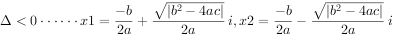零 项目背景/原理/技术栈
1.介绍boost准标准库

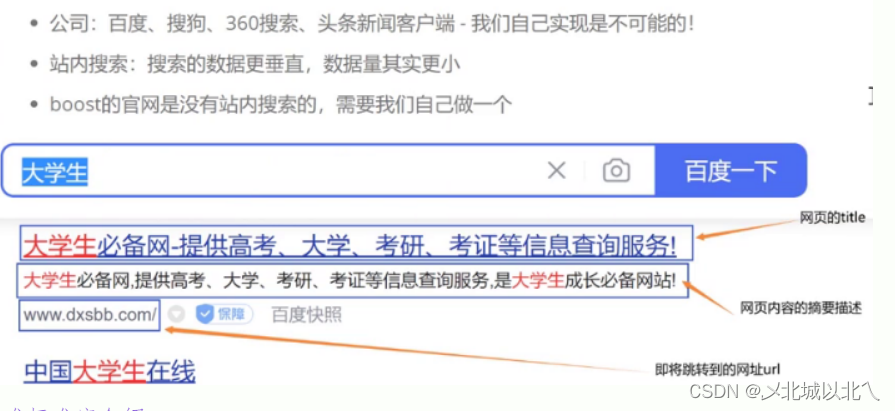
2.项目实现效果
3.搜索引擎宏观架构图
这是一个基于Web的搜索服务架构

该架构优点:
- 客户端-服务器模型:采用了经典的客户端-服务器模型,用户通过客户端与服务器交互,有助于集中管理和分散计算。
- 简单的用户界面:客户端似乎很简洁,用户通过简单的HTTP请求与服务端交互,易于用户操作。
- 搜索引擎功能:服务器端的搜索器能够接收查询请求,从数据存储中检索信息,这是Web搜索服务的核心功能。
- 数据存储:有专门的存储系统用于存放数据文件(如HTML文件),有助于维护数据的完整性和持久性。
- 模块分离:搜索器、存储和处理请求的模块被分开,这有助于各模块独立更新和维护.
该架构不足:
- 单一服务器瓶颈:所有请求似乎都经过一个中心服务器处理,这可能会导致瓶颈,影响扩展性和可用性。
- 缺乏负载均衡:在架构图中没有显示负载均衡系统,当大量并发请求到来时可能会影响性能。
- 没有明确的缓存策略:对于频繁搜索的内容,缓存可以显著提高响应速度,降低服务器压力,架构图中没有体现出缓存机制。
- 可靠性和冗余性:没有看到备份服务器或数据复制机制,这对于数据的安全性和服务的持续可用性非常重要。
- 安全性:架构图中未展示任何安全措施,例如SSL加密通信、防火墙、入侵检测系统等。
4.搜索过程的原理~正排,倒排索引


5.技术栈和项目环境,工具
技术栈:C/C++ C++11 STL boost准标准库 JsonCPP cppjieba cpp-httplib
html css js jQuery Ajax
项目环境:Centos7 华为云服务器 gcc/g++/makefile Vscode
一 Paser数据清洗,获取数据源模块
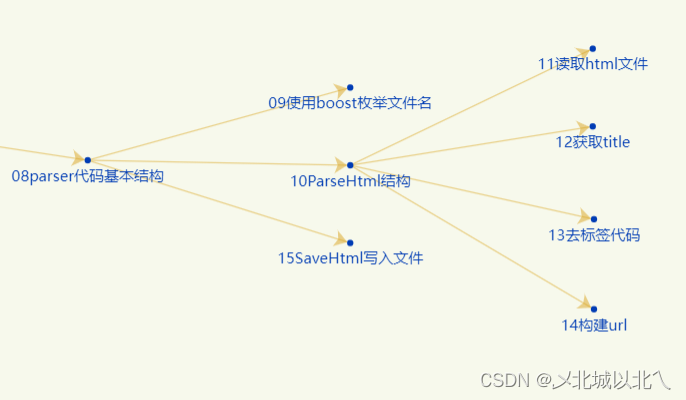
const std::string src_path = "data/input/";
const std::string output_file = "data/output/dest.txt";class DocInfo
{
public:
std::string _title;
std::string _content;
std::string _url;
};Paser模块主逻辑
int main()
{
std::vector<std::string> files_list;
// 第一步 把搜索范围src_path内的所有html的路径+文件名放到 files_list中
if (!EnumFileName(src_path, &files_list))
{
lg(_Error,"%s","enum filename err!");
exit(EnumFileNameErr);
}
// 第二步 将files_list中的文件打开,读取并解析为DocInfo后放到 web_documents中
std::vector<DocInfo> html_documents;
if (!ParseHtml(files_list, &html_documents))
{
lg(_Error,"%s","parse html err!");
exit(ParseHtmlErr);
}
// 第三步 将web_documents的信息写入到 output_file文件中, 以\3为每个文档的分隔符
if (!SaveHtml(html_documents, output_file))
{
lg(_Error,"%s","save html err!");
exit(SaveHtmlErr);
}
}-
枚举文件:从给定的源路径(
src_path)中枚举所有HTML文件,并将它们的路径和文件名放入files_list中。 -
解析HTML:读取
files_list中的每个文件,解析它们为DocInfo对象(可能包含标题、URL、正文等元素),然后存储到html_documents向量中。 -
保存文档:将
html_documents中的文档信息写入到指定的输出文件output_file中,文档之间用\3(ASCII码中的End-of-Text字符)分隔。
EnumFileName
bool EnumFileName(const std::string &src_path, std::vector<std::string> *files_list)
{
namespace fs = boost::filesystem;
fs::path root_path(src_path);
if (!fs::exists(root_path)) // 判断路径是否存在
{
lg(_Fatal,"%s%s",src_path.c_str()," is not exist");
return false;
}
// 定义一个空迭代器,用来判断递归是否结束
fs::recursive_directory_iterator end;
// 递归式遍历文件
for (fs::recursive_directory_iterator it(src_path); it != end; it++)
{
if (!fs::is_regular(*it))
continue; // 保证是普通文件
if (it->path().extension() != ".html")
continue; // 保证是.html文件
files_list->push_back(it->path().string()); // 插入的都是合法 路径+.html文件名
}
return true;
}ParseHtml
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo> *html_documents)
{
for (const std::string &html_file_path : files_list)
{
// 第一步 遍历files_list,根据路径+文件名,读取html文件内容
std::string html_file;
if (!ns_util::FileUtil::ReadFile(html_file_path, &html_file))
{
lg(_Error,"%s","ReadFile err!");
continue;
}
DocInfo doc_info;
// 第二步 解析html文件,提取title
if (!ParseTitle(html_file, &doc_info._title))
{
lg(_Error,"%s%s","ParseTitle err! ",html_file_path.c_str());
continue;
}
// 第三步 解析html文件,提取content(去标签)
if (!ParseContent(html_file, &doc_info._content))
{
lg(_Error,"%s","ParseContent err!");
continue;
}
// 第四步 解析html文件,构建url
if (!ParseUrl(html_file_path, &doc_info._url))
{
lg(_Error,"%s","ParseUrl err!");
continue;
}
// 解析html文件完毕,结果都保存到了doc_info中
// ShowDcoinfo(doc_info);
html_documents->push_back(std::move(doc_info)); // 尾插会拷贝,效率不高,使用move
}
lg(_Info,"%s","ParseHtml success!");
return true;
}1.ReadFile
class FileUtil
{
public:
static bool ReadFile(const std::string &file_path, std::string *out)
{
std::ifstream in(file_path, std::ios::in); // 以输入方式打开文件
if (!in.is_open())
{
lg(_Fatal,"%s%s%s","ReadFile:",file_path.c_str()," open err!");
return false;
}
std::string line;
while (std::getline(in, line))
{
*out += line;
}
in.close();
return true;
}
};2.ParseTitle
static bool ParseTitle(const std::string &html_file, std::string *title)
{
size_t left = html_file.find("<title>");
if (left == std::string::npos)
return false;
size_t right = html_file.find("</title>");
if (right == std::string::npos)
return false;
int begin = left + std::string("<title>").size();
int end = right;
// 截取[begin,end-1]内的子串就是标题内容
if (end-begin<0)
{
lg(_Error,"%s%s%s","ParseTitle:",output_file.c_str(),"has no title");
//std::cerr << "ParseTitle:" << output_file << "has no title" << std::endl;
return false;
}
std::string str = html_file.substr(begin, end - begin);
//std::cout << "get a title: " << str << std::endl;
*title = str;
return true;
}3.ParseContent
static bool ParseContent(const std::string &html_file, std::string *content)
{
// 利用简单状态机完成去标签工作
enum Status
{
Lable,
Content
};
Status status = Lable;
for (char ch : html_file)
{
switch (status)
{
case Lable:
if (ch == '>')
status = Content;
break;
case Content:
if (ch == '<')
status = Lable;
else
{
// 不保留html文本中自带的\n,防止后续发生冲突
if (ch == '\n')
ch = ' ';
content->push_back(ch);
}
break;
default:
break;
}
}
return true;
}4.ParseUrl
static bool ParseUrl(const std::string &html_file_path, std::string *url)
{
std::string url_head = "https://www.boost.org/doc/libs/1_84_0/doc/html";
std::string url_tail = html_file_path.substr(src_path.size());
*url = url_head + "/" + url_tail;
return true;
}
SaveHtml
//doc_info内部用\3分隔,doc_info之间用\n分隔
bool SaveHtml(const std::vector<DocInfo> &html_documents, const std::string &output_file)
{
const char sep = '\3';
std::ofstream out(output_file, std::ios::out | std::ios::binary|std::ios::trunc);
if (!out.is_open())
{
lg(_Fatal,"%s%s%s","SaveHtml:",output_file.c_str()," open err!");
return false;
}
for(auto &doc_info:html_documents)
{
std::string outstr;
outstr += doc_info._title;
outstr += sep;
outstr += doc_info._content;
outstr += sep;
outstr+= doc_info._url;
outstr+='\n';
out.write(outstr.c_str(),outstr.size());
}
out.close();
lg(_Info,"%s","SaveHtml success!");
return true;
}二 Index建立索引模块
三 Searcher搜索模块
四 http_server模块
const std::string input = "data/output/dest.txt";//从input里读取数据构建索引
const std::string root_path = "./wwwroot";
int main()
{
std::unique_ptr<ns_searcher::Searcher> searcher(new ns_searcher::Searcher());
searcher->SearcherInit(input);
httplib::Server svr;
svr.set_base_dir(root_path.c_str()); // 设置根目录
// 重定向到首页
svr.Get("/", [](const httplib::Request &, httplib::Response &rsp)
{ rsp.set_redirect("/home/LZF/boost_searcher_project/wwwroot/index.html"); }); // 重定向到首页
svr.Get("/s",[&searcher](const httplib::Request &req,httplib::Response &rsp)
{
if(!req.has_param("word"))
{
rsp.set_content("无搜索关键字!","test/plain,charset=utf-8");
return;
}
std::string json_str;
std::string query = req.get_param_value("word");
std::cout<<"用户正在搜索: "<<query<<std::endl;
searcher->Search(query,&json_str);
rsp.set_content(json_str,"application/json");
});
svr.listen("0.0.0.0", 8800);
}
五 前端模块
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<script src="http://code.jquery.com/jquery-2.1.1.min.js"></script>
<title>boost 搜索引擎</title>
<style>
/* 去掉网页中的所有的默认内外边距,html的盒子模型 */
* {
/* 设置外边距 */
margin: 0;
/* 设置内边距 */
padding: 0;
}
/* 将我们的body内的内容100%和html的呈现吻合 */
html,
body {
height: 100%;
}
/* 类选择器.container */
.container {
/* 设置div的宽度 */
width: 800px;
/* 通过设置外边距达到居中对齐的目的 */
margin: 0px auto;
/* 设置外边距的上边距,保持元素和网页的上部距离 */
margin-top: 15px;
}
/* 复合选择器,选中container 下的 search */
.container .search {
/* 宽度与父标签保持一致 */
width: 100%;
/* 高度设置为52px */
height: 52px;
}
/* 先选中input标签, 直接设置标签的属性,先要选中, input:标签选择器*/
/* input在进行高度设置的时候,没有考虑边框的问题 */
.container .search input {
/* 设置left浮动 */
float: left;
width: 600px;
height: 50px;
/* 设置边框属性:边框的宽度,样式,颜色 */
border: 1px solid black;
/* 去掉input输入框的有边框 */
border-right: none;
/* 设置内边距,默认文字不要和左侧边框紧挨着 */
padding-left: 10px;
/* 设置input内部的字体的颜色和样式 */
color: #CCC;
font-size: 14px;
}
/* 先选中button标签, 直接设置标签的属性,先要选中, button:标签选择器*/
.container .search button {
/* 设置left浮动 */
float: left;
width: 150px;
height: 52px;
/* 设置button的背景颜色,#4e6ef2 */
background-color: #4e6ef2;
/* 设置button中的字体颜色 */
color: #FFF;
/* 设置字体的大小 */
font-size: 19px;
font-family:Georgia, 'Times New Roman', Times, serif;
}
.container .result {
width: 100%;
}
.container .result .item {
margin-top: 15px;
}
.container .result .item a {
/* 设置为块级元素,单独站一行 */
display: block;
/* a标签的下划线去掉 */
text-decoration: none;
/* 设置a标签中的文字的字体大小 */
font-size: 20px;
/* 设置字体的颜色 */
color: #4e6ef2;
}
.container .result .item a:hover {
text-decoration: underline;
}
.container .result .item p {
margin-top: 5px;
font-size: 16px;
font-family:'Lucida Sans', 'Lucida Sans Regular', 'Lucida Grande', 'Lucida Sans Unicode', Geneva, Verdana, sans-serif;
}
.container .result .item i{
/* 设置为块级元素,单独站一行 */
display: block;
/* 取消斜体风格 */
font-style: normal;
color: green;
}
</style>
</head>
<body>
<div class="container">
<div class="search">
<input type="text" value="请输入搜索关键字">
<button onclick="Search()">搜索一下</button>
</div>
<div class="result">
</div>
</div>
<script>
function Search(){
let query = $(".container .search input").val();
console.log("query = " + query);
$.get("/s", {word: query}, function(data){
console.log(data);
BuildHtml(data);
});
}
function BuildHtml(data){
let result_lable = $(".container .result");
result_lable.empty();
for( let elem of data){
let a_lable = $("<a>", {
text: elem.title,
href: elem.url,
target: "_blank"
});
let p_lable = $("<p>", {
text: elem.desc
});
let i_lable = $("<i>", {
text: elem.url
});
let div_lable = $("<div>", {
class: "item"
});
a_lable.appendTo(div_lable);
p_lable.appendTo(div_lable);
i_lable.appendTo(div_lable);
div_lable.appendTo(result_lable);
}
}
</script>
</body>
</html>