文章目录
- 🚀🚀🚀前言
- 一、1️⃣ CAM模块详细介绍
- 二、2️⃣CAM模块的三种融合模式
- 三、3️⃣如何添加CAM模块
- 3.1 🎓 添加CAM模块代码
- 3.2 ✨添加yolov5s_CAM.yaml文件
- 3.3 ⭐️修改yolo.py文相关文件
- 四、4️⃣实验结果
- 4.1 🎓 yolov5基准模型
- 4.2 ✨使用CAM的weight连接方式
- 4.3 ⭐️用CAM的adaptive连接方式
- 4.4 🎯用CAM的concat连接方式
- 4.5 🚀实验总结

👀🎉📜系列文章目录
【YOLOv5改进系列(1)】高效涨点----使用EIoU、Alpha-IoU、SIoU、Focal-EIOU替换CIou
【YOLOv5改进系列(2)】高效涨点----Wise-IoU详细解读及使用Wise-IoU(WIOU)替换CIOU
【YOLOv5改进系列(3)】高效涨点----Optimal Transport Assignment:OTA最优传输方法
【YOLOv5改进系列(4)】高效涨点----添加可变形卷积DCNv2
【YOLOv5改进系列(5)】高效涨点----添加密集小目标检测NWD方法
【YOLOv5改进系列(6)】高效涨点----使用DAMO-YOLO中的Efficient RepGFPN模块替换yolov5中的Neck部分
【YOLOv5改进系列(7)】高效涨点----使用yolov8中的C2F模块替换yolov5中的C3模块
【YOLOv5改进系列(8)】高效涨点----添加yolov7中Aux head 辅助训练头
🚀🚀🚀前言
CAM(上下文增强模块) 这个模块是出至于CONTEXT AUGMENTATION AND FEATURE REFINE- MENT NETWORK FOR TINY OBJECT DETECTION这篇论文,这是一个针对小目标检测的文本,提出了一种名为“上下文增强和特征细化网络”的方法。将多尺度展开卷积的特征从上到下融合注入到特征金字塔网络中,补充上下文信息。引入通道和空间特征细化机制,抑制多尺度特征融合中的冲突形成,防止微小目标淹没在冲突信息中。此外,提出了一种数据增强方法copy-reduce-paste,该方法可以增加训练过程中微小对象对损失的贡献,保证训练更加均衡。
博主也是使用该论文中的CAM模块去替换掉yolov5中的SPPF模块,在经过CAM三个不同的特征融合连接实验之后(分别是:weight, adaptive,concat),在我自己的疵点数据集上面效果非常好,尤其是使用adaptive连接方法,模型涨点非常高,提升了10个百分点。
📜论文地址:基于上下文增强和特征细化网络的微小目标检测
由于该论文没有提供代码,没有办法像之前的改进一样,直接使用别人的代码修改参数,所以这边也是观看了很多博主的代码之后,自己总结复现了一下。
一、1️⃣ CAM模块详细介绍
微小目标检测需要上下文信息。所以提出使用不同空洞卷积速率的空洞卷积来获取不同感受野的上下文信息,以丰富FPN的上下文信息;下图就是CAM的结构图,在C5上以不同的空洞卷积速率进行空洞卷积,得到不同感受野的上下文信息,卷积核大小为3×3,空洞卷积速率为1、3和5。
SPP模块:我第一次从论文中看到这个结构首先想到的就是和SPP模块比较类似,SPP的特征融合方式是:feature map首先经过一个卷积降维,然后分别进行kernel size为5, 9, 13的max polling层,最后将它们与降维之后的特征concat起来,然后再经过一个卷积将channel恢复成原来大小。

二、2️⃣CAM模块的三种融合模式
关于C5上面的三个特征融合方式有三种,(a)、(b)和(c)所示,

方法(a)和(c)分别为加权融合和拼接操作。即直接在空间维度和通道维度上添加特征映射。方法(b)是一种自适应融合方法。具体来说,假设输入的大小可以表示为(bs, C, H, W),我们可以通过卷积、拼接和Softmax操作获得(bs, 3, H, W)的空间自适应权值。三个通道一对一地对应三个输入,通过计算加权和可以将上下文信息聚合到输出。(b)的方法需要进行更多的特征处理,通过实验发现,在我自己的中小型目标疵点数据集上该方法是优于另外两种方法。
在该论文中通过消融实验验证了每种融合方法的有效性,结果如下表所示。 AP s \operatorname{AP}_{\mathrm{s}} APs、 AP m \operatorname{AP}_{\mathrm{m}} APm和 AP l \operatorname{AP}_{\mathrm{l}} APl分别定义为微小、中等和大型目标的精度。 AR s \operatorname{AR}_{\mathrm{s}} ARs、 AR m \operatorname{AR}_{\mathrm{m}} ARm、 AR l \operatorname{AR}_{\mathrm{l}} ARl分别表示小、中、大目标的召回率。由表1可以看出,(c)对微小物体的优势最大。 AP s \operatorname{AP}_{\mathrm{s}} APs和 AR s \operatorname{AR}_{\mathrm{s}} ARs均增长1.8%。方法(b)对于大中型目标改善最大。方法(a)带来的改进基本上介于两者之间。

三、3️⃣如何添加CAM模块
3.1 🎓 添加CAM模块代码
首先找到models文件夹下面找到common.py文件,在该文件中的最后一行添加CAM模块代码,添加内容如下:
class CAM(nn.Module):
def __init__(self, inc, fusion='weight'):
super().__init__()
assert fusion in ['weight', 'adaptive', 'concat'] #三种融合方式
self.fusion = fusion
self.conv1 = Conv(inc, inc, 3, 1, None, 1, 1)
self.conv2 = Conv(inc, inc, 3, 1, None, 1, 3)
self.conv3 = Conv(inc, inc, 3, 1, None, 1, 5)
self.fusion_1 = Conv(inc, inc, 1)
self.fusion_2 = Conv(inc, inc, 1)
self.fusion_3 = Conv(inc, inc, 1)
if self.fusion == 'adaptive':
self.fusion_4 = Conv(inc * 3, 3, 1)
def forward(self, x):
x1 = self.conv1(x)
x2 = self.conv2(x)
x3 = self.conv3(x)
if self.fusion == 'weight':
return self.fusion_1(x1) + self.fusion_2(x2) + self.fusion_3(x3)
elif self.fusion == 'adaptive':
fusion = torch.softmax(
self.fusion_4(torch.cat([self.fusion_1(x1), self.fusion_2(x2), self.fusion_3(x3)], dim=1)), dim=1)
x1_weight, x2_weight, x3_weight = torch.split(fusion, [1, 1, 1], dim=1)
return x1 * x1_weight + x2 * x2_weight + x3 * x3_weight
else:
return torch.cat([self.fusion_1(x1), self.fusion_2(x2), self.fusion_3(x3)], dim=1)
3.2 ✨添加yolov5s_CAM.yaml文件
这个文件你可以直接复制yolov5s.yaml文件,然后重命名为yolov5s_CAM.yaml,这里只需要修改一处地方,就是将backbone特征提取部分的最后一层SPPF模块替换成CAM模块,并且指定特征的连接方式(weight、adaptive、concat),修改内容如下:

3.3 ⭐️修改yolo.py文相关文件
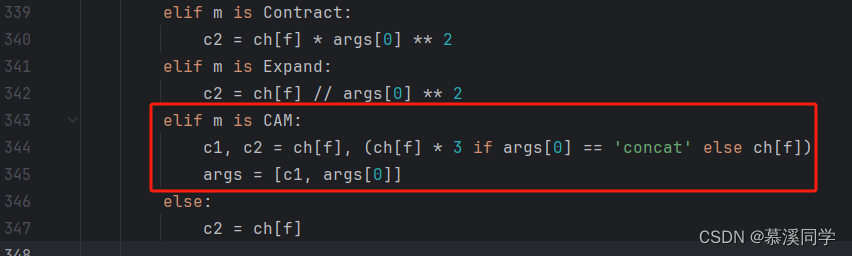
📌在models文件夹下面找到yolo.py文件,在342行添加一个CAM模块判断代码,添加如下:
elif m is CAM:
c1, c2 = ch[f], (ch[f] * 3 if args[0] == 'concat' else ch[f])
args = [c1, args[0]]
四、4️⃣实验结果
4.1 🎓 yolov5基准模型
训练结果:F1置信度分数为0.71、map@0.5=0.779;

4.2 ✨使用CAM的weight连接方式
训练结果:F1置信度分数为0.73、map@0.5=0.796;

4.3 ⭐️用CAM的adaptive连接方式
训练结果:F1置信度分数为0.73、map@0.5=0.851;

4.4 🎯用CAM的concat连接方式
训练结果:F1置信度分数为0.73、map@0.5=0.821;

4.5 🚀实验总结
我的疵点数据集是有大目标和小目标的,使用自适应的连接方式训练效果最好,map@0.5提升了将近6个百分点,其次就是concat连接方式提升效果排第二,因为我的疵点数据集小目标其实是多余大目标的,所以效果是要优于weight连接方式。