本文首发于公众号:Hunter后端
原文链接:MySQL面试必备一之索引
在面试过程中,会有一些关于 MySQL 索引相关的问题,以下总结了一些:
- MySQL 的数据存储使用的是什么索引结构
- B+ 树的结构是什么样子
- 什么是复合索引、聚簇索引、覆盖索引
- 什么是最左匹配原则
- 数据 B+ 树中是如何查询的
- 回表是什么操作
- B+ 树的查询有什么优势
- 索引下推是什么意思
对于上面这几个问题,看完这篇笔记你应该就会明白这些问题应该如何作答。
这篇笔记将从以下几个方面开始介绍:
- B+树
- 查询数据的过程
- 覆盖索引
- 联合索引
- MyISAM 的存储结构
- InnoDB 与 MyISAM 的区别
- B 树与 B+ 树
1、B+树
MySQL 的存储引擎包括 InnoDB、MyISAM、Memory 等,其中 InnoDB 是默认的表存储引擎,InnoDB 和 MyISAM 的数据都存储在 B+ 树这种结构中。
首先来了解下 B+ 树的结构。
1. B+ 树结构
与二叉树一样,B+ 树也是一种树结构,与之不同的点在于每一层并非只有左右两个子结点,而是可以有多个结点,而在 InnoDB 中,数据都是存储在叶子结点上,现在假设我们有一张 user 表,以 id 为主键,有 name、age 这两个字段,那么数据的存储示意图则如下:
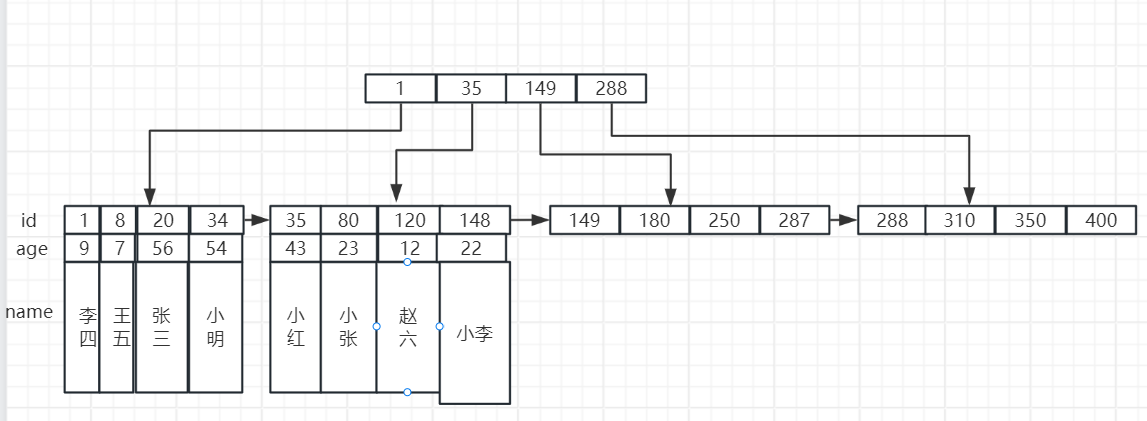
在上图中,只展示了 B+ 树的两层,每一层有四个子结点,所有的数据都存储在叶子结点上。
在 InnoDB 中,B+ 树的高度通常为 2 到 4 层,假设每一层我们有 1000 个结点,那么如果树有 4 层,那么在第四层的叶子结点我们可以存储 1000 的三次方条数据,那么就可以存储 10 亿条数据。
2. 主键索引与聚簇索引
当我们创建一张表,并往里面添加数据,数据存储的格式就是上面这张图的形式,默认以主键作为索引,也就是 B+ 树的非叶子结点,所以又称其为主键索引。
对于这张表,除了 id 字段,还有 age 和 name 字段,这几个表字段是一起存放在叶子结点的,因此这种存储方式也称为聚簇索引。
3. 非聚簇索引与二级索引
在 InnoDB 中,除了主键索引外,我们还可以为表的某个或者某些字段创建索引,对于这些索引,我们称其为非聚簇索引或者二级索引。
二级索引的存储结构也是 B+ 树,不一样的点在于非叶子结点的值是创建了索引的字段值,叶子结点就不再是这条表数据了,而是这个索引字段所在的数据的主键值。
还是以前面的 user 表为例,我们在 name 字段上创建索引,那么 InnoDB 会额外创建一个 B+ 树,B+ 树的结构大致如下:
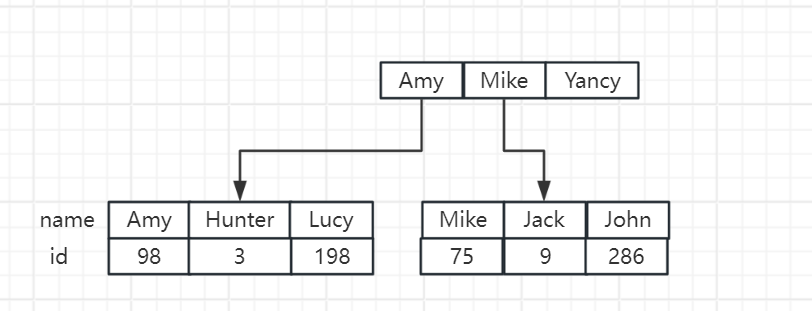
这里为了更直白的表示字段值的排序,用了英文名字来表示,如上就是一个二级索引的存储形式。
2、查询数据的过程
1. 根据主键查询
比如我们要查询 id = 80 的数据,sql 语句如下:
select id, name, age from user where id = 80;
这里是针对 id 字段进行查询,所以可以直接查询主键索引,根据上面主键索引的示意图,其查询步骤如下:
- 根据 id = 18 逐层找到 B+ 树的对应非叶子结点,比如这里就到了图里的最上层结点
- 根据 id = 18,判断 1 <18 < 35,所以查询进入的叶子结点将会进入最左侧往下
- 在最左侧的叶子结点,找到 id = 18 的叶子结点,然后这个节点对应的 id,name,age 字段获取然后返回
以上就是一次根据主键进行查询的过程
2. 根据二级索引查询
还是 user 表,在 name 字段上建立了一个二级索引,我们想要找到 name = “Hunter” 的 id,name,age 字段:
select id, name, age from user where name = "Hunter";
其查询过程如下:
- 根据 name=“Hunter” 查询二级索引的 B+ 树,也就是我们的第二张图,根据非叶子结点的值找到最左侧的数据
- 根据 “Hunter” 可以找到这条数据的主键 id = 3
- 根据 id = 3 去主键索引的 B+ 树里查询对应的字段(这里的查询操作就是根据主键查询数据了)
回表:上面的查询过程中,根据二级索引获取到的主键 id,到主键索引里查询对应的数据,这个过程就称为回表。
3、覆盖索引
对上面二级索引查询的过程,我们有一个回表的操作,即根据二级索引获取到的主键 id 再去主键索引获取相应的字段数据,这部分的查询过程是会影响查询效率的。
那么针对这种回表的情况,我们可以在某些情况下使用覆盖索引来对其进行优化。
所谓覆盖索引,并非某种实际的索引结构,而应该算得上是一种思想或者优化手段。其主要思想为在二级索引中就可以拿到查询所需的全部字段,而不需要进行回表操作。
针对前面我们对 name 加了索引的情况,如果我们的 SQL 语句如下,那么即可使用覆盖索引,而不需要再到主键索引里回表查询:
select id, name from user where name = "Hunter";
在上面这个语句中,我们查询的是 id 和 name 两个字段,这两个字段在 name 字段的二级索引的查询中即可获取所需的字段值,那么则不需要进行回表操作,这个过程就相当于使用了覆盖索引。
而如果我们所需要的字段并不只是这两个字段,比如我们还要查询 age 字段,针对这种情况,如果要用覆盖索引的话,就需要引入下一节的内容,联合索引,或者叫复合索引。
4、联合索引
复合索引,或者叫联合索引,指的是针对多个字段创建的索引,常常适用于多个字段进行查询的场景。
1. 联合索引的结构
联合索引也是二级索引,不过它的非叶子结点的值是多个字段组合的。
还是以 user 表为例,我们在 age 和 name 上创建一个联合索引:
CREATE INDEX age_name_idx ON user (age, name);
那么,在 MySQL 中,这个二级索引的存储结构大致如下:
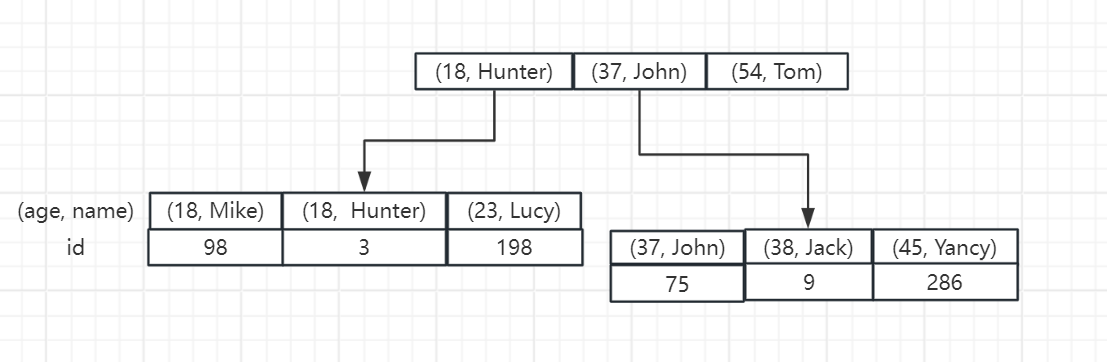
根据上面的这个结构,我们可以知道,字段的顺序是十分重要的,如果我们 SQL 语句的使用不当可能就会用不上联合索引。
2. 联合索引生效的情况
根据上图可以看到非叶子结点的值由两部分组成,分别是 age 和 name 的值,那么我们在进行查询的时候,也应该遵循这个顺序才可能使得索引生效。
1) 单个字段查询
如果我们要查询单个字段,比如 age,那么下面的条件都可以使得索引生效:
where age = 23;
where age > 25;
但是如果 where 后面的条件是针对 name 字段,那么下面的条件则不会使得这个联合索引生效:
where name = "Hunter";
2) 多个字段查询
如果是多个字段查询,那么则使用的时候一定要注意查询的顺序,下面的条件的是可以生效的:
where age = 23 and name = "Hunter";
where age = 24 and name like "Hun*";
而如果是 age 是一个范围查找,则不管 name 字段是什么条件,这个索引也可以生效,但仅仅是 age 字段会用到索引,name 字段的则不会用到索引,比如:
where age > 34 and name = "Hunter";
上面这个 SQL 语句,索引则只会对 age 字段生效进行范围查找,name 字段不用用到索引的精确匹配。
3) 最左匹配原则
基于联合索引的结构,如上图,最左匹配原则的概念其实就显而易见了,即联合索引只会从建立了索引的最左字段开始匹配,直到遇到范围查询则停止,就比如上面提到的这条:
where age > 34 and name = "Hunter";
它匹配到 age 就停止了,因为 age 是一个范围查询。
再来一种情况,如果我们的联合索引字段有三个,按照顺序为 age, name 和 field_3,下面的语句则会分别匹配到 age、name 和 field_3:
where age > 4 and name = "Hunter" and field_3 = 45;
where age = 34 and name like "Hun*" and field_3 = 45;
where age = 34 and name = "Hunter" and field_3 > 45;
下面这几种针对后面几个字段的查询联合索引都是不生效的:
where name = "Hunter" and field_3 = 45;
where field_3 = 45;
因为他们都没有从联合索引的最左字段字段开始查询。
3. 索引下推
索引下推是 MySQL 5.6 版本及以上引入的一个特性,主要用于减少回表的次数,从而实现提高查询性能的效果。
还是以前面 age 和 name 这个复合索引为例,SQL 如下:
where age > 30 and name like "Hun*";
如果没有索引下推,那么它的查询流程是根据 age > 30 这个条件,查询主键 id,逐个回表去主键索引里查询 name 字段的值是否满足 “Hun*” 这个条件。
而如果有索引下推这个优化,那么在二级索引里,查找出 age > 30 的值后,会直接根据复合索引中 name 的值来判断是否满足 “Hun*” 这个特性,满足的话就去回表查询,不满足则在当前复合索引里直接将这条数据过滤掉。
所谓的索引下推就是通过这个流程来减少回表的次数,以提高查询的性能。
5、MyISAM 的存储结构
MyISAM 的数据存储结构也是 B+ 树,但有一点不同,那就是 InnoDB 的叶子结点存储的是完整的一条数据,而 MyISAM 的叶子结点存储的数据的指针,通过指针指向底层存储的数据,其大概示意图如下:

同理,MyISAM 的二级索引的叶子结点也是直接指向存储的数据。
因此,MyISAM 在底层存储的表文件有三个,一个是 frm,是表的定义文件,一个 MYD,用于存储数据的文件,一个是 MYI,用于存储索引的文件。
相对来说,InnoDB 就只有两个,一个是 frm,一个是 IBD,用于存储索引和数据,因为 InnoDB 的叶子结点即存储了数据。
6、InnoDB 与 MyISAM 的区别
这里总结一下 InnoDB 与 MyISAM 的区别:
- InnoDB 是聚簇索引,MyISAM 是非聚簇索引
- 即 InnoDB 的主键索引是数据和索引放在一起的,而 MyISAM 是索引和数据分离的
- InnoDB 支持外键,MyISAM 不支持外键
- InnoDB 支持事务,MyISAM 不支持事务
- InnoDB 默认支持到行级锁,而 MyISAM 支持表级锁
7、B 树与 B+ 树
B 树和 B+ 树是很相似的树结构,都是每个结点都有多个子结点,不一样的在于 B 树的非叶子结点也存有数据,而 B+ 树只有叶子结点才有数据,非叶子结点都是索引数据,且 B+ 树的叶子结点之间也形成有序链表。
针对以上这个不同点,在 MySQL 中使用 B+ 树有如下优点:
- B+ 树在非叶子结点不包含数据,因此在内存页可以存放更多 key,从而在查询的时候可以减少 IO 次数
- B+ 树的叶子结点之间形成链表,遍历操作会更方便,而 B 树需要从根节点从上往下遍历
- B+ 树的数据都存放在叶子结点,而 B 树的非叶子结点也都有数据,所以查询的过程中 B+ 树总是需要访问到叶子结点,所以 B+ 树的查询效率会更稳定