算法面试相关专题:
北大硕士LeetCode算法专题课-数组相关问题_骨灰级收藏家的博客-CSDN博客
北大硕士LeetCode算法专题课---算法复杂度介绍_骨灰级收藏家的博客-CSDN博客
北大硕士LeetCode算法专题课-基础算法之排序_骨灰级收藏家的博客-CSDN博客
反转字符串(LeetCode344)
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 s 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。

反转字符串(LeetCode344)——方法一:双指针
解题思路:
l 将 left 指向字符数组首元素,right 指向字符数组尾元素。
l 当 left < right:
交换 s[left] 和 s[right];
left 指针右移一位,即 left = left + 1;
right 指针左移一位,即 right = right – 1
l 当 left >= right,反转结束,返回字符数组即可。

class Solution(object):
def reverseString(self, s): """
:type s: List[str]
:rtype: None Do not return anything, modify s in-place instead. """
l, r = 0, len(s) - 1
while l < r:
s[l], s[r] = s[r], s[l] l += 1
r -= 1
复杂度分析:时间复杂度:O(n),其中 N 为字符数组的长度。一共执行了 N/2 次的交换。 空间复杂度:O(1) 。
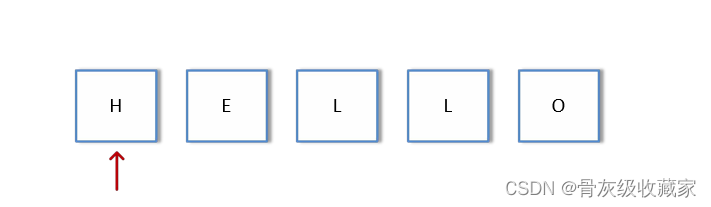
反转字符串(LeetCode344)——方法二:单指针
解题思路:
l 将 指针指向最左侧
l 当 left < 字符串长度/2:交换 s[left] 和 s[-left-1], 相当于第一个跟倒数第一交换, 第二跟与倒数第二交换
l 当 left >= 字符串长度/2,反转结束,返回字符数组即可。
class Solution(object):
def reverseString(self, s): """
:type s: List[str]
:rtype: None Do not return anything, modify s in-place instead. """
for i in range(len(s) // 2):
s[i], s[-i - 1] = s[-i - 1], s[i]
复杂度分析:时间复杂度:O(n),其中 N 为字符数组的长度。一共执行了 N/2 次的交换。 空间复杂度:O(1) 。
验证回文串(LeetCode 125)
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写

解法1: 对字符串进行遍历, 只保留数字和字母, 将结果保存到新的字符串s_中。 此时只需判断新的字符串s_ 与其逆序是否相同 如果相同则为回文串。
def isPalindrome(s):
# isalnum 为Python自带API, 判断当前字符是否是数字或者字母 s_ = "".join(ch.lower() for ch in s if ch.isalnum()) return s_ == s_[::-1]
解法1优化: 对字符串进行遍历, 只保留数字和字母, 将结果保存到新的字符串s_中。将新字符串是否为回文的判断改用双指针 实现



def isPalindrome2(s):
s_ = "".join(ch.lower() for ch in s if ch.isalnum()) n = len(s_)
left, right = 0, n - 1
while left < right:
if s_[left] != s_[right]:
return False
left, right = left + 1, right - 1
return True
时间复杂度:O(|s|),其中 |s| 是字符串 s 的长度。
空间复杂度:O(|s|)。在最坏情况下,新的字符串 s_ 与原字符串 s完全相同,因此需要使用 O(|s|) 的空间。
无重复字符的最长子串(LeetCode 3) 中等
一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1:
输入:s = "abcabcbb"
输出:3
解释:因为无重复字符的最长子串是 "abc",所以其长度为 3。

解法1: 暴力解法
①找到所有的子串 O(n2)
②确定子串是否有重复字符O(n)
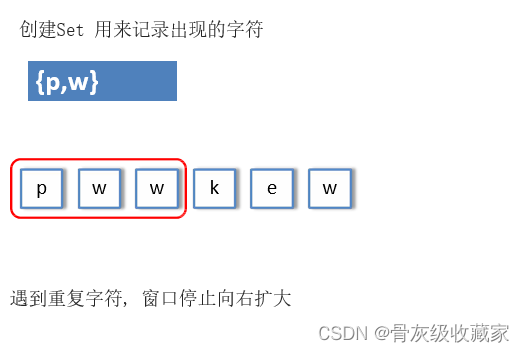
解法2: 滑动窗口
创建Set 用来记录出现的字符,

在字符串长度范围以内, 窗口内没有出现重复字符, 窗口右侧向右滑动窗口, 并用Set记录窗口内增加的字符

def lengthOfLongestSubstring(s):
# 哈希集合,记录每个字符是否出现过
occ = set() n = len(s)
# 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
rk, ans = -1, 0
for i in range(n):
if i != 0:
# 左指针向右移动一格,移除一个字符
occ.remove(s[i - 1])
while rk + 1 < n and s[rk + 1] not in occ:
# 不断地移动右指针
occ.add(s[rk + 1])
rk += 1
# 第 i 到 rk 个字符是一个极长的无重复字符子串
ans = max(ans, rk - i + 1)
return ans
时间复杂度:O(n)
字符串中的第一个唯一字符(LeetCode387)
给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
示例 1:
s = "leetcode"
返回 0
s = "loveleetcode"
返回 2
字符串中的第一个唯一字符(LeetCode387)——方法一:使用哈希表存储频数
思路及算法
对字符串进行两次遍历:
l 在第一次遍历时,我们使用哈希映射统计出字符串中每个字符出现的次数
l 在第二次遍历时,我们只要遍历到了一个只出现一次的字符,那么就返回它的索引,否则在遍历结束后返回 -1。

class Solution:
def firstUniqChar(self, s: str) -> int: frequency = collections.Counter(s) for i, ch in enumerate(s):
if frequency[ch] == 1:
return i
return -1
复杂度分析:时间复杂度:O(n),其中 n 是字符串 s 的长度。我们需要进行两次遍历。
空间复杂度:O(∣Σ∣),其中 Σ 是字符集,在本题中 s 只包含小写字母,因此 ∣Σ∣≤26。我们需要 O(∣Σ∣) 的
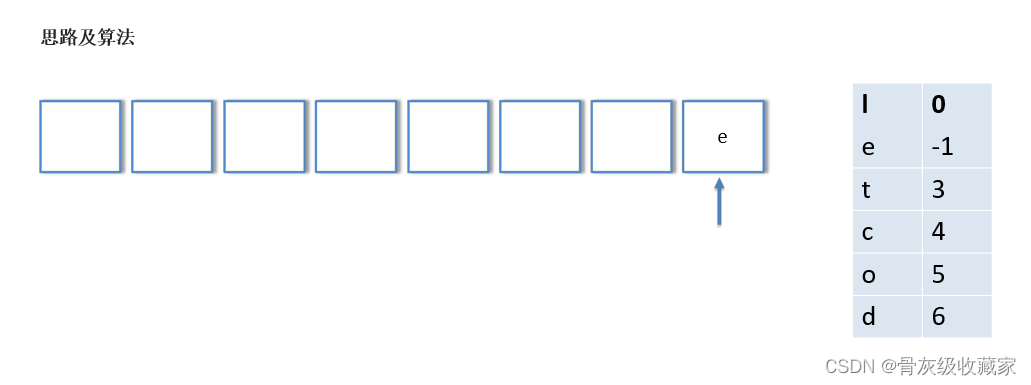
思路及算法
创建一个字典(哈希表),键表示一个字符,值表示它的首次出现的索引(如果该字符只出现一次)或者 -1(如果该字 符出现多次)。
第一次遍历字符串时,设当前遍历到的字符为 c,如果 c 不在哈希映射中,我们就将 c 与它的索引作为一个键值对加 入哈希映射中,否则我们将 c 在哈希映射中对应的值修改为 -1。
在第一次遍历结束后,只需要再遍历一次哈希映射中的所有值,找出其中不为 -1 的最小值,即为第一个不重复字符的 索引。如果哈希映射中的所有值均为 -1,我们就返回 -1。
def firstUniqChar2(s): position = dict() n = len(s)
for i, ch in enumerate(s):
if ch in position: position[ch] = -1
else:
position[ch] = i first = n
for pos in position.values():
if pos != -1 and pos < first: first = pos
if first == n: first = -1
return first
有效的字母异位词(LeetCode242)
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
注意:若 s 和 t 中每个字符出现的次数都相同,则称 s 和 t 互为字母异位词。

有效的字母异位词(LeetCode242) ——方法一: 排序
t 是 s的异位词等价于「两个字符串排序后相等」。因此我们可以对字符串 s 和 t 分别排序,看排序后的字符串是否相等 即可判断。此外,如果 s 和 t 的长度不同,t 必然不是 s 的异位词。
class Solution1(object):
def isAnagram(self, s, t): """
:type s: str
:type t: str
:rtype: bool """
return sorted(s) == sorted(t)
时间复杂度:O(nlogn),其中 n 为 s 的长度。排序的时间复杂度为O(nlogn),比较两个字符串是否相等时间复杂度为O(n), 因此总体时间复杂度为Onogn+n=Onogn。)l()l(
空间复杂度:O(logn)。排序需要 O(logn) 的空间复杂度。
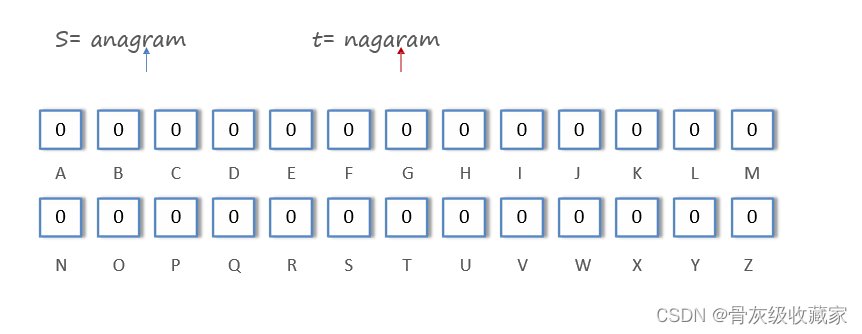
有效的字母异位词(LeetCode242) ——方法二:哈希表
从另一个角度考虑,t 是 s 的异位词等价于「两个字符串中字符出现的种类和次数均相等」。由于字符串只包含 26 个小写字母,因此我们可以维护一个长度为 26 的频次数组 table,先遍历记录字符串 s 中字符出现的频次, 然后遍历字符串 t,减去 table 中对应的频次,如果出现 table[i]<0,则说明 t 包含一个不在 s 中的额外字符,返回 false 即可。

def isAnagram(s, t): a = [0] * 26
for i in s:
a[ord(i)-ord('a')] += 1
for j in t:
if a[ord(j)-ord('a')] == 0:
return False
else:
a[ord(j)-ord('a')] -= 1
for i in range(26):
if a[i]!=0:
return False
return True
字母异位词分组(LeetCode 49) 中等
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
字母异位词 是由重新排列源单词的字母得到的一个新单词,所有源单词中的字母通常恰好只用一次

给两个字符串互为字母异位词时,两个字符串包含的字母相同。
可使用这一组相同的字母作为一组字母异位词的标志(dict 的 key),使用dict存储每一组字母异位词
解法1: 对每个字符串排序, 排序之后相同的为字母异位词, 将排序之后结果作为dict的 key
def groupAnagrams(strs):
mp = collections.defaultdict(list)
for st in strs:
key = "".join(sorted(st)) mp[key].append(st)
return list(mp.values())
时间复杂度:O(nklogk),其中 n 是 strs 中的字符串的数量,k 是 strs 中的字符串的的最大长度。需 要遍历 n 个字符串,对于每个字符串,需要 O(klogk) 的时间进行排序以及 O(1)的时间更新哈希表, 因此总时间复杂度是 O(nklogk)。空间复杂度:O(nk)
解法2:将每个字母出现的次数作为哈希表(dict) 的key
def groupAnagrams2(strs):
mp = collections.defaultdict(list)
for st in strs: counts = [0] * 26 for ch in st:
counts[ord(ch) - ord("a")] += 1
# 需要将 list 转换成 tuple 才能进行哈希
mp[tuple(counts)].append(st)
return list(mp.values())
时间复杂度:O(n(k+∣ Σ∣ )),其中 n 是 strs 中的字符串的数量,k 是 strs 中的字符串的的最大长度,
Σ 是字符集,在本题中字符集为所有小写字母,∣ Σ∣ =26。需要遍历 n个字符串,对于每个字符串, 需要 O(k)的时间计算每个字母出现的次数,O(∣ Σ∣ ) 的时间生成哈希表的键,以及 O(1)的时间更新