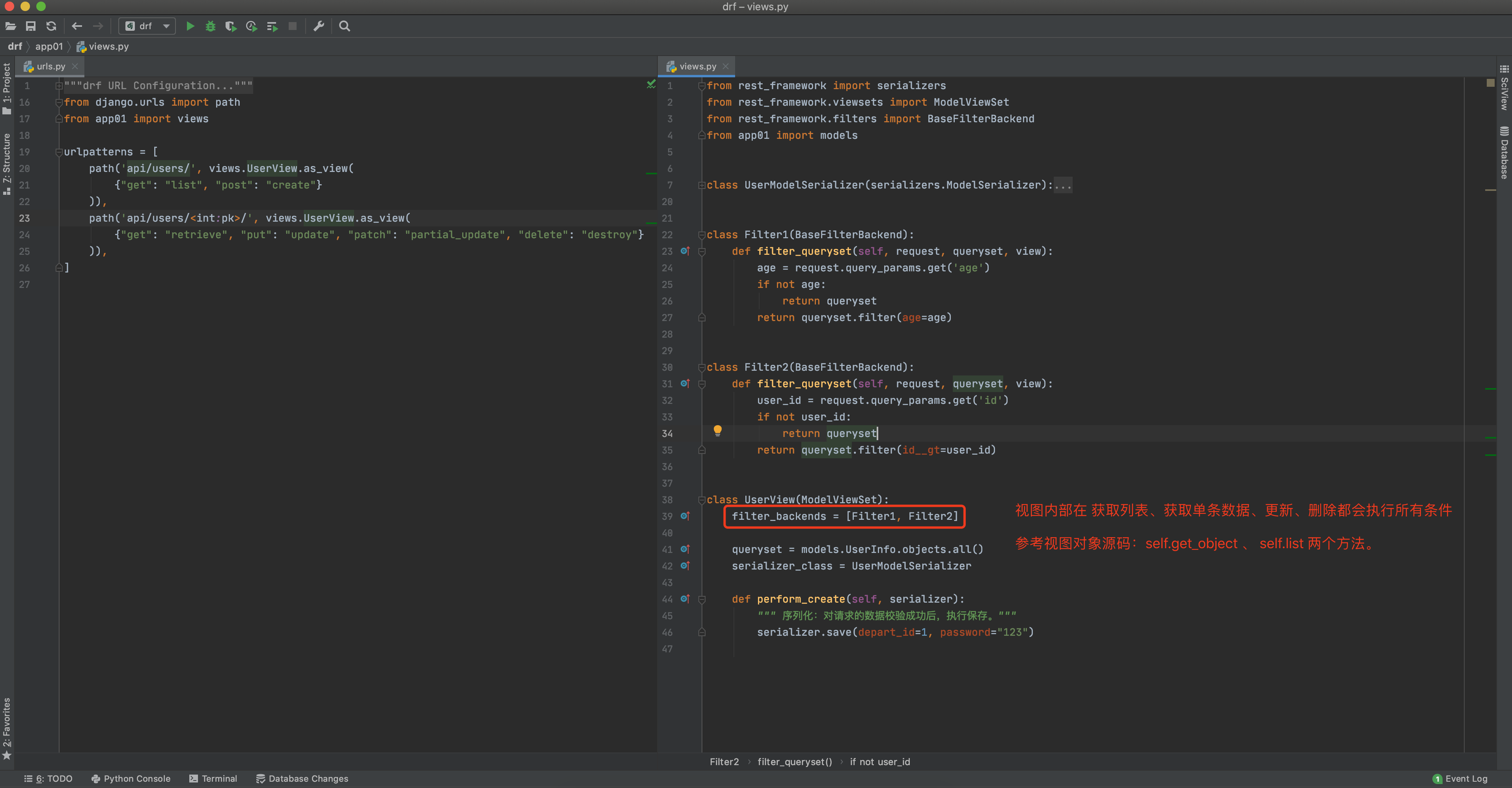
1、不可变对象
1.1、概念
不可变类是指一旦创建对象实例后,就不能修改该实例的状态。这意味着不可变类的对象是不可修改的,其内部状态在对象创建后不能被更改。不可变类通常具有以下特征:
- 实例状态不可改变:一旦不可变类的对象被创建,其内部状态(字段或属性)将不会改变。这意味着不可变类中的字段都应该声明为final,以防止被修改。
- 线程安全:由于不可变类的实例状态不会改变,因此它们在多线程环境中是安全的。多个线程可以同时访问不可变对象,而不需要担心同步问题。
- 可共享:由于不可变对象的状态不会改变,因此它们可以被多个客户端共享而无需担心数据的意外修改。
- 简化设计:不可变类的设计相对简单,因为它们不需要提供修改状态的方法或者进行状态变更的复杂逻辑。
- 缓存友好:不可变对象适合用于缓存,因为它们的状态不会改变,可以安全地在缓存中共享。
不可变类的经典例子是Java中的String类。一旦创建了String对象,就无法更改其内容,任何对字符串的操作都会返回一个新的字符串对象。
创建不可变类的关键是:
- 将类的字段声明为final,防止被修改。
- 不提供修改字段的方法。
- 如果类的字段是可变对象(如集合类),需要在构造函数中进行防御性拷贝,以防止外部对象修改内部状态。
1.2、案例
模拟十个线程同时使用SimpleDateFormat对日期进行格式化:
@Slf4j(topic = "c.Demo2")
public class Demo2 {
public static void main(String[] args) {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
for (int i = 0; i < 10; i++) {
new Thread(()->{
try {
log.debug(String.valueOf(simpleDateFormat.parse("2024-03-30")));
} catch (Exception e) {
log.error("error", e);
}
}).start();
}
}
}运行结果:
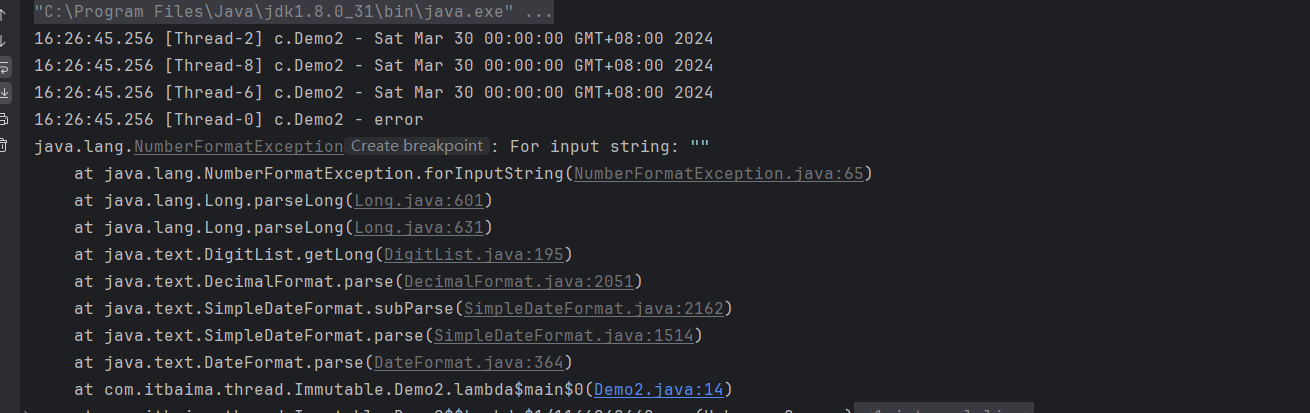
最终发现,有的线程执行成功,有的线程执行失败,原因是因为parse方法是线程不安全的。
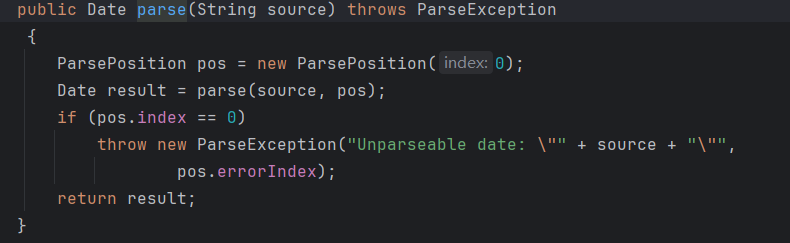
我们可以通过加锁的方式解决这个问题:
@Slf4j(topic = "c.Demo2")
public class Demo2 {
public static void main(String[] args) {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
for (int i = 0; i < 10; i++) {
new Thread(()->{
synchronized (simpleDateFormat) {
try {
log.debug(String.valueOf(simpleDateFormat.parse("2024-03-30")));
} catch (Exception e) {
log.error("error", e);
}
}
}).start();
}
}
}最终的运行结果符合预期
但是加锁会同时导致性能上的损失,是否有其他方式解决问题?
我们可以使用DateTimeFormatter去进行日期格式化:
@Slf4j(topic = "c.Demo3")
public class Demo3 {
public static void main(String[] args) {
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
for (int i = 0; i < 10; i++) {
new Thread(()->{
LocalDate parse = dateTimeFormatter.parse("2024-03-30", LocalDate::from);
log.debug(String.valueOf(parse));
}).start();
}
}
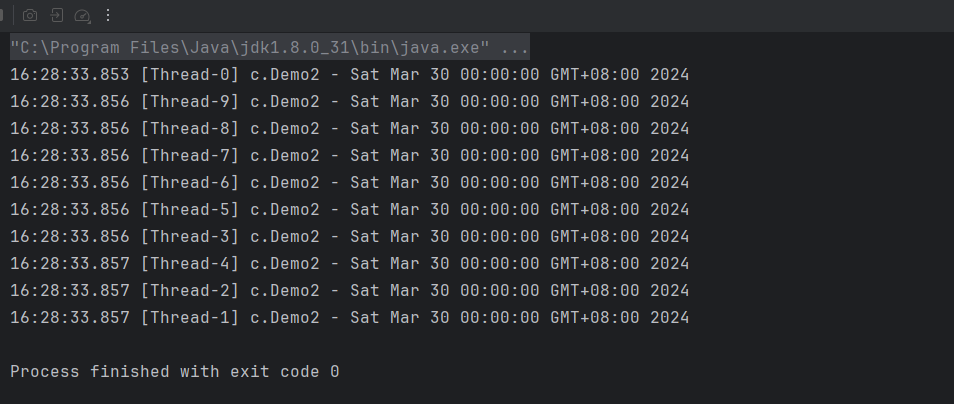
}最终的结果符合预期,没有发生线程安全问题:

DateTimeFormatter类与成员变量都是不可变的,属性用 final 修饰保证了该属性是只读的,不能修改,类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性。
1.3、保护性拷贝
可以用于确保可变对象的私有数据在传递给外部时不会被外部对象修改。这种技术通常在设计不可变类或者需要保护可变对象的类中使用。
防御性拷贝的主要思想是在将可变对象的引用传递给外部时,先创建一个该可变对象的副本(拷贝),而不是直接传递原始对象的引用。这样做可以防止外部对象对原始对象进行修改,从而保护原始对象的不可变性或者状态一致性。
例如在构造不可变对象时:
public class ImmutableClass {
private final List<Integer> numbers;
public ImmutableClass(List<Integer> numbers) {
this.numbers = new ArrayList<>(numbers);
}
}
返回对象时,返回的是对象的拷贝而不是原始对象,避免外部对于原始变量进行修改。
public class MutableClass {
private List<Integer> numbers;
public List<Integer> getNumbers() {
return new ArrayList<>(numbers);
}
}
Q1:为什么在构造不可变对象时创建副本可以保证传入的可变对象不会在外部被修改?
在 Java 中,对象的赋值实际上是传递引用,而不是传递对象本身。这意味着如果你简单地将一个对象的引用传递给另一个变量,这两个变量将指向同一个对象。如果对其中一个变量进行修改,那么另一个变量也会反映出这种修改,因为它们指向同一个内存位置。
没有使用防御性拷贝的情况:
public ImmutableClass(List<Integer> numbers) { this.numbers = numbers; // 直接赋值,不进行防御性拷贝 } // 外部代码 List<Integer> mutableList = new ArrayList<>(); mutableList.add(1); mutableList.add(2); ImmutableClass immutable = new ImmutableClass(mutableList); mutableList.add(3); System.out.println(immutable.getNumbers()); // 输出 [1, 2, 3],不符合不可变类的预期行为在这种情况下,ImmutableClass的numbers 字段和外部的mutableList指向同一个对象,因此外部代码对mutableList的修改会直接影响到ImmutableClass实例中的numbers字段。
使用了防御性拷贝时:
public ImmutableClass(List<Integer> numbers) { this.numbers = new ArrayList<>(numbers); // 进行防御性拷贝 } // 外部代码 List<Integer> mutableList = new ArrayList<>(); mutableList.add(1); mutableList.add(2); ImmutableClass immutable = new ImmutableClass(mutableList); mutableList.add(3); System.out.println(immutable.getNumbers()); // 输出 [1, 2],符合不可变类的预期行为在这种情况下,ImmutableClass的numbers 字段被赋值为mutableList的一个副本,即使外部代码修改了mutableList,也不会影响到ImmutableClass实例中的numbers字段,因为它们指向不同的内存位置。
相当于如果没有进行拷贝,那么成员变量private final List<Integer> numbers;的地址指向的就是外部代码中List<Integer> mutableList的地址,mutableList的值发生改变,那么numbers的值同时会发生改变。
当进行拷贝时,成员变量private final List<Integer> numbers;的地址指向的是构造ImmutableClass对象时创建的新的ArrayList的地址,即使外部修改了原始列表,不可变类中的列表也不会受到影响。
Q2:防御性拷贝是深拷贝还是浅拷贝?
防御性拷贝通常是指深拷贝,而不是浅拷贝。深拷贝会创建一个全新的对象,并且拷贝了原对象的所有数据,包括对象内部的数据结构,使得拷贝对象与原对象完全独立,互不影响。
在防御性拷贝中使用深拷贝的原因是为了确保在传递可变对象时不会影响到不可变对象的状态,从而保持对象的不变性。当不可变类接收一个可变对象作为参数时,通常会对这个可变对象进行深拷贝,创建一个新的对象来保存可变对象的副本,而不是直接引用可变对象。
1.4、享元模式
享元模式(Flyweight Pattern)是一种结构型设计模式,旨在通过共享对象来最大程度地减少内存使用和提高性能。该模式适用于大量相似对象的情况,通过共享相同的部分来减少内存消耗。即:需要重复使用数量有限的同一类对象。
享元模式的体现:例如Long的valueOf方法
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}当传递的值在-128~127之间时,不会创建新的对象,而是从缓存池中提取已有的对象,避免重复创建。
private static class LongCache {
private LongCache(){}
static final Long cache[] = new Long[-(-128) + 127 + 1];
static {
for(int i = 0; i < cache.length; i++)
cache[i] = new Long(i - 128);
}
}享元模式案例:
@Slf4j(topic = "c.Demo1")
public class Demo1 {
public static void main(String[] args) {
//线程池中有两个连接对象
Pool pool = new Pool(2);
//创建五个线程去获取
for (int i = 0; i < 5; i++) {
int finalI = i;
new Thread(()->{
MockConnection mockConnection = pool.getMockConnection();
log.info("线程"+(finalI +1)+"获取到了连接");
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
pool.freeConnection(mockConnection);
log.info("线程"+(finalI +1)+"归还了连接");
},"线程"+(i+1)).start();
}
}
}
@Slf4j(topic = "c.Pool")
class Pool{
/*
自定义线程池大小
*/
private final int poolSize;
/*
自定义线程池数组
*/
private MockConnection[] mockConnections;
/*
自定义线程池状态 0 空闲 1 使用
*/
private AtomicIntegerArray stateArr;
/**
*
* @param poolSize 线程池大小
*/
public Pool(int poolSize) {
this.poolSize = poolSize;
this.mockConnections = new MockConnection[poolSize];
this.stateArr = new AtomicIntegerArray(new int[poolSize]);
for (int i = 0; i < this.mockConnections.length; i++) {
MockConnection mockConnection = new MockConnection("线程" + (i + 1));
this.mockConnections[i] = mockConnection;
}
}
/**
* 获取连接
* @return 数组中的连接对象
*/
public MockConnection getMockConnection() {
while (true) {
for (int i = 0; i < mockConnections.length; i++) {
//找寻连接池中自定义线程状态为0-空闲的线程
if (stateArr.get(i) == 0){
if (stateArr.compareAndSet(i, 0, 1)) {
return mockConnections[i];
}
}
}
synchronized (this){
try {
this.wait();
log.info(Thread.currentThread().getName()+"未获取到连接,等待中");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
/**
* 归还连接
* @param mockConnection 连接
*/
public void freeConnection(MockConnection mockConnection) {
for (int i = 0; i < this.mockConnections.length; i++) {
if (mockConnection.equals(this.mockConnections[i])) {
stateArr.set(i,0);
synchronized (this){
this.notifyAll();
}
break;
}
}
}
}
class MockConnection implements Connection {
private String name;
public MockConnection(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
//重写父类中的方法.....
}在上面的案例中,会在构造Pool对象时预先创建好一定数量的连接,这样后续用到的时候就不用重复创建了。
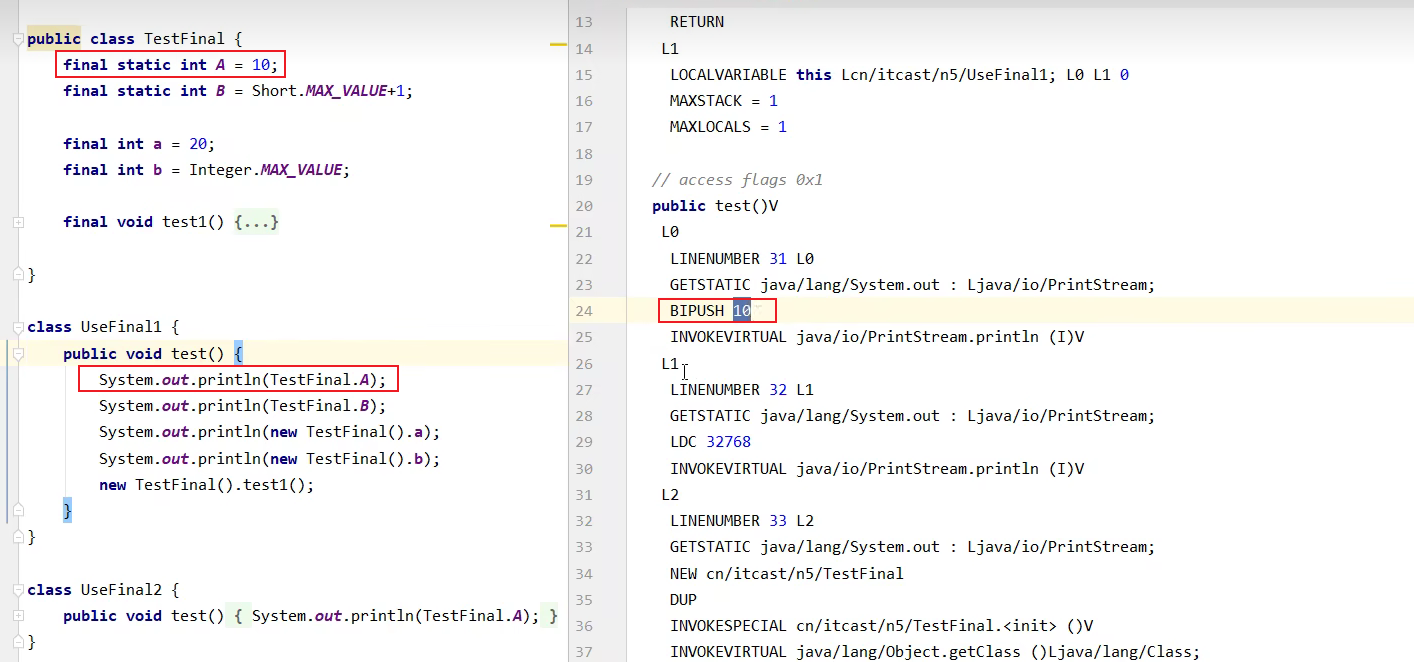
1.5、final的原理
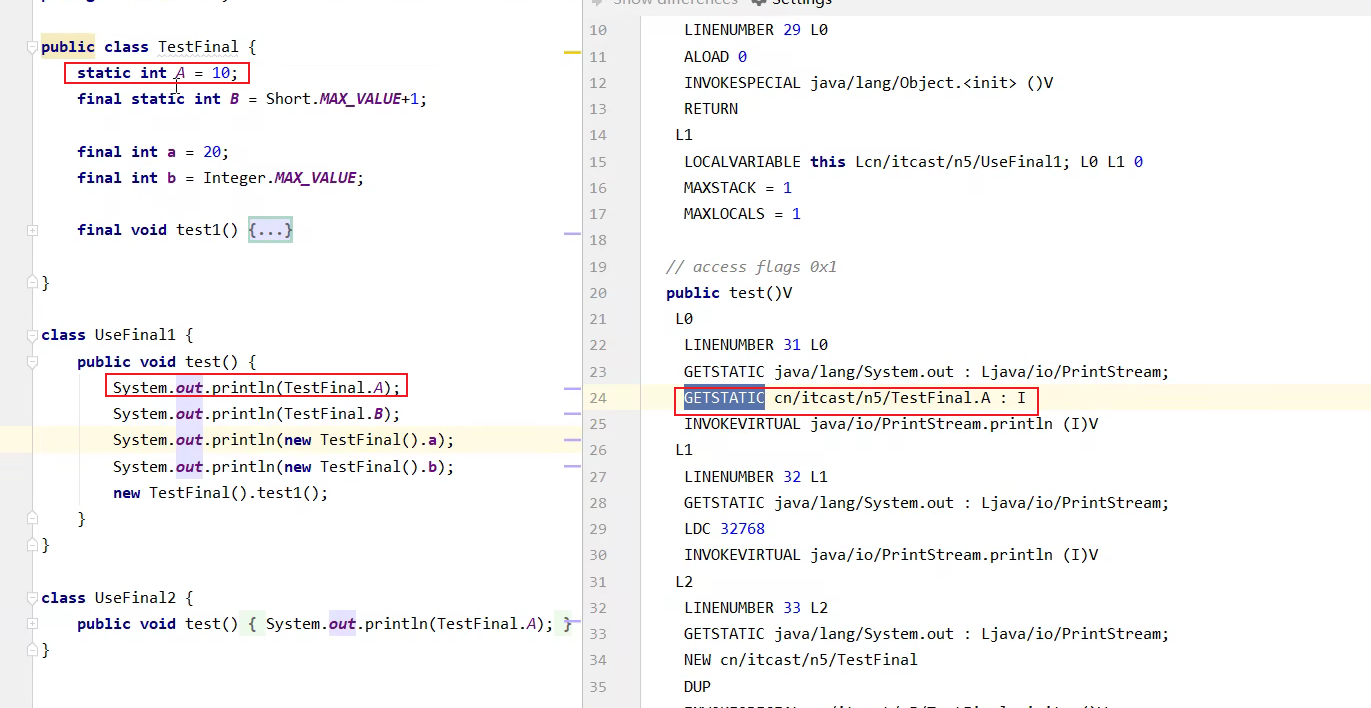
被final关键字修饰的变量在进行设置时,同样会加入读写屏障,这一点和volatile关键字很相似。例如int i = 20,此时没有被final关键字修饰,在字节码的层面是分为两步,第一步是初始化int,然后才是赋值为20,如果在初始化的过程中就被其他线程看到很明显是不正确的。
当读取被final关键字修饰的变量时,相当于将final变量的值复制一份到读取方法的栈内存中:
而读取非final的变量时,是要去另一个类读取变量的值,效率较低。
2、线程池
2.1、概念
Java线程池是一种用于管理和复用线程的机制,它通过维护一组工作线程并管理它们的执行来提高多线程应用程序的性能和资源利用率。线程池通常由线程池管理器(ThreadPoolExecutor)和一组工作线程组成。
线程池的组成:
- 任务队列(Task Queue):用于存储待执行的任务。当线程池中的工作线程执行完当前任务后,会从任务队列中获取下一个任务执行。
- 工作线程(Worker Threads):实际执行任务的线程。线程池中会维护一定数量的工作线程,它们在有任务时会被分配执行任务,执行完毕后又返回到线程池中等待下一个任务。
- 线程池管理器(ThreadPoolExecutor):负责管理线程池的创建、终止、任务提交和执行等操作。
线程池的常见配置参数:
- 核心线程数(Core Pool Size):线程池中保持的最小工作线程数量。即使工作线程处于空闲状态,也不会被回收。
- 最大线程数(Maximum Pool Size):线程池中允许的最大工作线程数量。当任务队列已满且工作线程数小于最大线程数时,线程池会创建新的工作线程来处理任务。
- 工作线程的持续时间(Duration):工作线程也称为应急线程,当核心线程和任务队列已满,会被创建进行任务处理。任务处理完成后会被回收。
- 时间单位(TimeUnit):工作线程持续时间的单位。
- 阻塞队列(BlockingQueue):存储待执行任务的队列。
- 线程工厂(ThreadFactory):线程池创建线程时调用的工厂方法,通过此方法可以设置线程的优先级、线程命名规则以及线程类型(用户线程还是守护线程)等。
- 拒绝策略(RejectedExecutionHandler):当队列已满,核心线程数+工作线程数>最大线程数时,执行的策略。
其中,最大线程数=核心线程数+工作线程数。
线程池的工作流程:
- 当有任务提交给线程池时,线程池会根据任务数量和线程池的配置来决定如何处理任务。
- 当任务数量小于核心线程数时,线程池会创建线程执行任务。
- 当任务数量超过核心线程数,会将多余的任务放入阻塞队列中等待。
- 当任务数量超过核心线程数,并且阻塞队列已满,会创建工作线程去临时进行处理。
- 当任务数量超过核心线程数,并且阻塞队列已满,并且核心线程数+工作线程数>最大线程数时,会触发拒绝策略。
优先使用核心线程进行处理,其次放入阻塞队列,再次使用工作线程,最后触发拒绝策略。
2.2、阻塞队列
阻塞队列时线程池中用于存储待执行任务的一种特殊队列。它与普通队列的区别在于,当队列已满时,阻塞队列会导致向队列中添加元素的线程阻塞,直到队列中有空闲位置或者队列被关闭才能继续添加元素。同样,当队列为空时,阻塞队列会导致从队列中取出元素的线程阻塞,直到队列中有可用元素或者队列被关闭才能继续取出元素。
阻塞队列在线程池中的作用主要体现在两个方面:
- 任务提交:当线程池中的工作线程数量达到核心线程数时,后续提交的任务会被放入阻塞队列中等待执行。如果队列已满(即队列的容量达到上限),则提交任务的线程会被阻塞,直到队列中有空闲位置或者队列被关闭才能继续提交任务。
- 任务执行:工作线程从阻塞队列中取出任务进行执行。如果队列为空(即没有待执行的任务),工作线程会被阻塞,直到队列中有可执行的任务或者队列被关闭才能继续取出任务执行。
下面列举几个常见的阻塞队列:
- LinkedBlockingQueue:基于链表实现的阻塞队列,可以设置容量,当容量达到上限时阻塞入队操作或者出队操作。
- ArrayBlockingQueue:基于数组实现的阻塞队列,需要指定容量,当容量达到上限时阻塞入队操作或者出队操作。
- PriorityBlockingQueue:基于优先级堆实现的阻塞队列,不需要指定容量,元素按照优先级顺序出队,如果队列为空则出队操作会阻塞。
2.3、拒绝策略
线程池的拒绝策略(Rejected Execution Policy)定义了当线程池无法接受新任务时,应该如何处理这些被拒绝的任务。拒绝策略在线程池中起到非常重要的作用,它可以避免系统因为无法处理过多的任务而发生故障,同时也可以根据具体的业务需求来灵活地处理任务的拒绝。
Java线程池中提供了四种内置的拒绝策略:
- 抛出RejectedExecutionException异常拒绝新任务,这是默认的拒绝策略。
- 让提交任务的线程(调用execute方法的线程)自行执行被拒绝的任务。这样做可以避免任务被丢弃,但会使得任务提交线程来处理被拒绝的任务,可能会导致任务提交线程阻塞。
- 直接丢弃被拒绝的任务,不做任何处理。
- 丢弃队列中最老的任务(即队列中最早被添加的任务),然后尝试重新提交被拒绝的任务。这样做可以保留较新的任务,但可能会丢失一些较旧的任务。
同时Java还提供了自定义拒绝策略的接口RejectedExecutionHandler,可以通过实现这个接口来定义自定义的拒绝策略,满足特定的业务需求。例如,你可以实现一个自定义的拒绝策略来记录被拒绝的任务、将任务重新放入队列或者通过其他方式进行处理。
2.4、线程池分类
在java.util.concurrent下的Executors类中,提供了创建线程池的静态方法,下面对常见的进行简单介绍:
2.4.1、固定大小的线程池
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
} public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
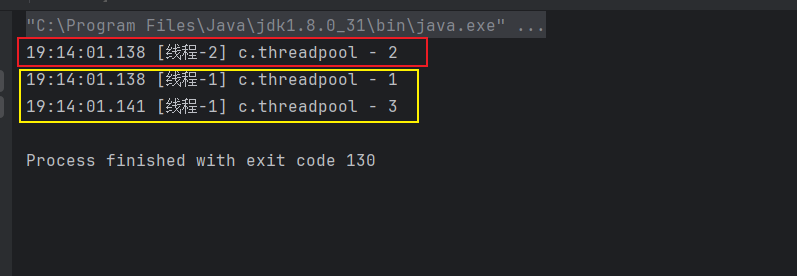
}最大线程数等于核心线程数,没有应急线程,阻塞队列长度为Integer的最大值。
@Slf4j(topic = "c.threadpool")
public class FixedPoolDemo {
public static void main(String[] args) {
//带固定大小的线程池
//最大线程数等于核心线程数,应急线程为0,阻塞队列长度为Integer的最大值
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2, new ThreadFactory() {
AtomicInteger atomicInteger = new AtomicInteger(1);
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "线程-" + atomicInteger.getAndIncrement());
}
});
fixedThreadPool.execute(()->{
log.debug("1");
});
fixedThreadPool.execute(()->{
log.debug("2");
});
fixedThreadPool.execute(()->{
log.debug("3");
});
}
}
应用场景:
-
服务器端的并发控制:在服务器端,如果有明确的并发控制需求,需要限制同时处理的请求数量,可以使用固定大小的线程池。这样可以有效地控制系统资源的使用,避免因线程过多导致的资源竞争和性能下降。
-
对资源访问进行限制:例如,对于数据库连接池、文件访问等资源,固定大小的线程池可以控制同时访问资源的线程数量,避免资源过度占用和阻塞。
-
任务处理的稳定性需求:在一些场景下,需要保证任务的处理稳定性和可靠性,而不希望因为线程数的动态变化导致系统性能的波动。固定大小的线程池可以提供稳定的执行环境,使得任务处理的稳定性更高。
-
对线程资源有限制的环境:在一些环境中,线程资源是有限的,例如在移动设备上或者嵌入式系统中,固定大小的线程池可以避免消耗过多的系统资源。
2.4.2、单线程线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
} public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}最大线程数等于核心线程数等于1,没有应急线程,阻塞队列长度为Integer的最大值。
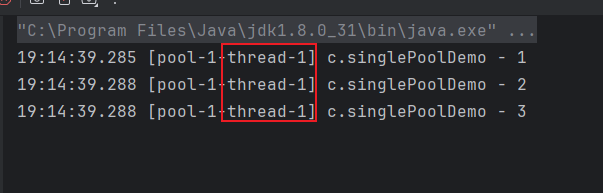
@Slf4j(topic = "c.singlePoolDemo")
public class SinglePoolDemo {
public static void main(String[] args) {
//单线程线程池
//最大线程数=核心线程数=1,没有应急线程,阻塞队列最大值为Integer最大值
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
singleThreadExecutor.execute(() -> log.debug("1"));
singleThreadExecutor.execute(() -> log.debug("2"));
singleThreadExecutor.execute(() -> log.debug("3"));
}
}
应用场景:
-
顺序执行任务:单线程线程池保证任务按照提交的顺序依次执行,不会并发执行多个任务,适用于需要保持任务执行顺序的场景。
-
线程资源有限的环境:在一些资源有限的环境中(例如移动设备、嵌入式系统),单线程线程池可以避免消耗过多的系统资源,保证系统的稳定性。
-
避免线程竞争和资源竞争:单线程线程池可以避免多个线程之间的竞争和资源的竞争,减少线程安全问题的发生,适用于一些对线程安全性要求较高的场景。
-
串行化处理任务:某些任务需要串行化地处理,例如对共享资源进行操作时需要保证操作的原子性,单线程线程池可以确保这种任务的串行执行。
与固定大小线程池的联系在于,如果固定大小线程池设置线程数为1,则可以达到和单线程线程池相同的效果。
2.4.3、带缓冲的线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}核心线程数为0,最大线程数是Integer的最大值。(全部都是应急线程),应急线程的存活时间为60s。并且队列是没有容量的,必须一存一取。
SynchronousQueue并不保存任务,而是在任务提交时立即将任务交给消费者线程,或者在没有消费者线程时阻塞等待消费者线程的到来。(相当于一手交钱一手交货)。
下面是SynchronousQueue的一些特点:
- 零容量:SynchronousQueue是一个零容量的队列,意味着它不保存任何元素。任务只有在被消费者线程接收时才会移出队列,否则任务会一直阻塞等待消费者。
- 生产者与消费者的直接交互:SynchronousQueue在任务提交时会直接将任务交给消费者线程,而不是将任务存储在队列中等待消费。这种直接交互的方式可以避免任务在队列中的排队等待,减少了任务处理的延迟。
- 适用于同步执行任务:由于 SynchronousQueue不保存任务,因此适用于需要同步执行任务的场景。当任务提交时,如果有空闲的消费者线程,任务会被立即执行;如果没有空闲的消费者线程,则任务会阻塞等待,直到有消费者线程可用为止。
- 适用于一些特定的线程池配置:SynchronousQueue在线程池的核心线程参数设置为 0 时特别有用。这种配置下,线程池中的工作线程数始终为 0,所有任务都会被直接交给新创建的线程执行,可以避免线程的空闲和资源浪费。
- 防止任务堆积:由于 SynchronousQueue不保存任务,所以不会出现任务堆积的情况。当任务提交的速度超过消费者线程的处理速度时,新提交的任务会阻塞等待,避免了任务队列过长导致的内存溢出或性能问题。
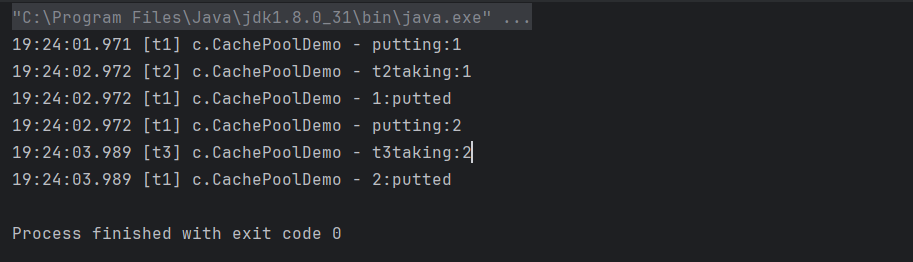
@Slf4j(topic = "c.CachePoolDemo")
public class CachePoolDemo {
public static void main(String[] args) throws InterruptedException {
//带缓冲的线程池
//核心线程数为0,最大线程数为Integer的最大值(全部都是应急线程),应急线程存活时间为60s
//队列没有容量,必须一存一取
ExecutorService executorService = Executors.newCachedThreadPool();
SynchronousQueue<Integer> integers = new SynchronousQueue<>();
new Thread(()->{
try {
log.debug("putting:{}",1);
integers.put(1);
log.debug("{}:putted",1);
log.debug("putting:{}",2);
integers.put(1);
log.debug("{}:putted",2);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},"t1").start();
Thread.sleep(1000);
new Thread(()->{
log.debug(Thread.currentThread().getName()+"taking:{}",1);
try {
integers.take();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},"t2").start();
Thread.sleep(1000);
new Thread(()->{
log.debug(Thread.currentThread().getName()+"taking:{}",2);
try {
integers.take();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},"t3").start();
}
}在上面的案例中,t1线程负责向阻塞队列中存入了两个元素,t2,t3负责取出元素,可以看到,只有1被t2线程取出后,2才被t1线程放入阻塞队列,而不是1,2同时被放入。
2.5、submit&execute
用于向线程池提交一个任务,并返回一个表示任务处理结果的future对象。submit()方法通常用于提交实现了Callable接口的任务,也可以用于提交实现了Runnable接口的任务。
与execute的联系:同样都是向线程池提交任务,submit通常用于接收返回值,但是底层同样调用的也是execute。
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
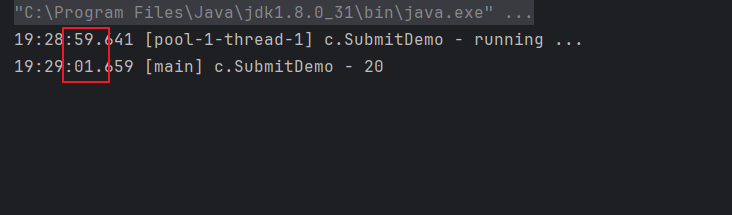
}@Slf4j(topic = "c.SubmitDemo")
public class SubmitDemo1 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
Future<Integer> future = fixedThreadPool.submit(() -> {
log.debug("running ...");
Thread.sleep(2000);
return 20;
});
log.debug(future.get().toString());
}
}
经过2s获取到了执行结果:
2.6、invokeAll&invokeAny
2.6.1、invokeAll
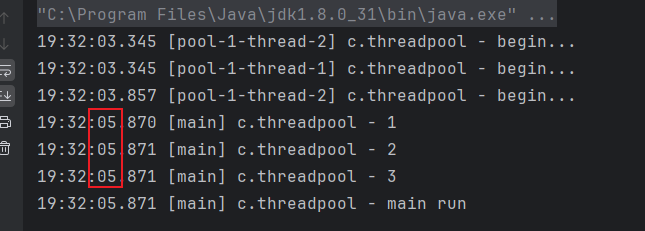
@Slf4j(topic = "c.threadpool")
public class SubmitDemo2 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
//提交task中所有任务
List<Future<Object>> futures = fixedThreadPool.invokeAll(Arrays.asList(
() -> {
log.debug("begin...");
Thread.sleep(1000);
return "1";
},
() -> {
log.debug("begin...");
Thread.sleep(500);
return "2";
},
() -> {
log.debug("begin...");
Thread.sleep(2000);
return "3";
}
));
for (Future<Object> future : futures) {
log.debug((String) future.get());
}
}
}invokeAll()会阻塞当前线程,等待所有任务执行完成后返回结果:
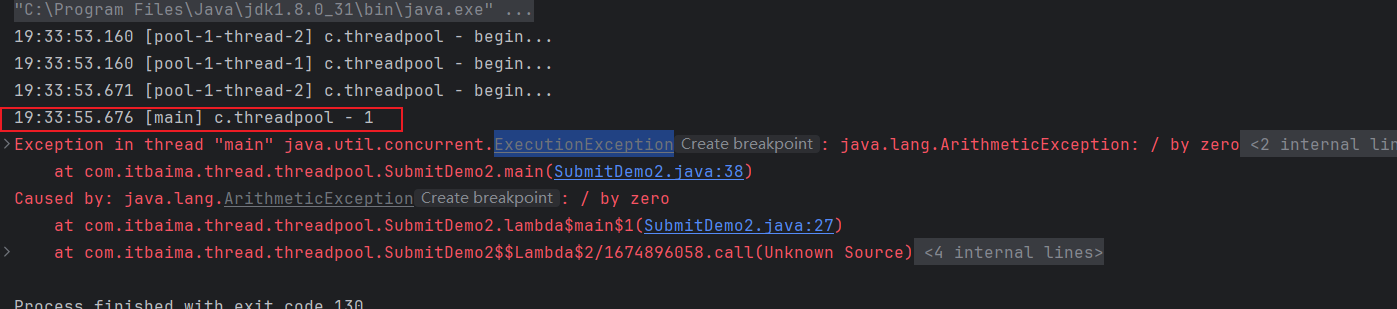
如果有某个任务抛出异常,invokeAll()会抛出ExecutionException并且不会返回后续任务的结果:
2.6.2、invokeAny
@Slf4j(topic = "c.SubmitDemo3")
public class SubmitDemo3 {
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
//提交task中所有任务,哪个任务先成功执行完毕,返回该任务的执行结果
try {
Object result = fixedThreadPool.invokeAny(Arrays.asList(
() -> {
log.debug("begin...");
Thread.sleep(1000);
return "1";
},
() -> {
log.debug("begin...");
Thread.sleep(500);
return "2";
},
() -> {
log.debug("begin...");
Thread.sleep(2000);
return "3";
}
));
log.debug(result.toString());
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
log.debug("main run...");
}
}同样会阻塞调用者线程,但是会返回最先完成任务的结果:

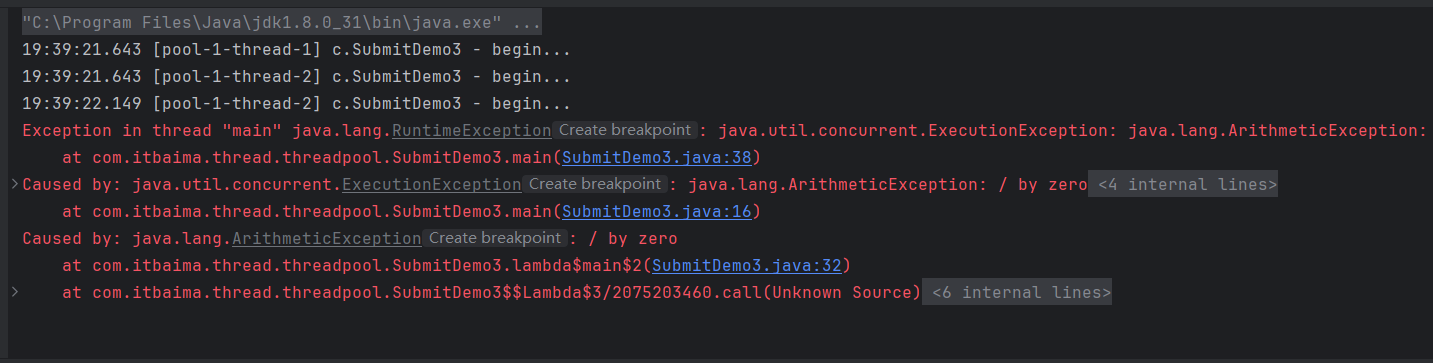
如果最先完成的任务抛出异常,则会返回第二个完成任务的结果。如果所有任务都发生异常,则会抛出ExecutionException。
2.7、shutdown&shutdownNow
shutdown:
@Slf4j(topic = "c.shutDownDemo1")
public class ShutDownDemo1 {
public static void main(String[] args) throws InterruptedException {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
Future<Object> future1 = fixedThreadPool.submit(() -> {
log.debug("task 1 running...");
Thread.sleep(1000);
log.debug("task 1 stop...");
return 1;
});
Future<Object> future2 = fixedThreadPool.submit(() -> {
log.debug("task 2 running...");
Thread.sleep(1000);
log.debug("task 2 stop...");
return 2;
});
Future<Object> future3 = fixedThreadPool.submit(() -> {
log.debug("task 3 running...");
Thread.sleep(1000);
log.debug("task 3 stop...");
return 3;
});
//不会接受新任务,但是已提交的任务会执行完,不会阻塞调用线程的执行
fixedThreadPool.shutdown();
Thread.sleep(3000);
log.debug("main thread pool shutdown");
}
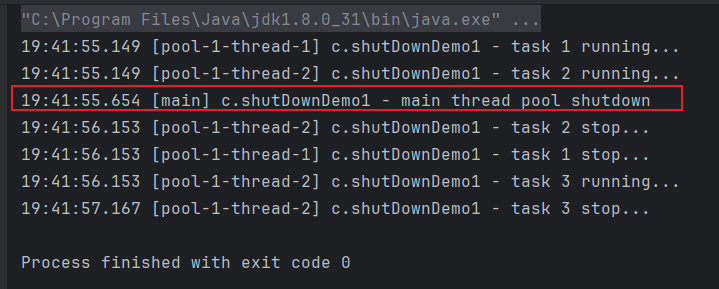
}已经提交任务的线程会执行完,不会接收调用shutdown后的新任务,同时主线程不会阻塞:
shutdownNow:
@Slf4j(topic = "c.ShutDownDemo2")
public class ShutDownDemo2 {
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
Future<Object> future1 = fixedThreadPool.submit(() -> {
log.debug("task 1 running...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
log.debug("error running task",e);
}
log.debug("task 1 stop...");
return 1;
});
Future<Object> future2 = fixedThreadPool.submit(() -> {
log.debug("task 2 running...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
log.debug("error running task",e);
}
log.debug("task 2 stop...");
return 2;
});
Future<Object> future3 = fixedThreadPool.submit(() -> {
log.debug("task 3 running...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
log.debug("error running task",e);
}
log.debug("task 3 stop...");
return 3;
});
//不会接受新任务,会将队列中的任务返回,并用interrupt的方式中断正在执行的任务
List<Runnable> runnables = fixedThreadPool.shutdownNow();
System.out.println(runnables);
}
} 不会接收新的任务,同时会将队列中的任务返回,并用interrupt的方式中断正在执行的任务: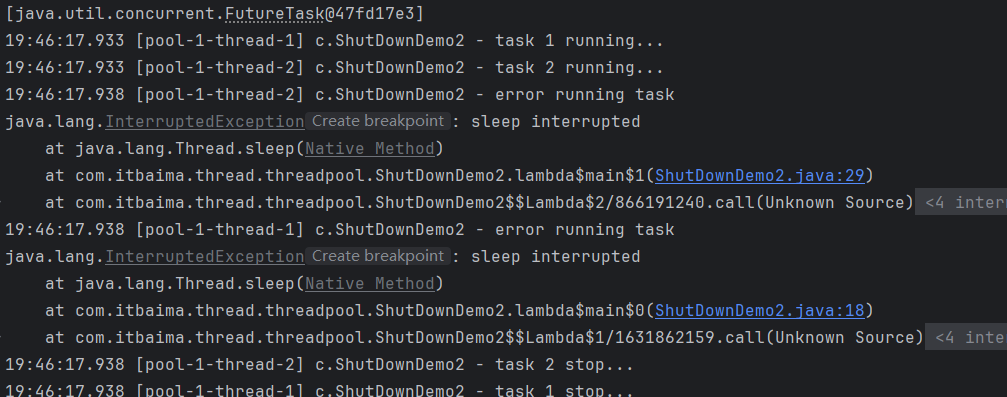
2.8、设计模式:工作模式
让有限的工作线程(Worker Thread)来轮流异步处理无限多的任务。也可以将其归类为分工模式,它的典型实现 就是线程池,也体现了经典设计模式中的享元模式。
固定大小线程池会有饥饿现象,例如下面的案例,模拟了餐馆的工作场景,固定大小的线程池中有2个线程,其中每个线程既可以接受客户点餐,也可以去做菜。
@Slf4j(topic = "c.StarvationDemo")
public class StarvationDemo1 {
static final List<String> MENU = Arrays.asList("毛豆烧土鸡","酱蒸豆腐","卤鸡腿","西红柿炒蛋");
static Random random = new Random();
static String cooking(){
return MENU.get(random.nextInt(MENU.size()));
}
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2);
//submit和execute的区别:submit可以获取结果,但是底层调用的依旧是execute
//一个线程点餐,另一个线程做菜
fixedThreadPool.execute(()->{
log.debug("开始点餐");
Future<Object> future = fixedThreadPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜:{}",future.get());
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
});
//一个线程点餐,另一个线程做菜
fixedThreadPool.execute(()->{
log.debug("开始点餐");
Future<Object> future = fixedThreadPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜:{}",future.get());
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
});
}
}此时如果两个线程同时去接收两个客户点餐,那就没有线程去做菜了,于是发生了饥饿现象。(并非死锁):
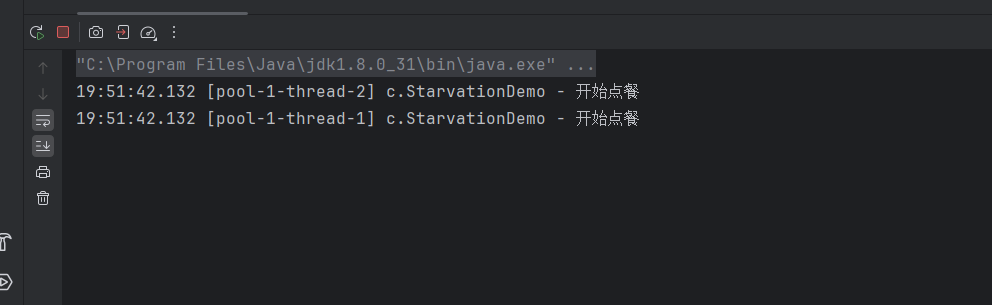
这个问题可以通过增加线程数量解决,但不是根本的解决方案。最好的方案是,将线程进行分工,同一类型的工作只交给一个线程去做。
改进后的案例,创建了两个线程池,waiterPool中的线程专门用来处理用户点餐,cookPool中的线程用于做菜。
@Slf4j(topic = "c.StarvationDemo")
public class StarvationDemo2 {
static final List<String> MENU = Arrays.asList("毛豆烧土鸡","酱蒸豆腐","卤鸡腿","西红柿炒蛋");
static Random random = new Random();
static String cooking(){
return MENU.get(random.nextInt(MENU.size()));
}
public static void main(String[] args) {
ExecutorService waiterPool = Executors.newFixedThreadPool(1,new ThreadFactory() {
AtomicInteger atomicInteger = new AtomicInteger(1);
/**
* Constructs a new {@code Thread}. Implementations may also initialize
* priority, name, daemon status, {@code ThreadGroup}, etc.
*
* @param r a runnable to be executed by new thread instance
* @return constructed thread, or {@code null} if the request to
* create a thread is rejected
*/
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"服务员"+atomicInteger.getAndIncrement());
}
});
ExecutorService cookPool = Executors.newFixedThreadPool(1,new ThreadFactory() {
/**
* Constructs a new {@code Thread}. Implementations may also initialize
* priority, name, daemon status, {@code ThreadGroup}, etc.
*
* @param r a runnable to be executed by new thread instance
* @return constructed thread, or {@code null} if the request to
* create a thread is rejected
*/
@Override
public Thread newThread(Runnable r) {
return new Thread(r,"厨师"+atomicInteger.getAndIncrement());
}
AtomicInteger atomicInteger = new AtomicInteger(1);
});
//submit和execute的区别:submit可以获取结果,但是底层调用的依旧是execute
//一个线程点餐,另一个线程做菜
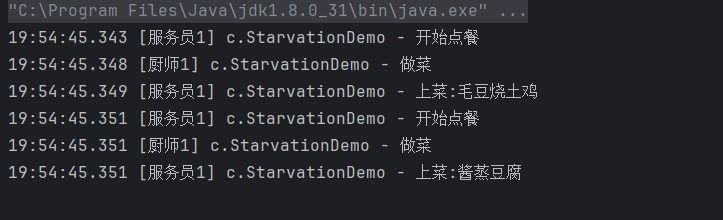
waiterPool.execute(()->{
log.debug("开始点餐");
Future<Object> future = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜:{}",future.get());
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
});
//一个线程点餐,另一个线程做菜
waiterPool.execute(()->{
log.debug("开始点餐");
Future<Object> future = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜:{}",future.get());
} catch (InterruptedException | ExecutionException e) {
throw new RuntimeException(e);
}
});
}
}
2.9、线程池大小最佳实践
线程池大小的设计,一般有以下的原则:
-
任务类型:不同类型的任务对线程池大小的需求不同。如果任务是计算密集型的,例如大量的数学计算或者数据处理,可以选择较大的线程池大小来充分利用多核处理器的计算能力。如果任务是IO密集型的,例如大量的网络请求或者文件读写操作,通常可以选择较小的线程池大小,因为任务在等待IO时线程是空闲的。
-
系统资源:线程池的大小也应该考虑系统的资源情况,包括CPU、内存等。如果线程池过大,会导致系统资源过度占用,可能会影响系统的稳定性和性能;如果线程池过小,可能会导致任务排队等待或者资源浪费。
-
任务队列大小:线程池的任务队列大小也会影响线程池的大小设置。如果任务队列大小较大,可以适当增加线程池的大小以提高任务并发性;如果任务队列大小较小,可以减少线程池的大小以避免任务堆积和资源浪费。
-
任务响应时间:线程池的大小也会影响任务的响应时间。如果任务需要快速响应,可以适当增加线程池的大小以提高任务处理的速度;如果任务响应时间对实时性要求不高,可以选择较小的线程池大小以节省系统资源。
经验公式:
- CPU密集型,线程池大小为CPU核心数+1,主要是为了防止CPU页缺失,增加容错。
- IO密集型,线程数 = 核数 * 期望 CPU 利用率 * 总时间(CPU计算时间+等待时间) / CPU 计算时间。
2.10、延时&定时执行任务
2.10.1、Timer的弊端
@Slf4j(topic = "c.TimerDemo1")
public class TimerDemo1 {
public static void main(String[] args) {
Timer timer = new Timer();
TimerTask t1 = new TimerTask(){
/**
* The action to be performed by this timer task.
*/
@Override
public void run() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
log.info("t1 run...");
}
};
TimerTask t2 = new TimerTask(){
/**
* The action to be performed by this timer task.
*/
@Override
public void run() {
log.info("t2 run...");
}
};
log.info("main run...");
timer.schedule(t1,1000);
timer.schedule(t2,1000);
}
}所有的任务都是串行执行,且前一个任务如果发生异常,会影响后续任务的执行。
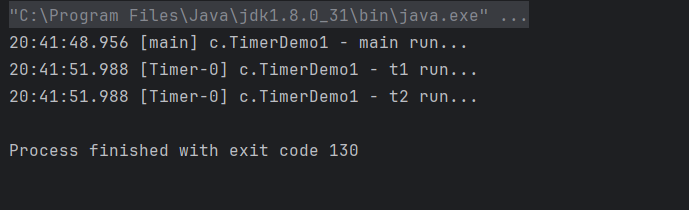
使用Executors.newScheduledThreadPool进行改造:
@Slf4j(topic = "c.TimerDemo2")
public class TimerDemo2 {
public static void main(String[] args) {
//带有任务调度功能的线程池
//最大线程数为Integer的最大值,没有应急线程
//多个线程运行时不会阻塞调度
// 不会被异常中断
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(1);
threadPool.schedule(()->{
log.info("t1 run ...");
// try {
// Thread.sleep(2000);
// } catch (InterruptedException e) {
// throw new RuntimeException(e);
// }
int i = 1/0;
},1, TimeUnit.SECONDS);
threadPool.schedule(()->{
log.info("t2 run ...");
},1, TimeUnit.SECONDS);
threadPool.shutdown();
}
}newScheduledThreadPool是带有任务调度功能的线程池,最大线程数为Integer的最大值,没有应急线程:
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}多个线程可以并行运行,而且某个任务出现异常时不会被中断:
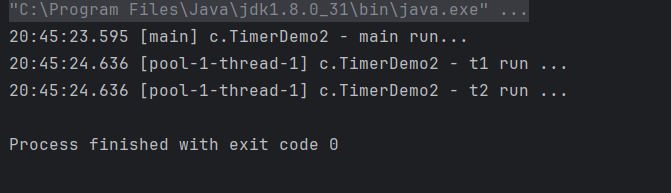
2.10.2、使用ScheduledExecutorService实现延时/定时任务
ScheduledExecutorService提供了scheduleAtFixedRate()和scheduleWithFixedDelay()方法:
@Slf4j(topic = "c.TimerDemo3")
public class TimerDemo3 {
public static void main(String[] args) {
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(1);
//以固定的频率执行
//参数一:任务对象 参数二:延迟n秒开始执行 参数三:两次执行的间隔 参数四:时间单位
//如果任务的执行时间大于两次执行的间隔,则执行间隔以任务最终完成时间为准
threadPool.scheduleAtFixedRate(()->{
log.info("scheduleAtFixedRate start");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},1,2, TimeUnit.SECONDS);
}
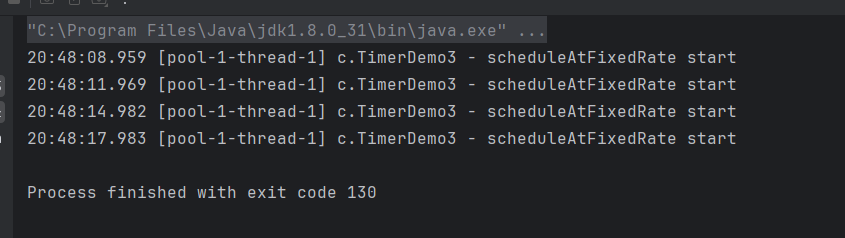
}任务的执行时间大于设定的两次执行的间隔,以任务实际执行时间作为两次执行的间隔:
@Slf4j(topic = "c.TimerDemo3")
public class TimerDemo3 {
public static void main(String[] args) {
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(1);
// 任务间隔时间 = 任务实际的结束时间 + 设置的间隔时间
threadPool.scheduleWithFixedDelay(()->{
log.info("scheduleAtFixedRate start");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
},1,1,TimeUnit.SECONDS);
}
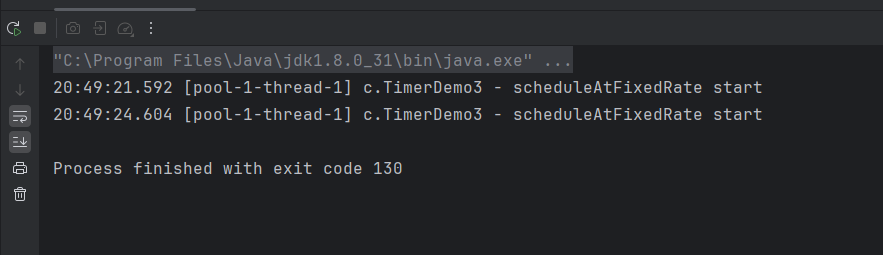
}任务的间隔时间 = 任务实际的结束时间 + 设置的间隔时间
2.11、正确处理线程池中的异常
方式一:try..catch处理
@Slf4j(topic = "c.ThreadPoolExceptionDemo")
public class ThreadPoolExceptionDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//正确处理线程池中的异常
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(1);
// 方式一:try..catch并处理
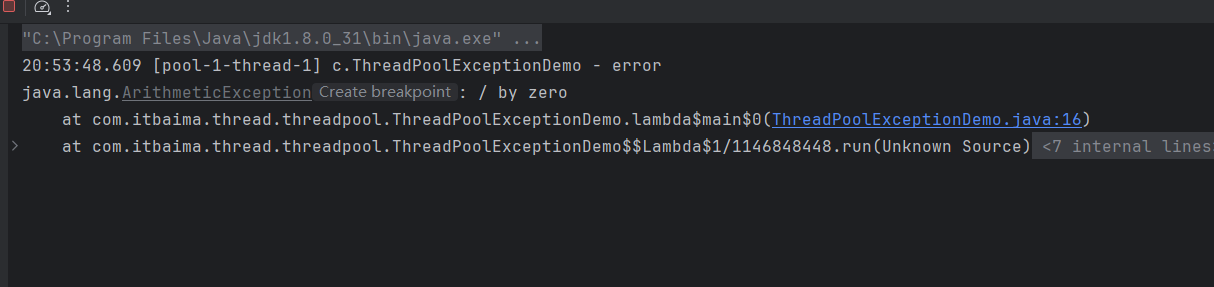
threadPool.schedule(()->{
try {
int i = 1/0;
} catch (Exception e) {
log.error("error", e);
}
},1, TimeUnit.SECONDS);
}
}
方式二:利用callable的future
@Slf4j(topic = "c.ThreadPoolExceptionDemo")
public class ThreadPoolExceptionDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//正确处理线程池中的异常
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(1);
//方式二:利用callable的future
ScheduledFuture<Boolean> future = threadPool.schedule(() -> {
int i = 1 / 0;
return true;
}, 1, TimeUnit.SECONDS);
log.info(String.valueOf(future.get()));
}
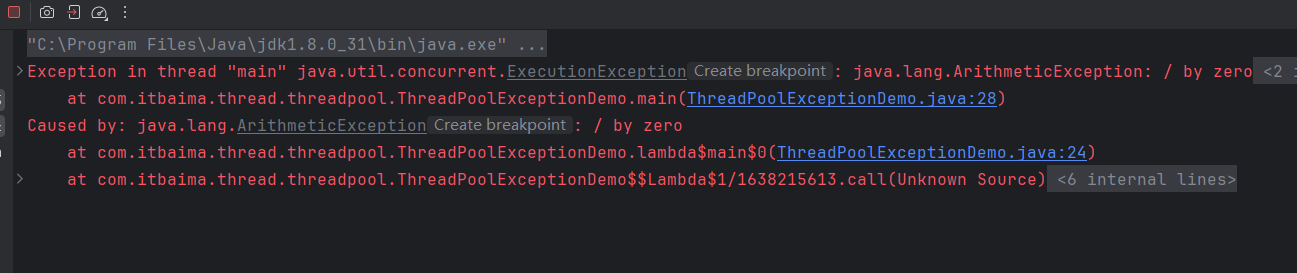
}如果业务代码没有出现异常就会返回true,否则返回错误信息:
2.12、fork&join
线程池的 Fork/Join 框架是 Java 并发包中用于并行处理任务的一种机制,主要用于解决分治算法中的大规模问题并行化执行的需求。Fork/Join 框架通过工作窃取(Work Stealing)算法来实现任务的自动分配和负载均衡,可以有效利用多核处理器的计算能力,提高任务的并发性和执行效率。
Fork/Join 框架的核心概念包括以下几个部分:
1.ForkJoinPool:
- 它代表一个工作线程池,负责管理和执行任务。默认大小等于CPU核心数。
- 工作线程采用工作窃取算法(Work Stealing Algorithm),当一个线程执行完自己的任务后,会尝试从其他线程的任务队列中窃取任务来执行,以保持线程的高效利用和负载均衡。
2.ForkJoinTask:
- 是 Fork/Join 框架中任务的抽象类,它有两个重要的子类:RecursiveTask和RecursiveAction
- RecursiveTask用于有返回值的任务,使用compute()方法返回计算结果。
- RecursiveAction用于没有返回值的任务,compute()方法不会返回结果。
3.任务分割和合并:
- Fork/Join 框架通过递归地将大任务分割成小任务,并且在计算过程中合并小任务的结果,以达到并行计算的目的。
- 当一个任务需要执行时,它会调用 Fork() 方法来提交子任务,然后调用join()方法来等待子任务的执行结果。
@Slf4j(topic = "c.ForkJoinDemo")
public class ForkJoinDemo {
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool(4);
System.out.println(forkJoinPool.invoke(new MyTask(5)));
}
}
@Slf4j(topic = "c.MyTask")
class MyTask extends RecursiveTask<Integer> {
private int num;
public MyTask(int num) {
this.num = num;
}
/**
* The main computation performed by this task.
*
* @return the result of the computation
*/
@Override
protected Integer compute() {
if (num == 1){
log.info(Thread.currentThread().getName() + ":join() {}",num);
return 1;
}
MyTask myTask = new MyTask(num - 1);
myTask.fork();//让一个线程去执行任务
log.info(Thread.currentThread().getName() + ":fork() {}",num);
//获取任务结果
int result = num + myTask.join();
log.info(Thread.currentThread().getName() + ":join() {}",num);
return result;
}
} 
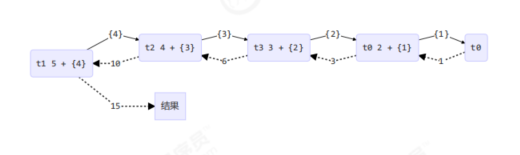
t1线程将任务分解成5-1=4,然后调用fork方法让其他线程去计算,并且调用join方法等待计算的结果,相当于多线程版的递归。
3、附录
3.1、tomcat线程池
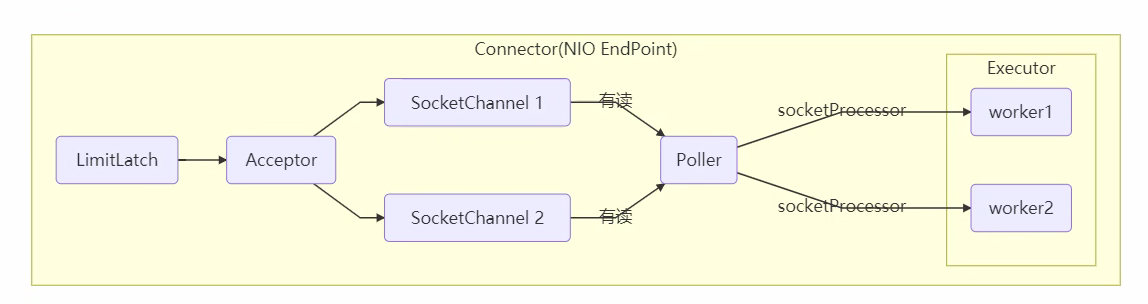
- LimitLatch负责限流,控制最大连接个数。
- Acceptor负责接收socket连接。
- Poller负责监听SocketChannel中是否有IO事件。
-
一旦可读,封装一个任务对象( socketProcessor ),提交给 Executor 线程池处理 。
-
Executor 线程池中的工作线程最终负责处理请求。
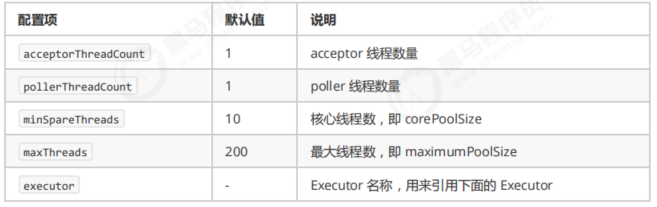
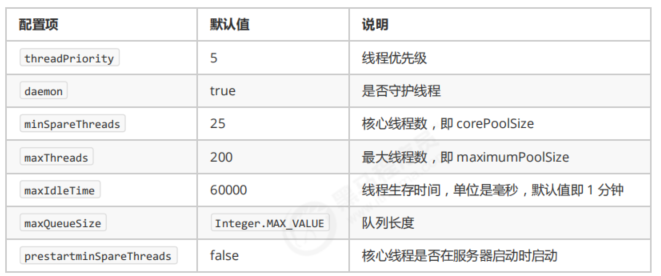
线程配置:
3.2、自定义实现JDK线程池
阻塞队列:
@Slf4j(topic = "c.BlockingQueue")
class BlockingQueue<T> {
/*
使用链表模拟
*/
private Deque<T> deque = new ArrayDeque<>();
/*
锁
*/
private ReentrantLock lock = new ReentrantLock();
/*
生产者休息室,用于阻塞队列已满时
*/
private Condition providerWait = lock.newCondition();
/*
消费者休息室,用于阻塞队列为空时
*/
private Condition consumerWait = lock.newCondition();
/*
容量
*/
private int capcity;
public BlockingQueue(int capcity) {
this.capcity = capcity;
}
/**
* 带超时的消费方法
* @param timeout 超时时间
* @param unit 时间单位
* @return 阻塞队列中获取的元素
*/
public T getObj(long timeout, TimeUnit unit) {
try {
lock.lock();
//将timeout转换成纳秒
long nanos = unit.toNanos(timeout);
while (deque.isEmpty()) {
try {
log.info("阻塞队列已空!");
if (nanos <= 0) {
log.error("已超时!");
return null;
}
nanos = consumerWait.awaitNanos(nanos);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
T obt = deque.removeFirst();
providerWait.signal();
return obt;
} finally {
lock.unlock();
}
}
/**
* 消费方法
* @return T 阻塞队列中获取的元素
*/
public T getObj() {
try {
lock.lock();
while (deque.isEmpty()) {
try {
log.info("阻塞队列已空!");
consumerWait.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
T obt = deque.removeFirst();
providerWait.signal();
return obt;
} finally {
lock.unlock();
}
}
/**
* 生产方法
* @param obj 向阻塞队列中添加的元素
*/
public void setObj(T obj) {
try {
lock.lock();
while (capcity <= deque.size()) {
log.info("阻塞队列已满!");
try {
providerWait.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
log.info("加入阻塞任务队列:{}",obj);
deque.addLast(obj);
consumerWait.signal();
} finally {
lock.unlock();
}
}
/**
* 带超时的生产方法
* @param obj 任务对象
* @param timeout 超时时间
* @param unit 时间单位
*/
public boolean setObj(T obj,long timeout, TimeUnit unit) {
try {
lock.lock();
long nanos = unit.toNanos(timeout);
while (capcity <= deque.size()) {
log.info("阻塞队列已满!");
if (nanos<=0){
return false;
}
nanos = providerWait.awaitNanos(timeout);
}
log.info("加入阻塞任务队列:{}",obj);
deque.addLast(obj);
consumerWait.signal();
return true;
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
public int getSize() {
try {
lock.lock();
return deque.size();
} finally {
lock.unlock();
}
}
public void trySet(RejectPolicy<T> rejectPolicy, T task) {
try {
lock.lock();
//阻塞队列已满
if (deque.size()==capcity){
//调用拒绝策略
rejectPolicy.reject(this,task);
}else {
log.info("加入阻塞任务队列:{}",task);
deque.addLast(task);
consumerWait.signal();
}
}finally {
lock.unlock();
}
}
}线程池对象,其中执行任务的逻辑:
没有超过核心线程数,直接交给工作线程处理。
超过核心线程数,触发拒绝策略(与JDK线程池不同的是,没有实现应急线程。)
当队列不为空时,工作线程会从队列中获取任务并执行,执行完成后删除对应任务。
@Slf4j(topic = "c.ThreadPool")
class ThreadPool {
/*
阻塞任务队列
*/
private BlockingQueue<Runnable> queue;
/*
工作线程集合
*/
private HashSet<Worker> workers = new HashSet<>();
/*
核心线程数
*/
private int corePoolSize;
/*
超时时间
*/
private long timeout;
/*
超时时间单位
*/
private TimeUnit unit;
/*
拒绝策略
*/
private RejectPolicy<Runnable> rejectPolicy;
public ThreadPool(int corePoolSize, long timeout, TimeUnit unit, int capcity,RejectPolicy<Runnable> rejectPolicy) {
this.corePoolSize = corePoolSize;
this.timeout = timeout;
this.unit = unit;
this.queue = new BlockingQueue<>(capcity);
this.rejectPolicy = rejectPolicy;
}
/**
* 执行任务
* @param task 将要执行的任务对象
*/
public void execute(Runnable task) {
synchronized (workers) {
//当任务数量没有超过coreSize时,直接交给worker处理
if (workers.size() < corePoolSize) {
//实例化worker内部类
Worker worker = new Worker(task);
log.info("创建worker任务:{},worker对象:{}",task,worker);
//加入线程集合
workers.add(worker);
//启动
worker.start();
} else {
//任务数量超过coreSize时,的拒绝策略
// queue.setObj(task,1,TimeUnit.SECONDS);
queue.trySet(rejectPolicy,task);
}
}
}
/**
* worker内部类
*/
class Worker extends Thread {
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
/**
* 执行任务
*/
@Override
public void run() {
//当task不为空,执行任务
//task执行完毕,从任务队列再次获取并执行
while (task != null || (task = queue.getObj(timeout,unit)) != null) {
//为了处理执行任务中的异常
try {
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
log.info("{}:执行完成",task);
//执行完成
task = null;
}
}
synchronized (workers) {
log.info("任务对象移除:{}",this);
workers.remove(this);
}
}
}
}拒绝策略,设置成函数式接口,方便编写不同的逻辑:
@FunctionalInterface
interface RejectPolicy<T>{
void reject(BlockingQueue<T> blockingQueue,T task);
}测试类:
@Slf4j(topic = "c.MyThreadPool")
public class MyThreadPool {
public static void main(String[] args) {
ThreadPool threadPool = new ThreadPool(2, 1, TimeUnit.SECONDS, 10,
(queue,task)->{
//1.死等
// queue.setObj(task);
//2.带时间等待
//3.放弃执行
//4.抛出异常
//5.主线程执行
});
for (int i = 0; i < 5; i++) {
threadPool.execute(() -> {
log.info(Thread.currentThread().getName()+"开始运行");
});
}
}
}