1.1pandas验证操作
1、验证以下代码,并将结果附截图
import pandas as pd
A=[1,3,6,4,9,10,15]
weight=[67,66,83,68,79,88]
sex=['女','男','男','女','男', '男']
S1=pd.Series(A)#构建S1序列
print(S1)
S2=pd.Series(weight)#构建S2序列
print(S2)
S3=pd.Series(sex)#构建S3序列
print(S3)
print(S3[1])#或print(S3.iloc[1]
print(S2[2])#或print(S2.iloc[2])

- 分别验证S2.loc[1]、S2[1]、S2.iloc[1],并附截图,说明序列变量.loc[i]、序列变量.iloc和序列变量[i]的作用

3、验证以下代码,并结果附截图
B=pd.concat([S2,S3],axis=0)
print(B)
S=pd.concat([S2,S3],axis=1)#按列合并序列,合并后为两列成为数据框
print(S)
print(S.loc[0])#第1行
print(S.iloc[0,:])#第1行
print(S[1])#第2列
print(S.iloc[:,1])#第2列
print(S.iloc[1,0])
print(S.loc[1,0])
print(S[0:3])
print(S.iloc[1:3,0:1])
X=[1,3,6,4,9,8,6]
X=pd.DataFrame(X)#由列表创建数据框
print(X)
print(X.loc[1])#默认索引为0,1,2,3,4,由索引号(下标)引用元素
print(X[0])
print(X.iloc[1,0])

4、验证以下代码,并将结果附截图
weight=[88,77,67,66,83,68,79]
df=pd.DataFrame(weight,columns=['weight'],index=['A','C','B','D','E','F','G'])
df
print(df.loc['A'])#用索引引用一个元素
print(df.iloc[0,:])
df['weight2']=df['weight']*2;df#增加数据框列
df['weight2']
df.iloc[:,1]
del df['weight2'];df#删除数据框列
df.sort_index()#按索引index排序
df.sort_values(by='weight')#按weight排序

5、验证以下代码,并将结果附截图
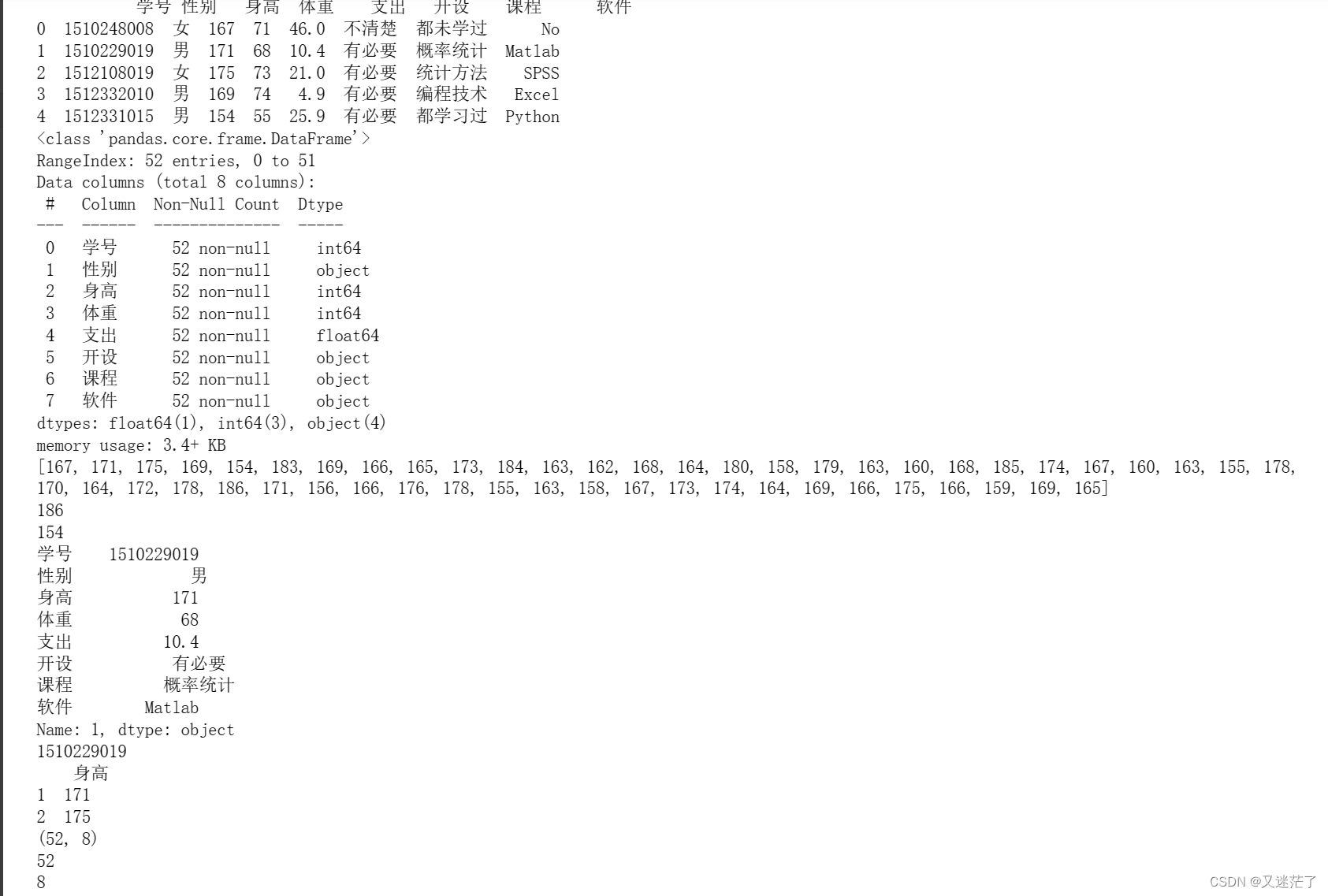
import pandas as pd
datacsv=pd.read_csv(r"exp_data\Bsdata.csv")
# Bsdata.csv文件是研究生开课信息调查表从2600名学生按2%抽样52名调查情况
#r表示当前路径,文件可以从超星下载
print(datacsv.head())
#用pandas读取csv文件实例
datacsv.info()#输出结构信息
h=list(datacsv.身高)
print(h)
print(datacsv.身高.max())
print(datacsv.身高.min())
print(datacsv.loc[1])
print(datacsv.iloc[1,0])
print(datacsv.iloc[1:3,2:3])
print(datacsv.shape) #显示数据框的行数和列数
print(datacsv.shape[0]) #数据框行数
print(datacsv.shape[1]) #数据框列数
6、验证以下代码,并将结果附截图,销售流水记录tmp.csv文件可在超星上下载。
import pandas as pd
datacsv=pd.read_csv(r'销售流水记录tmp.csv')
print(len(datacsv))
datacsv.info()
datacsv.head()
7、验证以下代码,并将结果附截图。
datacsv = pd.read_csv(r'销售流水记录tmp.csv', index_col=[0,1],low_memory=False,encoding='gb18030')#读取指定列,1,2列为索引
datacsv.info()

8、验证以下代码,并将结果附截图。
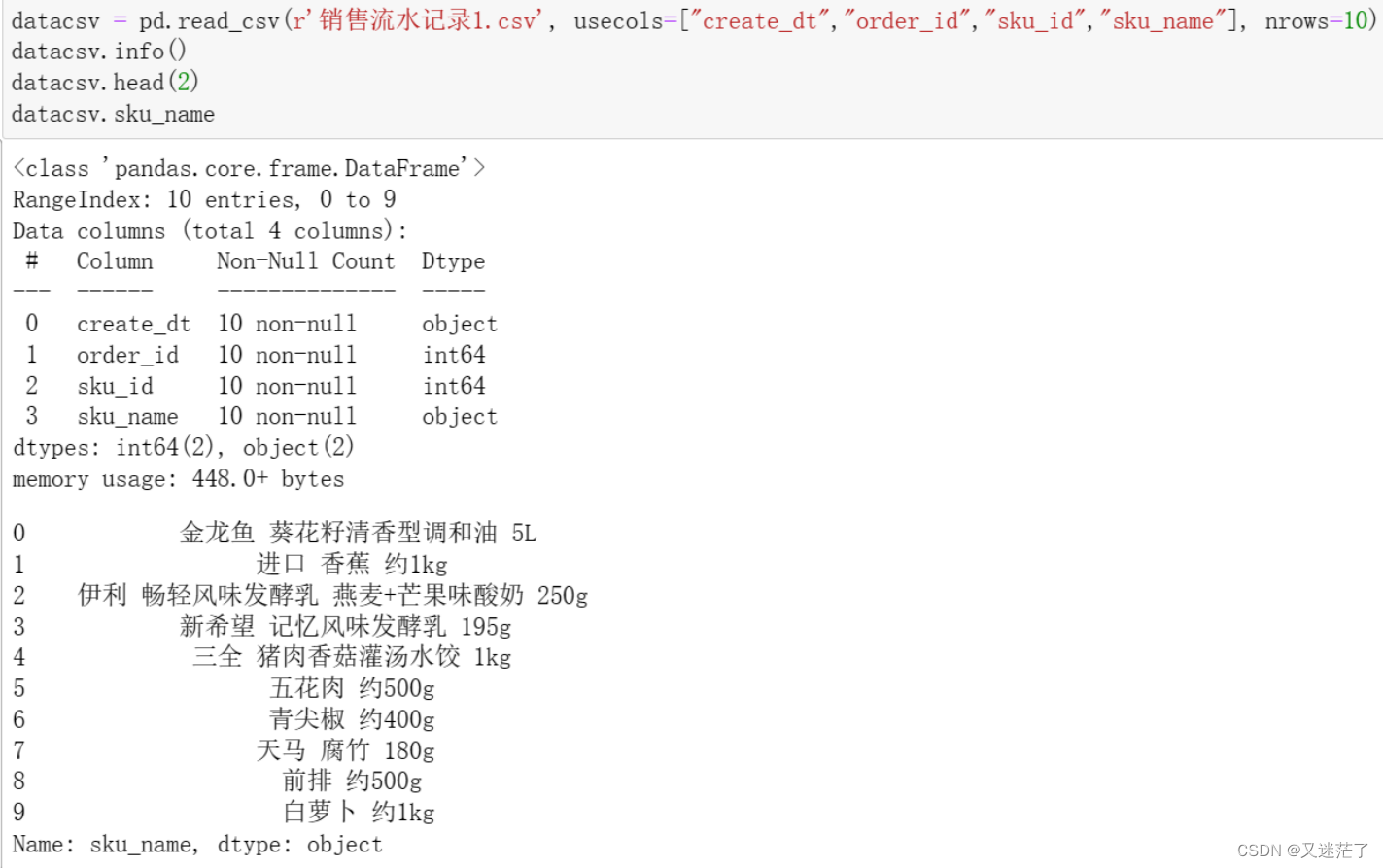
datacsv = pd.read_csv(r'销售流水记录tmp.csv', usecols=["create_dt","order_id","sku_id","sku_name"], nrows=10)
datacsv.info()
datacsv.head(2)
datacsv.sku_name
9、验证以下代码,并将结果附截图,people.csv可在超星上下载。
import pandas as pd
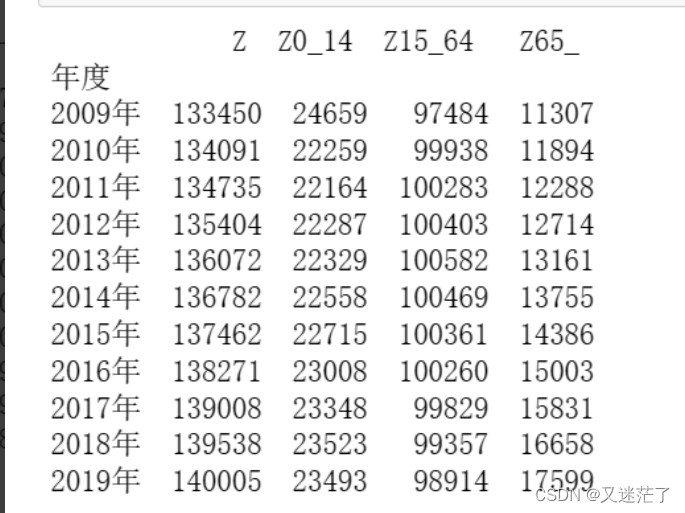
datacsv=pd.read_csv(r'people.csv',names=["年度","Z","Z0_14","Z15_64","Z65_"],header=None,skiprows=1,index_col=0)#指定列标题
#"年度","Z","Z0_14","Z15_64","Z65_"为列标题,skiprows表示跳过第1行,index_col=0年度(第1列)作为时间序列索引,绘图作为x周
print(datacsv)
datacsv.columns.tolist()

10、利用people.csv文件验证以下代码,并将结果附截图
print(datacsv[datacsv['年度']>'2008'])#提取年度大于2008年的数据
print(datacsv[(datacsv['年度']>'2008')&(datacsv['年度']<'2018')])
#逻辑运算符与、或用&、|表示
2.1 pandas工具包绘图
pandas包学习网址:User Guide — pandas 2.2.1 documentation
1、读取people.csv文件,指定列标题为"年度","Z","Z0_14","Z15_64","Z65_",利用pandas绘制年度与年末总人口折线图,并附截图,参考代码如下:
2、利用pandas绘制年度与年末总人口、0-14岁人口折线图,并附截图,参考代码如下:
3、利用pandas绘制年度与各年龄阶段人口变化折线对比图,并附截图,参考代码如下:
4、利用pandas绘制年度与各年龄阶段人口变化对比复式柱状图,并附截图,参考代码如下:

5、提取csv文件Bsdata.csv中的身高和体重,利用DataFrame.plot绘制折线图和散点图。
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.family']=['STSong']#设置汉字字体
datacsv=pd.read_csv(r"Bsdata.csv")
datacsv["身高"].plot()#折线图
datacsv["体重"].plot(color="r")#折线图
datacsv.plot.scatter(x="身高",y="体重",color="r")#散点图

6、提取csv文件Bsdata.csv中的体重,利用DataFrame.plot绘制直方图。
datacsv["体重"].hist(color="r")

7、提取csv文件Bsdata.csv的开设情况,利用DataFrame.plot绘制开设统计分类柱状图。
T=datacsv.开设.value_counts()#针对分类数据或定性数据统计
T.plot(kind='bar')

实 验 结 果 及 分 析:
- 读取无人售货机数据
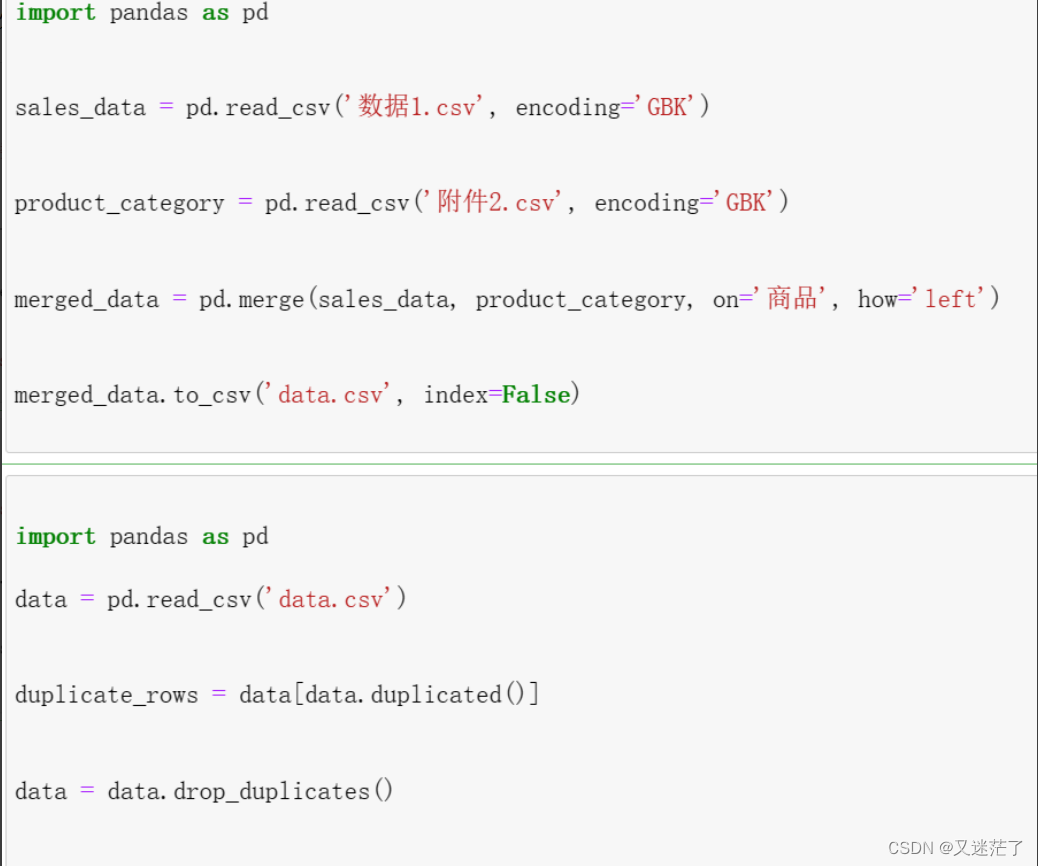
在商场不同地点安放了5台自动售货机,编号分别为A、B、C、D、E。数据1提供了从2017年1月1日至2017年12月31日每台自动售货机的商品销售数据,数据2提供了商品的分类。现在要对两个表格中的数据进行合并。
- 使用pandas中的read_csv函数分别读取数据。
- 使用pandas中的merge函数或者join方法进行数据合并
- 保存合并后的结果


- 对1中合并的数据进行数据校验、清洗,如重复值校验与处理、异常值校验与处理、缺失值校验与处理。对每一步的操作都做出说明分析。
- 查找重复记录并进行删除
- 查找异常数据,并在箱线图中绘制处理,最后对异常数据进行删除
- 查找缺失值并进行处理(删除、填充等)。
- 保存处理后的数据

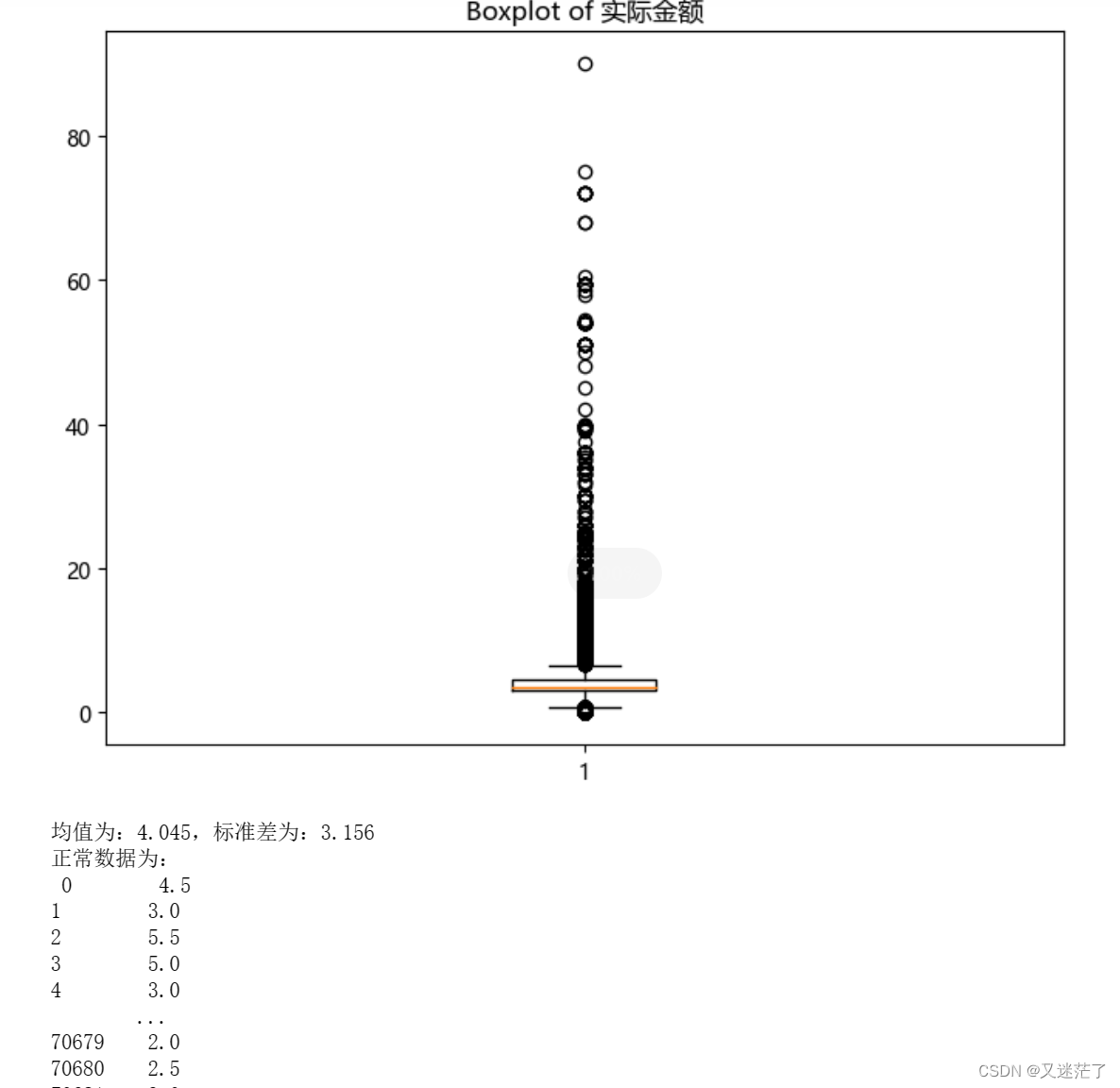
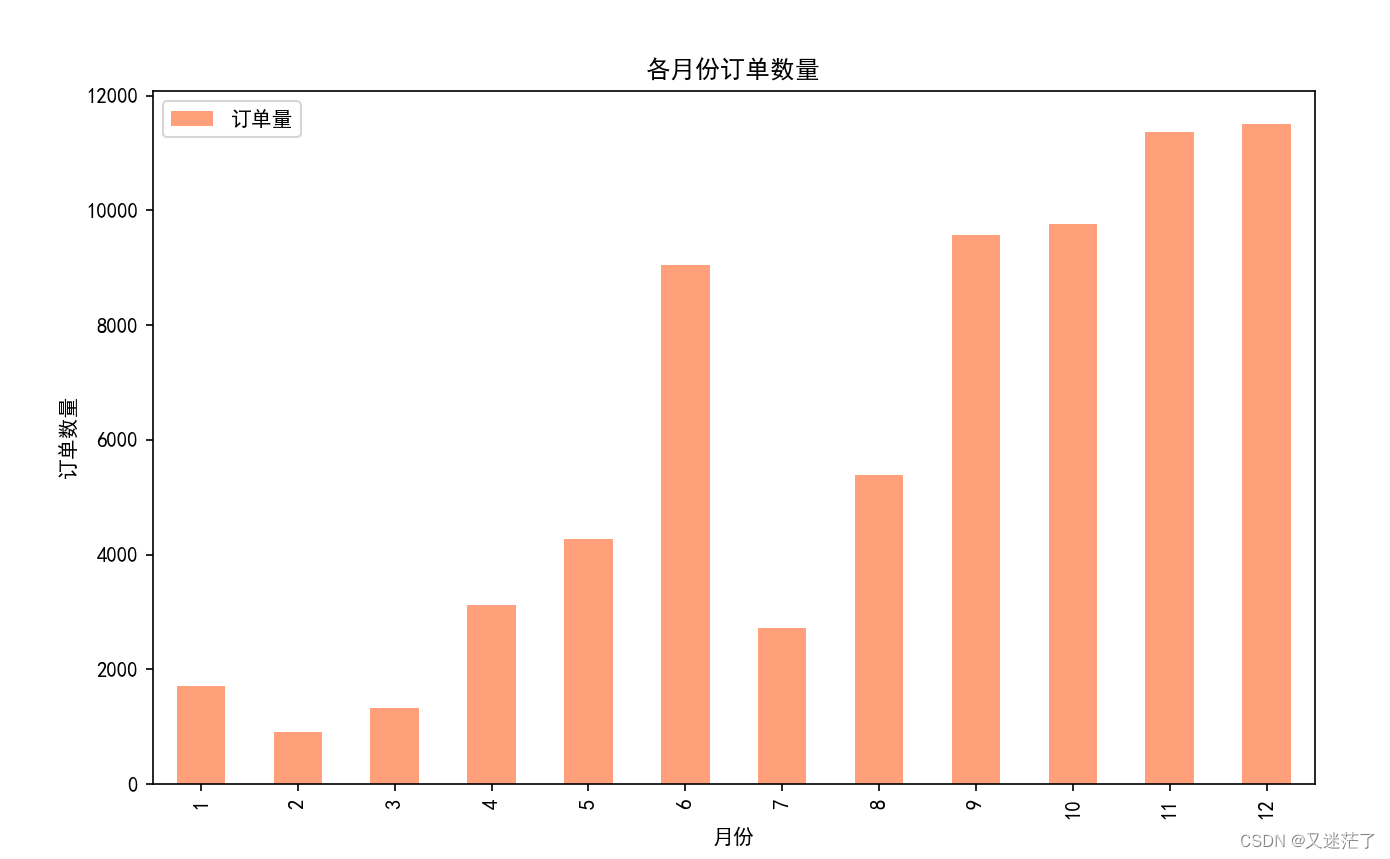
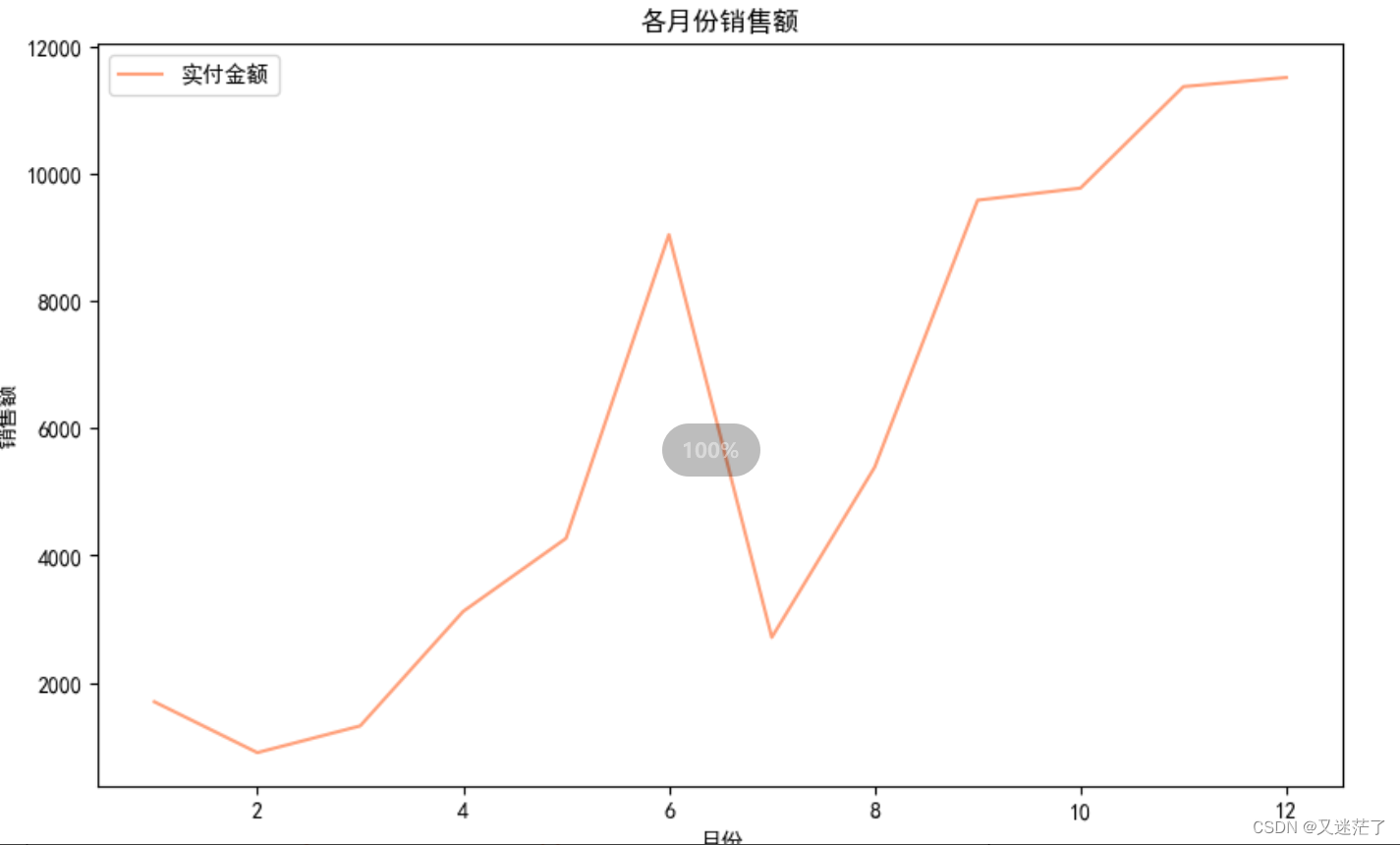
- 针对数据1
- 绘制出每个月的订单量的柱状图,用pandas进行绘图展示(要求添加标题、X轴和Y轴名称)

- 绘制出每个月的销售额变化情况折线图,用pandas进行绘图展示(要求添加标题、X轴和Y轴名称)

- 绘制出A类自动售货机中商品名称为”怡宝纯净水”的商品,12个月中每个月的订单量饼图,用pandas进行绘图展示(要求添加标题、饼图按照订单量进行排序展示)


- 对五类自动售货机的实付金额数据,分别绘制出箱线图。