1、统计XML文件内标签的种类和其数量
对于自己标注的数据集,需在标注完成后需要对标注好的XML文件校验,下面是代码,只需将SrcDir换成需要统计的xml的文件夹即可。
import os
from tqdm import tqdm
import xml.dom.minidom
def ReadXml(FilePath):
if os.path.exists(FilePath) is False:
return None
dom = xml.dom.minidom.parse(FilePath)
root_ = dom.documentElement
object_ = root_.getElementsByTagName('object')
info = []
for object_1 in object_:
name = object_1.getElementsByTagName("name")[0].firstChild.data
bndbox = object_1.getElementsByTagName("bndbox")[0]
xmin = int(bndbox.getElementsByTagName("xmin")[0].firstChild.data)
ymin = int(bndbox.getElementsByTagName("ymin")[0].firstChild.data)
xmax = int(bndbox.getElementsByTagName("xmax")[0].firstChild.data)
ymax = int(bndbox.getElementsByTagName("ymax")[0].firstChild.data)
info.append([xmin, ymin, xmax, ymax, name])
return info
def CountLabelKind(Path):
LabelDict = {}
print("Star to count label kinds....")
for root, dirs, files in os.walk(Path):
for file in tqdm(files):
if file[-1] == 'l':
Infos = ReadXml(root + "\\" + file)
for Info in Infos:
if Info[-1] not in LabelDict.keys():
LabelDict[Info[-1]] = 1
else:
LabelDict[Info[-1]] += 1
return dict(sorted(LabelDict.items(), key=lambda x: x[0]))
if __name__ == '__main__':
SrcDir = r"D:\program\数据集\自标数据集(fall-nofall)\自标数据集(fall-nofall)\标注1~1000(1)"
LabelDict = CountLabelKind(SrcDir)
KeyDict = sorted(LabelDict)
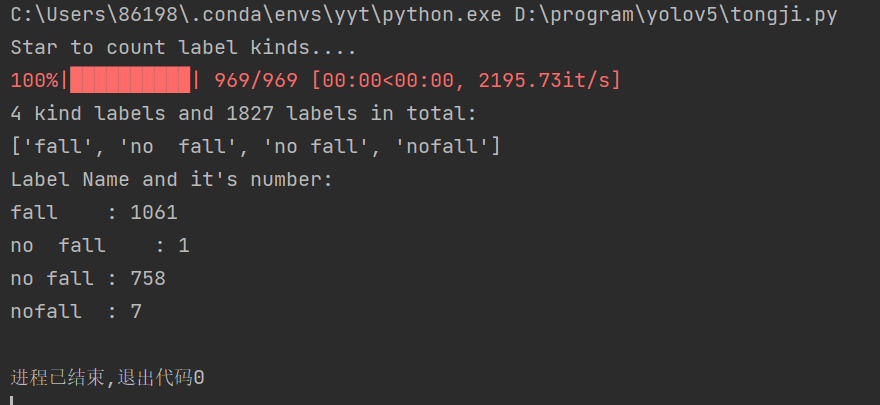
print("%d kind labels and %d labels in total:" % (len(KeyDict), sum(LabelDict.values())))
print(KeyDict)
print("Label Name and it's number:")
for key in KeyDict:
print("%s\t: %d" % (key, LabelDict[key]))
2、运行后报错:xml.parsers.expat.ExpatError: no element found: line 1, column 0
这是因为我的数据集中有XML文件为空
解决办法:最简单就是查看你文件夹下的XML文件的大小是否为0kb,若为0kb,直接删除。
最终统计效果如下:
3、将xml格式转换为yolov5所需的txt格式
先给大家看我的目录:
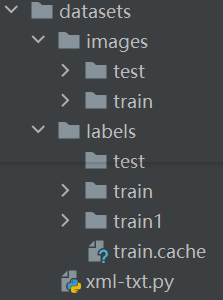
注意:
①此处的xml—txt.py文件是放在datasets文件夹下的(代码中的绝对路径)。
②imges文件夹中的train目录下的每一张图片都要有相应的xml文件,若无,则手动删除该jpg文件。
train1是存放xml文件的文件夹,train是存放txt文件的文件夹。
文件代码:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import glob
classes = ['fall', 'no fall', 'no fall', 'nofall']
def convert(size, box):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_name):
in_file = open('./labels/train1/' + image_name[:-3] + 'xml') # xml文件路径
out_file = open('./labels/train/' + image_name[:-3] + 'txt', 'w') # 转换后的txt文件存放路径
f = open('./labels/train1/' + image_name[:-3] + 'xml')
xml_text = f.read()
root = ET.fromstring(xml_text)
f.close()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if __name__ == '__main__':
for image_path in glob.glob("./images/train/*.jpg"): # 每一张图片都对应一个xml文件这里写xml对应的图片的路径
image_name = image_path.split('\\')[-1]
convert_annotation(image_name)
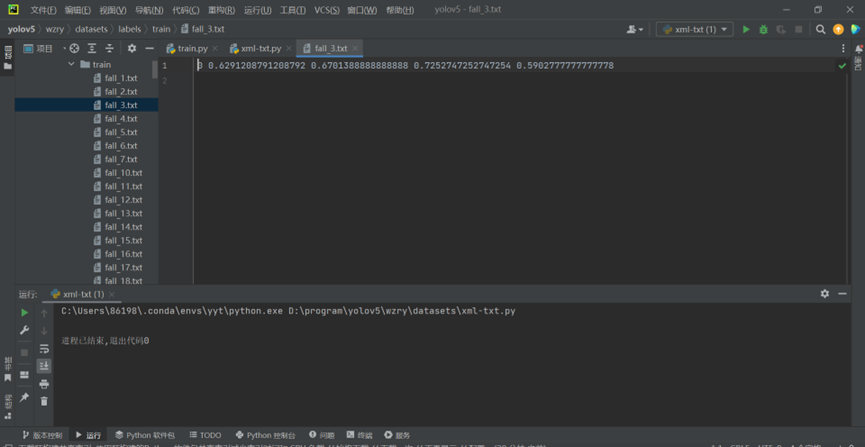
转换后的txt文件为:
我的标注标签有四个,分别对应下面这四个数字。
接下来又是漫长且易秃的环境配置之路了。