此为观看视频What is NLP (Natural Language Processing)?后的笔记。
你正在看这个视频,试图理解作者说的单词和句子,当我们要求计算机做到这一点时,这就是 NLP,即自然语言处理。 NLP 在人工智能应用中实用价值很高。NLP 从非结构化文本开始,也就是你和我所说的。 例如,我说“将鸡蛋和牛奶添加到我的购物清单中”,你很容易理解,但对于计算机来说它是非结构化的。
我们需要把非结构化转换为结构化,例如:
{
"action": "add",
"items": ["eggs", "milk"],
"list": "shopping"
}
NLP其实就是在这两者间进行翻译,从非结构化到结构化就是NLU(自然语言理解),从结构化到非结构化就是NLG(自然语言生成),本视频主要谈NLU。
翻译时,我们不能简单的逐个单词翻译,而需要理解该句子的上下文(内容的整体结构和背景)。NLP就非常适合机器翻译的场景。
第二个用例是虚拟助手或聊天机器人,就像手机上的 Siri 或 亚马逊的虚拟助手 Alexa 一样,它可以接收人类的话语并派生出要执行的命令。 聊天机器人采用书面语言,然后遍历决策树以采取行动。
另一个用例是情感分析。 从文本(电子邮件或产品评论)得出其中表达的情感,是积极的还是消极的情绪?是严肃的陈述还是轻松的揶揄?
最后一个例子是垃圾邮件检测,如果在邮件内容中找到诸如过度使用的词语、语法错误或不恰当的紧急声明之类,都可能表明这是垃圾邮件。
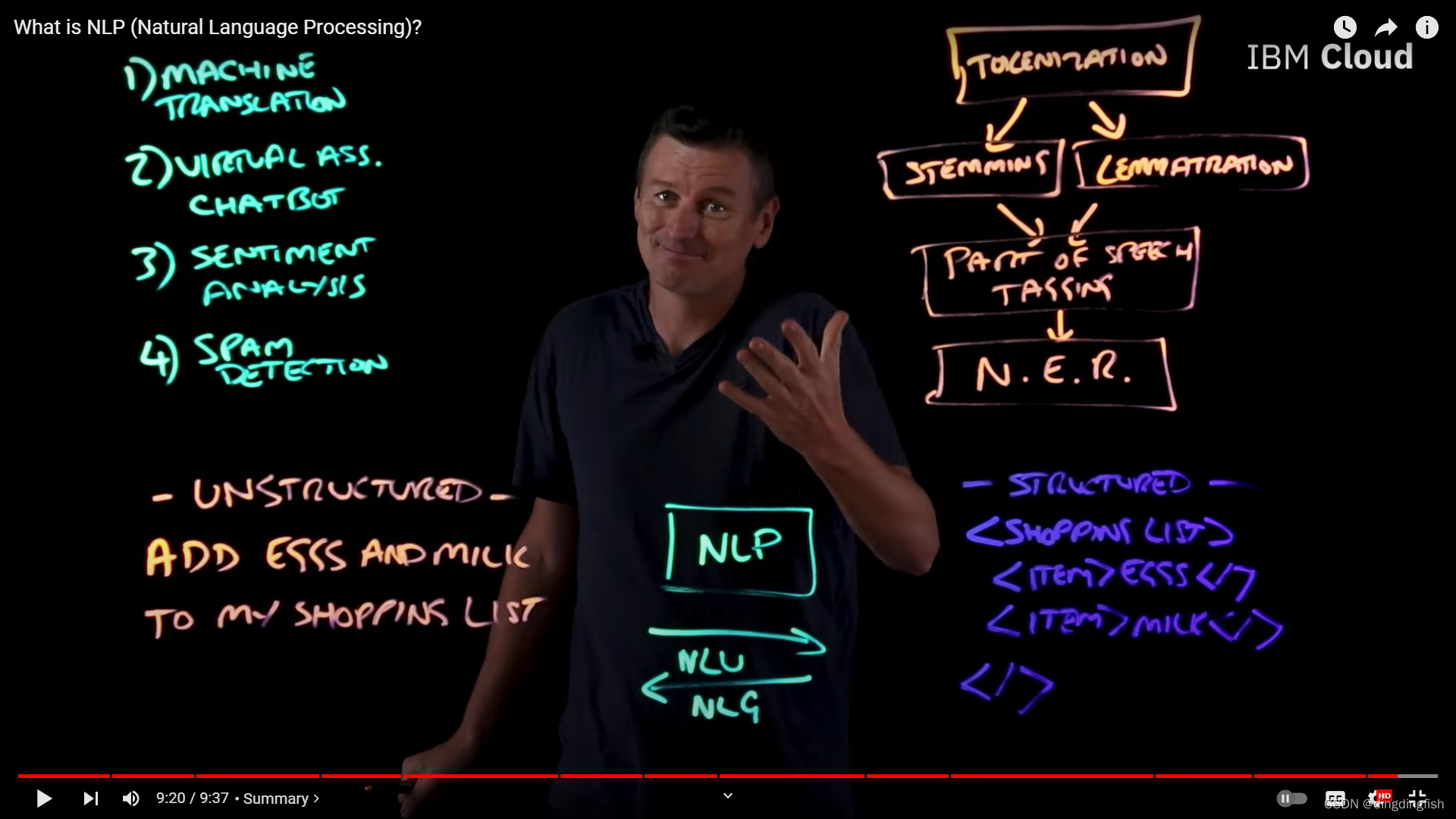
那NLP是如何运作的呢?NLP更像是一个工具包,而不是一个算法。 下面来看一下到底有哪些工具。
NLP 的输入是非结构化文本,如书面的,或由语音转换过来的。NLP 的第一阶段称为标记化(tokenization ),即获取一串文字并将其分解成块(chunk)。例如“add eggs and milk to my shopping list”经标记化后,变为8个标记(token)。然后逐一对标记做词干提取(stemming)。例如running、runs 和 ran的词干都是 run。 删除前缀和后缀并标准化时态,然后我们就得到了词干。
但词干提取并不适用于所有情形。 例如, universal和university的词干并不是universe。此时,我们需要使用另一种工具,称为词形还原(lemmatization)。对于指定的标记,词形还原通过字典定义学习其含义,并从中导出其词根或词元。 以better为例,better源自good,所以better的词根或词目就是good。 如果使用词干提取,则better的处理结果就是bet(显然不对)。所以使用词干提取还是词形还原就很重要。
接下来要做的就是词性标记(part of speech tagging),即根据上下文确定标记(token)的词性或词类,如动词,名词还是形容词。例如对于make,在“I’m going to make dinner”中是动词,在“what make is your laptop?”中则是名词。
最后一个阶段是命名实体识别(Named Entity Recognition,简称NER。其目标是识别文本中的命名实体,并将它们分类为预定义的类别,如人名、地名、组织机构、日期、时间等等。例如Arizona的实体是美国的州,而Ralph的实体是人名。
以上就是在将非结构化的人类语音转化为计算机可以理解的结构化内容过程中,使用的主要NLP工具。一旦完成了这个过程,我们就可以将该结构化数据应用于各种人工智能应用程序。更多信息参见这里。
这篇讲的还挺清晰的,你学废了吗,😉