书生·浦语大模型实战营

为了帮助社区用户高效掌握和广泛应用大模型技术,我们重磅推出书生·浦语大模型实战营系列活动,旨在为开发者们提供全面而系统的大模型技术学习课程。加入我们,一起深入大模型全流程,从零搭建 RAG、多模态和智能体应用。
😊 你将获得
👨🏫 实力讲师:来自前沿科研机构、一线大厂和 Github 热门开源项目的讲师手把手教学
💻 算力支持:算力资源免费提供,助力无忧训练大模型
💬 专属社群:助教、讲师全程陪伴,提供录播回放、线上答疑及实战作业辅导
📜 官方认证:优秀学员将获得荣誉证书,优秀项目有机会被官方收录,获得更多展示
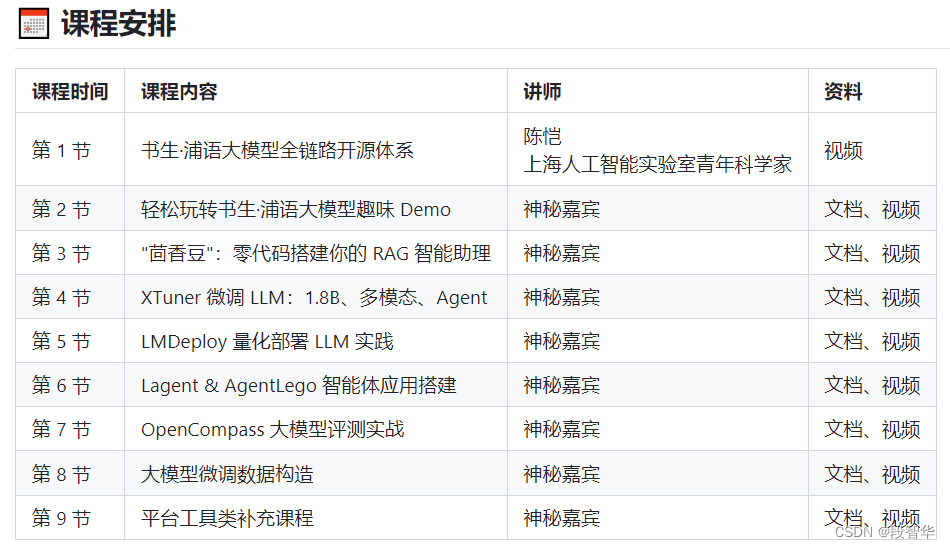
第二节课来啦!由书生·浦语角色扮演小组长【那路】为大家带来【轻松玩转书生·浦语大模型趣味 Demo】课程!玩转书生·浦语【智能对话】、【智能体解应用题】、【多模态理解及图文创作】等趣味 Demo!
趣味 Demo 任务列表
本节课可以让同学们实践 4 个主要内容,分别是:
- 部署 InternLM2-Chat-1.8B 模型进行智能对话
- 部署实战营优秀作品 八戒-Chat-1.8B 模型
- 通过 InternLM2-Chat-7B 运行 Lagent 智能体 Demo
- 实践部署 浦语·灵笔2 模型
课程文档:https://github.com/InternLM/Tutorial/blob/camp2/helloworld/hello_world.md
课程视频:https://www.bilibili.com/video/BV1AH4y1H78d/
【为课程加油】觉得不错欢迎 Star!给课程制作者和助教们一点小小的鼓励!
部署 InternLM2-Chat-1.8B 模型进行智能对话
配置基础环境:打开 Intern Studio 界面,点击 创建开发机 配置开发机系统。填写 开发机名称 后,点击 选择镜像 使用 Cuda11.7-conda 镜像,然后在资源配置中,使用 10% A100 * 1 的选项,然后立即创建开发机器。
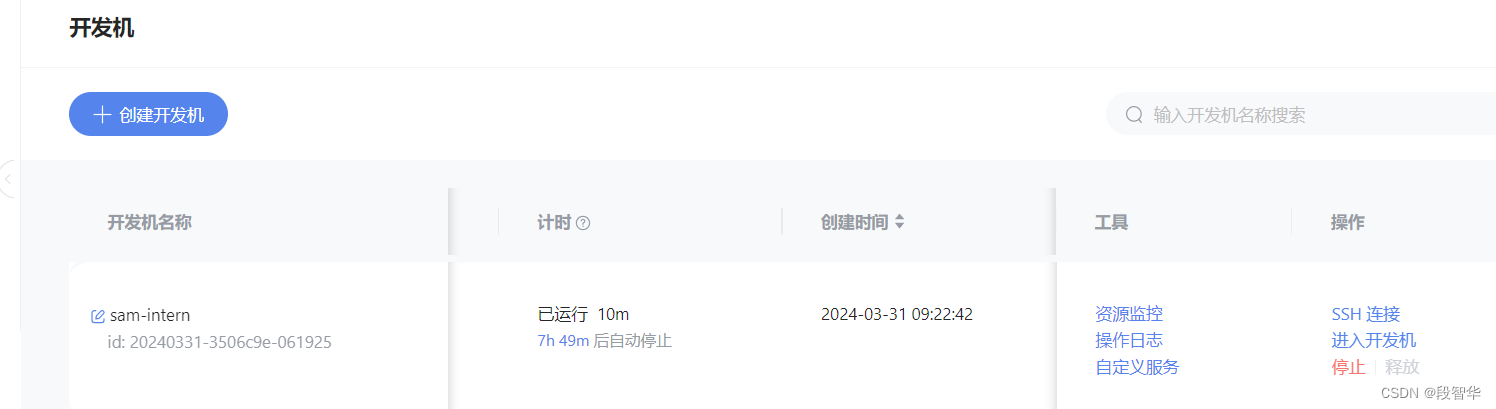
进入开发机后,在 terminal 中输入环境配置命令
studio-conda -o internlm-base -t demo
配置完成后,进入到新创建的 conda 环境之中:
conda activate demo
输入以下命令,完成环境包的安装:
pip install huggingface-hub==0.17.3
pip install transformers==4.34
pip install psutil==5.9.8
pip install accelerate==0.24.1
pip install streamlit==1.32.2
pip install matplotlib==3.8.3
pip install modelscope==1.9.5
pip install sentencepiece==0.1.99
下载 InternLM2-Chat-1.8B 模型
按路径创建文件夹,并进入到对应文件目录中
mkdir -p /root/demo
touch /root/demo/cli_demo.py
touch /root/demo/download_mini.py
cd /root/demo

双击打开 /root/demo/download_mini.py 文件,输入以下代码:
import os
from modelscope.hub.snapshot_download import snapshot_download
# 创建保存模型目录
os.system("mkdir /root/models")
# save_dir是模型保存到本地的目录
save_dir="/root/models"
snapshot_download("Shanghai_AI_Laboratory/internlm2-chat-1_8b",
cache_dir=save_dir,
revision='v1.1.0')
执行命令,下载模型参数文件:
python /root/demo/download_mini.py
双击打开 /root/demo/cli_demo.py 文件,输入以下代码:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name_or_path = "/root/models/Shanghai_AI_Laboratory/internlm2-chat-1_8b"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True, device_map='cuda:0')
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='cuda:0')
model = model.eval()
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
messages = [(system_prompt, '')]
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
while True:
input_text = input("\nUser >>> ")
input_text = input_text.replace(' ', '')
if input_text == "exit":
break
length = 0
for response, _ in model.stream_chat(tokenizer, input_text, messages):
if response is not None:
print(response[length:], flush=True, end="")
length = len(response)
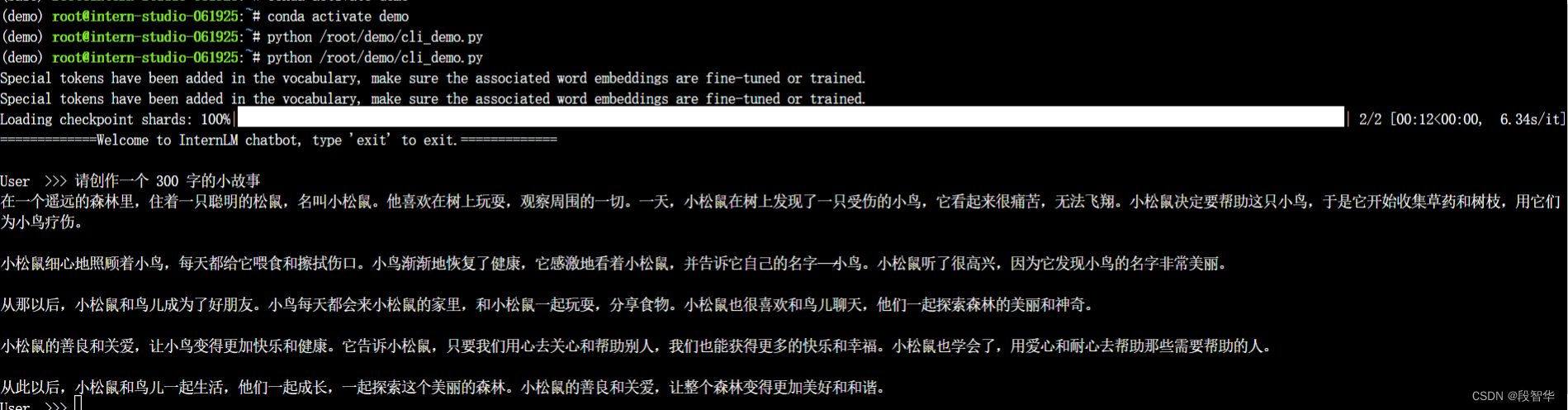
输入命令,执行 程序:
conda activate demo
python /root/demo/cli_demo.py
模型加载完成,键入内容示例
请创作一个 300 字的小故事
实战:部署实战营优秀作品 八戒-Chat-1.8B 模型
八戒-Chat-1.8B、Chat-嬛嬛-1.8B、Mini-Horo-巧耳(实战营优秀作品)
八戒-Chat-1.8B、Chat-嬛嬛-1.8B、Mini-Horo-巧耳 均是在第一期实战营中运用 InternLM2-Chat-1.8B 模型进行微调训练的优秀成果。其中,八戒-Chat-1.8B 是利用《西游记》剧本中所有关于猪八戒的台词和语句以及 LLM API 生成的相关数据结果,进行全量微调得到的猪八戒聊天模型。
- 八戒-Chat-1.8B:https://www.modelscope.cn/models/JimmyMa99/BaJie-Chat-mini/summary
- Chat-嬛嬛-1.8B:https://openxlab.org.cn/models/detail/BYCJS/huanhuan-chat-internlm2-1_8b
- Mini-Horo-巧耳:https://openxlab.org.cn/models/detail/SaaRaaS/Horowag_Mini
配置基础环境
运行环境命令
conda activate demo
使用 git 命令来获得仓库内的 Demo 文件
cd /root/
git clone https://gitee.com/InternLM/Tutorial -b camp2
# git clone https://github.com/InternLM/Tutorial -b camp2
cd /root/Tutorial
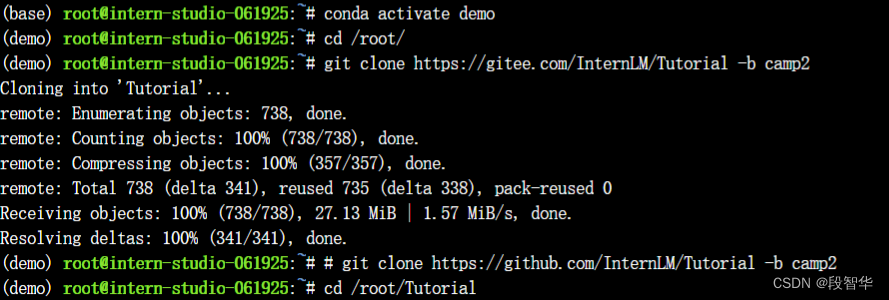
下载运行 Chat-八戒 Demo
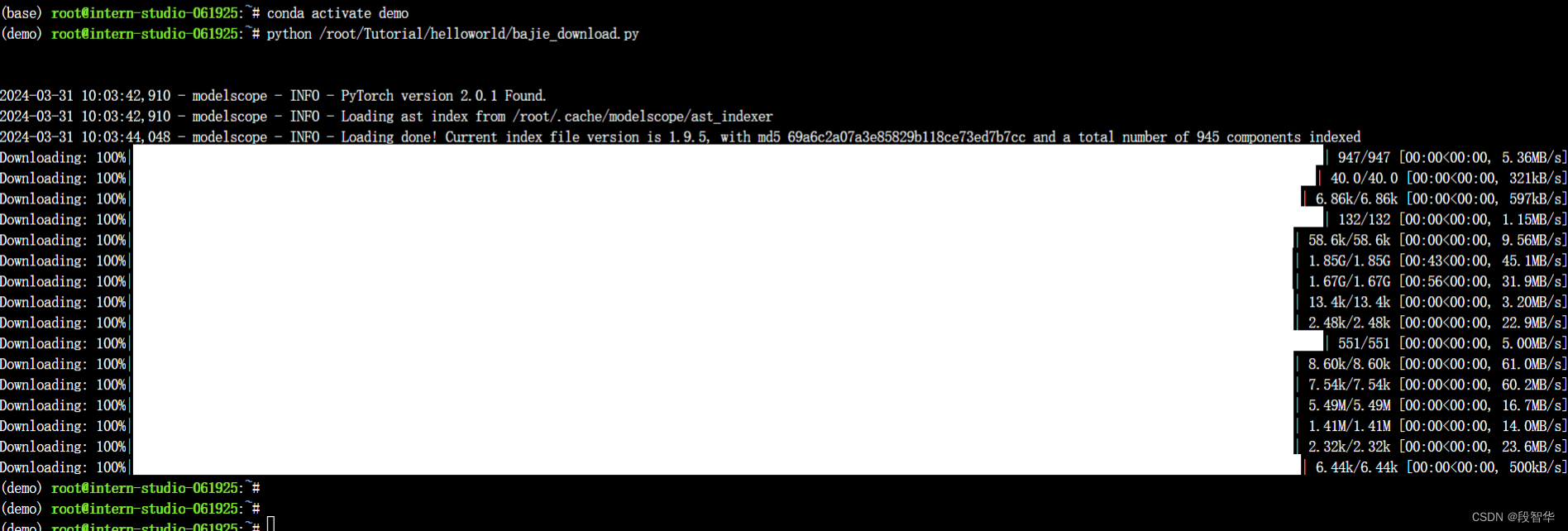
python /root/Tutorial/helloworld/bajie_download.py
bajie_download.py代码如下:
import os
#模型下载
from modelscope.hub.snapshot_download import snapshot_download
# 创建保存模型目录
os.system("mkdir -p /root/models")
# save_dir是模型保存到本地的目录
save_dir="/root/models"
snapshot_download('JimmyMa99/BaJie-Chat-mini',
cache_dir=save_dir)
输入运行命令
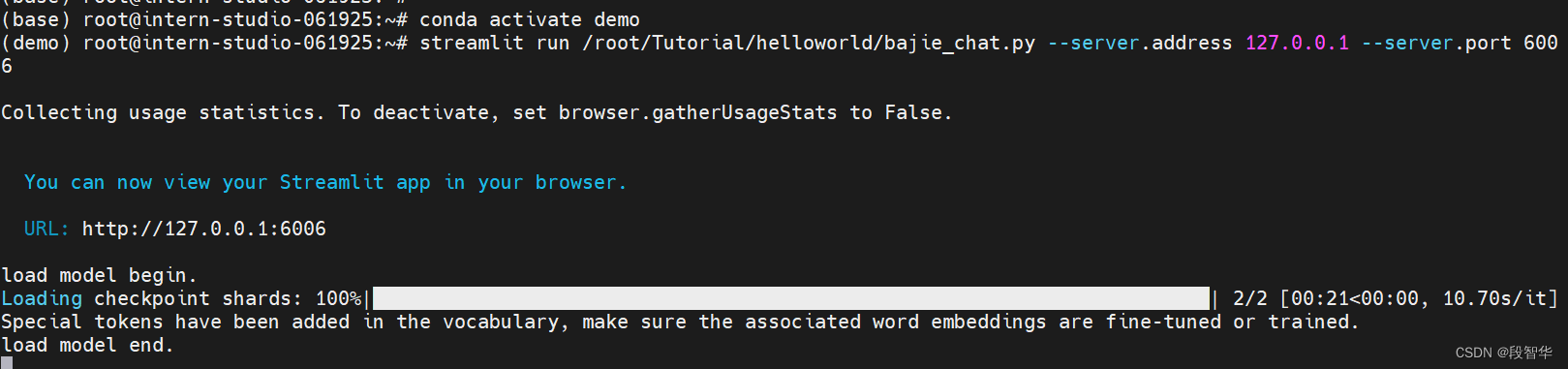
streamlit run /root/Tutorial/helloworld/bajie_chat.py --server.address 127.0.0.1 --server.port 6006
bajie_chat.py的代码:
# isort: skip_file
import copy
import warnings
from dataclasses import asdict, dataclass
from typing import Callable, List, Optional
import streamlit as st
import torch
from torch import nn
from transformers.generation.utils import (LogitsProcessorList,
StoppingCriteriaList)
from transformers.utils import logging
from transformers import AutoTokenizer, AutoModelForCausalLM # isort: skip
logger = logging.get_logger(__name__)
@dataclass
class GenerationConfig:
# this config is used for chat to provide more diversity
max_length: int = 32768
top_p: float = 0.8
temperature: float = 0.8
do_sample: bool = True
repetition_penalty: float = 1.005
@torch.inference_mode()
def generate_interactive(
model,
tokenizer,
prompt,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor],
List[int]]] = None,
additional_eos_token_id: Optional[int] = None,
**kwargs,
):
inputs = tokenizer([prompt], padding=True, return_tensors='pt')
input_length = len(inputs['input_ids'][0])
for k, v in inputs.items():
inputs[k] = v.cuda()
input_ids = inputs['input_ids']
_, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
if generation_config is None:
generation_config = model.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs)
bos_token_id, eos_token_id = ( # noqa: F841 # pylint: disable=W0612
generation_config.bos_token_id,
generation_config.eos_token_id,
)
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
if additional_eos_token_id is not None:
eos_token_id.append(additional_eos_token_id)
has_default_max_length = kwargs.get(
'max_length') is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None:
warnings.warn(
f"Using 'max_length''s default ({repr(generation_config.max_length)}) \
to control the generation length. "
'This behaviour is deprecated and will be removed from the \
config in v5 of Transformers -- we'
' recommend using `max_new_tokens` to control the maximum \
length of the generation.',
UserWarning,
)
elif generation_config.max_new_tokens is not None:
generation_config.max_length = generation_config.max_new_tokens + \
input_ids_seq_length
if not has_default_max_length:
logger.warn( # pylint: disable=W4902
f"Both 'max_new_tokens' (={generation_config.max_new_tokens}) "
f"and 'max_length'(={generation_config.max_length}) seem to "
"have been set. 'max_new_tokens' will take precedence. "
'Please refer to the documentation for more information. '
'(https://huggingface.co/docs/transformers/main/'
'en/main_classes/text_generation)',
UserWarning,
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = 'input_ids'
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, "
f"but 'max_length' is set to {generation_config.max_length}. "
'This can lead to unexpected behavior. You should consider'
" increasing 'max_new_tokens'.")
# 2. Set generation parameters if not already defined
logits_processor = logits_processor if logits_processor is not None \
else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None \
else StoppingCriteriaList()
logits_processor = model._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
encoder_input_ids=input_ids,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
)
stopping_criteria = model._get_stopping_criteria(
generation_config=generation_config,
stopping_criteria=stopping_criteria)
logits_warper = model._get_logits_warper(generation_config)
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
scores = None
while True:
model_inputs = model.prepare_inputs_for_generation(
input_ids, **model_kwargs)
# forward pass to get next token
outputs = model(
**model_inputs,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
if generation_config.do_sample:
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(probs, dim=-1)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = model._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=False)
unfinished_sequences = unfinished_sequences.mul(
(min(next_tokens != i for i in eos_token_id)).long())
output_token_ids = input_ids[0].cpu().tolist()
output_token_ids = output_token_ids[input_length:]
for each_eos_token_id in eos_token_id:
if output_token_ids[-1] == each_eos_token_id:
output_token_ids = output_token_ids[:-1]
response = tokenizer.decode(output_token_ids)
yield response
# stop when each sentence is finished
# or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(
input_ids, scores):
break
def on_btn_click():
del st.session_state.messages
@st.cache_resource
def load_model():
model = (AutoModelForCausalLM.from_pretrained('/root/models/JimmyMa99/BaJie-Chat-mini',
trust_remote_code=True).to(
torch.bfloat16).cuda())
tokenizer = AutoTokenizer.from_pretrained('/root/models/JimmyMa99/BaJie-Chat-mini',
trust_remote_code=True)
return model, tokenizer
def prepare_generation_config():
with st.sidebar:
max_length = st.slider('Max Length',
min_value=8,
max_value=32768,
value=32768)
top_p = st.slider('Top P', 0.0, 1.0, 0.8, step=0.01)
temperature = st.slider('Temperature', 0.0, 1.0, 0.7, step=0.01)
st.button('Clear Chat History', on_click=on_btn_click)
generation_config = GenerationConfig(max_length=max_length,
top_p=top_p,
temperature=temperature)
return generation_config
user_prompt = '<|im_start|>user\n{user}<|im_end|>\n'
robot_prompt = '<|im_start|>assistant\n{robot}<|im_end|>\n'
cur_query_prompt = '<|im_start|>user\n{user}<|im_end|>\n\
<|im_start|>assistant\n'
def combine_history(prompt):
messages = st.session_state.messages
meta_instruction = ('你是猪八戒,猪八戒说话幽默风趣,说话方式通常表现为直率、幽默,有时带有一点自嘲和调侃。'
'你的话语中常常透露出对食物的喜爱和对安逸生活的向往,同时也显示出他机智和有时的懒惰特点。'
'尽量保持回答的自然回答,当然你也可以适当穿插一些文言文,另外,书生·浦语是你的好朋友,是你的AI助手。')
total_prompt = f"<s><|im_start|>system\n{meta_instruction}<|im_end|>\n"
for message in messages:
cur_content = message['content']
if message['role'] == 'user':
cur_prompt = user_prompt.format(user=cur_content)
elif message['role'] == 'robot':
cur_prompt = robot_prompt.format(robot=cur_content)
else:
raise RuntimeError
total_prompt += cur_prompt
total_prompt = total_prompt + cur_query_prompt.format(user=prompt)
return total_prompt
def main():
# torch.cuda.empty_cache()
print('load model begin.')
model, tokenizer = load_model()
print('load model end.')
st.title('猪猪Chat-InternLM2')
generation_config = prepare_generation_config()
# Initialize chat history
if 'messages' not in st.session_state:
st.session_state.messages = []
# Display chat messages from history on app rerun
for message in st.session_state.messages:
with st.chat_message(message['role']):
st.markdown(message['content'])
# Accept user input
if prompt := st.chat_input('What is up?'):
# Display user message in chat message container
with st.chat_message('user'):
st.markdown(prompt)
real_prompt = combine_history(prompt)
# Add user message to chat history
st.session_state.messages.append({
'role': 'user',
'content': prompt,
})
with st.chat_message('robot'):
message_placeholder = st.empty()
for cur_response in generate_interactive(
model=model,
tokenizer=tokenizer,
prompt=real_prompt,
additional_eos_token_id=92542,
**asdict(generation_config),
):
# Display robot response in chat message container
message_placeholder.markdown(cur_response + '▌')
message_placeholder.markdown(cur_response)
# Add robot response to chat history
st.session_state.messages.append({
'role': 'robot',
'content': cur_response, # pylint: disable=undefined-loop-variable
})
torch.cuda.empty_cache()
if __name__ == '__main__':
main()
使用快捷键组合 Windows + R(Windows 即开始菜单键)打开指令界面,并输入命令,按下回车键
使用快捷键组合 Windows + R(Windows 即开始菜单键)打开指令界面,并输入命令,按下回车键
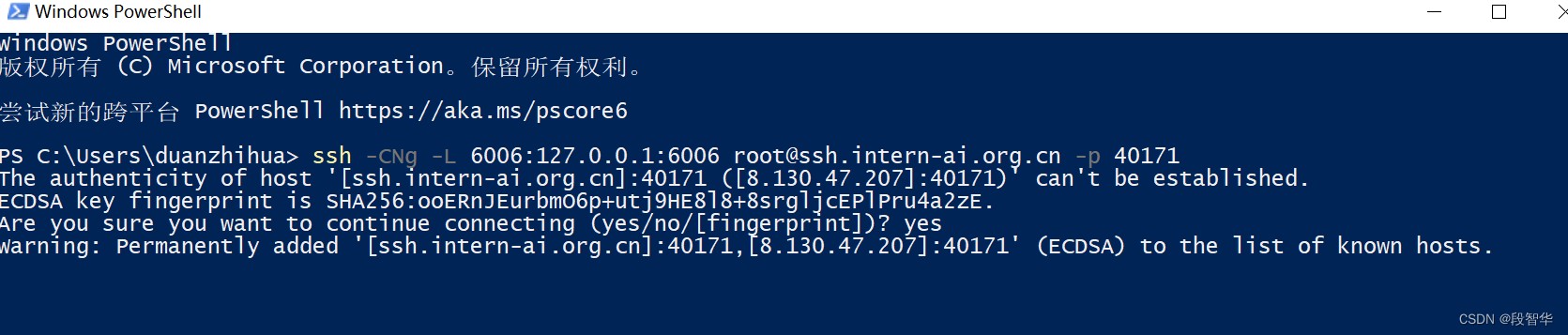
SSH 连接开发机(https://aicarrier.feishu.cn/wiki/VLS7w5I22iQWmTk0ExpczIKcnpf)
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 40171
这是一个 SSH 命令,用于建立一个加密的 SSH 隧道并进行端口转发。
ssh: 这是 SSH 客户端命令。-C: 该选项启用压缩,以减少数据传输的带宽消耗。-N: 该选项告诉 SSH 不执行任何远程命令,仅用于建立连接。-g: 该选项允许其他主机通过该 SSH 隧道连接到本地转发的端口。-L 6006:127.0.0.1:6006: 这是端口转发的部分。它将本地主机(通常是你运行该 SSH 命令的主机)的端口 6006 转发到远程主机127.0.0.1的端口 6006。这意味着任何连接到本地主机的 6006 端口的流量都会通过 SSH 隧道转发到远程主机的 6006 端口。root@ssh.intern-ai.org.cn: 这是远程 SSH 服务器的用户名和主机地址。root是用户名,ssh.intern-ai.org.cn是远程主机的地址。-p 40171: 这是远程 SSH 服务器的端口号,指定为 40171。
该命令会建立一个加密的 SSH 连接到远程主机 ssh.intern-ai.org.cn,并在本地主机的端口 6006 和远程主机的端口 6006 之间建立一个隧道,以便通过该隧道进行数据传输。这通常用于在本地主机上访问远程主机上运行的服务或应用程序,而不需要直接公开远程主机上的端口。
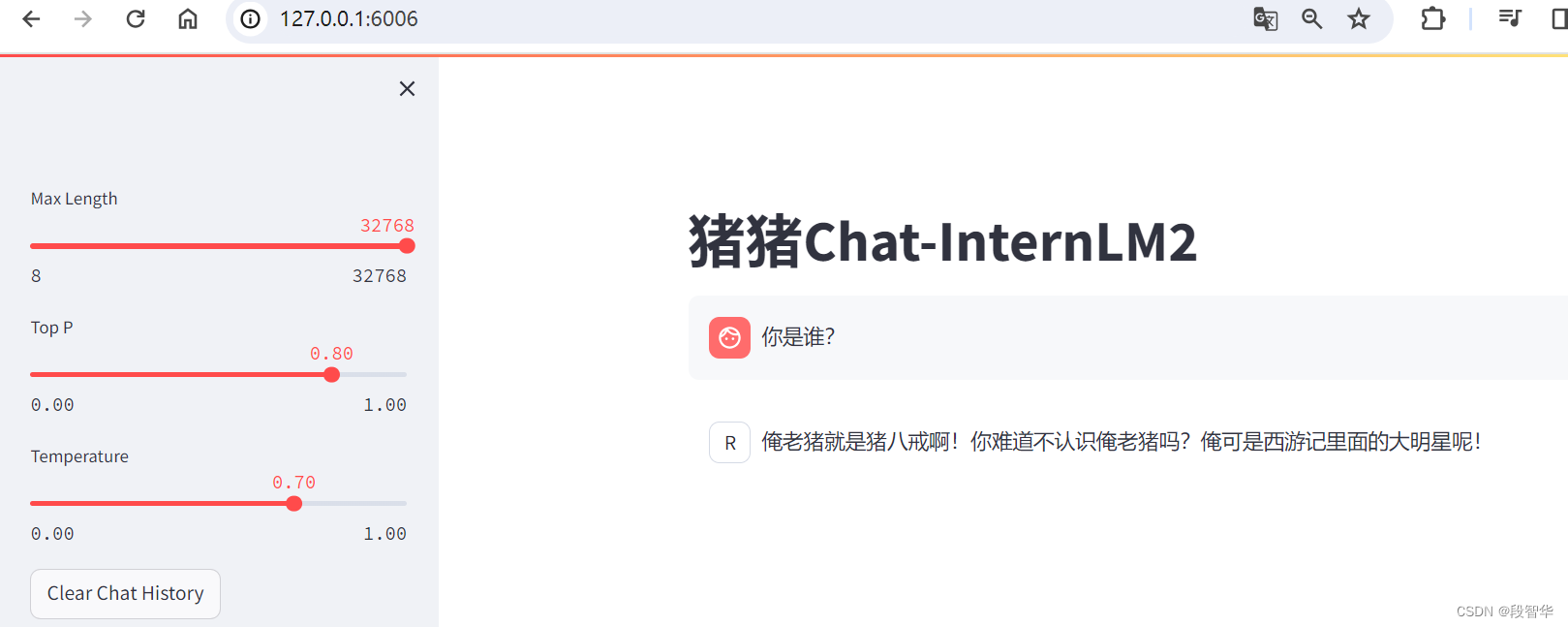
打开 http://127.0.0.1:6006 后,等待加载完成即可进行对话,键入内容示例如下
实战:使用 Lagent 运行 InternLM2-Chat-7B 模型
初步介绍 Lagent 相关知识
Lagent 是一个轻量级、开源的基于大语言模型的智能体(agent)框架,支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供了一些典型工具为大语言模型赋能。 整个框架图如下:
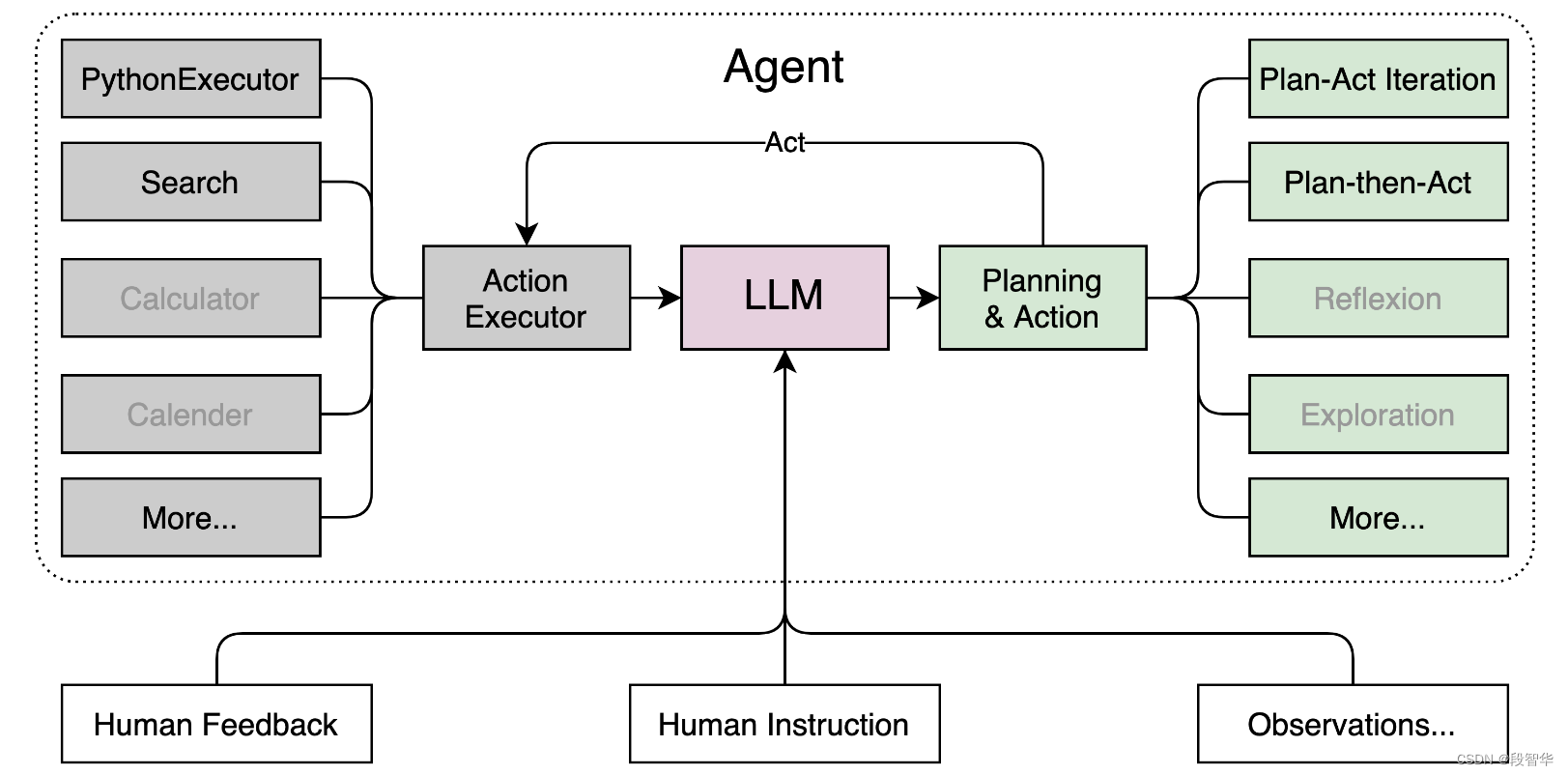
Lagent 的特性总结如下:
- 流式输出:提供 stream_chat 接口作流式输出,本地就能演示酷炫的流式 Demo。
- 接口统一,设计全面升级,提升拓展性,包括:
- Model : 不论是 OpenAI API, Transformers 还是推理加速框架 LMDeploy 一网打尽,模型切换可以游刃有余;
- Action: 简单的继承和装饰,即可打造自己个人的工具集,不论 InternLM 还是 GPT 均可适配;
- Agent:与 Model 的输入接口保持一致,模型到智能体的蜕变只需一步,便捷各种 agent 的探索实现;
- 文档全面升级,API 文档全覆盖。
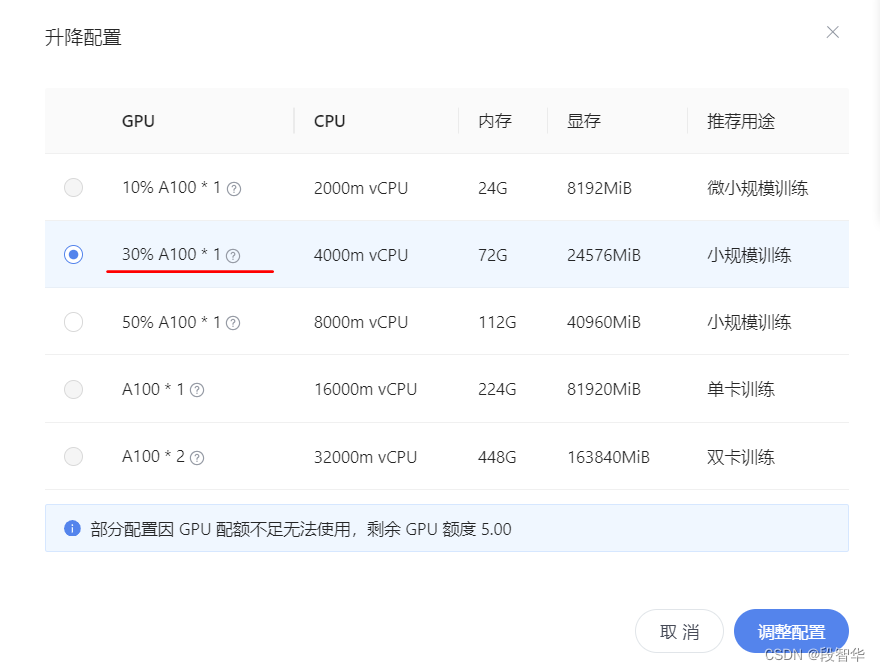
配置基础环境(开启 30% A100 权限后才可开启此章节)
打开 Intern Studio 界面,调节配置
重新开启开发机,输入命令,开启 conda 环境
ssh -p 40171 root@ssh.intern-ai.org.cn -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null
conda activate demo
(base) root@intern-studio-061925:~# conda activate demo
(demo) root@intern-studio-061925:~#
打开文件子路径
cd /root/demo
使用 git 命令下载 Lagent 相关的代码库
git clone https://gitee.com/internlm/lagent.git
# git clone https://github.com/internlm/lagent.git
cd /root/demo/lagent
git checkout 581d9fb8987a5d9b72bb9ebd37a95efd47d479ac
pip install -e . # 源码安装
使用 Lagent 运行 InternLM2-Chat-7B 模型为内核的智能体
Intern Studio 在 share 文件中预留了实践章节所需要的所有基础模型,包括 InternLM2-Chat-7b 、InternLM2-Chat-1.8b 等等。
打开 lagent 路径
cd /root/demo/lagent
在 terminal 中输入指令,构造软链接快捷访问方式:
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b
该命令是用于创建一个符号链接(符号链接也称为软链接),将源文件或目录链接到目标位置。
ln: 这是用于创建链接的命令。-s: 该选项指示创建一个符号链接,而不是硬链接。/root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b: 这是源文件或目录的路径。它指定了要链接的文件或目录的位置。/root/models/internlm2-chat-7b: 这是目标位置的路径。它指定了创建的符号链接的位置。
该命令会创建一个名为 /root/models/internlm2-chat-7b 的符号链接,指向位于 /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b 的源文件或目录。通过这个符号链接,你可以通过访问 /root/models/internlm2-chat-7b 来间接访问源文件或目录。这对于组织文件或创建软件包的不同版本或不同配置的副本非常有用。
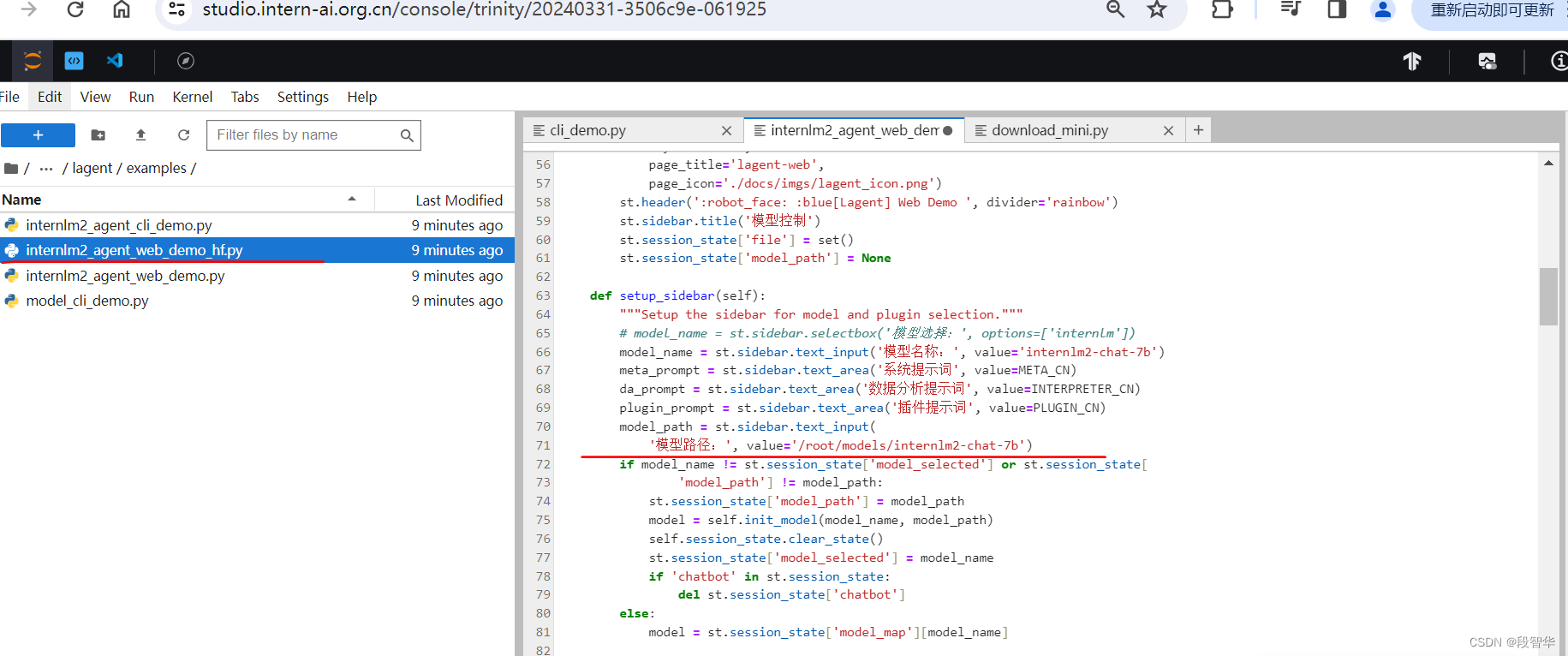
打开 lagent 路径下 examples/internlm2_agent_web_demo_hf.py 文件,并修改对应位置 (71行左右) 代码:
import copy
import hashlib
import json
import os
import streamlit as st
from lagent.actions import ActionExecutor, ArxivSearch, IPythonInterpreter
from lagent.agents.internlm2_agent import INTERPRETER_CN, META_CN, PLUGIN_CN, Internlm2Agent, Internlm2Protocol
from lagent.llms import HFTransformer
from lagent.llms.meta_template import INTERNLM2_META as META
from lagent.schema import AgentStatusCode
# from streamlit.logger import get_logger
class SessionState:
def init_state(self):
"""Initialize session state variables."""
st.session_state['assistant'] = []
st.session_state['user'] = []
action_list = [
ArxivSearch(),
]
st.session_state['plugin_map'] = {
action.name: action
for action in action_list
}
st.session_state['model_map'] = {}
st.session_state['model_selected'] = None
st.session_state['plugin_actions'] = set()
st.session_state['history'] = []
def clear_state(self):
"""Clear the existing session state."""
st.session_state['assistant'] = []
st.session_state['user'] = []
st.session_state['model_selected'] = None
st.session_state['file'] = set()
if 'chatbot' in st.session_state:
st.session_state['chatbot']._session_history = []
class StreamlitUI:
def __init__(self, session_state: SessionState):
self.init_streamlit()
self.session_state = session_state
def init_streamlit(self):
"""Initialize Streamlit's UI settings."""
st.set_page_config(
layout='wide',
page_title='lagent-web',
page_icon='./docs/imgs/lagent_icon.png')
st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow')
st.sidebar.title('模型控制')
st.session_state['file'] = set()
st.session_state['model_path'] = None
def setup_sidebar(self):
"""Setup the sidebar for model and plugin selection."""
# model_name = st.sidebar.selectbox('模型选择:', options=['internlm'])
model_name = st.sidebar.text_input('模型名称:', value='internlm2-chat-7b')
meta_prompt = st.sidebar.text_area('系统提示词', value=META_CN)
da_prompt = st.sidebar.text_area('数据分析提示词', value=INTERPRETER_CN)
plugin_prompt = st.sidebar.text_area('插件提示词', value=PLUGIN_CN)
model_path = st.sidebar.text_input(
'模型路径:', value='internlm/internlm2-chat-20b')
if model_name != st.session_state['model_selected'] or st.session_state[
'model_path'] != model_path:
st.session_state['model_path'] = model_path
model = self.init_model(model_name, model_path)
self.session_state.clear_state()
st.session_state['model_selected'] = model_name
if 'chatbot' in st.session_state:
del st.session_state['chatbot']
else:
model = st.session_state['model_map'][model_name]
plugin_name = st.sidebar.multiselect(
'插件选择',
options=list(st.session_state['plugin_map'].keys()),
default=[],
)
da_flag = st.sidebar.checkbox(
'数据分析',
value=False,
)
plugin_action = [
st.session_state['plugin_map'][name] for name in plugin_name
]
if 'chatbot' in st.session_state:
if len(plugin_action) > 0:
st.session_state['chatbot']._action_executor = ActionExecutor(
actions=plugin_action)
else:
st.session_state['chatbot']._action_executor = None
if da_flag:
st.session_state[
'chatbot']._interpreter_executor = ActionExecutor(
actions=[IPythonInterpreter()])
else:
st.session_state['chatbot']._interpreter_executor = None
st.session_state['chatbot']._protocol._meta_template = meta_prompt
st.session_state['chatbot']._protocol.plugin_prompt = plugin_prompt
st.session_state[
'chatbot']._protocol.interpreter_prompt = da_prompt
if st.sidebar.button('清空对话', key='clear'):
self.session_state.clear_state()
uploaded_file = st.sidebar.file_uploader('上传文件')
return model_name, model, plugin_action, uploaded_file, model_path
def init_model(self, model_name, path):
"""Initialize the model based on the input model name."""
st.session_state['model_map'][model_name] = HFTransformer(
path=path,
meta_template=META,
max_new_tokens=1024,
top_p=0.8,
top_k=None,
temperature=0.1,
repetition_penalty=1.0,
stop_words=['<|im_end|>'])
return st.session_state['model_map'][model_name]
def initialize_chatbot(self, model, plugin_action):
"""Initialize the chatbot with the given model and plugin actions."""
return Internlm2Agent(
llm=model,
protocol=Internlm2Protocol(
tool=dict(
begin='{start_token}{name}\n',
start_token='<|action_start|>',
name_map=dict(
plugin='<|plugin|>', interpreter='<|interpreter|>'),
belong='assistant',
end='<|action_end|>\n',
), ),
max_turn=7)
def render_user(self, prompt: str):
with st.chat_message('user'):
st.markdown(prompt)
def render_assistant(self, agent_return):
with st.chat_message('assistant'):
for action in agent_return.actions:
if (action) and (action.type != 'FinishAction'):
self.render_action(action)
st.markdown(agent_return.response)
def render_plugin_args(self, action):
action_name = action.type
args = action.args
import json
parameter_dict = dict(name=action_name, parameters=args)
parameter_str = '```json\n' + json.dumps(
parameter_dict, indent=4, ensure_ascii=False) + '\n```'
st.markdown(parameter_str)
def render_interpreter_args(self, action):
st.info(action.type)
st.markdown(action.args['text'])
def render_action(self, action):
st.markdown(action.thought)
if action.type == 'IPythonInterpreter':
self.render_interpreter_args(action)
elif action.type == 'FinishAction':
pass
else:
self.render_plugin_args(action)
self.render_action_results(action)
def render_action_results(self, action):
"""Render the results of action, including text, images, videos, and
audios."""
if (isinstance(action.result, dict)):
if 'text' in action.result:
st.markdown('```\n' + action.result['text'] + '\n```')
if 'image' in action.result:
# image_path = action.result['image']
for image_path in action.result['image']:
image_data = open(image_path, 'rb').read()
st.image(image_data, caption='Generated Image')
if 'video' in action.result:
video_data = action.result['video']
video_data = open(video_data, 'rb').read()
st.video(video_data)
if 'audio' in action.result:
audio_data = action.result['audio']
audio_data = open(audio_data, 'rb').read()
st.audio(audio_data)
elif isinstance(action.result, list):
for item in action.result:
if item['type'] == 'text':
st.markdown('```\n' + item['content'] + '\n```')
elif item['type'] == 'image':
image_data = open(item['content'], 'rb').read()
st.image(image_data, caption='Generated Image')
elif item['type'] == 'video':
video_data = open(item['content'], 'rb').read()
st.video(video_data)
elif item['type'] == 'audio':
audio_data = open(item['content'], 'rb').read()
st.audio(audio_data)
if action.errmsg:
st.error(action.errmsg)
def main():
# logger = get_logger(__name__)
# Initialize Streamlit UI and setup sidebar
if 'ui' not in st.session_state:
session_state = SessionState()
session_state.init_state()
st.session_state['ui'] = StreamlitUI(session_state)
else:
st.set_page_config(
layout='wide',
page_title='lagent-web',
page_icon='./docs/imgs/lagent_icon.png')
st.header(':robot_face: :blue[Lagent] Web Demo ', divider='rainbow')
_, model, plugin_action, uploaded_file, _ = st.session_state[
'ui'].setup_sidebar()
# Initialize chatbot if it is not already initialized
# or if the model has changed
if 'chatbot' not in st.session_state or model != st.session_state[
'chatbot']._llm:
st.session_state['chatbot'] = st.session_state[
'ui'].initialize_chatbot(model, plugin_action)
st.session_state['session_history'] = []
for prompt, agent_return in zip(st.session_state['user'],
st.session_state['assistant']):
st.session_state['ui'].render_user(prompt)
st.session_state['ui'].render_assistant(agent_return)
if user_input := st.chat_input(''):
with st.container():
st.session_state['ui'].render_user(user_input)
st.session_state['user'].append(user_input)
# Add file uploader to sidebar
if (uploaded_file
and uploaded_file.name not in st.session_state['file']):
st.session_state['file'].add(uploaded_file.name)
file_bytes = uploaded_file.read()
file_type = uploaded_file.type
if 'image' in file_type:
st.image(file_bytes, caption='Uploaded Image')
elif 'video' in file_type:
st.video(file_bytes, caption='Uploaded Video')
elif 'audio' in file_type:
st.audio(file_bytes, caption='Uploaded Audio')
# Save the file to a temporary location and get the path
postfix = uploaded_file.name.split('.')[-1]
# prefix = str(uuid.uuid4())
prefix = hashlib.md5(file_bytes).hexdigest()
filename = f'{prefix}.{postfix}'
file_path = os.path.join(root_dir, filename)
with open(file_path, 'wb') as tmpfile:
tmpfile.write(file_bytes)
file_size = os.stat(file_path).st_size / 1024 / 1024
file_size = f'{round(file_size, 2)} MB'
# st.write(f'File saved at: {file_path}')
user_input = [
dict(role='user', content=user_input),
dict(
role='user',
content=json.dumps(dict(path=file_path, size=file_size)),
name='file')
]
if isinstance(user_input, str):
user_input = [dict(role='user', content=user_input)]
st.session_state['last_status'] = AgentStatusCode.SESSION_READY
for agent_return in st.session_state['chatbot'].stream_chat(
st.session_state['session_history'] + user_input):
if agent_return.state == AgentStatusCode.PLUGIN_RETURN:
with st.container():
st.session_state['ui'].render_plugin_args(
agent_return.actions[-1])
st.session_state['ui'].render_action_results(
agent_return.actions[-1])
elif agent_return.state == AgentStatusCode.CODE_RETURN:
with st.container():
st.session_state['ui'].render_action_results(
agent_return.actions[-1])
elif (agent_return.state == AgentStatusCode.STREAM_ING
or agent_return.state == AgentStatusCode.CODING):
# st.markdown(agent_return.response)
# 清除占位符的当前内容,并显示新内容
with st.container():
if agent_return.state != st.session_state['last_status']:
st.session_state['temp'] = ''
placeholder = st.empty()
st.session_state['placeholder'] = placeholder
if isinstance(agent_return.response, dict):
action = f"\n\n {agent_return.response['name']}: \n\n"
action_input = agent_return.response['parameters']
if agent_return.response[
'name'] == 'IPythonInterpreter':
action_input = action_input['command']
response = action + action_input
else:
response = agent_return.response
st.session_state['temp'] = response
st.session_state['placeholder'].markdown(
st.session_state['temp'])
elif agent_return.state == AgentStatusCode.END:
st.session_state['session_history'] += (
user_input + agent_return.inner_steps)
agent_return = copy.deepcopy(agent_return)
agent_return.response = st.session_state['temp']
st.session_state['assistant'].append(
copy.deepcopy(agent_return))
st.session_state['last_status'] = agent_return.state
if __name__ == '__main__':
root_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
root_dir = os.path.join(root_dir, 'tmp_dir')
os.makedirs(root_dir, exist_ok=True)
main()
这段代码是一个使用Streamlit框架构建的Web应用程序,它提供了一个用户界面来与一个聊天机器人进行交互。以下是代码的主要组成部分和功能:
-
导入依赖:代码开始部分导入了多个Python库,包括用于处理文件、加密、JSON数据和操作系统操作的库,以及Streamlit库本身。
-
SessionState 类:这个类负责管理用户会话的状态,包括用户和助手的消息列表、插件映射、模型选择、历史记录等。
-
StreamlitUI 类:这个类负责初始化Streamlit的UI设置,设置侧边栏用于模型和插件选择,并处理用户输入和聊天机器人的响应。
-
模型和插件初始化:用户可以在侧边栏中选择模型和插件,然后通过文本输入框提供模型名称和路径。应用程序会根据选择的模型初始化一个
HFTransformer实例。 -
聊天界面:应用程序使用Streamlit的聊天输入组件来允许用户与聊天机器人交互。用户输入显示在标记为"user"的区域,而聊天机器人的响应显示在标记为"assistant"的区域。
-
文件上传:用户可以上传文件,应用程序会根据文件类型显示图像、视频或音频。
-
聊天机器人代理:
Internlm2Agent类是聊天机器人的代理,它处理用户的输入并生成响应。它使用了Internlm2Protocol协议来定义聊天的格式和结构。 -
主函数:
main函数是应用程序的入口点,它初始化UI和会话状态,然后进入一个循环,不断处理用户的输入和聊天机器人的响应。 -
辅助函数:
render_user、render_assistant、render_plugin_args、render_interpreter_args和render_action_results等函数用于渲染用户的输入、聊天机器人的响应、插件参数、解释器参数和动作结果。 -
状态管理:应用程序通过
AgentStatusCode类来管理聊天机器人的状态,并处理可能出现的错误消息。
整体来看,这段代码展示了一个交互式的Web应用程序,它允许用户通过自然语言与聊天机器人进行对话,并能够处理文件上传和展示多种媒体内容。应用程序使用了Streamlit的组件和布局特性来创建一个用户友好的界面。
修改 ‘模型路径:’, value=‘internlm/internlm2-chat-20b’ 为 value='/root/models/internlm2-chat-7b
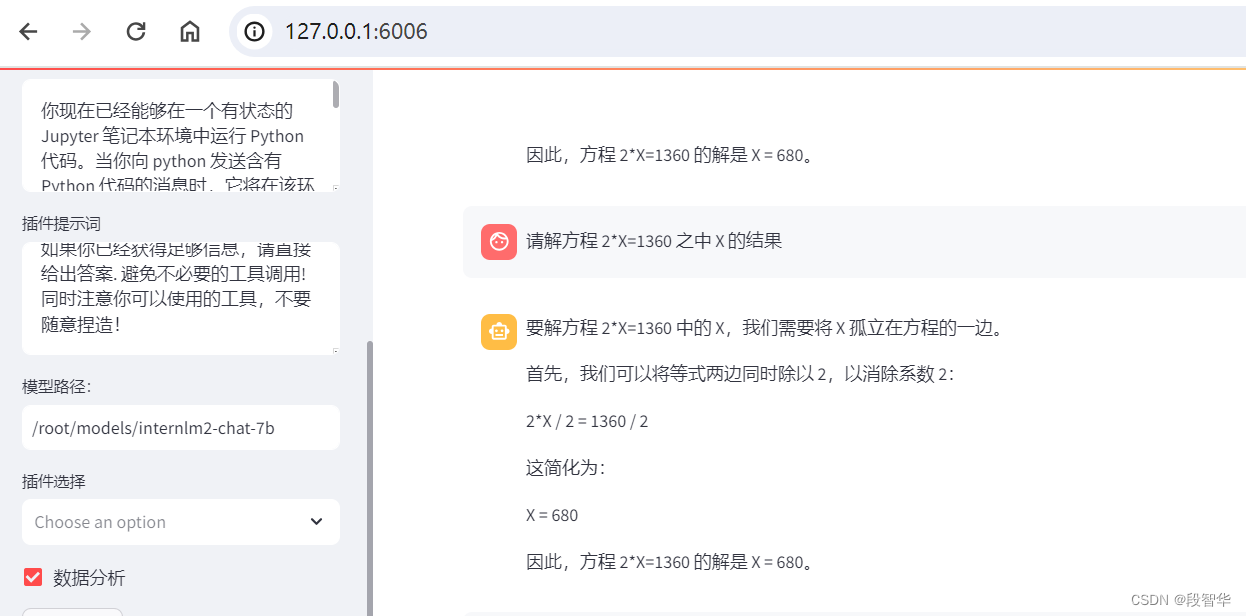
输入运行命令 - 点开 6006 链接后,大约需要 5 分钟完成模型加载:
streamlit run /root/demo/lagent/examples/internlm2_agent_web_demo_hf.py --server.address 127.0.0.1 --server.port 6006

使用快捷键组合 Windows + R(Windows 即开始菜单键)打开指令界面,并输入命令,按下回车键。
ssh -CNg -L 6006:127.0.0.1:6006 root@ssh.intern-ai.org.cn -p 40171

打开 http://127.0.0.1:6006 后,(会有较长的加载时间)勾上数据分析,其他的选项不要选择,进行计算方面的 Demo 对话,即完成本章节实战。键入内容示例:
实战:实践部署 浦语·灵笔2 模型
初步介绍 XComposer2 相关知识
浦语·灵笔2 是基于 书生·浦语2 大语言模型研发的突破性的图文多模态大模型,具有非凡的图文写作和图像理解能力,在多种应用场景表现出色,总结起来其具有:
- 自由指令输入的图文写作能力: 浦语·灵笔2 可以理解自由形式的图文指令输入,包括大纲、文章细节要求、参考图片等,为用户打造图文并貌的专属文章。生成的文章文采斐然,图文相得益彰,提供沉浸式的阅读体验。
- 准确的图文问题解答能力:浦语·灵笔2 具有海量图文知识,可以准确的回复各种图文问答难题,在识别、感知、细节描述、视觉推理等能力上表现惊人。
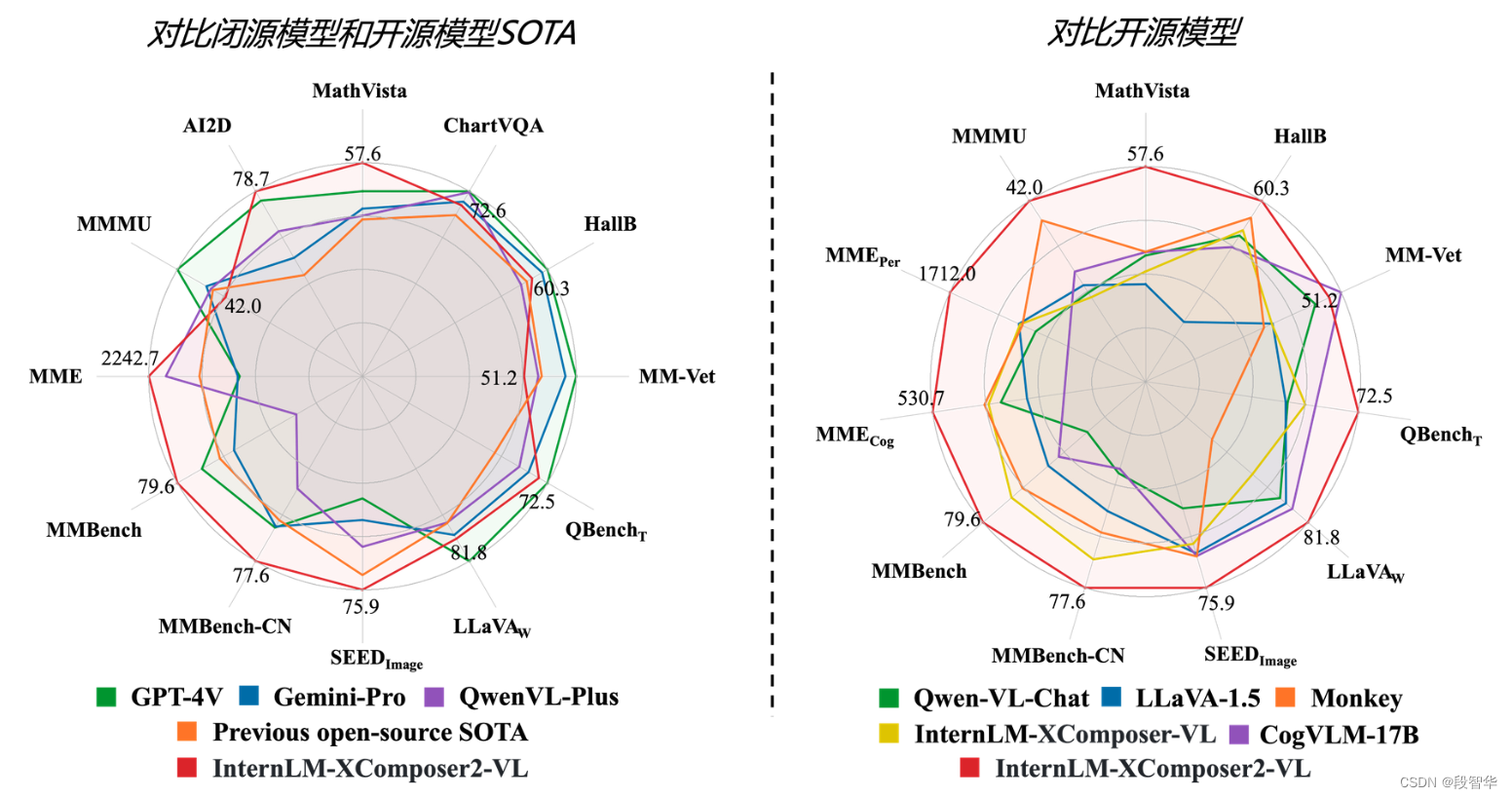
- 杰出的综合能力: 浦语·灵笔2-7B 基于 书生·浦语2-7B 模型,在13项多模态评测中大幅领先同量级多模态模型,在其中6项评测中超过 GPT-4V 和 Gemini Pro。
配置基础环境(开启 50% A100 权限后才可开启此章节)
选用 50% A100 进行开发
进入开发机,启动 conda 环境
conda activate demo
# 补充环境包
pip install timm==0.4.12 sentencepiece==0.1.99 markdown2==2.4.10 xlsxwriter==3.1.2 gradio==4.13.0 modelscope==1.9.5

下载 InternLM-XComposer 仓库 相关的代码资源
在 terminal 中输入指令,构造软链接快捷访问方式
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm-xcomposer2-7b /root/models/internlm-xcomposer2-7b
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm-xcomposer2-vl-7b /root/models/internlm-xcomposer2-vl-7b
图文写作实战
输入指令,用于启动 InternLM-XComposer:
cd /root/demo/InternLM-XComposer
python /root/demo/InternLM-XComposer/examples/gradio_demo_composition.py \
--code_path /root/models/internlm-xcomposer2-7b \
--private \
--num_gpus 1 \
--port 6006
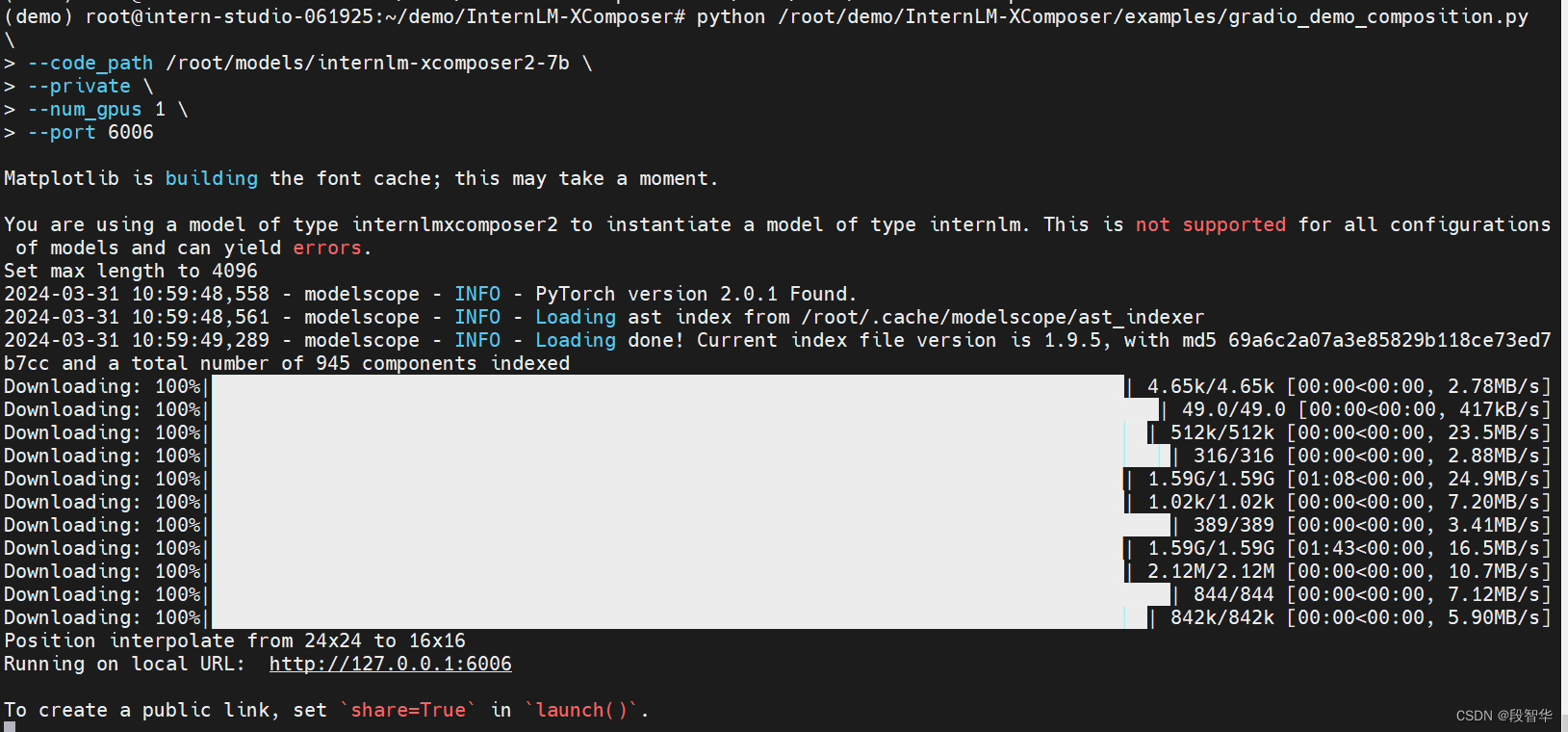
使用快捷键组合 Windows + R(Windows 即开始菜单键)打开指令界面,(Mac 用户打开终端即可)并输入命令,按下回车键

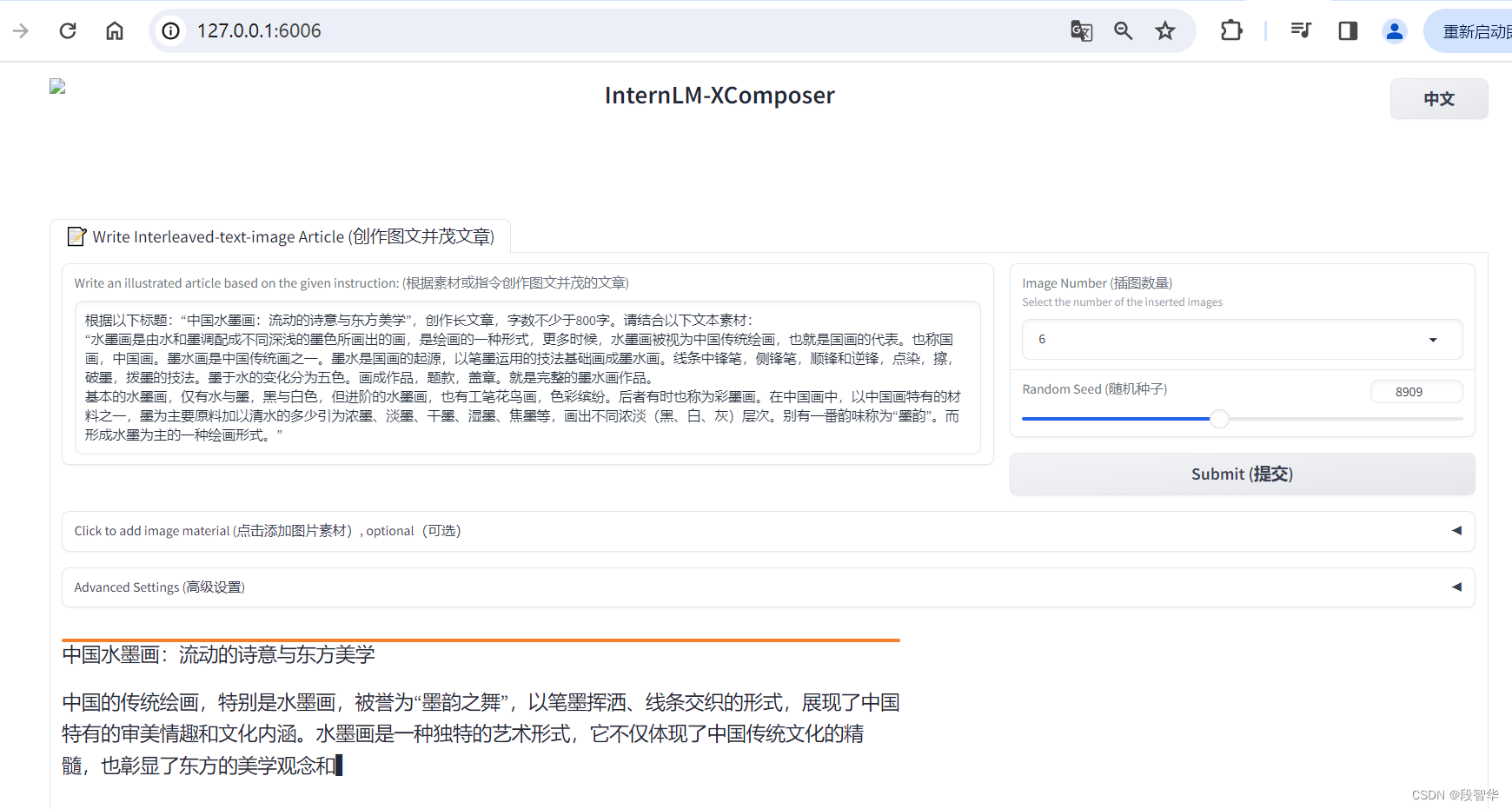
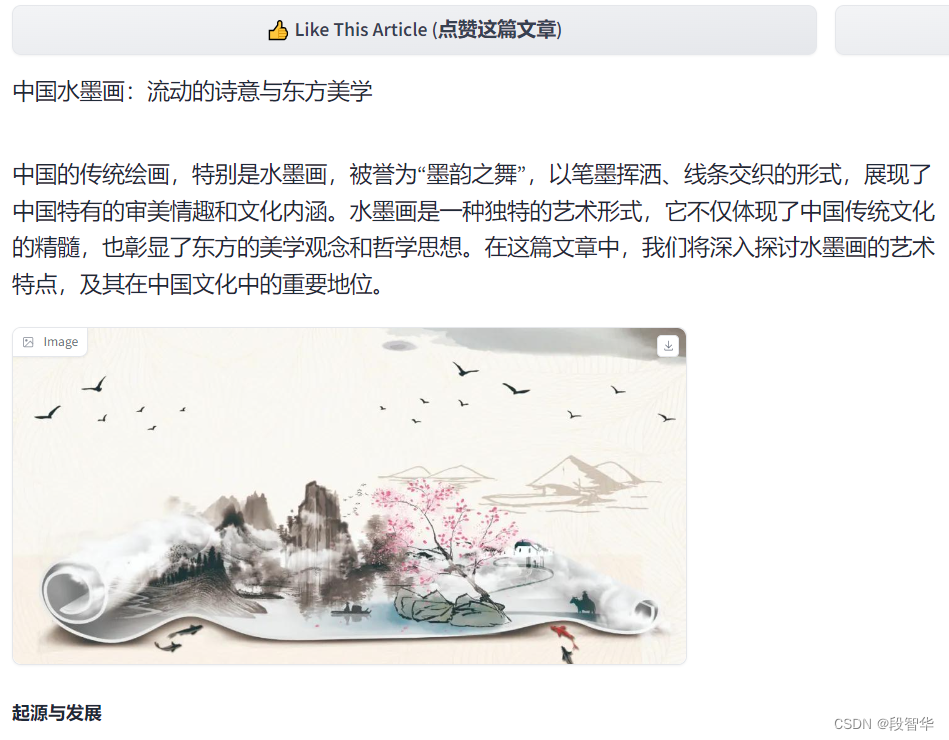
打开 http://127.0.0.1:6006 实践效果如下图所示
根据以下标题:“中国水墨画:流动的诗意与东方美学”,创作长文章,字数不少于800字。请结合以下文本素材:
“水墨画是由水和墨调配成不同深浅的墨色所画出的画,是绘画的一种形式,更多时候,水墨画被视为中国传统绘画,也就是国画的代表。也称国画,中国画。墨水画是中国传统画之一。墨水是国画的起源,以笔墨运用的技法基础画成墨水画。线条中锋笔,侧锋笔,顺锋和逆锋,点染,擦,破墨,拨墨的技法。墨于水的变化分为五色。画成作品,题款,盖章。就是完整的墨水画作品。
基本的水墨画,仅有水与墨,黑与白色,但进阶的水墨画,也有工笔花鸟画,色彩缤纷。后者有时也称为彩墨画。在中国画中,以中国画特有的材料之一,墨为主要原料加以清水的多少引为浓墨、淡墨、干墨、湿墨、焦墨等,画出不同浓淡(黑、白、灰)层次。别有一番韵味称为“墨韵”。而形成水墨为主的一种绘画形式。”

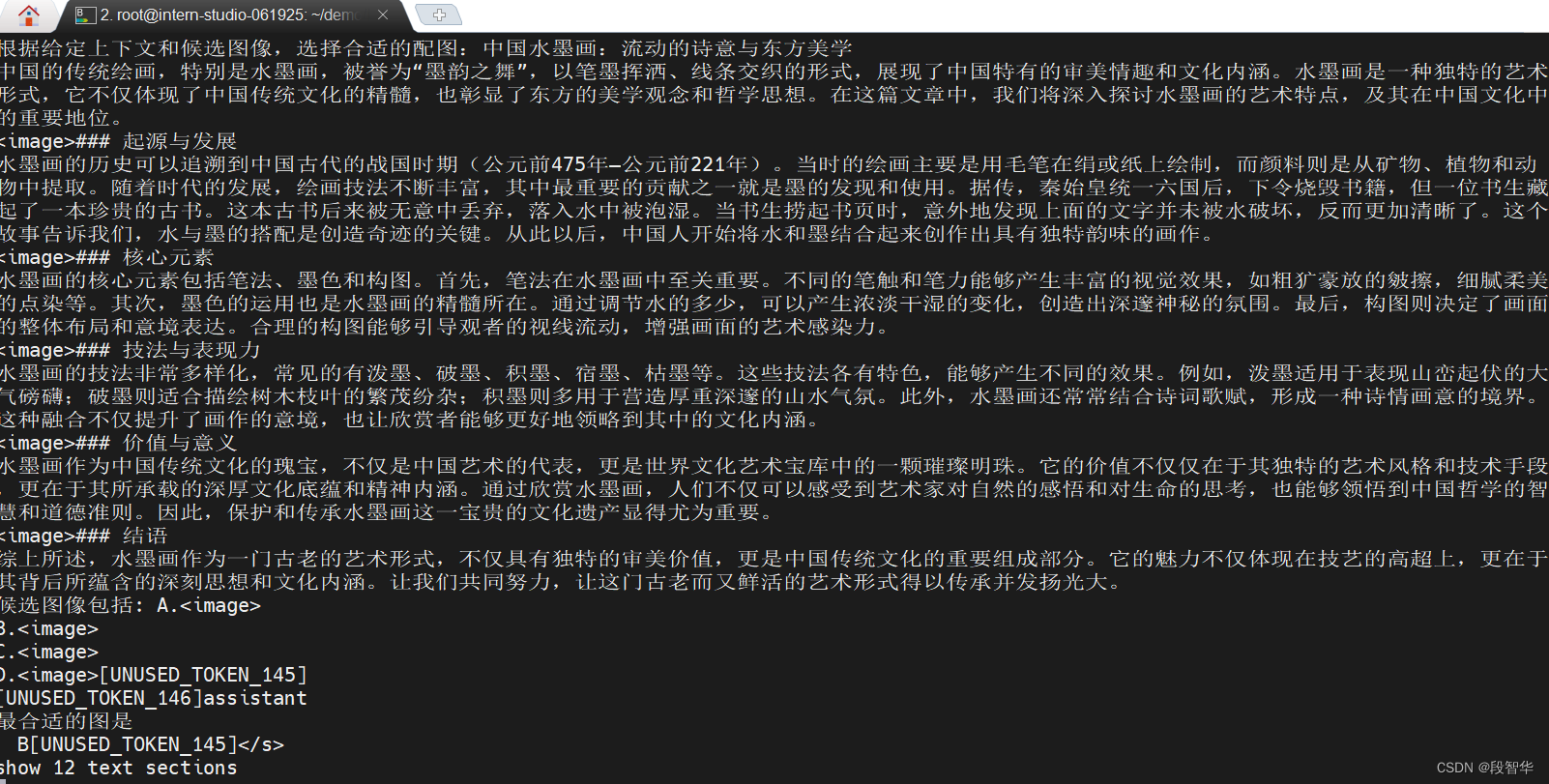
图片理解实战
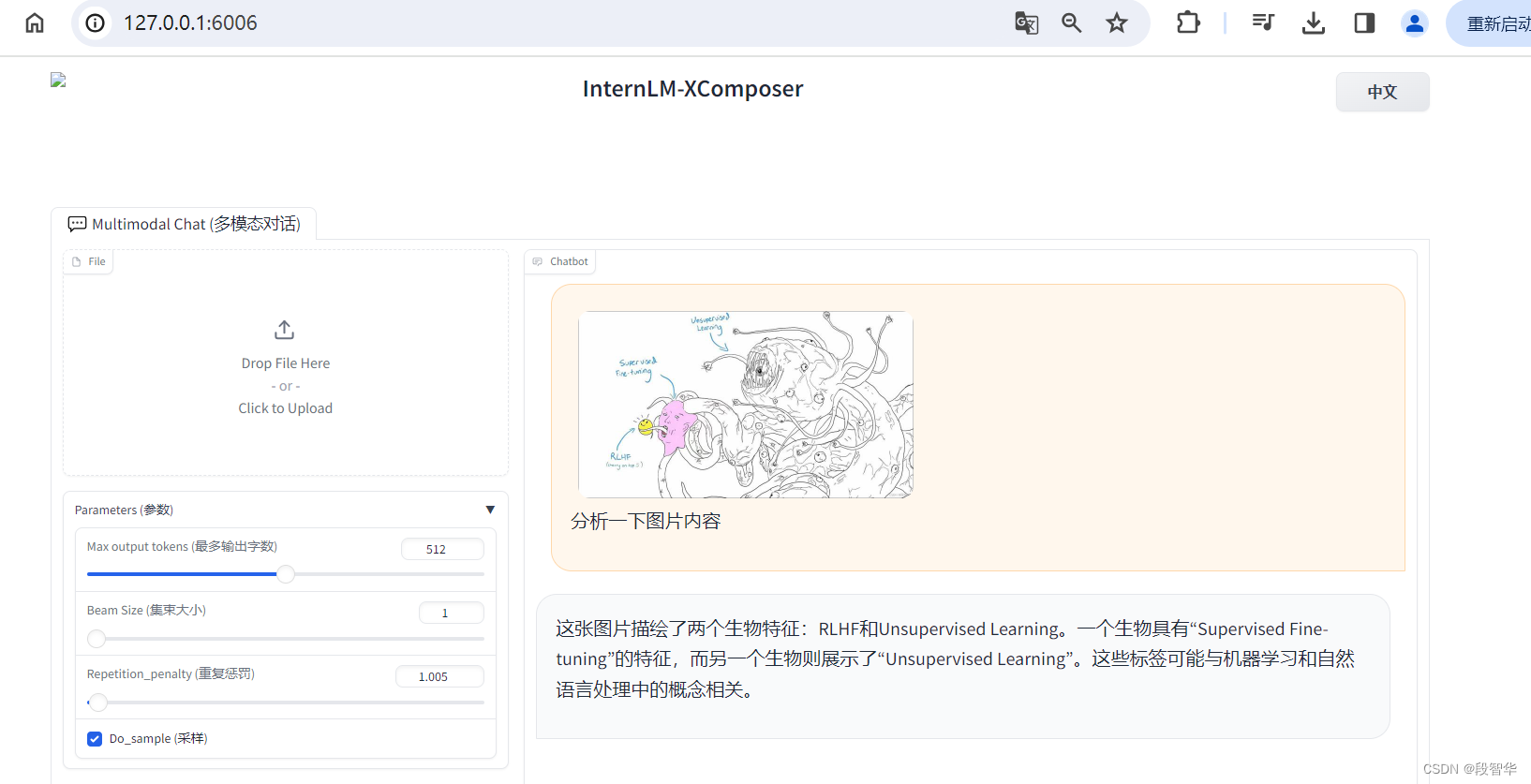
重新启动一个新的 terminal,继续输入指令,启动 InternLM-XComposer2-vl:
conda activate demo
cd /root/demo/InternLM-XComposer
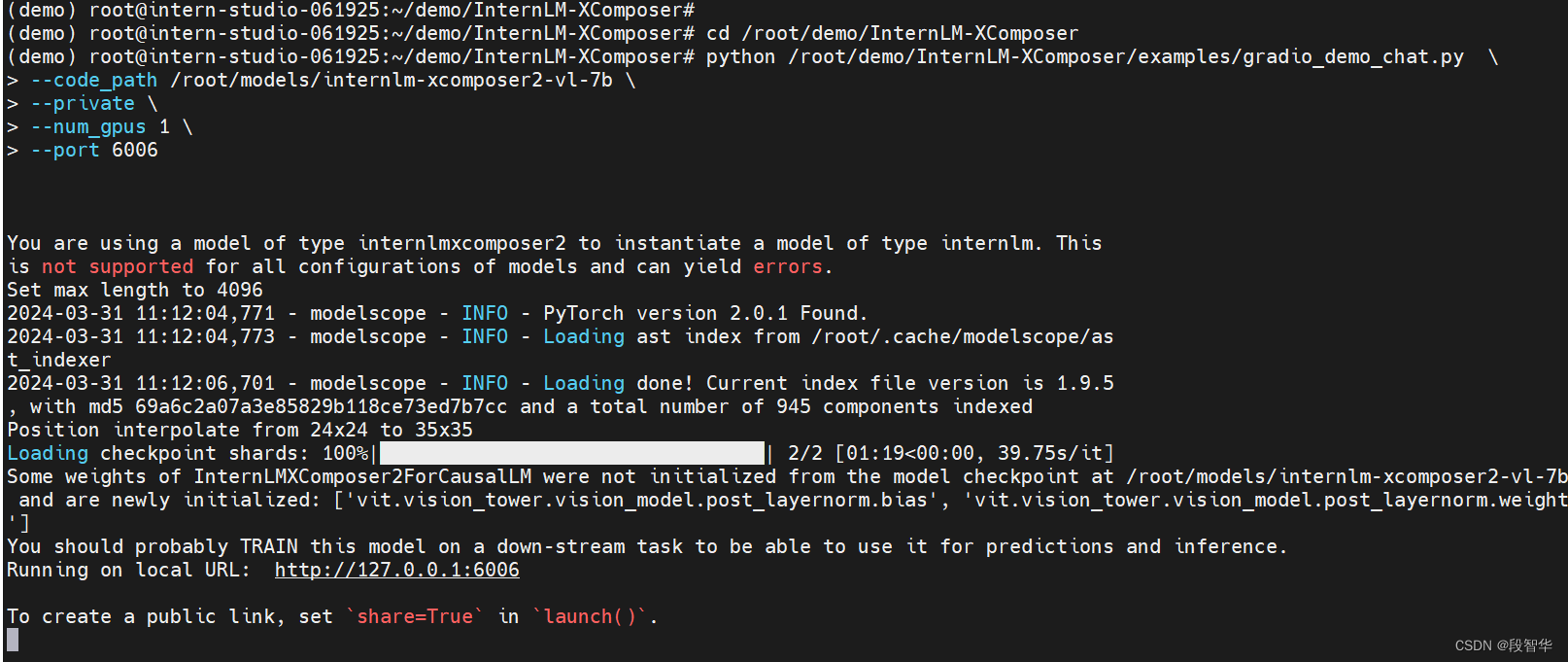
python /root/demo/InternLM-XComposer/examples/gradio_demo_chat.py \
--code_path /root/models/internlm-xcomposer2-vl-7b \
--private \
--num_gpus 1 \
--port 6006
打开 http://127.0.0.1:6006 (上传图片后) 键入内容示例如下