目录
概要
一、概述
二、实现方法
1.转置卷积
2.反池化
3.双线性插值法
三、在经典网络中的的应用
1.U-Net
2.FCN
总结
概要
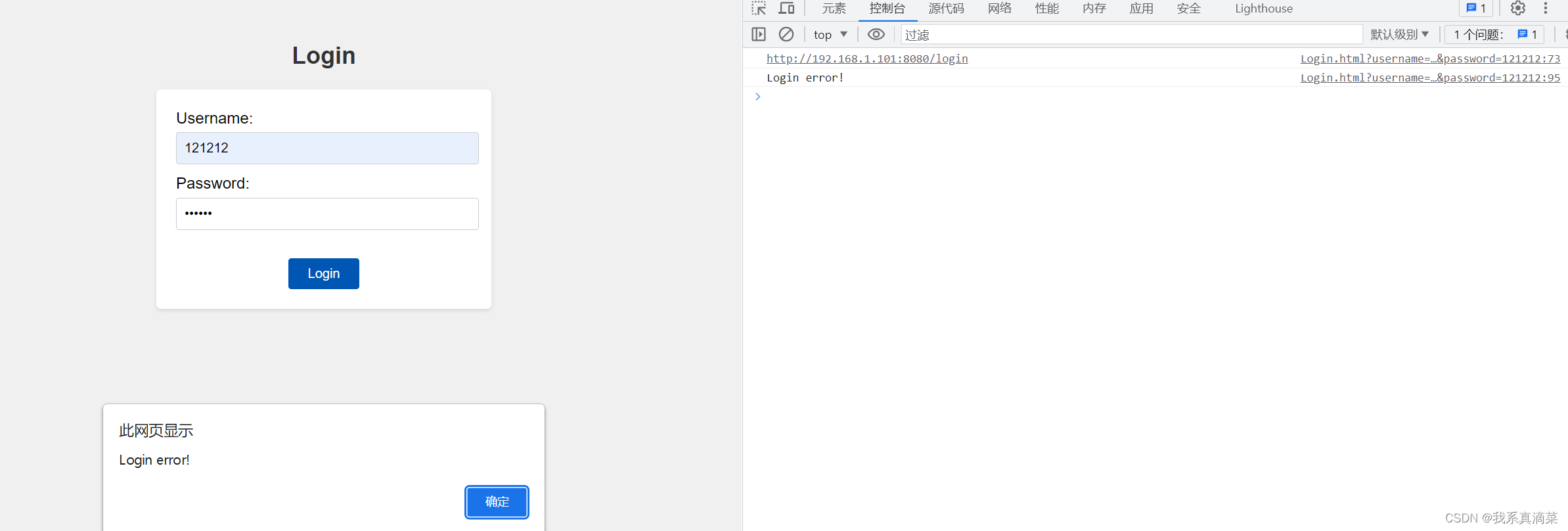
上采样是用于深度学习中提高语义分割精度的技术,可以实现图像放大和像素级别标注
一、概述
神经网络的基本结构为:输入层->隐藏层->输出层。而在传统卷积神经网络中,隐藏层往往由多个卷积层和池化层、(激活函数层和批标准化层)全连接层组成。而为了提高模型的泛化性能,演变出了可以与卷积层或输出层结合使用的Dropout、softmax等技术。本文将以语义分割任务为背景,通过分析U-net、FCN等经典网络结构,介绍上采样(up-sampling)技术在神经网络模型中的应用。
传统卷积神经网络结构如图:

输入图像经过多次卷积、池化等操作,图像尺寸不算缩小,最后在全连接层转化为向量,经过处理(如softmax等)得到预测得分 W。这样的网络输出结果是一个数字或向量,在分类问题中可以起到很好的效果,但它存在以下问题:
固定输入尺寸: 传统CNN通常采用固定大小的输入图像,在实际应用中可能需要对图像进行裁剪或缩放,这会导致信息丢失或扭曲。
特征图分辨率损失: 在传统CNN中,随着网络层数的增加,特征图的尺寸会逐渐减小,导致分辨率损失。这会影响对图像中细节信息的捕获和重建。
语义信息丢失: 传统CNN在进行卷积和池化操作时会丢失部分像素级别的细节信息,导致对语义信息的表达不够准确。
上下文信息不足: 传统CNN通常只关注局部区域的特征提取,缺乏对整体上下文信息的充分利用,导致在处理全局语义信息时效果不佳。
缺乏跳跃连接: 传统CNN中各层之间通常是串行连接,信息传递受限,难以实现跳跃连接的功能,而跳跃连接有助于提高网络的信息传递效率和性能。
如果说对传统端到端需求尚无太大影响的话,这些缺陷在语义分割任务中的表现就不可谓不突出了。语义分割任务当中对原始图像的处理是模型构建面临的主要难题之一,即如何实现对图片像素级的标注。
2014年,Long等人发表了FCN网络结构。2015年,为了解决生物医学图像分割问题,Olaf Ronneberger等发表了《U-Net: Convolutional Networks for Biomedical Image Segmentation》,在这篇文章中,UNet网络结构中使用了一种称为转置卷积(transpose convolution)或反卷积(deconvolution)的上采样操作,这使得网络能够将下采样后的特征图进行还原,从而实现端到端的语义分割。U-Net标志着上采样技术在深度学习中的广泛应用开始兴起。
上采样(up-sampling)的逻辑思路是通过多种手段,增加图像尺寸或恢复图像分辨率,从而使模型的输出不是一个向量,而是一张标注的热力图(heatmap)。事实上,它可以看作是池化(又称为下采样down-sampling)的逆向操作。
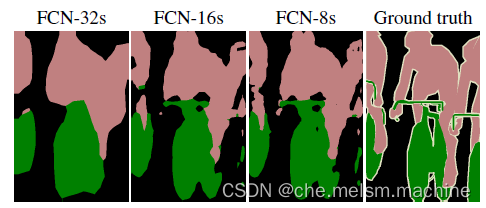
U-Net语义分割实现效果: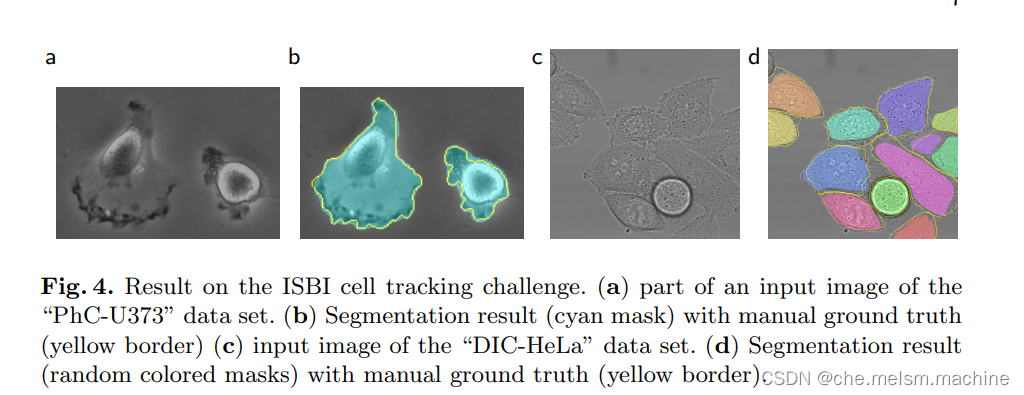
总的来说,与传统神经网络相比,FCN和U-Net分别通过将全连接层替换为卷积层并进行反卷积操作 和 在图像压缩层后增加扩展层等手段实现上采样,还原了因特征采集而缩小的图像尺寸,实现了对图像分割精度的提高。
二、实现方法
我们知道下采样(池化)通过最大值池化、平均池化、概率池化等方式缩小图像尺寸实现特征提取,下面我们介绍上采样的三种实现方案:
1.转置卷积
转置卷积(transpose convolution),也称为反卷积(deconvolution),是一种常见的神经网络层,用于实现上采样操作,可以将一个单个值映射到一个较大的局部区域,用于输入特征图的尺寸扩大。
转置卷积的操作本质上是通过学习参数来实现的,通过学习卷积核来放大特征图。在转置卷积中,输入特征图中的每个像素值都会被扩展到一个更大的区域,通常使用插值或填充技术来实现。
转置卷积操作通常包括以下几个步骤:
-
零填充(Zero Padding):在输入特征图的周围添加零值,以增加输出特征图的大小。这样可以保持输出特征图的大小与输入特征图的大小相同。
-
扩展卷积核(Expanded Convolution Kernel):将卷积核进行扩展,通常通过在卷积核中插入零值来实现。扩展后的卷积核的大小通常大于原始卷积核的大小。
-
正常的卷积操作:将扩展后的卷积核应用于输入特征图,执行常规的卷积操作,生成输出特征图。
-
调整步长(Adjusting Stride):通过调整卷积操作的步长,可以控制输出特征图的尺寸,从而实现上采样的效果。
我们用最简单的手段,在结果卷积得到的特征图像素周围填充0,从而提高图像的分辨率
当然为了使图像的特征分布更合理,我们可以将填充方法修改为在每个像素点周围补0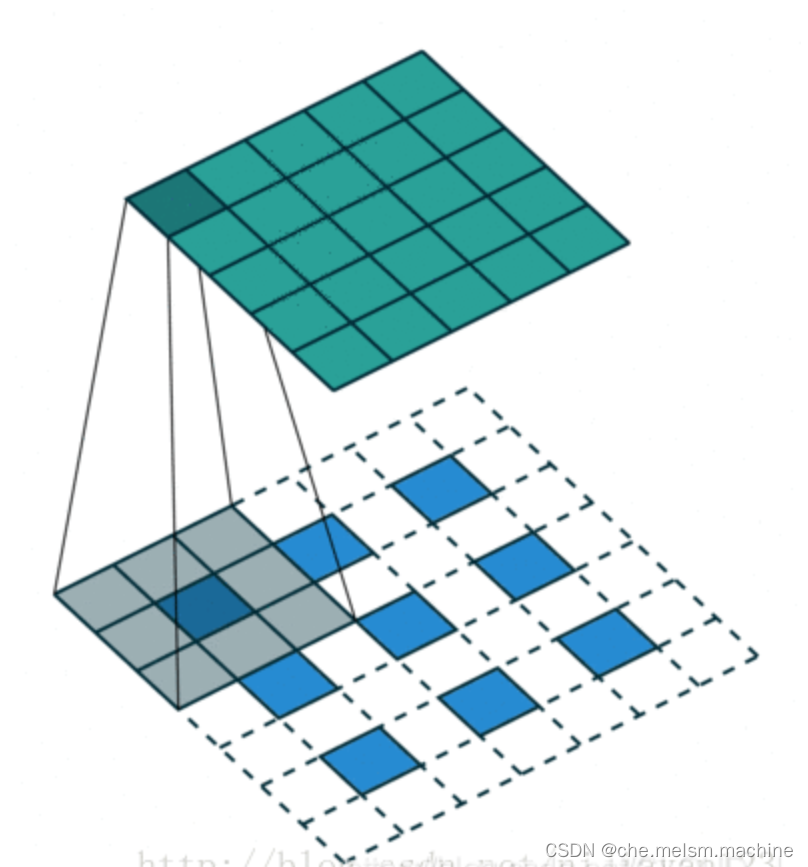
2.反池化
卷积时特征图尺寸会缩小,我们采用了反卷积,而针对池化,我们也有类似的上采样手段。
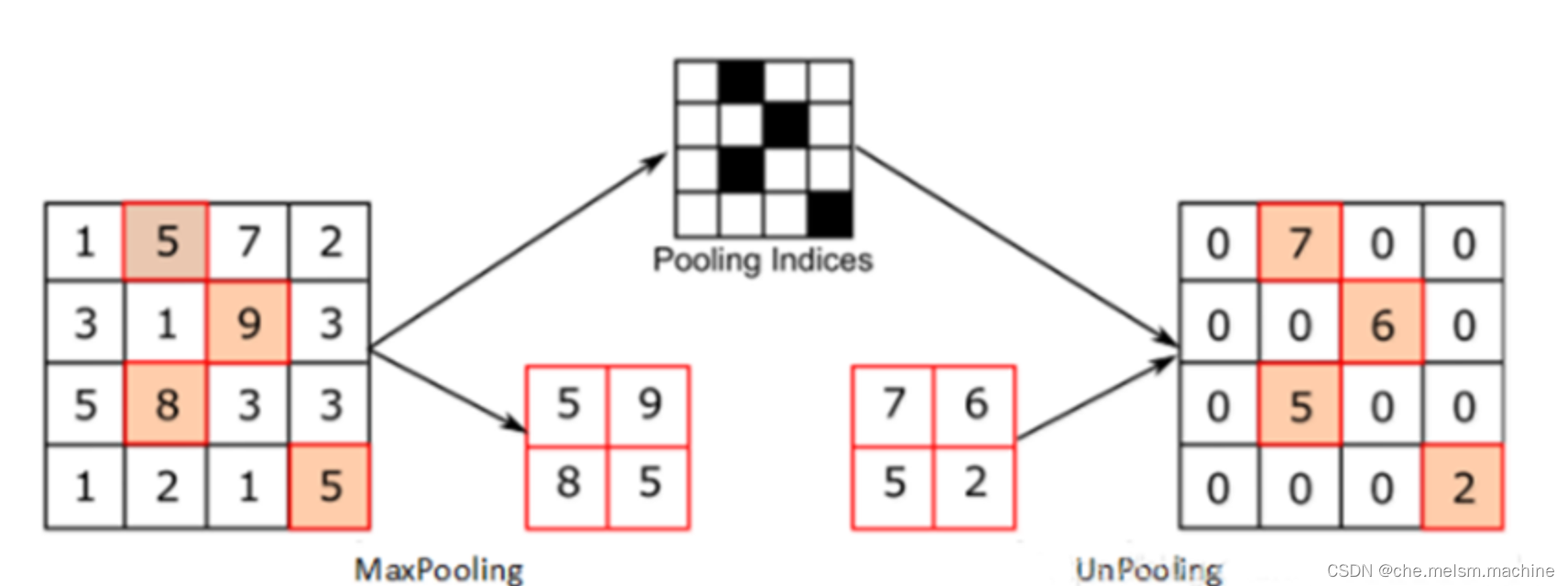
其中最简单的如上图,保留池化的区域,在其他部分填充0。
3.双线性插值法
双线性插值法是一种常用的图像插值方法,用于在已知离散采样点的图像上估计任意位置的像素值。这种方法假设在每个像素之间存在线性关系,并且利用相邻四个像素的信息进行插值。
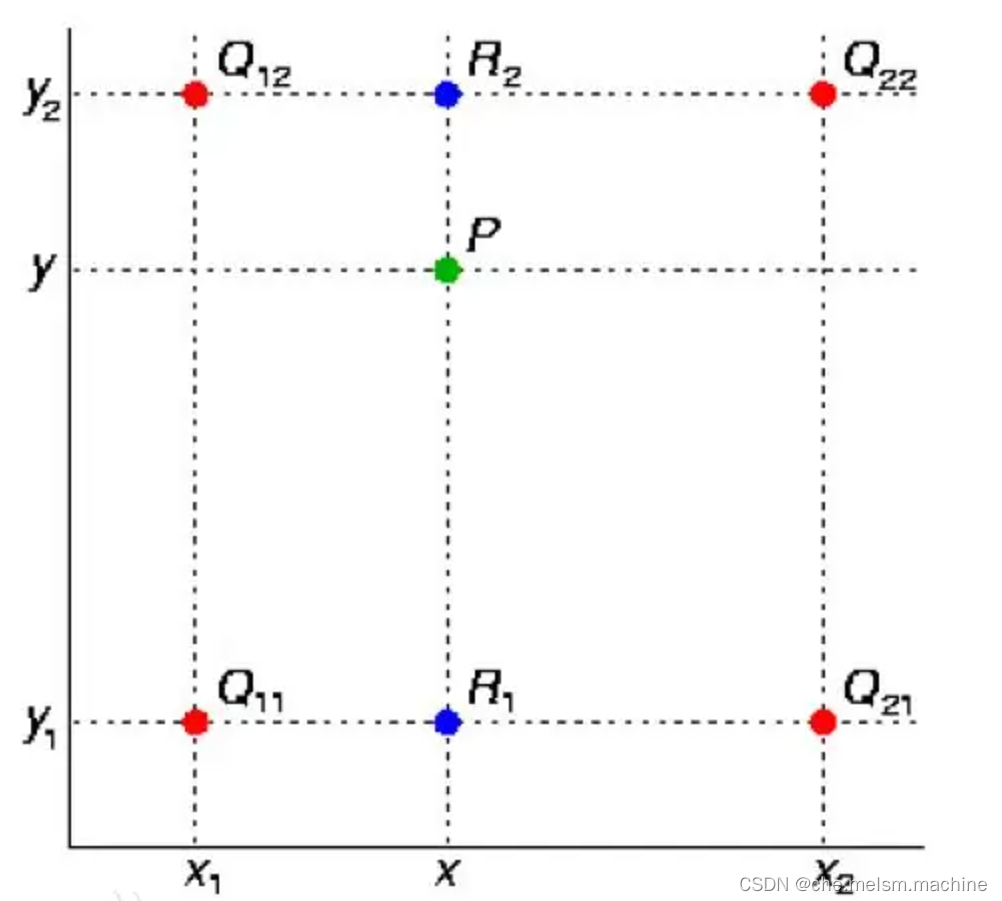
具体来说,双线性插值法通过以下步骤进行:
- 确定目标像素在原始图像中的位置,并计算其在水平和垂直方向上的相对位置(通常使用浮点数表示)。
- 找到目标像素周围的四个最近的像素点,通常是左上、右上、左下和右下四个点。
- 对这四个像素点的像素值进行加权平均,其中权重是根据目标像素在水平和垂直方向上的相对位置计算得到的。通常使用的权重是与目标像素与相邻像素之间的距离成反比的。
- 将加权平均值作为目标像素的插值结果。


简而言之,双线性插值首先在x方向进行线性插值,得到R1和R2,然后在y方向进行线性插值,得到P,这样就得到所要的结果f(x,y)。
三、在经典网络中的的应用
1.U-Net

它包括一条收缩路径(左侧)和一条扩张路径(右侧)。
收缩路径遵循卷积网络的典型架构。它由两个3x3卷积(未填充卷积)的重复应用组成,每个卷积后面都有一个整流线性单元(ReLU)和一个2x2 max池化操作,步幅为2,用于下采样,在每个降采样步骤中,我们将特征通道的数量加倍。扩展路径中的每一步都包括特征映射的上采样2x2卷积(“反卷积”),将特征通道的数量减半,与收缩路径中相应裁剪的特征映射进行连接,以及两个3x3卷积,每个卷积都有一个ReLU。由于在每次卷积中边界像素的损失,裁剪是必要的。在最后一层,使用1x1卷积将每个64个分量的特征向量映射到所需的类数,这个网络总共有23个卷积层。
右侧进行反卷积上采样,但因为卷积进行的下采样会导致部分边缘信息的丢失,失去的特征并不能从上采样中找回,因此作者采用了特征拼接操作来弥补,后续FPN貌似是延用了这一思想,通过横向连接将低分辨率语义强的特征和高分辨率语义弱的特征结合起来。
class deconv2d_bn(nn.Module):
def __init__(self,in_channels,out_channels,kernel_size=2,strides=2):
super(deconv2d_bn,self).__init__()
self.conv1 = nn.ConvTranspose2d(in_channels,out_channels,
kernel_size = kernel_size,
stride = strides,bias=True)
self.bn1 = nn.BatchNorm2d(out_channels)
def forward(self,x):
out = F.relu(self.bn1(self.conv1(x)))
return out上采样是通过 deconv2d_bn 类实现的。具体来说,deconv2d_bn 类使用了 nn.ConvTranspose2d 这个 PyTorch 中的函数来进行上采样操作。在 U-Net 中,上采样是通过反卷积(转置卷积)层实现的。
在 Unet 类的 forward 方法中,你可以看到这样的部分代码:
convt1 = self.deconv1(conv5)
convt2 = self.deconv2(conv6)
convt3 = self.deconv3(conv7)
convt4 = self.deconv4(conv8)
这些部分使用了 deconv2d_bn 类来进行上采样操作,将特征图的大小调整为原始输入图像的大小,以便进行后续的特征融合和预测。
2.FCN
在FCN中,典型的结构包括编码器(Encoder)和解码器(Decoder)部分。编码器部分通常由预训练的卷积神经网络(如VGG、ResNet等)组成,用于提取输入图像的特征。然后,解码器部分通过上采样操作将编码器部分得到的低分辨率特征图恢复到输入图像相同的分辨率,从而得到像素级别的语义分割结果。
FCN通过转置卷积、双线性插值达到了以下效果:
-
恢复空间信息:在卷积过程中,由于池化操作等因素,图像的空间信息被逐渐丢失。上采样能够将特征图的分辨率提高,从而恢复空间信息,使网络更好地理解图像中的细节和结构。
-
提高分割精度:在语义分割任务中,精确的像素级别的预测非常重要。通过上采样,可以获得更高分辨率的特征图,从而提高分割的精度和准确性。
-
增加感受野:通过上采样,可以扩大特征图的大小,使得每个像素点能够感知更广阔的上下文信息,从而提高网络对图像的理解能力。
另一种连接粗糙输出到dense像素的方法就是插值法。比如,简单的双线性插值计算每个输出y_ij来自只依赖输入和输出单元的相对位置的线性图最近的四个输入。
从某种意义上,伴随因子f的上采样是对步长为1/f的分数式输入的卷积操作。只要f是整数,一种自然的方法进行上采样就是向后卷积(有时称为去卷积)伴随输出步长为f。这样的操作实现是不重要的,因为它只是简单的调换了卷积的顺推法和逆推法。所以上采样在网内通过计算像素级别的损失的反向传播用于端到端的学习。
需要注意的是去卷积滤波在这种层面上不需要被固定不变(比如双线性上采样)但是可以被学习。一堆反褶积层和激励函数甚至能学习一种非线性上采样。在我们的实验中,我们发现在网内的上采样对于学习dense prediction是快速且有效的。我们最好的分割架构利用了这些层来学习上采样用以微调预测
class FCN(nn.Module):
def __init__(self, out_channel=21):
super(FCN, self).__init__()
#self.backbone = models.resnet101(pretrained=True) #旧版本写法
self.backbone = models.resnet101(weights = models.ResNet101_Weights.IMAGENET1K_V1)
# 4倍下采样 256
self.stage1 = nn.Sequential(*list(self.backbone.children())[:-5])
# 8倍下采样 512
self.stage2 = nn.Sequential(list(self.backbone.children())[-5])
# 16倍下采样 1024
self.stage3 = nn.Sequential(list(self.backbone.children())[-4])
# 32倍下采样 2048
self.stage4 = nn.Sequential(list(self.backbone.children())[-3])
self.conv2048_256 = nn.Conv2d(2048, 256, 1)
self.conv1024_256 = nn.Conv2d(1024, 256, 1)
self.conv512_256 = nn.Conv2d(512, 256, 1)
self.upsample2x = nn.Upsample(scale_factor=2)
self.upsample8x = nn.Upsample(scale_factor=8)
self.outconv = nn.Conv2d(256, out_channel, kernel_size=3, stride=1, padding=1)总结
以语义分割任务为背景,通过分析U-net、FCN等经典网络结构,介绍上采样(up-sampling)技术在神经网络模型中的应用