第四周笔记
一、ElasticSearch
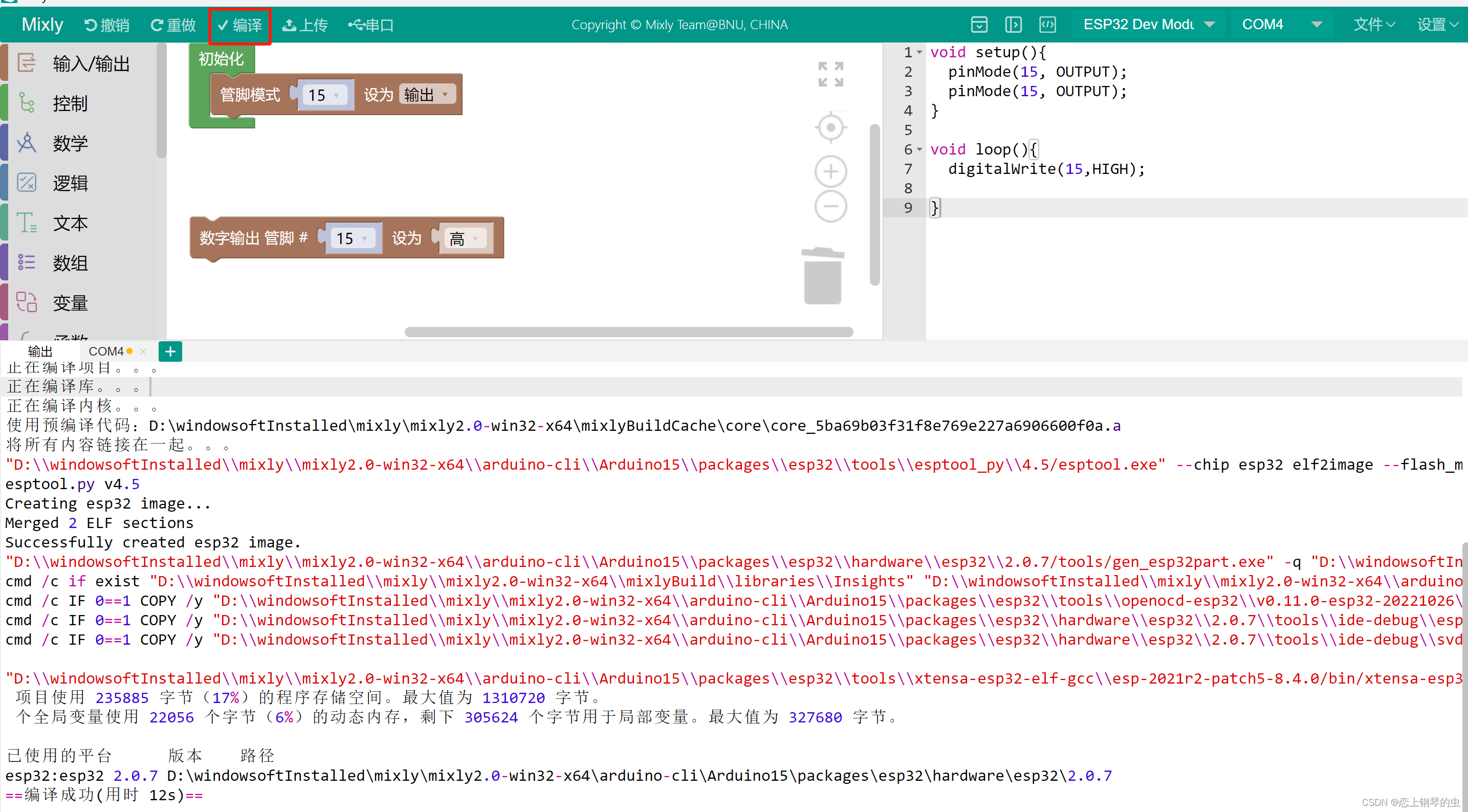
1.安装
apt-get install lrzsz
adduser -m es
创建用户组:
useradd *-m* xiaoming(用户名) *PS:追加参数-m*
passwd xiaoming(用户名)
passwd xiaoming
输入新的 UNIX 密码:
重新输入新的 UNIX 密码:
passwd:已成功更新密码
最大文件描述符数(max file descriptors)太低,需要增加至少到65535。
ulimit -Hn 65536
ulimit -Hn
最大虚拟内存区域数(max virtual memory areas)过低,需要增加至少到262144。
-
使用root权限登录到Elasticsearch所在的服务器。
-
打开sysctl.conf文件,可以使用vim或者nano等文本编辑器打开:
复制代码sudo vim /etc/sysctl.conf -
在文件末尾添加以下内容:
复制代码vm.max_map_count=262144 -
保存并关闭文件。
-
执行以下命令使配置生效:
复制代码sudo sysctl -p -
重新启动Elasticsearch:
复制代码/path/to/elasticsearch/bin/elasticsearch
curl -O 路径下载文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
sudo yum install lrzsz
压缩:
tar -zcvf 文件名 压缩路径
解压:
tar -zxvf 文件名
sudo mkdir -p /root/es/elasticsearch-7.9.3/log
sudo yum install vim
sudo chown -R qingyue:qingyue /usr/local/es/elasticsearch-7.9.3/
[超详细的ElasticSearch安装使用教程视频_哔哩哔哩_bilibili
新增PUT
PUT新增索引,已存在会报错(幂等)
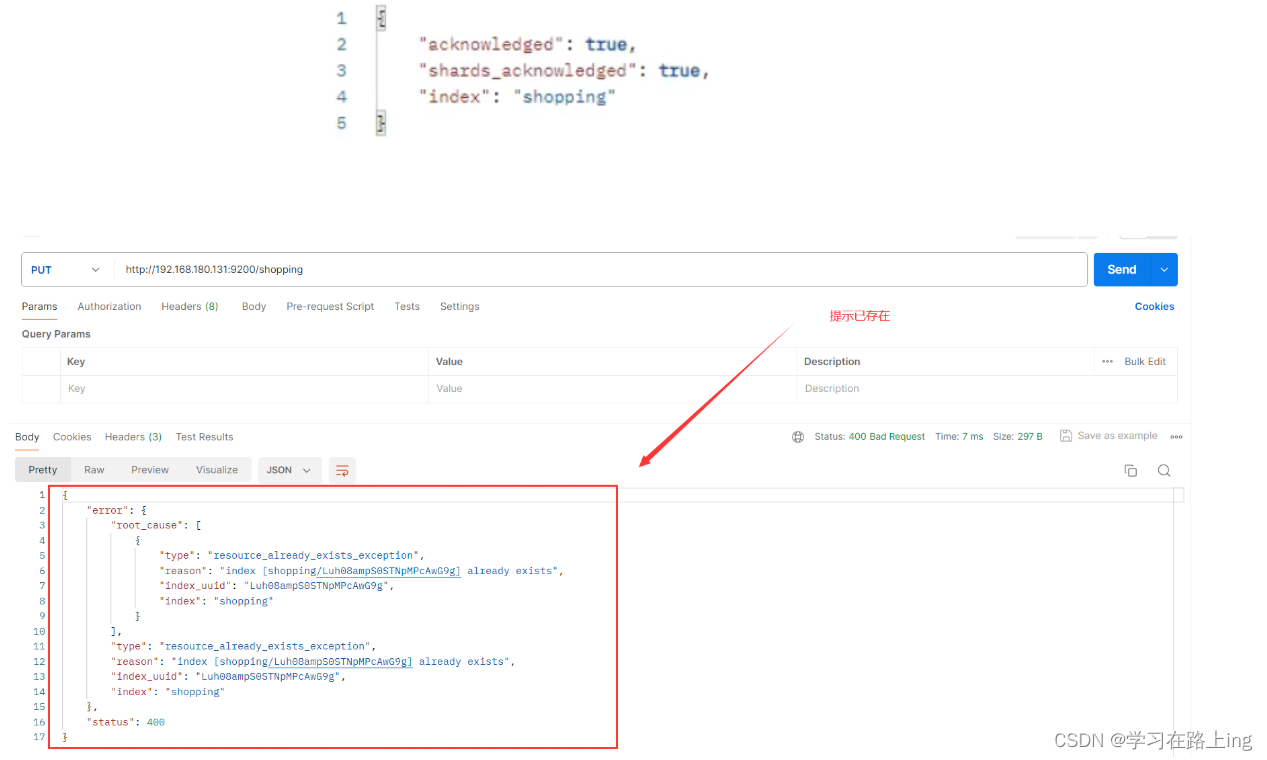
查询GET
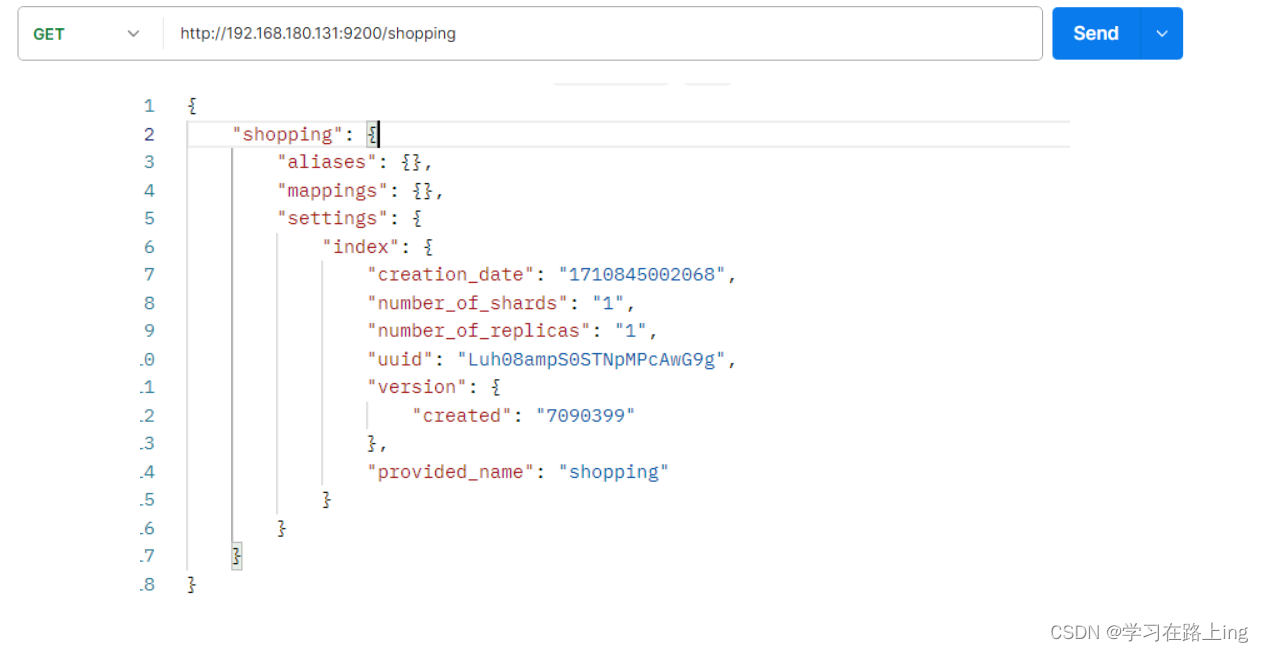
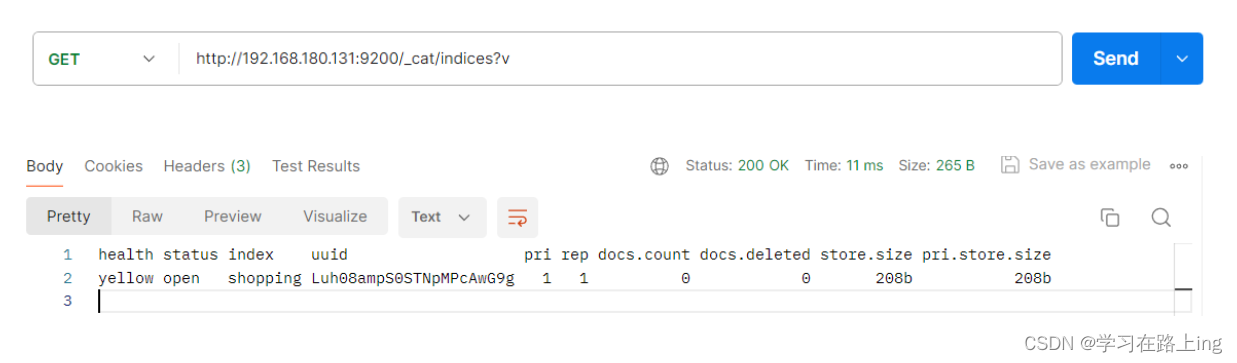
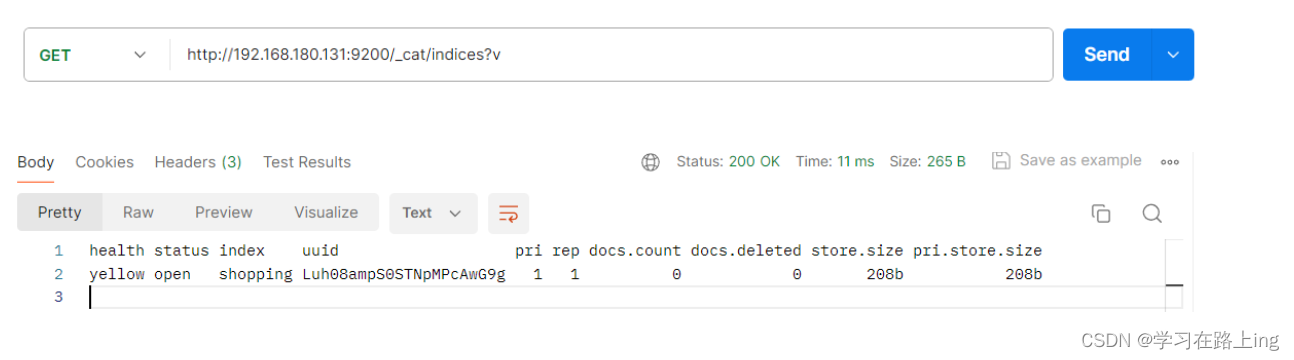
查询全部索引
POST
文档的创建
不指定id
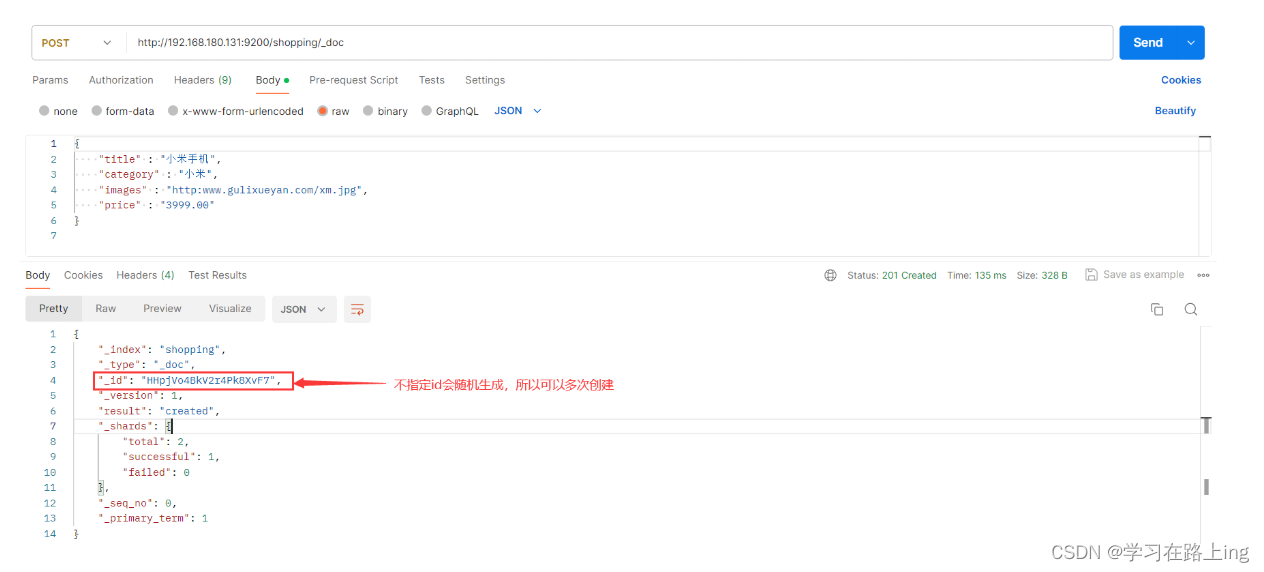
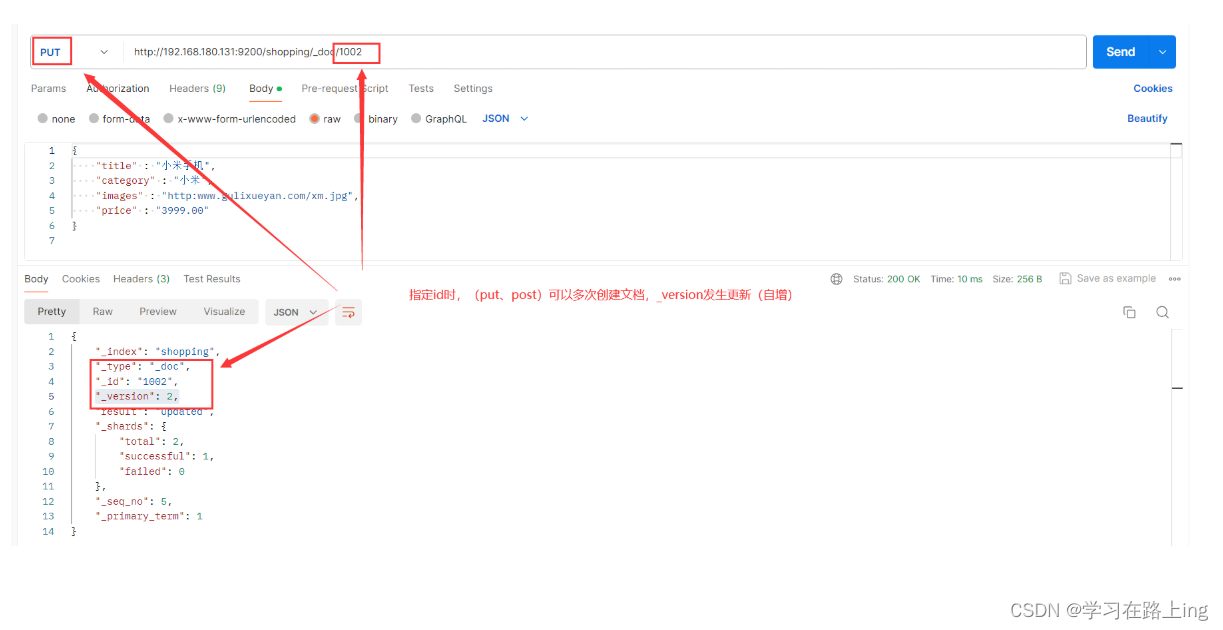
指定id

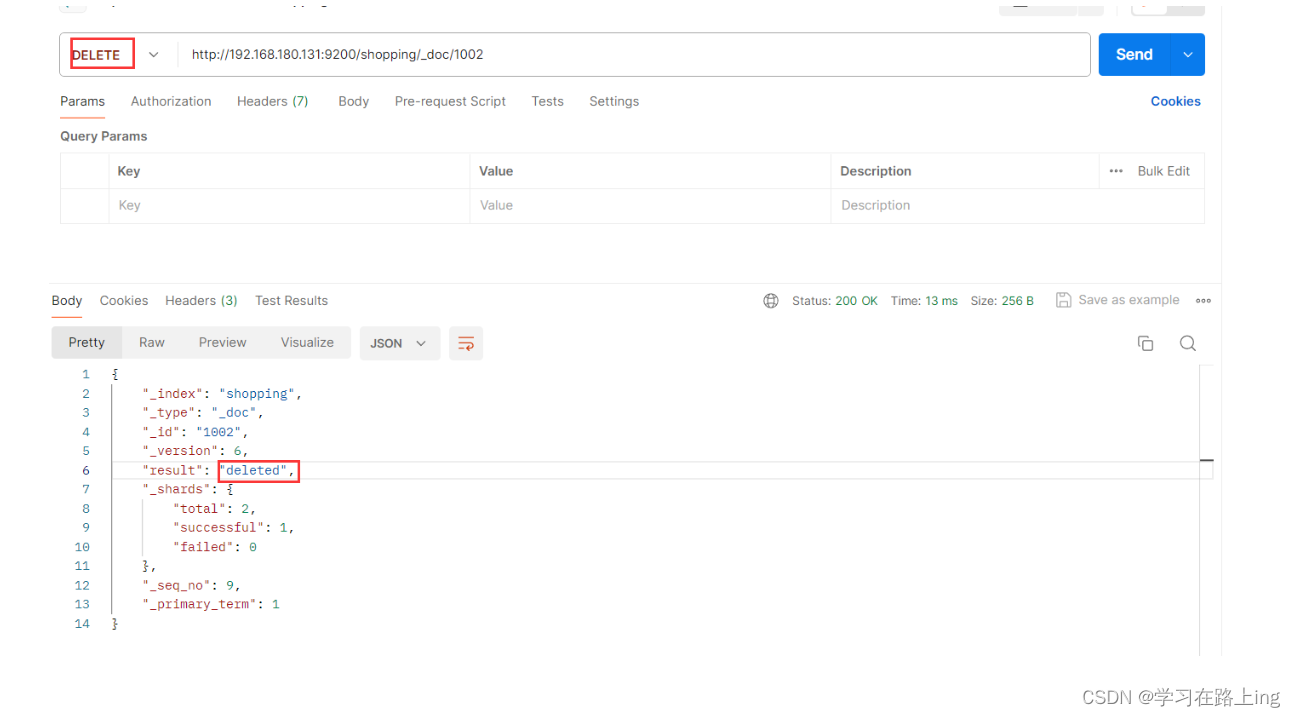
删除
二、java的四大内置函数式接口
1、Supplier(生产型接口)
Supplier:这是一个不接受任何参数并产生一个结果的函数。泛型类型 T 是返回结果的类型。例如,你可以使用 Supplier 接口来生成一个随机数:
1.1、get()方法
1.1.1示例:
package supplierTest;
import java.util.function.Supplier;
/*
常用的函数式接口
java.util.fuction.Supplier<T>接口仅包含一个无参的方法:T get();用来获取一个泛型参数指定类型的对象数据
Supplier<T>接口被称之为生产型接口,泛型执行String,get方法就会返回一个String
*/
public class SupplierTest {
// 定义一个方法,方法的参数传毒Supplier<T>接口,泛型执行String,get方法就会返回一个String;
public static String getString(Supplier<String> supplier) {
return supplier.get();
}
public static void main(String[] args) {
// 调用getString方法,方法的参数Supplier是一个函数式接口,所以可以传递Lambda表达式;
String str1 = getString(() -> {
return "hello";
});
System.out.println(str1);
// 优化Lambda表达式(只有一条语句,可以省略{},又是return语句,可以省略return)
String str = getString(() -> "Hello");
System.out.println(str);
}
}
1.1.2练习
package supplierTest;
import java.util.function.Supplier;
public class SupplierTest2 {
public static Integer getMax(Supplier<Integer> supplier) {
return supplier.get();
}
public static void main(String[] args) {
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int max = getMax(() -> {
int maxNum = arr[1];
for (int i = 0; i < arr.length; i++) {
if (arr[i] > maxNum) {
maxNum = arr[i];
}
}
return maxNum;
});
System.out.println(max);
}
}
2、Consumer(消费型接口)
这是一个接受一个参数并返回 void 的函数。泛型类型 T 是输入参数的类型。例如,你可以使用 Consumer 接口来打印一个字符串:
1.1、appect()方法
package ConsumerTest;
import java.util.function.Consumer;
/*
java.util.functional.Consumer<T> 接口则正好与Supplier接口相反,
它是不是生产一个数据,而是消费一个数据,其数据类型有泛型决定
Consumer接口中包含抽象发放void accept(T t),意为消费一个指定泛型的数据。
Consumer接口是一个消费型接口,泛型执行什么类型,就可以使用accept方法消费什么类型的数据,治愈具体则呢么消费(使用),需要自定义(输出,计算......)
*/
public class ConsumerTest1 {
/*
* 定义一个方法
* 方法的参数传递一个字符串的姓名
* 方法的参数传递Consumer接口,泛型使用String
* 可以使用Consumer接口消费字符串的姓名
*
* */
public static void method(String name, Consumer<String> consumer) {
consumer.accept(name);
}
public static void main(String[] args) {
method("hahah", (String name) -> {
System.out.println(name);
});
method("hahah", (String name) -> {
// 调用StringBuffer的reverse方法,将字符串反转
String reName = new StringBuffer(name).reverse().toString();
System.out.println(reName);
});
}
}
1.2 andThen方法示例
package ConsumerTest;
import java.util.function.Consumer;
/*
* Consumer接口的默认方法andThen()
* 作用:需要两个Consumer接口,可以把连个Consumer接口组合到一起,再对数据解析消费
* 例如:
* Consumer<String> consumer1;
* Consumer<String> consumer2;
* String s = "hello world";
* consumer1.accpet(s);
* consumer2.accpet(s);
*
* consumer.andThen(consumer2).accept(s);谁在前谁先消费
* */
public class AndThenTest {
// 定义一个方法,方法的参数传递一个字符串和两个Consumer接口,Consumer接口的泛型使用字符串
public static void method(String s, Consumer<String> con1, Consumer<String> con2) {
// con1.accept(s);
// con2.accept(s);
// 使用adnThen()方法,把两个Consumer接口组合到一起,再对数据解析消费
con1.andThen(con2).accept(s);
}
public static void main(String[] args) {
// 调用method方法,传递一个字符串,两个Lamnbda表达式
method("hello",
(t) -> {
System.out.println(t.toUpperCase());
},
(t) -> {
System.out.println(t.toLowerCase());
});
}
}
1.3 andThen方法练习
package ConsumerTest;
import java.util.function.Consumer;
public class AndThenTest2 {
// 定义一个方法,参数传递String类型的数组和两个Consumer接口,泛型用String
public static void printInfo(String[] arr, Consumer<String> consumer1, Consumer<String> consumer2) {
for (String s : arr) {
consumer1.andThen(consumer2).accept(s);
}
}
public static void main(String[] args) {
String[] arr = {"迪丽热巴,女", "古力娜扎,女", "马尔扎哈,男"};
printInfo(arr, (message) -> {
String name = message.split(",")[0];
System.out.println("姓名:"+ name);
}, (message) -> {
String sex = message.split(",")[1];
System.out.println("性别:"+sex);
});
}
}
3、Predicate(断言型接口)
这是一个接受一个参数并返回一个布尔值的函数。泛型类型 T 是输入参数的类型。例如,你可以使用 Predicate 接口来检查一个字符串是否为空:
1.1、test() 方法
package PreicateTest;
import java.util.function.Predicate;
/*
* java.util.fuction.Predicate<T>接口 判断性接口
* 作用:对某种数据类型的数据进行判断,结果返回一个Boolean类型
*
* Predicate接口中包含一个抽象发放:
* boolean test(T t):用来指定数据类型进行判断的方法
* 结果:
* 符合条件返回true,否则返回false
*
* */
public class PredicateTest {
/*
* 定义一个方法
* 参数传一个String类型的字符串
* 传递与一个Predicate接口,泛型使用String
* 使用Predicate中的方法test对字符串进行判断,并返回判断的结果返回
* */
public static Boolean chekString(String s, Predicate<String> predicate) {
return predicate.test(s);
}
public static void main(String[] args) {
String s = "hello";
Boolean a = chekString(s, (message) -> message.length() > 5
);
System.out.println(a);
}
}
1.2、and() 方法
package PreicateTest;
import java.util.function.Predicate;
/*
* 逻辑表达式:可以连接多个判断的条件
* && : 与
* || : 或
* ! : 非(取反)
*
* Predicate方法中的默认方法and,表示并且关系,可以用于连接两个判断条件
*
* */
public class PredicateAndTest {
/* 需求:判断一个字符串,有两个判断条件
* 1.判断字符串的长度是否大于5
* 2.判断字符串中是否包含a
* 两个条件必须同时满足
* */
public static Boolean chekPredicateString(String s, Predicate<String> predicate, Predicate<String> predicate2) {
// return predicate.test(s) && predicate2.test(s);
return predicate.and(predicate2).test(s);
}
public static void main(String[] args) {
String s = "hello";
boolean a = chekPredicateString(s, (message) -> message.length() > 5,
(message) -> message.contains("a"));
System.out.println(a);
}
}
1.3 or() 方法
package PreicateTest;
import java.util.function.Predicate;
/* 需求:判断一个字符串,有两个判断条件
* 1.判断字符串的长度是否大于5
* 2.判断字符串中是否包含a
* 两个条件有一个满足
*
* Predicate方法中的默认方法or,表示或关系,可以用于连接两个判断条件
* */
public class PredicateOrTest {
public static Boolean chekStringOr(String s, Predicate<String> predicate, Predicate<String> predicate2) {
// return predicate.test(s) || predicate2.test(s);
return predicate.or(predicate2).test(s);
}
public static void main(String[] args) {
String s = "hello";
boolean a = chekStringOr(s, (message) -> message.length() > 5
, (message) -> message.contains("o"));
System.out.println(a);
}
}
1.4 negate() 方法
package PreicateTest;
import java.util.function.Predicate;
public class PredicateNegateTest {
/* 需求:判断一个字符串的长度是否大于5
如果字符串的长度大于5,那么返回false,反之
Predicate方法中的默认方法negate,表示取反关系,
* */
public static Boolean chekStingNegate(String s, Predicate<String> predicate, Predicate<String> predicate2) {
// return !(predicate.and(predicate2).test(s));
return predicate.and(predicate2).negate().test(s);
}
public static void main(String[] args) {
String s = "hello";
boolean a = chekStingNegate(s, (message) -> message.length() > 5,
(message) -> message.contains("e"));
System.out.println(a);
}
}
3、Function<T, R>(函数型接口)
这是一个接受一个参数并产生一个结果的函数。泛型类型 T 是输入参数的类型,而 R 是返回结果的类型。例如,你可以使用 Function 接口将一个字符串转换为大写:
1.1、apply() 方法
package FunctionTest;
import java.util.function.Function;
/*
* java.util.fuction.Function<T,R>接口 用来根据一个类型的数据得到另一个类型的数据,
* 前者称为前置条件,后者称为后置条件
* Function接口中最主要的抽象方法为:R apply(T t) 根据类型T的参数获取类型R的结果
* 使用场景如:将String类型转换为Integer类型
* */
public class FunctionTest {
/*
* 定义一个方法
* 方法的参数传递一个字符串类型的整数
* 方法的参数传递一个Function接口,泛型使用<String, Integer>
* 使用Function接口中的方法apply,把字符串类型的整数,转换为Integer类型的整数
* */
public static Integer change(String s, Function<String, Integer> fun) {
// Integer i = fun.apply(s);
int i = fun.apply(s); // 自动拆箱
System.out.println(i);
return i;
}
public static void main(String[] args) {
String s = "123456";
// change(s, (message) -> Integer.parseInt(message));
change(s, Integer::parseInt);
}
}
1.2、andThen() 方法
package FunctionTest;
import java.util.function.Function;
/*
* Function接口中的默认方法andThen:用来进行组合操作
* */
public class FunctionAndThenTest {
/* 需求:
* 把String类型的"123",转换为Integer类型,把转换后的结果加10
* 把增加之后的Integer类型的数据,转换为String类型
* 分析:
* 转换了两次
* */
public static void chek(String s, Function<String, Integer> function, Function<Integer, String> function2) {
String a = function.andThen(function2).apply(s);
System.out.println(a);
}
public static void main(String[] args) {
String s = "123456";
chek(s, (message) -> Integer.parseInt(message) + 10
, (message) ->Integer.toString(message) // 只能是int或者Integer类型
// return String.valueOf(message); // 所有类型都可以
);
}
}
1.3 andThen()方法练习
package FunctionTest;
import java.util.function.Consumer;
import java.util.function.Function;
public class FunctionTestDemo {
public static Integer change(String s, Function<String, String> function1, Function<String, Integer> function2, Function<Integer, Integer> function3) {
return function1.andThen(function2).andThen(function3).apply(s);
}
public static void main(String[] args) {
String s = "清月,20";
Integer a = change(s, (message) -> message.split(",")[1],
(String1) -> Integer.parseInt(String1),
(Integer1) -> Integer1 + 100);
System.out.println(a);
}
}
三、Stream流
1、Stream的两种获取方式
(1)通过Collection接口中的默认方法Stream stream()
(2)通过Stream接口中的静态of方法
package StreamAPI;
import java.util.*;
import java.util.stream.Stream;
public class StreamTest02 {
public static void main(String[] args) {
// 方法一: 根据Collection获取流
// Collection接口中有一个默认的方法:default Stream<E> stream
ArrayList<String> list = new ArrayList<>();
Stream<String> stream1 = list.stream();
HashSet<String> set = new HashSet<>();
Stream<String> stream2 = set.stream();
HashMap<String, String> map = new HashMap<>();
Stream<String> stream3 = map.keySet().stream();
Stream<String> stream4 = map.values().stream();
Stream<Map.Entry<String, String>> stream5 = map.entrySet().stream();
// 方式二:Stream中的静态方法of获取流
// static<t> Stream<T> of(T... values)
Stream<String> stream6 = Stream.of("aa", "bb", "cc");
String[] strings = {"aa", "bb", "cc"};
Stream<String> stream7 = Stream.of(strings);
// 基本数据类型的数组不行,会将整个数组看做一个元素进行操作
int[] arr = {11, 22, 33};
Stream<int[]> stream8 = Stream.of(arr);
}
}
2、Stream的注意事项和常用方法
1、注意事项
1.Stream只能操作一次
2.Stream方法返回的是新的流
3.Stream不调用终结方法,中间的操作不会执行
package StreamAPI;
import java.util.stream.Stream;
public class StreamTest03 {
public static void main(String[] args) {
Stream<String> stream1 = Stream.of("aa", "bb", "cc");
// 1.Stream只能操作一次
// long count = stream1.count();
// long count2 = stream1.count();
// 2.Stream方法返回的是新的流
// Stream<String> stream2 = stream1.limit(1);
// System.out.println(stream1);
// System.out.println(stream2);
// 3.Stream不调用终结方法,中间的操作不会执行
stream1.filter((s) -> {
System.out.println(s);
return true;
}).count();
}
}
2、常用方法
(1)终结方法:返回值类型不再是Stream类型的方法,不再支持链式调用。
(2)非终结方法:反之
| 方法名 | 方法作用 | 返回值类型 | 方法种类 |
|---|---|---|---|
| count | 统计个数 | long | 终结 |
| forEach | 逐一处理 | void | 终结 |
| filter | 过滤 | Stream | 函数拼接 |
| limit | 取用前几个 | Stream | 函数拼接 |
| skip | 跳过前几个 | Stream | 函数拼接 |
| map | 映射 | Stream | 函数拼接 |
| concat | 组合 | Stream | 函数拼接 |
1、forEach方法(遍历)
@Test
void StreamForEach() {
List<String> list = new ArrayList<>();
Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");
list.stream().forEach(System.out::println);
}
2、count方法(求个数)
@Test
void StreamCount() {
List<String> list = new ArrayList<>();
Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");
Long a = list.stream().count();
System.out.println(a);
}
3、filter方法(过滤)
@Test
void StreamFilter() {
List<String> list = new ArrayList<>();
Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");
list.stream().filter(message -> message.length() == 3).forEach(System.out::println);
}
4、limit方法(只取前几个)
@Test
void StreamLimit() {
List<String> list = new ArrayList<>();
Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");
list.stream().limit(3).forEach(System.out::println);
}
5、skip方法(跳过前几个)
@Test
void StreamSkip() {
List<String> list = new ArrayList<>();
Collections.addAll(list, "欧阳无敌", "鱿鱼卷", "苏大娣", "老子", "庄子", "孙子");
list.stream().skip(3).forEach(System.out::println);
}
6、map方法(映射)
@Test
void StreamMap() {
List<String> list = new ArrayList<>();
Collections.addAll(list, "11", "22", "33", "44", "66", "55");
list.stream().map(Integer::parseInt).forEach(System.out::println);
}
7、sorted方法(按元素的自然顺序排列)
@Test
void StreamSorted() {
List<String> list = new ArrayList<>();
Collections.addAll(list, "11", "22", "33", "44", "66", "55");
list.stream().sorted().forEach(System.out::println);
System.out.println("-----------------------------");
Stream<Integer> integerStream = Stream.of(11, 22, 33, 44, 66, 55);
// integerStream.sorted().forEach(System.out::println); // 正序
//通过Comparator构造自定义比较器,
integerStream.sorted((o1, o2) -> o2 - o1).forEach(System.out::println);// 反序
}
8、distinct方法(去重)
@Test
void StreamDistinct() {
Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);
stream.distinct().forEach(System.out::println);
System.out.println("-----------------------------");
Stream<String> stream1 = Stream.of("aa", "bb", "cc", "cc", "dd", "aa");
stream1.distinct().forEach(System.out::println);
}
9、distinct方法自定义对象(去重)
@Test
void StreamDistinct1() {
Stream<Student> stream = Stream.of(
new Student("西施", 18),
new Student("貂蝉", 19),
new Student("貂蝉", 19),
new Student("杨玉环", 19),
new Student("王昭君", 20));
stream.distinct().forEach(System.out::println);
}
10、allMatch方法(判断所有元素是否满足)
@Test
void StreamAllMatch() {
Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);
boolean a = stream.allMatch(message -> message > 7);
System.out.println(a);
}
11、anyMatch方法(判断任意元素是否满足)
@Test
void StreamAnyMatch() {
Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);
boolean a = stream.anyMatch(message -> message > 44);
System.out.println(a);
}
12、noneMatch方法(判断所有元素均不满足)
@Test
void StreamNoneMatch() {
Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);
boolean a = stream.noneMatch(message -> message > 44);
System.out.println(a);
}
13、findFirst 和 findAny 方法(查找第一个元素)
@Test
void StreamFindFirst() {
Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);
Optional<Integer> a = stream.findFirst();
System.out.println(a.get());
System.out.println("---------------------");
Stream<Integer> stream1 = Stream.of(11, 22, 33, 33, 66, 55);
Optional<Integer> b = stream1.findAny();
System.out.println(b.get());
}
14、max方法(比较最大值,取排列后的最后一个元素)
@Test
void StreamMax() {
Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);
Optional<Integer> a = stream.max((o1, o2) -> o1 - o2);
System.out.println(a.get());
}
15、min方法(比较最小值,取排列后的第一个元素)
@Test
void StreamMin() {
Stream<Integer> stream = Stream.of(11, 22, 33, 33, 66, 55);
Optional<Integer> a = stream.min((o1, o2) -> o1 - o2);
System.out.println(a.get());
}
16、reduce方法() (各种类型的累积计算操作,例如求和、求积、字符串连接等)
@Test
void StreamReduce() {
Stream<Integer> stream = Stream.of(4, 5, 3, 9);
// Integer a = stream.reduce(0,(x,y) -> x+y );
Optional<Integer> a = stream.reduce((x, y) -> x + y);
System.out.println(a.get());
}
17、mapToInt方法 (将Stream中的Integer类型数据转换成int类型)
// 同理还有mapLong、mapToDouble
@Test
void StreamMapToInt() {
// Stream<Integer>.filter 自动拆箱进行比较
Stream<Integer> stream = Stream.of(4, 5, 3, 9).filter(s -> s > 3);
stream.forEach(System.out::println);
// 转换成IntStream 减少自动装箱和拆箱
IntStream intStream = Stream.of(4, 5, 3, 9).mapToInt(Integer::intValue);
intStream.filter(s1 -> s1 > 3).forEach(System.out::println);
}
18、collect方法(将流中的数据收集到集合中)
@Test
void StreamCollect() {
Stream<String> stream1 = Stream.of("张三", "李四", "王五", "张三");
// 收集到List集合中
// List<String> collect = stream1.collect(Collectors.toList());
// System.out.println(collect);
// 收集到Set集合中
// Set<String> collect = stream1.collect(Collectors.toSet());
// System.out.println(collect);
// 收集到指定的集合中AyyayList
// ArrayList<String> collect = stream1.collect(Collectors.toCollection(ArrayList::new));
// System.out.println(collect);
// 收集到指定的集合中AyyayList
HashSet<String> collect = stream1.collect(Collectors.toCollection(HashSet::new));
System.out.println(collect);
}
19、toArray()方法(将流中的数据和收集到数组中)
@Test
void StreamToArray() {
Stream<String> stream1 = Stream.of("张三", "李四", "王五总", "张三");
// 转成Object数组不方便
// Object[] array = stream1.toArray();
// for (Object o : array) {
// System.out.println(o);
// }
String[] array = stream1.toArray(String[]::new);
for (String s : array) {
System.out.println(s.length() + s);
}
}
20、其他收集流中数据的方式(相当于数据库中的聚合函数)
@Test
public void StreamToOther() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 58, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
// 获取最大值
// Optional<Student> max = studentStream.collect(Collectors.maxBy((s1, s2) -> s1.getSocre() - s2.getSocre()));
// System.out.println("最大值: " + max.get());
// 获取最小值
// Optional<Student> min = studentStream.collect(Collectors.minBy((s1, s2) -> s1.getSocre() - s2.getSocre()));
// System.out.println("最小值: " + min.get());
// 求总和
// Integer sum = studentStream.collect(Collectors.summingInt(s -> s.getAge()));
// System.out.println("总和: " + sum);
// 平均值
// Double avg = studentStream.collect(Collectors.averagingInt(s -> s.getSocre()));
// Double avg = studentStream.collect(Collectors.averagingInt(Student::getSocre));
// System.out.println("平均值: " + avg);
// 统计数量
Long count = studentStream.collect(Collectors.counting());
System.out.println("统计数量: " + count);
}
21、groupingBy方法(分组)
//
@Test
public void StreamGroup() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33));
// Map<Integer, List<Student>> map = studentStream.collect(Collectors.groupingBy(Student::getAge));
// 将分数大于60的分为一组,小于60分成另一组
Map<String, List<Student>> map = studentStream.collect(Collectors.groupingBy((s) -> {
if (s.getScoure() > 60) {
return "及格";
} else {
return "不及格";
}
}));
map.forEach((k, v) -> {
System.out.println(k + "::" + v);
});
}
22、groupingBy方法(多级分组)
@Test
public void StreamCustomGroup() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33));
// 先根据年龄分组,每组中在根据成绩分组
// groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream)
Map<Integer, Map<String, List<Student>>> map = studentStream.collect(Collectors.groupingBy(Student::getAge, Collectors.groupingBy((s) -> {
if (s.getScoure() > 60) {
return "及格";
} else {
return "不及格";
}
})));
// 遍历
map.forEach((k, v) -> {
System.out.println(k);
// v还是一个map,再次遍历
v.forEach((k2, v2) -> {
System.out.println("\t" + k2 + " == " + v2);
});
});
}
18、joining方法(拼接)
//
@Test
public void StreamJoining() {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("迪丽热巴", 56, 99),
new Student("柳岩", 52, 77));
// 根据一个字符串拼接: 赵丽颖__杨颖__迪丽热巴__柳岩
// String names = studentStream.map(Student::getName).collect(Collectors.joining("__"));
// 根据三个字符串拼接
String names = studentStream.map(Student::getName).collect(Collectors.joining("__", "^_^", "V_V"));
System.out.println("names = " + names);
}
3、Map和reduce的组合使用
package StreamAPI;
import org.junit.jupiter.api.Test;
import java.util.stream.Stream;
public class StreamMapAndReduceTest {
// 所有人的年龄总和
@Test
void mapAndReduce() {
Integer allTotalAge = Stream.of(
new Student("西施", 18),
new Student("貂蝉", 19),
new Student("杨玉环", 19),
new Student("王昭君", 20)).map(Student::getAge).reduce(0, Integer::sum);
System.out.println(allTotalAge);
}
// 找出最大的年龄
@Test
void test1() {
Integer allTotalAge = Stream.of(
new Student("西施", 18),
new Student("貂蝉", 19),
new Student("杨玉环", 19),
new Student("王昭君", 20))
.map(Student::getAge)
.reduce(0, Math::max); // Integer.max->Math.max
System.out.println(allTotalAge);
}
//统计a的出现次数
@Test
void test2() {
// long number = Stream.of("a","b","c","a","b","a","d").filter((s)->{
// return s.equals("a");
// }).count();
long number = Stream.of("a", "b", "c", "a", "b", "a", "d").map(s -> {
if (s.equals("a")) {
return 1;
} else {
return 0;
}
}).reduce(0, Integer::sum);
System.out.println(number);
}
}
3.串行Stream流的获取方式
1、streamParallel方法(直接获取并行的Stream流)
@Test
void Stream_StreamParallel() {
ArrayList<String> list = new ArrayList<>();
Stream<String> stream = list.parallelStream();
}
2、parallel方法(将串行流转换成并行流)
@Test
void StreamParallel() {
long count = Stream.of(4, 5, 3, 9, 1, 2, 6)
.parallel() // 转成并行流
.filter(s -> {
System.out.println(Thread.currentThread() + "::" + s);
return s > 3;
})
.count();
System.out.println(count);
}
3、解决parallelStream线程安全问题的三个方案
package StreamAPI;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Vector;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
import java.util.stream.LongStream;
public class StreamParallelTest {
private static final int times = 500000000;
long start;
@BeforeEach
public void init() {
start = System.currentTimeMillis();
}
@AfterEach
public void destory() {
long end = System.currentTimeMillis();
System.out.println("消耗时间:" + (end - start));
}
// 并行的Stream : 消耗时间:137
@Test
public void testParallelStream() {
LongStream.rangeClosed(0, times).parallel().reduce(0, Long::sum);
}
// 串行的Stream : 消耗时间:343
@Test
public void testStream() {
// 得到5亿个数字,并求和
LongStream.rangeClosed(0, times).reduce(0, Long::sum);
}
// 使用for循环 : 消耗时间:235
@Test
public void testFor() {
int sum = 0;
for (int i = 0; i < times; i++) {
sum += i;
}
}
// parallelStream线程安全问题
@Test
void test1() {
ArrayList<Integer> list = new ArrayList<>();
IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
list.add(i);
});
System.out.println("list = " + list.size()); // list.size < 1000
}
// 解决parallelStream线程安全问题方案一: 使用同步代码块
@Test
public void test2() {
ArrayList<Integer> list = new ArrayList<>();
Object obj = new Object();
IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
synchronized (obj) {
list.add(i);
}
});
}
// 解决parallelStream线程安全问题方案二: 使用线程安全的集合
@Test
public void test3() {
ArrayList<Integer> list = new ArrayList<>();
Vector<Integer> v = new Vector();
List<Integer> synchronizedList = Collections.synchronizedList(list);
IntStream.rangeClosed(1, 1000)
.parallel()
.forEach(i -> {
synchronizedList.add(i);
});
System.out.println("list = " + synchronizedList.size());
}
// 解决parallelStream线程安全问题方案三: 调用Stream流的collect/toArray
@Test
public void test4() {
ArrayList<Integer> list = new ArrayList<>();
List<Integer> collect = IntStream.rangeClosed(1, 1000)
.parallel()
.boxed()
.collect(Collectors.toList());
System.out.println("collect.size = "+collect.size());
}
}
四、parallelStream背后的技术
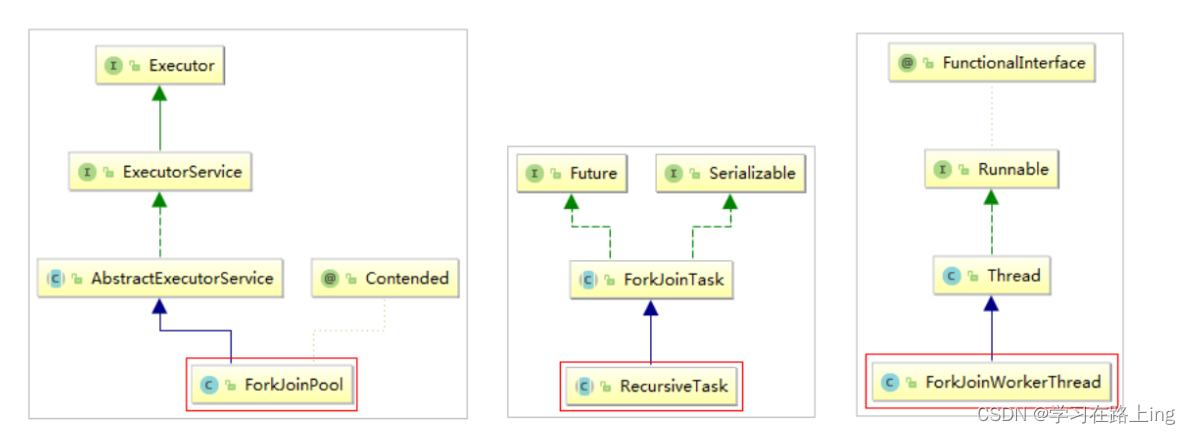
1、Fork/Join框架介绍
parallelStream使用的是Fork/Join框架。Fork/Join框架自JDK 7引入。Fork/Join框架可以将一个大任务拆分为很多小 任务来异步执行。 Fork/Join框架主要包含三个模块:
- 线程池:ForkJoinPool
- 任务对象:ForkJoinTask
- 执行任务的线程:ForkJoinWorkerThread
2、Fork/Join原理-分治法
把大任务拆成小任务

Fork/Join案例:
需求:使用Fork/Join计算1-10000的和,当一个任务的计算数量大于3000时拆分任务,数量小于3000时计算。
package study;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class ForkJoinTest {
public static void main(String[] args) {
Long startTime = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool();
SumRecursiveTask sumRecursiveTask = new SumRecursiveTask(1, 999999999);
Long result = pool.invoke(sumRecursiveTask);
System.out.println("result = " + result);
Long endTime = System.currentTimeMillis();
System.out.println("消耗时间 = " + (endTime - startTime));
}
}
// 创建一个求和的任务
// RecursiveTask:一个任务
class SumRecursiveTask extends RecursiveTask<Long> {
// 是否要拆分的临界值
private static final long THRESHOLD = 3000L;
// 起始值
private final long start;
// 结束值
private final long end;
SumRecursiveTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long lenth = end - start;
if (lenth < THRESHOLD){
// 小于拆分临界值
long sum = 0;
for (long i = start; i < end; i++) {
sum += i;
}
return sum;
} else {
// 拆分
long middle = (start + end) / 2;
SumRecursiveTask left = new SumRecursiveTask(start, middle);
left.fork();
SumRecursiveTask right = new SumRecursiveTask(middle + 1, end);
right.fork();
return left.join() + right.join();
}
}
}
3、Fork/Join原理-工作窃取算法
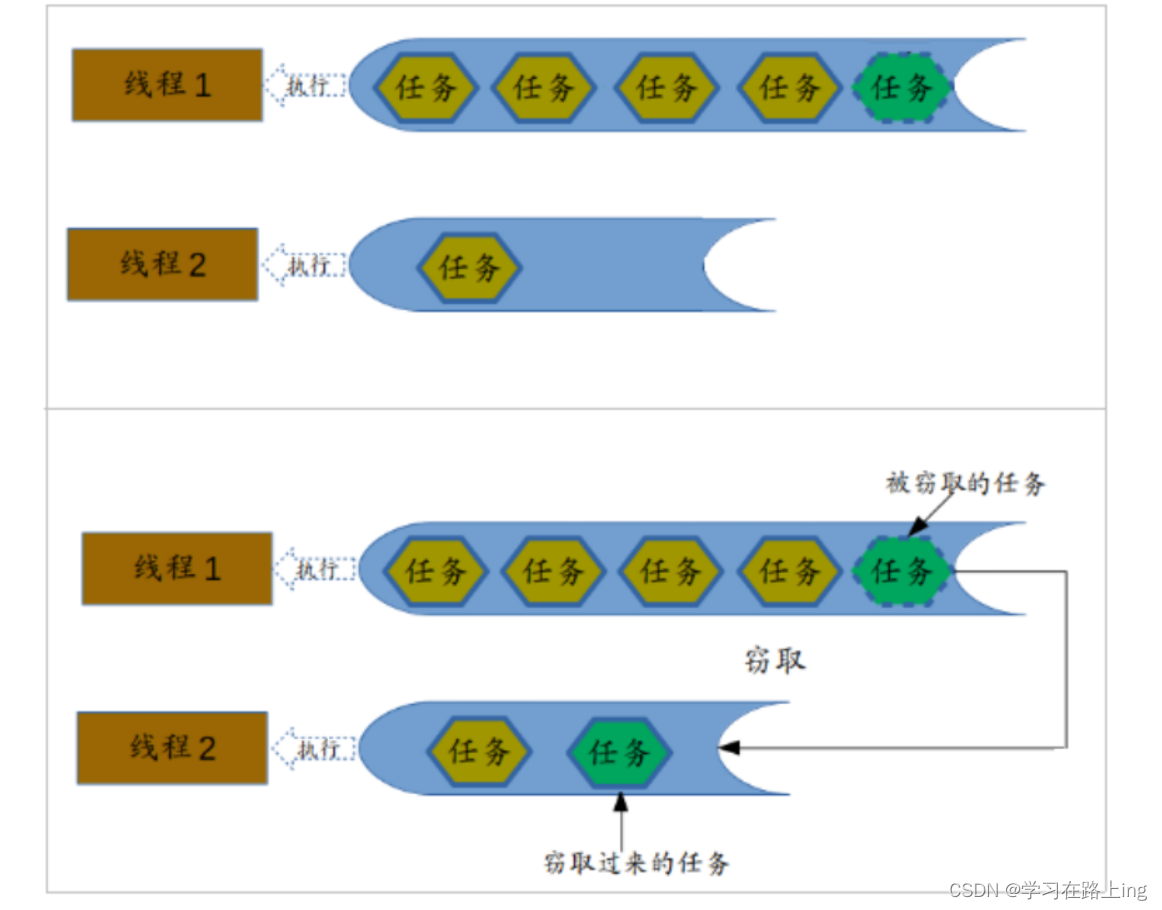
Fork/Join最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的 cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个Fork/Join框架的核心理念 Fork/Join工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
4、小结和注意事项
- parallelStream是线程不安全的
- parallelStream适用的场景是CPU密集型的,只是做到别浪费CPU,假如本身电脑CPU的负载很大,那还到处用 并行流,那并不能起到作用
- I/O密集型 磁盘I/O、网络I/O都属于I/O操作,这部分操作是较少消耗CPU资源,一般并行流中不适用于I/O密集 型的操作,就比如使用并流行进行大批量的消息推送,涉及到了大量I/O,使用并行流反而慢了很多
- 在使用并行流的时候是无法保证元素的顺序的,也就是即使你用了同步集合也只能保证元素都正确但无法保证 其中的顺序
五、Optional类
1、Optional类介绍
Optional是一个没有子类的工具类,Optional是一个可以为null的容器对象。它的作用主要就是为了解决避免Null检 查,防止NullPointerException。
2、Optional的常用方法基本使用
| 方法名 | 作用 |
|---|---|
| empty() | 静态方法,返回一个空的Optional实例。 |
| of(T value) | 静态方法,返回一个包含指定值的Optional实例,如果指定值为null,则抛出NullPointerException。 |
| ofNullable(T value) | 静态方法,返回一个Optional实例,若传入值为null,则返回一个空的Optional实例。 |
| filter(Predicate<? super T> predicate) | 如果值存在并且满足提供的谓词,返回表示该值的Optional;否则返回一个空的Optional。 |
| isPresent() | 如果值存在,返回true;否则返回false。 |
| ifPresent(Consumer<? super T> consumer) | 如果值存在,执行指定的操作。 |
| orElse(T other) | 如果值存在,返回该值;否则返回指定的其他值。 |
| orElseGet(Supplier<? extends T> other) | 如果值存在,返回该值;否则使用指定的Supplier函数生成一个值返回。 |
| orElseThrow(Supplier<? extends X> exceptionSupplier) | 如果值存在,返回该值;否则抛出由Supplier函数生成的异常。 |
package study;
import java.util.Optional;
public class study {
public static void main(String[] args) {
test();
test1();
test2();
test3();
test4();
}
// 静态of方法(具体值)
public static void test() {
Optional<String> op1 = Optional.of("凤姐");
// Optional<String> op2 = Optional.of(null); // NullPointerException
}
// ofNullable(具体值/空)
public static void test1() {
Optional<Object> op3 = Optional.ofNullable("如花");
Optional<Object> op4 = Optional.ofNullable(null);
}
// empty(只能传入空)
public static void test2() {
Optional<Object> op3 = Optional.empty();
}
// 判断Optional是否有具体值
// 1.isPresent()
public static void test3() {
Optional<Object> op3 = Optional.ofNullable("如花");
System.out.println(op3.isPresent()); // true
Optional<Object> op4 = Optional.ofNullable(null);
System.out.println(op4.isPresent()); // false
}
// 1.isPresent()
public static void test4() {
Optional<Object> op3 = Optional.ofNullable("如花");
System.out.println(op3.get()); // 如花
Optional<Object> op4 = Optional.ofNullable(null);
System.out.println(op4.get()); // NoSuchElementException
}
}
|
| orElseGet(Supplier<? extends T> other) | 如果值存在,返回该值;否则使用指定的Supplier函数生成一个值返回。 |
| orElseThrow(Supplier<? extends X> exceptionSupplier) | 如果值存在,返回该值;否则抛出由Supplier函数生成的异常。 |
package study;
import java.util.Optional;
public class study {
public static void main(String[] args) {
test();
test1();
test2();
test3();
test4();
}
// 静态of方法(具体值)
public static void test() {
Optional<String> op1 = Optional.of("凤姐");
// Optional<String> op2 = Optional.of(null); // NullPointerException
}
// ofNullable(具体值/空)
public static void test1() {
Optional<Object> op3 = Optional.ofNullable("如花");
Optional<Object> op4 = Optional.ofNullable(null);
}
// empty(只能传入空)
public static void test2() {
Optional<Object> op3 = Optional.empty();
}
// 判断Optional是否有具体值
// 1.isPresent()
public static void test3() {
Optional<Object> op3 = Optional.ofNullable("如花");
System.out.println(op3.isPresent()); // true
Optional<Object> op4 = Optional.ofNullable(null);
System.out.println(op4.isPresent()); // false
}
// 1.isPresent()
public static void test4() {
Optional<Object> op3 = Optional.ofNullable("如花");
System.out.println(op3.get()); // 如花
Optional<Object> op4 = Optional.ofNullable(null);
System.out.println(op4.get()); // NoSuchElementException
}
}