为什么要用线程池?
1、线程属于稀缺资源,它的创建会消耗大量系统资源
2、线程频繁地销毁,会频繁地触发GC机制,使系统性能降低
3、多线程并发执行缺乏统一的管理与监控
线程池的使用
线程池的创建使用可通过Executors类来完成,它提供了创建线程池的常用方法。
·newFixedThreadPool
·newSingleThreadExecutor
·newCachedThreadPool
·newScheduledThreadPool
用例
public static void main(String[] args) {
test();
}
public static void test() {
ExecutorService service = Executors.newFixedThreadPool(3);
for (int i = 0; i < 30; i++) {
// System.out.println("task name:addition_isCorrect");
service.execute(new MyRunnable("executor-" + i));
}
}
public static class MyRunnable implements Runnable {
String name;
public MyRunnable(String name) {
this.name = name;
}
@Override
public void run() {
try {
Thread.sleep(3000);
System.out.println( );
System.out.println("time = " + System.currentTimeMillis() + "--task name:" + name + "---thread name:" + Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}time = 1711718334177--task name:executor-1---thread name:pool-1-thread-2
time = 1711718334177--task name:executor-0---thread name:pool-1-thread-1
time = 1711718334177--task name:executor-2---thread name:pool-1-thread-3
time = 1711718337191--task name:executor-5---thread name:pool-1-thread-3
time = 1711718337191--task name:executor-4---thread name:pool-1-thread-1
time = 1711718337191--task name:executor-3---thread name:pool-1-thread-2
time = 1711718340193--task name:executor-6---thread name:pool-1-thread-3
time = 1711718340193--task name:executor-7---thread name:pool-1-thread-1
time = 1711718340201--task name:executor-8---thread name:pool-1-thread-2
time = 1711718343204--task name:executor-10---thread name:pool-1-thread-1
time = 1711718343204--task name:executor-9---thread name:pool-1-thread-3
time = 1711718343204--task name:executor-11---thread name:pool-1-thread-2
time = 1711718346216--task name:executor-12---thread name:pool-1-thread-1
time = 1711718346216--task name:executor-14---thread name:pool-1-thread-2
time = 1711718346216--task name:executor-13---thread name:pool-1-thread-3
time = 1711718349226--task name:executor-17---thread name:pool-1-thread-3
time = 1711718349226--task name:executor-15---thread name:pool-1-thread-1
time = 1711718349226--task name:executor-16---thread name:pool-1-thread-2
time = 1711718352241--task name:executor-19---thread name:pool-1-thread-1
time = 1711718352241--task name:executor-20---thread name:pool-1-thread-2
time = 1711718352241--task name:executor-18---thread name:pool-1-thread-3
time = 1711718355242--task name:executor-21---thread name:pool-1-thread-1
time = 1711718355242--task name:executor-22---thread name:pool-1-thread-2
time = 1711718355254--task name:executor-23---thread name:pool-1-thread-3
time = 1711718358245--task name:executor-24---thread name:pool-1-thread-1
time = 1711718358245--task name:executor-25---thread name:pool-1-thread-2
time = 1711718358261--task name:executor-26---thread name:pool-1-thread-3
time = 1711718361250--task name:executor-27---thread name:pool-1-thread-1
time = 1711718361250--task name:executor-28---thread name:pool-1-thread-2
time = 1711718361266--task name:executor-29---thread name:pool-1-thread-3
通过打印出来的日志可以看到,所有任务都在名为name:pool-1-thread-1、pool-1-thread-2、pool-1-thread-3的线程中运行,这与我们设置的线程池大小相符。在这个线程池中,前面三个任务优先执行,后面的任务都在等待。
如果把ExecutorService service = Executors.newFixedThreadPool(3);改为ExecutorService service = Executors.newCachedThreadPool();
time = 1711718860800--task name:executor-0---thread name:pool-1-thread-1
time = 1711718860823--task name:executor-23---thread name:pool-1-thread-24
time = 1711718860825--task name:executor-2---thread name:pool-1-thread-3
time = 1711718860826--task name:executor-25---thread name:pool-1-thread-26
time = 1711718860829--task name:executor-8---thread name:pool-1-thread-9
time = 1711718860825--task name:executor-26---thread name:pool-1-thread-27
time = 1711718860825--task name:executor-7---thread name:pool-1-thread-8
time = 1711718860825--task name:executor-20---thread name:pool-1-thread-21
time = 1711718860825--task name:executor-13---thread name:pool-1-thread-14
time = 1711718860823--task name:executor-22---thread name:pool-1-thread-23
time = 1711718860828--task name:executor-1---thread name:pool-1-thread-2
time = 1711718860828--task name:executor-14---thread name:pool-1-thread-15
time = 1711718860828--task name:executor-19---thread name:pool-1-thread-20
time = 1711718860828--task name:executor-29---thread name:pool-1-thread-30
time = 1711718860828--task name:executor-24---thread name:pool-1-thread-25
time = 1711718860828--task name:executor-5---thread name:pool-1-thread-6
time = 1711718860828--task name:executor-6---thread name:pool-1-thread-7
time = 1711718860828--task name:executor-4---thread name:pool-1-thread-5
time = 1711718860827--task name:executor-10---thread name:pool-1-thread-11
time = 1711718860827--task name:executor-9---thread name:pool-1-thread-10
time = 1711718860827--task name:executor-3---thread name:pool-1-thread-4
time = 1711718860827--task name:executor-12---thread name:pool-1-thread-13
time = 1711718860827--task name:executor-15---thread name:pool-1-thread-16
time = 1711718860827--task name:executor-18---thread name:pool-1-thread-19
time = 1711718860827--task name:executor-27---thread name:pool-1-thread-28
time = 1711718860826--task name:executor-17---thread name:pool-1-thread-18
time = 1711718860826--task name:executor-16---thread name:pool-1-thread-17
time = 1711718860826--task name:executor-11---thread name:pool-1-thread-12
time = 1711718860826--task name:executor-21---thread name:pool-1-thread-22
time = 1711718860826--task name:executor-28---thread name:pool-1-thread-29可以看到,一瞬间任务就都执行完了,可以想象出,newCachedThread()方式创建的线程池,执行任务时会创建足够多的线程。
下面我们看一下它们是如何被创建出来的
ExecutorService service = Executors.newFixedThreadPool(3);
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
..........构造函数..........
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
构造方法参数说明:
corePoolSize:核心线程数,除非设置核心线程超时-allowCoreThreadTimeOut,否则线程会一直存活在线程池中,即使线程池处于空闲状态。
maximumPoolSize:线程池中允许存在的最大线程数。
workQueue:工作队列,当核心线程都处于繁忙状态时,将任务提交到工作队列中。如果工作队列也超过了容量,会去尝试创建一个非核心线程执行任务。
keepAliveTime:非核心线程处理空闲状态最长时间,超过该值线程将会被回收。
threadFactory:线程工厂类,用于创建线程。
RejectedExecutionHandler:工作队列饱和策略,比如丢弃,抛出异常等。
线程池创建完成后,可通过execute方法提交任务,线程池根据当期运行状态和特定参数对任务进行处理。
线程池执行流程
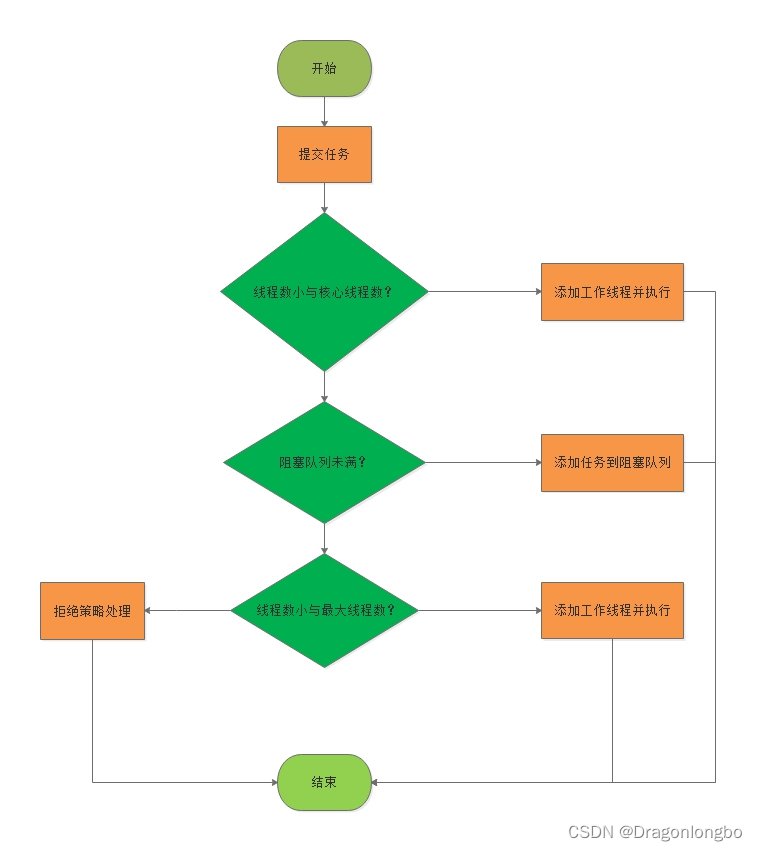
| 线程池类型 | 核心线程数 | 最大线程数 | 非核心线程空闲时间 | 工作队列 |
| newFixedThreadPool | specific | specific | 0 | LinkedBlockingQueue |
| newSingleThreadExecutor | 1 | 1 | 0 | LinkedBlockingQueue |
| newCachedThreadPool | 0 | Integer.MAX_VALUE | 60S | SynchronousQueue |
| newScheduledThreadPool | specific | INteger.MAX_VALUE | 0 | DelayedWorkQueue |
specific表示使用者传入的固定值。
阻塞队列
为什么要用阻塞队列?
阻塞队列常用于生产者-消费者模型,任务的添加是生产者,任务的调度执行是消费者,他们通常在不同的线程中,如果使用非阻塞队列,那么就需要使用额外的处理同步策略和线程间唤醒策略。比如当前任务队列为空时,消费者线程取元素会被阻塞,当有新的任务添加到队列中时,需要唤醒消费者线程处理任务。
阻塞队列的实现就是在添加元素和获取元素时设置了各种锁操作。
同时,非核心线程是根据阻塞队列的容量进行创建的。具体点就是当阻塞队列未满时,并不会创建非核心线程,而是将任务继续添加到阻塞队列后面等待核心线程执行。
LinkedBlockingQueue:内部使用链表实现的阻塞队列,默认构造函数使用Integer.MAX_VALUE作为容量,另外可通过带capacity参数的构造函数限制容量,使用Executors工具类创建的线程池容量均为Integer.MAX.
SynchronousQueue:容量为0,每当有任务添加进来时会立即触发消费,即每次插入操作一定伴随一个移除操作,反之亦然。
DelayedWorkQueue:用数组实现的,默认容量是16,支持动态扩容,可对延迟任务进行排序,类似优先级队列,搭配ScheduledThreadPoolExecutor可定时或延迟任务。
ArrayBlockingQueue:它不在上述线程池体系中,是基于数组实现,容量固定且不可扩容。
使用场景:
newFixedThreadPool:它的特点是没有非核心线程,这意味着即使任务过多也不会创建新的线程,即使任务闲置也仍然保留一定数量的核心线程,等待队列无线,性能相对稳定,适用于长期有任务要执行,同时任务量也不大的场景。
newSingleThreadExecutor:相当于线程数量为1的newFixedThreadPool,因为线程数量为1,所以适用于任务需要顺序执行的场景。
newCachedThreadPool:它的特点是没有核心线程,非核心线程无线,可短时间内处理无限多的任务,但实际上创建线程十分消耗资源,过多的创建线程可能导致oom,同时该线程池还设置了超时时间,还涉及到线程资源的释放,大量任务并行时性能不稳定,少量任务并行且后续不再执行其他任务的场景可用。
newScheduledThreadPool:通常用于定时或延迟任务。
实际项目开发过程中,不建议直接使用Executors提供的发放创建线程池,如果任务规模,响应时间大致确定,应根据实际需求通过ThreadPoolExecutor各种构造函数手动创建,自由控制线程数、超时时间、阻塞队列、饱和策略等内容(默认饱和策略都是AbortPolicy即抛出异常)。
饱和策略
DiscardPolicy:将丢弃被拒绝的任务
DiscardOldestPolicy:将丢弃队列头部的任务,即先入队的任务会出队以腾出空间
AbortPolicy:抛出RejectedExecutionException异常
CallerRunsPolicy:在execute方法的调用线程中运行被拒绝的任务。
用户也可以通过实现RejectedExecutionHandler接口自定义饱和策略,并通过ThreadPoolExecutor的构造函数传入。
线程池的继承结构
Executor:基类接口,仅定义一个execute方法。
ExecutorService:继承了Executor的接口,定义了带返回值的任务提交方法submit,以及关闭线程池的shutdown方法
AbstractExecutorService:实现了ExecutorService的大部分接口,剩余shutdown与execute方法为实现
ThreadPoolExecutor:常用线程池类
ScheduledThreadPoolExecutor:定义了一系列支持延迟执行任务的线程池
ForkJoinPool:它采用分治思想,将一个任务细分为多个子任务在多线程中执行。
线程池大小选定
需要了解任务是CPU密集型还是IO密集型
CPU密集型:比如大量的计算任务,CPU占用率高,那么此时如果多开线程反而会因为CPU频繁做线程调度导致性能降低。一般建议线程数为CPU核心数+1,+1是为了防止某个核心线程阻塞或意外中断时作为候补。
IO密集型:通常指文件IO、网络IO等。线程数的选取与IO耗时和CPU耗时的比例有关,最佳线程数=CPU核数*[1+(IO耗时/CPU耗时)],之所以设置比例是为了使IO设备和CPU的利用率都达到最高。
线程池的状态
线程池的状态在整个任务处理过程中至关重要,比如添加任务时会先判断线程池是否处于运行状态,任务添加到队列后再判断运行状态,如果此时线程池已经关闭则移除任务并执行饱和策略。
RUNNING:能接收新任务,并且也能处理阻塞队列中的任务
SHUTDOWN:关闭状态,不能接受新任务,但可以处理阻塞队列中已保存的任务。
STOP:不能接受新任务,也不能处理队列中的人物,会中断正在处理任务的线程。
TIDYING:如果所有任务已经终止,workerCount为0,线程池进入该状态后会调用terminated方法进入TERMINATED状态
TERMINATED:在terminated方法执行完之后进入该状态,默认terminated方法中什么也没有做。
参考:Java线程池工作原理浅析