Linux基础命令之文件处理
1. awk
awk是一种文本处理工具,用于处理结构化文本数据。它基于模式匹配和动作来处理输入数据。以下是一些常用的awk选项和示例:
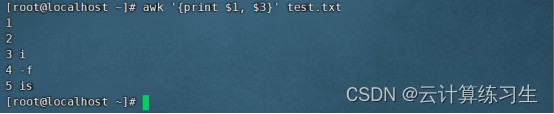
1.1- 打印指定字段:awk '{ print $1, $3 }' input-file(打印输入文件中的第1和第3个字段)
先准备练习所需要的文件和内容
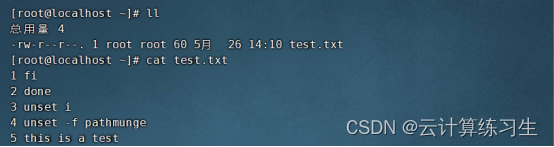
打印输入文件中每一行的第1和第3个字段
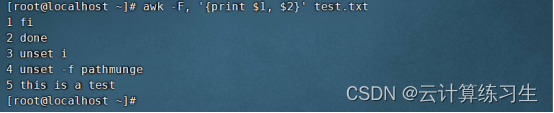
1.2- 使用自定义字段分隔符:awk -F, '{ print $1, $2 }' input-file(使用逗号作为字段分隔符)
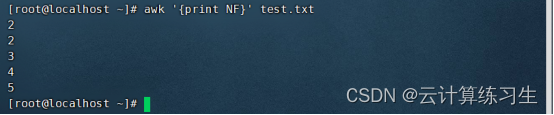
1.3 - 统计每行的总字数 awk ‘{print NF}’ input-file
awk还有很多其他的用法,这是一个非常强大的Linux命令,使用起来比其他命令复杂,这先举个简单的例子,在多学习一些Linux知识之后再去探究awk命令。
2. sed
sed是一种流编辑器,用于对输入数据(文件或管道)执行基本文本转换。以下是一些常用的sed选项和示例:
- 全局替换:
sed 's/pattern/replacement/g' input-file(将输入文件中的所有匹配项替换为指定文本)
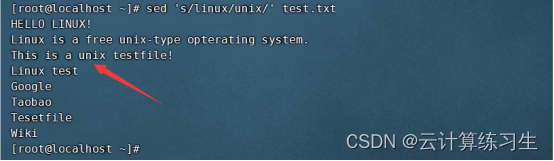
2.1 - 仅替换第一个匹配项:sed 's/pattern/replacement/' input-file
先创建一个用于练习的文件

将匹配到的第一个linux字段换成unix
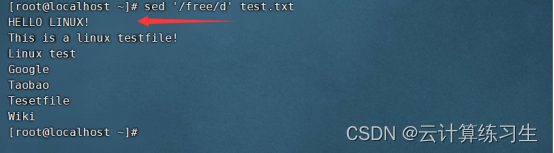
2.2 - 删除匹配行:sed '/pattern/d' input-file
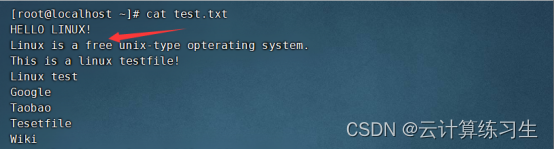
删除有free字段的行
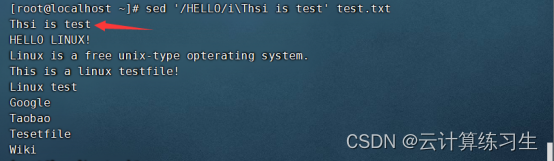
2.3 - 在匹配行之前插入文本:sed '/pattern/i\text-to-insert' input-file
在匹配到HELLO字段的前一行添加内容
2.4 - 在匹配行之后追加文本:sed '/pattern/a\text-to-append' input-file
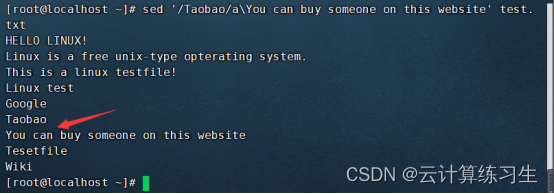
2.5 - 在指定的后面追加内容
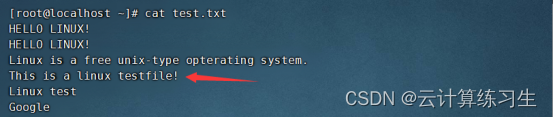
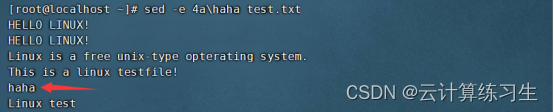
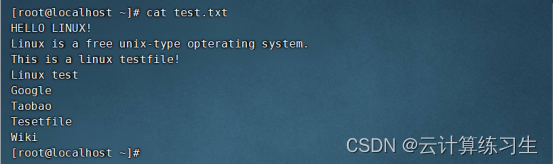
3. sort
sort命令用于对文本文件进行排序。以下是一些常用的sort选项和示例:
3.1 - 按数字顺序排序:sort -n input-file
准备一个文件
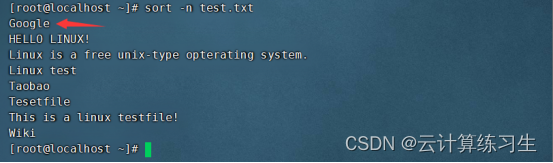
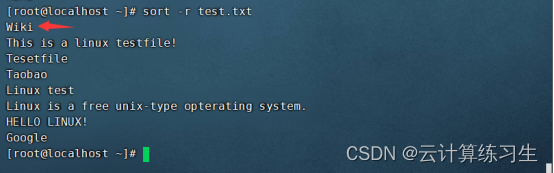
3.2 - 按逆序排序:sort -r input-file
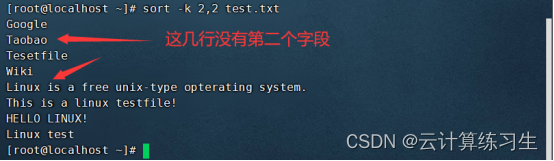
3.3 - 按指定字段排序:sort -k 2,2 input-file(按第2个字段排序)
4. uniq
uniq命令用于从文本文件中删除重复行。以下是一些常用的uniq选项和示例:
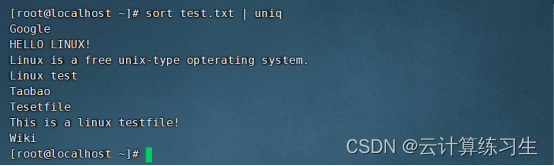
4.1 - 显示唯一行:sort input-file | uniq
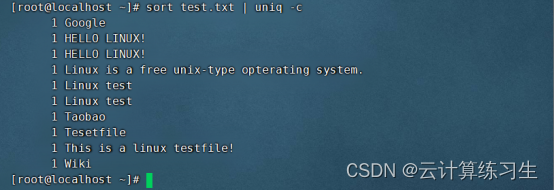
4.2 - 显示重复行及其计数:sort input-file | uniq -c
5. wc
wc命令用于计算文本文件中的行数、单词数和字符数。以下是一些常用的wc选项和示例:
5.1 - 显示行数:wc -l input-file

5.2 - 显示单词数:wc -w input-file

5.3 - 显示字符数:wc -c input-file

5.4 - 显示最长行的长度:wc -L input-file