paddle Layer and refer to the Paddle documentation for all matter related to general usage and behavior. Args: config (:class:`ErnieConfig`): An instance of ErnieConfig used to construct ErnieModel """ def __init__(self, initializer_range, num_attention_heads, intermediate_size, vocab_size, hidden_size, pad_token_id, max_position_embeddings, type_vocab_size, hidden_dropout_prob, hidden_act, attention_probs_dropout_prob, num_hidden_layers): super(ErnieModel, self).__init__() self.pad_token_id = pad_token_id self.initializer_range = initializer_range weight_attr = paddle.ParamAttr( initializer=nn.initializer.TruncatedNormal(mean=0.0, std=self.initializer_range) ) self.embeddings = ErnieEmbeddings(vocab_size, hidden_size, pad_token_id, max_position_embeddings, type_vocab_size, hidden_dropout_prob=0.1, weight_attr=weight_attr) encoder_layer = nn.TransformerEncoderLayer( hidden_size, num_attention_heads, intermediate_size, dropout=hidden_dropout_prob, activation=hidden_act, attn_dropout=attention_probs_dropout_prob, act_dropout=0, weight_attr=weight_attr, normalize_before=False, ) self.encoder = nn.TransformerEncoder(encoder_layer, num_hidden_layers) self.pooler = ErniePooler(hidden_size, weight_attr) # self.apply(self.init_weights) def get_input_embeddings(self): return self.embeddings.word_embeddings def set_input_embeddings(self, value): self.embeddings.word_embeddings = value def forward( self, input_ids: Optional[Tensor] = None, token_type_ids: Optional[Tensor] = None, position_ids: Optional[Tensor] = None, attention_mask: Optional[Tensor] = None, past_key_values: Optional[Tuple[Tuple[Tensor]]] = None, inputs_embeds: Optional[Tensor] = None, use_cache: Optional[bool] = None, output_hidden_states: Optional[bool] = None, output_attentions: Optional[bool] = None, return_dict: Optional[bool] = None, ): r""" Args: input_ids (Tensor): Indices of input sequence tokens in the vocabulary. They are numerical representations of tokens that build the input sequence. It's data type should be `int64` and has a shape of [batch_size, sequence_length]. token_type_ids (Tensor, optional): Segment token indices to indicate different portions of the inputs. Selected in the range ``[0, type_vocab_size - 1]``. If `type_vocab_size` is 2, which means the inputs have two portions. Indices can either be 0 or 1: - 0 corresponds to a *sentence A* token, - 1 corresponds to a *sentence B* token. Its data type should be `int64` and it has a shape of [batch_size, sequence_length]. Defaults to `None`, which means we don't add segment embeddings. position_ids (Tensor, optional): Indices of positions of each input sequence tokens in the position embeddings. Selected in the range ``[0, max_position_embeddings - 1]``. Shape as `[batch_size, num_tokens]` and dtype as int64. Defaults to `None`. attention_mask (Tensor, optional): Mask used in multi-head attention to avoid performing attention on to some unwanted positions, usually the paddings or the subsequent positions. Its data type can be int, float and bool. When the data type is bool, the `masked` tokens have `False` values and the others have `True` values. When the data type is int, the `masked` tokens have `0` values and the others have `1` values. When the data type is float, the `masked` tokens have `-INF` values and the others have `0` values. It is a tensor with shape broadcasted to `[batch_size, num_attention_heads, sequence_length, sequence_length]`. For example, its shape can be [batch_size, sequence_length], [batch_size, sequence_length, sequence_length], [batch_size, num_attention_heads, sequence_length, sequence_length]. We use whole-word-mask in ERNIE, so the whole word will have the same value. For example, "使用" as a word, "使" and "用" will have the same value. Defaults to `None`, which means nothing needed to be prevented attention to. inputs_embeds (Tensor, optional): If you want to control how to convert `inputs_ids` indices into associated vectors, you can pass an embedded representation directly instead of passing `inputs_ids`. past_key_values (tuple(tuple(Tensor)), optional): The length of tuple equals to the number of layers, and each inner tuple haves 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`) which contains precomputed key and value hidden states of the attention blocks. If `past_key_values` are used, the user can optionally input only the last `input_ids` (those that don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `input_ids` of shape `(batch_size, sequence_length)`. use_cache (`bool`, optional): If set to `True`, `past_key_values` key value states are returned. Defaults to `None`. output_hidden_states (bool, optional): Whether to return the hidden states of all layers. Defaults to `False`. output_attentions (bool, optional): Whether to return the attentions tensors of all attention layers. Defaults to `False`. return_dict (bool, optional): Whether to return a :class:`~paddlenlp.transformers.model_outputs.ModelOutput` object. If `False`, the output will be a tuple of tensors. Defaults to `False`. Returns: An instance of :class:`~paddlenlp.transformers.model_outputs.BaseModelOutputWithPoolingAndCrossAttentions` if `return_dict=True`. Otherwise it returns a tuple of tensors corresponding to ordered and not None (depending on the input arguments) fields of :class:`~paddlenlp.transformers.model_outputs.BaseModelOutputWithPoolingAndCrossAttentions`. Example: .. code-block:: import paddle from paddlenlp.transformers import ErnieModel, ErnieTokenizer tokenizer = ErnieTokenizer.from_pretrained('ernie-1.0') model = ErnieModel.from_pretrained('ernie-1.0') inputs = tokenizer("Welcome to use PaddlePaddle and PaddleNLP!") inputs = {k:paddle.to_tensor([v]) for (k, v) in inputs.items()} sequence_output, pooled_output = model(**inputs) """ if input_ids is not None and inputs_embeds is not None: raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time.") # print("hello Ernie") # init the default bool value output_attentions = output_attentions if output_attentions is not None else False output_hidden_states = output_hidden_states if output_hidden_states is not None else False return_dict = return_dict if return_dict is not None else False use_cache = use_cache if use_cache is not None else False past_key_values_length = 0 if past_key_values is not None: past_key_values_length = past_key_values[0][0].shape[2] if attention_mask is None: attention_mask = paddle.unsqueeze( (input_ids == self.pad_token_id).astype(self.pooler.dense.weight.dtype) * -1e4, axis=[1, 2] ) if past_key_values is not None: batch_size = past_key_values[0][0].shape[0] past_mask = paddle.zeros([batch_size, 1, 1, past_key_values_length], dtype=attention_mask.dtype) attention_mask = paddle.concat([past_mask, attention_mask], axis=-1) # For 2D attention_mask from tokenizer elif attention_mask.ndim == 2: attention_mask = paddle.unsqueeze(attention_mask, axis=[1, 2]).astype(paddle.get_default_dtype()) attention_mask = (1.0 - attention_mask) * -1e4 attention_mask.stop_gradient = True embedding_output = self.embeddings( input_ids=input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds, past_key_values_length=past_key_values_length, ) self.encoder._use_cache = use_cache # To be consistent with HF encoder_outputs = self.encoder( embedding_output, src_mask=attention_mask, cache=past_key_values, output_attentions=output_attentions, output_hidden_states=output_hidden_states, return_dict=return_dict, ) if isinstance(encoder_outputs, type(embedding_output)): sequence_output = encoder_outputs pooled_output = self.pooler(sequence_output) return (sequence_output, pooled_output) else: sequence_output = encoder_outputs[0] pooled_output = self.pooler(sequence_output) if not return_dict: return (sequence_output, pooled_output) + encoder_outputs[1:] return BaseModelOutputWithPoolingAndCrossAttentions( last_hidden_state=sequence_output, pooler_output=pooled_output, past_key_values=encoder_outputs.past_key_values, hidden_states=encoder_outputs.hidden_states, attentions=encoder_outputs.attentions, )

宋江三言两语说动关胜三人加入梁山。关胜说我没啥可报恩,救卢俊义我愿意做前部。于是第二天关胜宣赞郝思文,带着原来的兵马做前锋,梁山原来打大名府的头领一个不缺,又添了李俊张顺,依次向大名府进发。
天降大雪,吴用差人到大名城外挖陷阱,引索超来战,索超连人带马掉进去了。
欲知索超性命如何,且听下回分解。