Pyppeteer爬取实战
- 爬取目标
电影网站https://spa2.scrape.center/
- 任 务
- 通过Selenium遍历列表页,获取每部电影的详情页URL
- 通过Selenium根据上一步获取的详情页URL爬取每部电影的详情页
- 从详情页中提取每部电影的名称、类别、分数、简介、封面等内容。
- 爬取列表页
示例代码如下:
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s : %(message)s')
INDEX_URL = '<https://spa2.scrape.center/page/{page}>'
TIMEOUT = 10
TOTAL_PAGE = 10
WINDOW_WIDTH, WINDOW_HEIGHT = 1366, 768
HEADLESS = False
再定义一个初始化Pyppeteer的方法,其中包括启动Pyppeteer、新建一个页面选项卡和设置窗口大小等操作,代码如下:
from pyppeteer import launch
browser, tab = None, None
async def init():
global browser, tab
browser = await launch(headless=HEADLESS, args=['-disable-infobars', f'--window-size={WINDOW_WIDTH}, {WINDOW_HEIGHT}'])
tab = await browser.newPage()
await tab.setViewport({'width':WINDOW_WIDTH, 'height':WINDOW_HEIGHT})
接下来,定义一个通用的爬取方法:
async def scrape_page(url, selector):
logging.info('scraping %s', url)
try:
await tab.goto(url)
await tab.waitForSelector(selector, options={'timeout':TIMEOUT * 1000})
except TimeoutError:
logging.error('error occurred while scraping %s', url, exc_info=True)
下面实现爬取列表页的方法:
async def scrape_index(page):
url = INDEX_URL.format(page=page)
await scrape_page(url, '.item .name')
这里我们传入的选择器是.item .name,是列表页中电影的名称,意味着电影名称加载出来就代表页面加载成功了,如图所示:
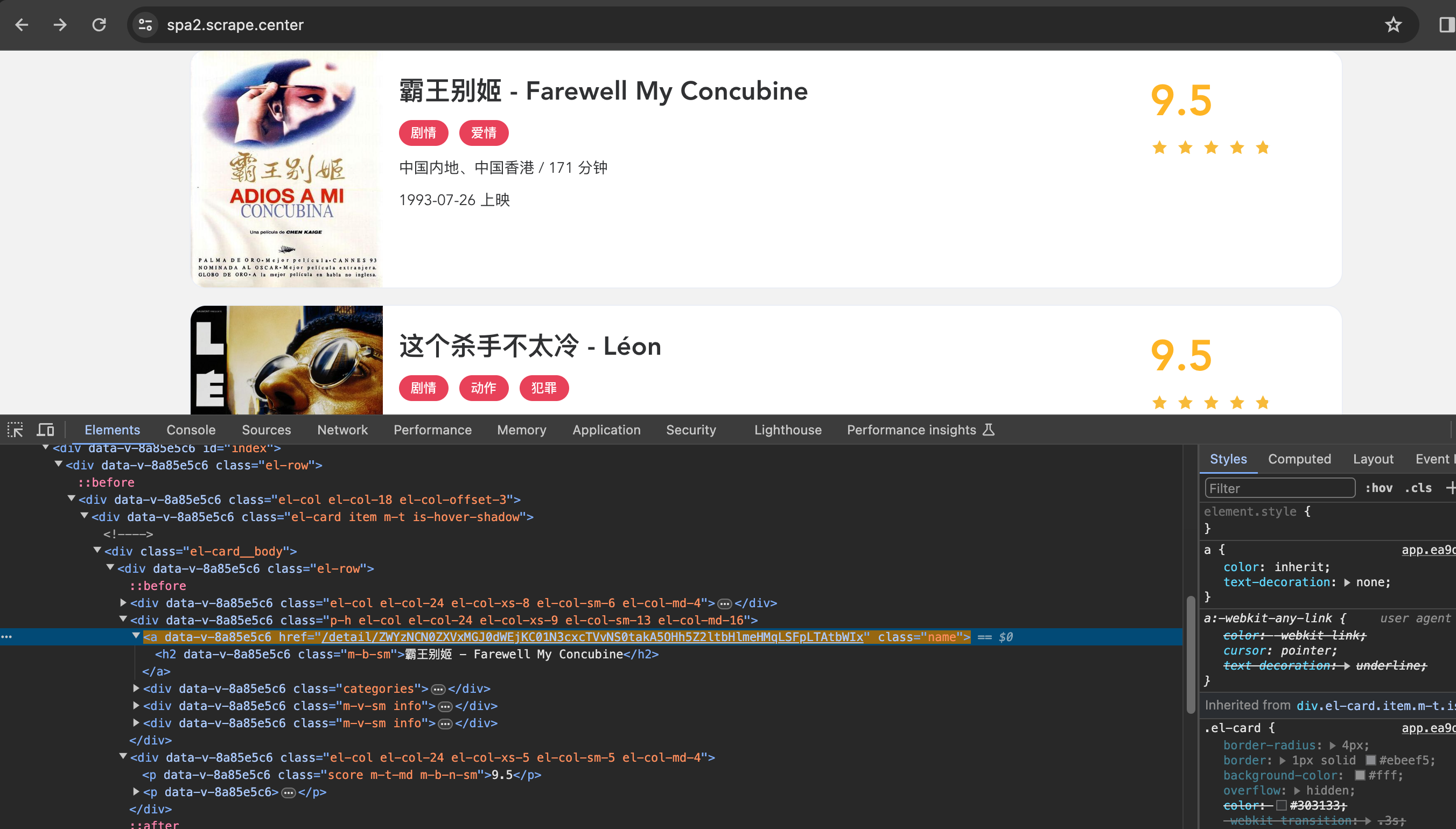
再定义一个解析列表页的方法,用来提取每部电影的详情页URL,方法定义如下:
async def parse_index():
return await tab.querySelectorAllEval('.item .name', 'nodes => nodes.map(node => node.href)')
接下来,串联调用上面的几个方法,代码如下:
import asyncio
async def main():
await init()
try:
for page in range(1, TOTAL_PAGE + 1):
await scrape_index(page)
detail_urls = await parse_index()
logging.info('detail_urls %s', detail_urls)
finally:
await browser.close()
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
运行结果如下:
2024-03-29 18:26:46,375 - INFO : Browser listening on: ws://127.0.0.1:52883/devtools/browser/151b2275-b1ac-4d49-93f9-2879b81ac315
2024-03-29 18:26:47,466 - INFO : scraping <https://spa2.scrape.center/page/1>
2024-03-29 18:26:50,654 - INFO : detail_urls ['<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIy>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIz>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI0>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI1>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI3>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI4>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI5>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIxMA==>']
....
....
2024-03-29 18:26:56,923 - INFO : scraping <https://spa2.scrape.center/page/7>
2024-03-29 18:26:57,650 - INFO : detail_urls ['<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2MQ==>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2Mg==>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2Mw==>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2NA==>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2NQ==>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2Ng==>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2Nw==>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2OA==>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI2OQ==>', '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWI3MA==>']
2024-03-29 18:26:57,650 - INFO : scraping <https://spa2.scrape.center/page/8>
...
...
- 爬取详情页
定义一个爬取详情页的方法,代码如下:
async def scrape_detail(url):
await scrape_page(url, 'h2')
定义一个提取详情页信息的方法:
async def parse_detail():
url = tab.url
name = await tab.querySelectorEval('h2', 'node => node.innerText')
categories = await tab.querySelectorAllEval('.categories button span', 'nodes => nodes.map(node => node.innerText)')
cover = await tab.querySelectorEval('.cover', 'node => node.src')
score = await tab.querySelectorEval('.score', 'node => node.innerText')
drama = await tab.querySelectorEval('.drama p', 'node => node.innerText')
return {
'url': url,
'name': name,
'categories': categories,
'cover': cover,
'score': score,
'drama': drama
}
在main方法里添加对scrape_detail方法和parse_detail方法的调用。main方法改写如下:
async def main():
await init()
try:
for page in range(1, TOTAL_PAGE + 1):
await scrape_index(page)
detail_urls = await parse_index()
for detail_url in detail_urls:
await scrape_detail(detail_url)
detail_data = await parse_detail()
logging.info('data %s', detail_data)
finally:
await browser.close()
重新运行结果如下:
2024-03-29 18:44:02,422 - INFO : data {'url': '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIzMg==>', 'name': '忠犬八公物语 - ハチ公物語', 'categories': ['剧情 '], 'cover': '<https://p0.meituan.net/movie/2d42e00d7ee59ff5bd574f93b8558aa726665.jpg@464w_644h_1e_1c>', 'score': '8.8', 'drama': '1923年,日本秋田县大馆市天降大雪,近藤家纯种秋田犬产仔,赠与县土木科长间濑。后者将其中一犬转赠东京帝国大学教授上野秀次郎(仲代达矢 饰)驯养。上野的独生女千鹤子对此欢欣鼓舞,而上野夫妇却面露难色。后来,千鹤子(石野真子 饰)谈恋爱,竟怀了男友的孩子。男友专程登门造访。上野与之对谈,后者诚惶诚恐,坦言要对其女儿负责,事不宜迟,即日便举行婚礼,上野闻听此言,转怒为喜。千鹤子出嫁后,上野旋即把全部的心血与爱都投注在幼犬身上,并取名为阿八。每日上下班,阿八必在涩谷车站等候,一年四季,风雨无阻,令路人叹为观止,成为地方一道风景,主仆之情感动天地……'}
....
....
2024-03-29 18:44:02,422 - INFO : scraping <https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIzMw==>
2024-03-29 18:44:03,349 - INFO : data {'url': '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIzMw==>', 'name': '海豚湾 - The Cove', 'categories': ['纪录片 '], 'cover': '<https://p0.meituan.net/movie/eb2ea56996f21e7fb47b1a0736c7f177258901.jpg@464w_644h_1e_1c>', 'score': '8.8', 'drama': '日本和歌山县太地,是一个景色优美的小渔村,然而这里却常年上演着惨无人道的一幕。每年,数以万计的海豚经过这片海域,他们的旅程却在太地戛然而止。渔民们将海豚驱赶到靠近岸边的一个地方,来自世界各地的海豚训练师挑选合适的对象,剩下的大批海豚则被渔民毫无理由地赶尽杀绝。这些屠杀,这些罪行,因为种种利益而被政府和相关组织所隐瞒。理查德·贝瑞年轻时曾是一名海豚训练师,他所参与拍摄电影《海豚的故事》备受欢迎。但是,一头海豚的死让理查德的心灵受到强烈的震撼。从此,他致力于拯救海豚的活动。不顾当地政府和村民百般阻挠,他和他的摄影团队想方设法潜入太地的海豚屠杀场,只为将罪行公之于众,拯救人类可爱的朋友……'}
2024-03-29 18:44:03,349 - INFO : scraping <https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIzNA==>
2024-03-29 18:44:04,859 - INFO : data {'url': '<https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIzNA==>', 'name': '英雄本色 - A Better Tomorrow', 'categories': ['剧情 ', '动作 ', '犯罪 '], 'cover': '<https://p0.meituan.net/movie/3e5f5f3aa4b7e5576521e26c2c7c894d253975.jpg@464w_644h_1e_1c>', 'score': '8.8', 'drama': '宋子豪(狄龙 饰)与Mark(周润发 饰)是一个国际伪钞集团之重要人物,也是情如手足的挚友。宋子豪之弟宋子杰(张国荣 饰)刚刚考入警官学校,其女友钟柔(朱宝意 饰)聪明敏慧,对子杰情深一片。一次,宋子豪带手下谭成(李子雄 饰)去台北与当地黑帮作伪钞交易。不料谭成早已勾结台北黑帮,出卖子豪。在一场枪战中宋子豪受伤,被闻讯而来的警察捕获入狱。Mark得知宋子豪被捕,孤身一人赴台北击毙黑帮头目,自己也身负重伤,艰难地逃离现场。与此同时,台湾黑帮唯恐子豪在狱中向警方泄密,派人至香港绑架子豪之父,混战中老父丧命。宋子豪的弟弟子杰得知兄长原为伪钞集团头目,老父为之而死,遂对子豪及黑社会恨之入骨,决心除暴安良。三年后,宋子豪出狱回到香港,决心弃暗投明,但得不到宋子杰的谅解。当年出卖宋子豪的谭成现已成为老大。他假惺惺地要求宋子豪合作,遭到拒绝,便设计加害宋子杰。宋子豪忍无可忍,联合Mark盗取谭成制造伪钞的电脑软盘,随即交给宋子杰。但同时佯称以软盘与谭成做交易,计划在交易时活捉谭成。岂料谭成早有准备,双方在码头展开枪战。这时,宋子杰也驾车赶来,激战中Mark不幸身亡。警察蜂拥而至,包围了码头。为了不连累宋子杰,宋子豪开枪击毙谭成后,从宋子杰身上取下手铐自缚,向警察自首。两兄弟终于言归于好。'}
2024-03-29 18:44:04,859 - INFO : scraping <https://spa2.scrape.center/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIzNQ==>
.....
- 数据存储
将爬取数据保存为JSON文件,实现如下:
import json
from os import makedirs
from os.path import exists
RESULTS_DIR = 'results'
exists(RESULTS_DIR) or makedirs(RESULTS_DIR)
async def save_data(data):
name = data.get('name')
data_path = f'{RESULTS_DIR}/{name}.json'
json.dump(data, open(data_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=2)
最后在main方法里添加save_data方法的调用。
async def main():
await init()
try:
for page in range(1, TOTAL_PAGE + 1):
await scrape_index(page)
detail_urls = await parse_index()
for detail_url in detail_urls:
await scrape_detail(detail_url)
detail_data = await parse_detail()
await save_data(detail_data)
logging.info('data %s', detail_data)
finally:
await browser.close()
以上案例可以在[小蜜蜂AI][https://zglg.work]获取更多体验