机器学习—— PU-Learning算法
本篇博客将介绍PU-Learning算法的基本概念、基本流程、基本方法,并简单探讨Two-step PU Learning算法和无偏PU Learning算法的具体流程。最后,将通过Python代码实现一个简单的PU-Learning示例,以便更好地理解这些概念和算法。
1. 基本概念
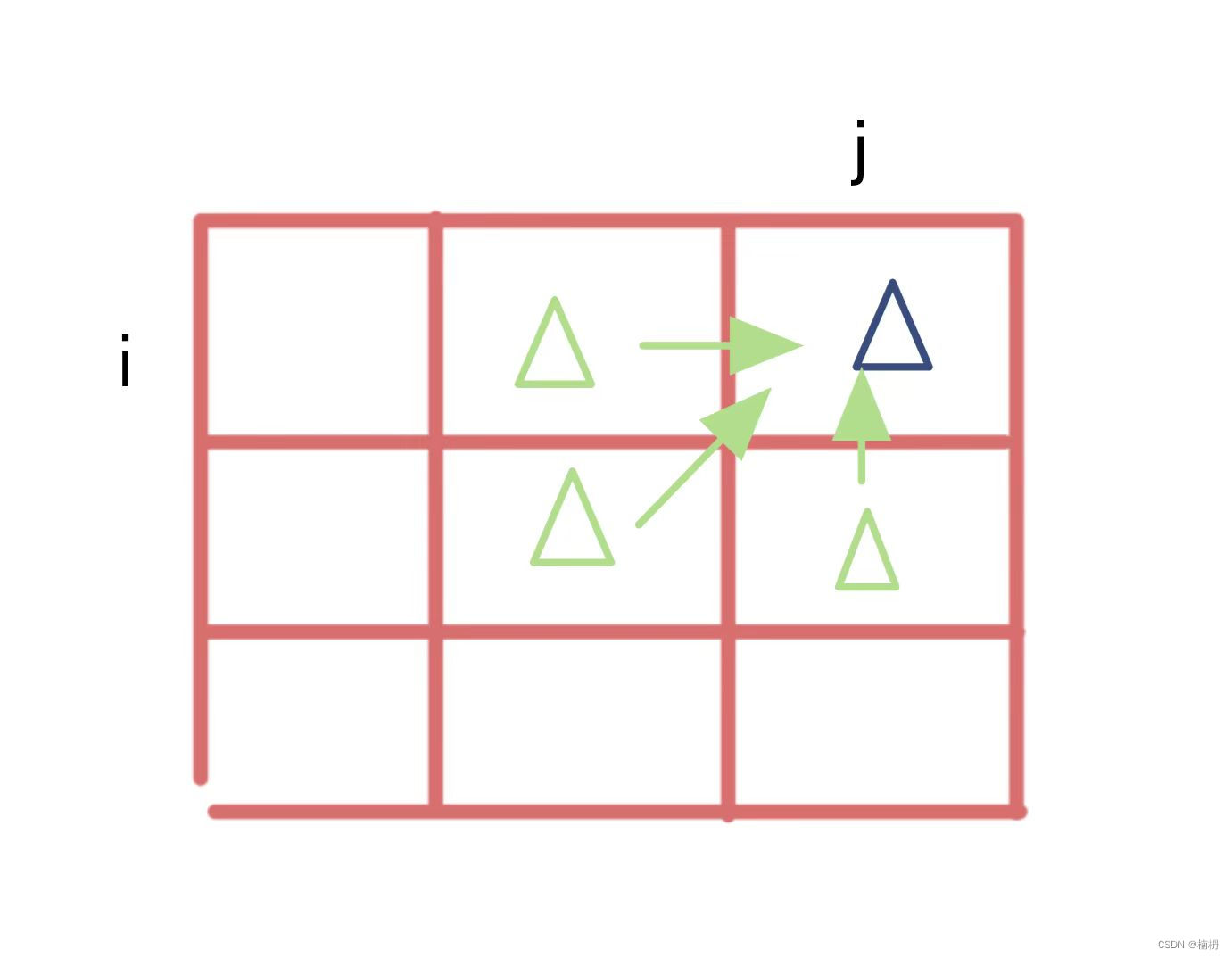
PU-Learning是一种解决类别不平衡问题的机器学习方法,其中类别包括正例(Positive)和未标记样本(Unlabeled)。在PU-Learning中,希望从未标记样本中挑选出可能的负例,以提高分类器性能。
2. 基本流程
PU-Learning的基本流程如下:
- 从已标记样本中选择一部分正例作为训练集的正例。
- 从未标记样本中选择一部分样本作为训练集的负例。
- 使用选择的正例和负例训练分类器。
- 使用训练好的分类器对未标记样本进行分类,并根据分类结果更新训练集。
3. 基本方法
PU-Learning的基本方法包括:
- 有偏采样(Biased Sampling):从未标记样本中选择概率较高的样本作为负例。
- 标记传播(Label Propagation):利用已标记样本的信息,通过传播标记来识别未标记样本的类别。
- 概率估计(Probability Estimation):估计未标记样本属于正例的概率。
4. Two-step PU Learning算法
Two-step PU Learning算法是一种常见的PU-Learning方法,其基本流程如下:
- 第一步:有偏采样(Biased Sampling):从未标记样本中选择概率较高的样本作为负例,构建训练集。
- 第二步:训练分类器(Train Classifier):使用选择的正例和负例训练分类器。
5. 无偏PU Learning算法
无偏PU Learning算法通过对未标记样本进行加权来减少有偏性,其基本流程如下:
- 计算正例和负例的相似度(Calculate Similarity):计算未标记样本与已标记样本的相似度。
- 根据相似度进行加权(Weighting):根据相似度对未标记样本进行加权,以减少有偏性。
- 训练分类器(Train Classifier):使用加权后的样本训练分类器。
6. 程序示例
下面是一个简单的Python实现PU-Learning的示例代码:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
class PUClassifier:
def __init__(self, positive_ratio=0.5, negative_ratio=0.5):
self.positive_ratio = positive_ratio
self.negative_ratio = negative_ratio
self.classifier = SVC()
def fit(self, X, y):
positive_samples = X[y == 1]
negative_samples = X[y == 0]
# Biased Sampling
positive_indices = np.random.choice(len(positive_samples), int(len(positive_samples) * self.positive_ratio), replace=False)
negative_indices = np.random.choice(len(negative_samples), int(len(negative_samples) * self.negative_ratio), replace=False)
X_train = np.concatenate((positive_samples[positive_indices], negative_samples[negative_indices]))
y_train = np.concatenate((np.ones(len(positive_indices)), np.zeros(len(negative_indices))))
# Train Classifier
self.classifier.fit(X_train, y_train)
def predict(self, X):
return self.classifier.predict(X)
# 构造一个二维数据集
X = np.random.randn(100, 2)
y = np.random.randint(2, size=100) # 随机生成正负例
# 创建PUClassifier对象并进行拟合
pu_classifier = PUClassifier()
pu_classifier.fit(X, y)
# 预测并输出结果
predictions = pu_classifier.predict(X)
# 绘制数据集和分类结果
plt.figure(figsize=(10, 6))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap='coolwarm', marker='o', edgecolors='k', label='Samples')
plt.scatter(X[predictions == 1][:, 0], X[predictions == 1][:, 1], c='blue', marker='s', edgecolors='k', label='Predicted Positive')
plt.scatter(X[predictions == 0][:, 0], X[predictions == 0][:, 1], c='red', marker='s', edgecolors='k', label='Predicted Negative')
# 绘制决策边界
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
xx, yy = np.meshgrid(np.linspace(xlim[0], xlim[1], 50), np.linspace(ylim[0], ylim[1], 50))
Z = pu_classifier.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.2, cmap='coolwarm')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('PU Learning Results')
plt.legend()
plt.show()

通过以上代码,使用随机生成的二维数据集,利用PU-Learning算法进行分类,并将结果可视化展示在图中。蓝色和红色方块代表分类器预测为正例和负例的样本,不同颜色的圆圈代表正负例样本,而背景的色块则表示分类器的决策边界。
总结
在本篇博客中,简单介绍了PU-Learning算法的基本概念、基本流程和基本方法,并简单讨论了Two-step PU Learning算法和无偏PU Learning算法的具体流程。通过示例代码,展示了如何用Python实现一个简单的PU-Learning分类器。PU-Learning是解决类别不平衡问题的有效方法,在实际应用中具有广泛的应用前景。