1. 索引
1.1 分类
- 主键索引、唯一索引、普通索引、组合索引、以及全文索引
主键索引
- 非空唯一索引,一个表只有一个主键索引;
- 在 innodb 中,主键索引的 B+ 树包含表数据信息。
唯一索引
- 不可以出现相同的值,可以有 NULL 值。
普通索引
- 允许出现相同的索引内容。
组合索引
- 对表上的多个列进行索引
全文索引
- 将存储在数据库当中的整本书和整篇文章中的任意内容信息查找出来的技术;
- 关键词 FULLTEXT。
1.2 主键选择
- innodb 中表是索引组织表,每张表有且仅有一个主键;
- 如果显示设置 PRIMARY KEY,则该设置的 key 为该表的主键;
- 如果没有显示设置,则从非空唯一索引中选择;
- 只有一个非空唯一索引,则选择该索引为主键;
- 有多个非空唯一索引,则选择声明的第一个为主键;
- 没有非空唯一索引,则自动生成一个 6 字节的 _rowid 作为主键。
1.3 约束
- 为了实现数据的完整性,对于 innodb,提供了以下几种约束:primary key,unique key,foreign key,default,not null;
- 外键约束:
- 外键用来关联两个表,来保证参照完整性;MyISAM 存储引擎本身并不支持外键,只起到注释作用;而 innodb 完整支持外键, 并具备事务性;
- 约束与索引的区别:
- 创建主键索引或者唯一索引的时候同时创建了相应的约束;但是约束是逻辑上的概念;索引是一个数据结构既包含逻辑的概念也包含物理的存储方式;
2. 索引实现
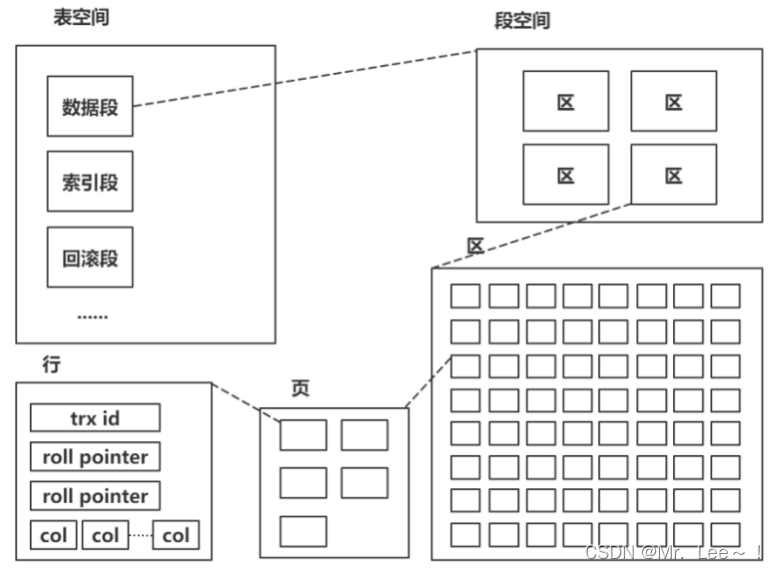
2.1 索引存储
- innodb 由段、区、页组成:
- 段分为数据段、索引段、回滚段等;
- 区大小为 1 MB(一个区由 64 个连续页构成);
- 页的默认值为 16k;页为逻辑页,磁盘物理页大小一般为 4K 或者 8K;为了保证区中的页的连续,存储引擎一般一次从磁盘中申请4~5个区;
- 页是 innodb 磁盘管理的最小单位;默认16K,可通过 innodb_page_size 参数来修改;
- B+ 树的一个节点的大小就是该页的值。
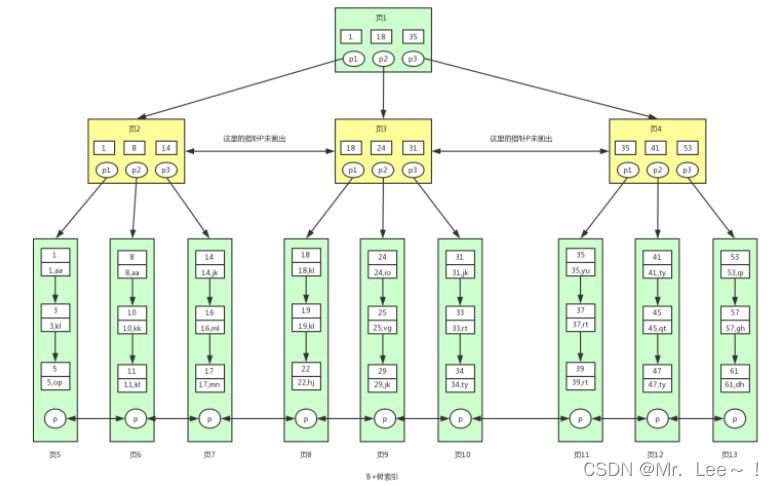
2.2 B+树
- 全称:多路平衡搜索树;
- 用来组织磁盘数据,以页为单位,物理磁盘页一般为 4K,innodb 默认页大小为 16K;
- 对页的访问是一次磁盘 IO,缓存中会缓存常访问的页;
- 特征:非叶子节点只存储索引信息,叶子节点存储具体数据信息;叶子节点之间互相连接,方便范围查询;
- 每个索引对应着一个 B+ 树;
- B+ 树的一个节点对应一个数据页;B+ 树的层越高,那么要读取到内存的数据页越多,IO 次数越多。
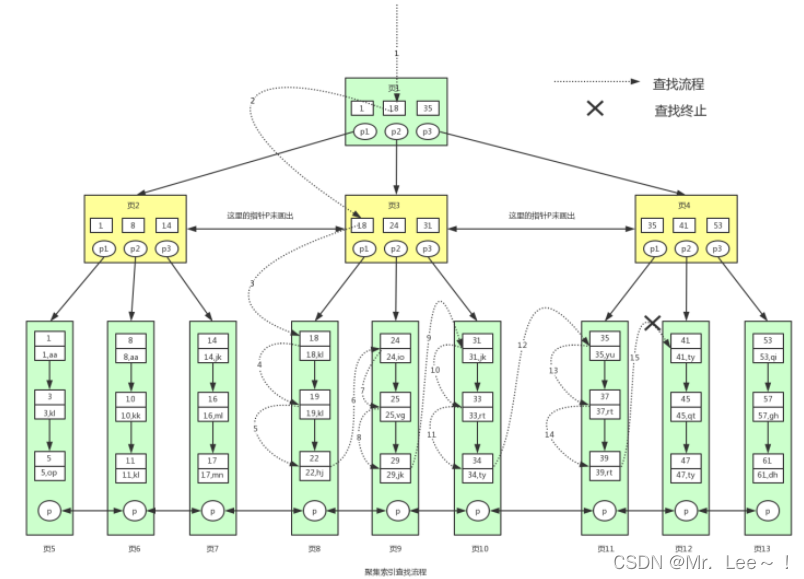
2.3 聚集索引
- 按照主键构造的 B+ 树;叶子节点中存放数据页;数据也是索引的一部分;
- 一个索引代表着一个B+树,修改非主键索引就会修改自己的和聚集索引两个B+树,修改一个元素只需要修改聚集索引的B+树
例子1
slelect * from user where id >= 18 and id < 40;
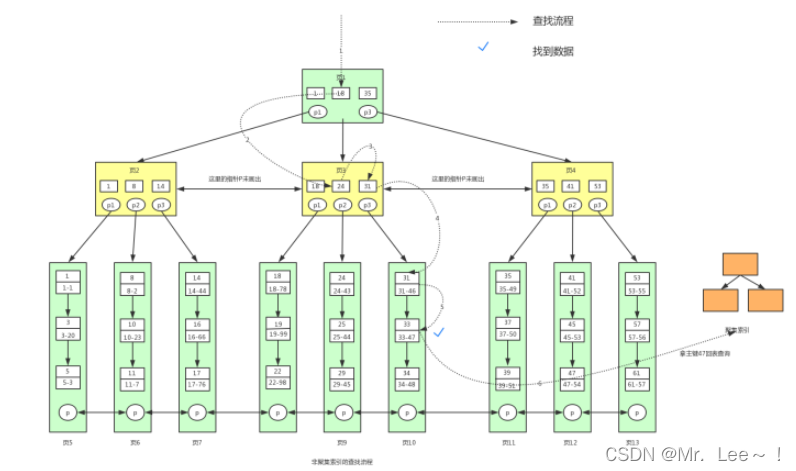
2.4 辅助索引
- 叶子节点不包含行记录的全部数据;辅助索引的叶子节点中, 除了用来排序的 key 还包含一个 bookmark ,用来存储聚集索引的 key。
例子 2
select * from user where lockyNum = 33;
3. innoDB体系结构
- io速度:顺序内存io(数组)>> 随机内存io(红黑树)≈ 顺序磁盘io >> 随机磁盘io
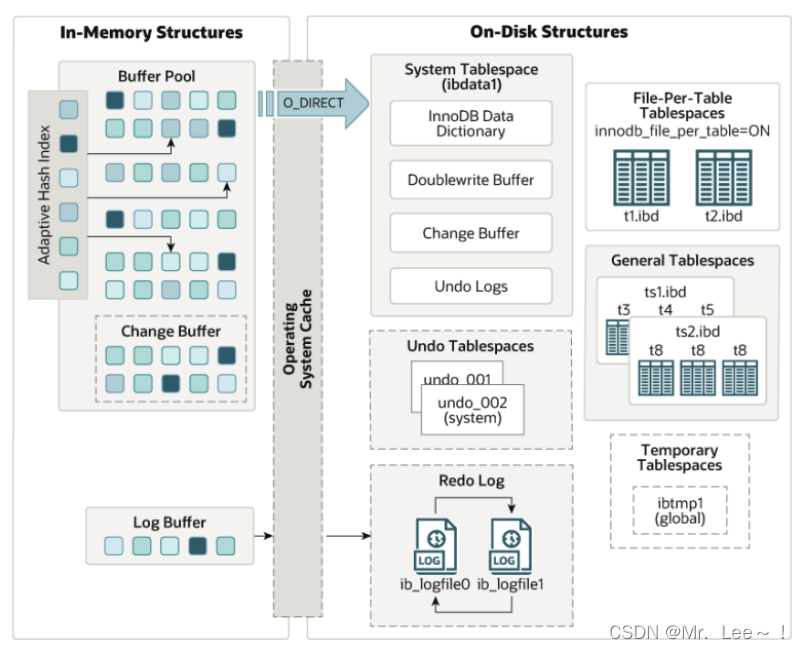
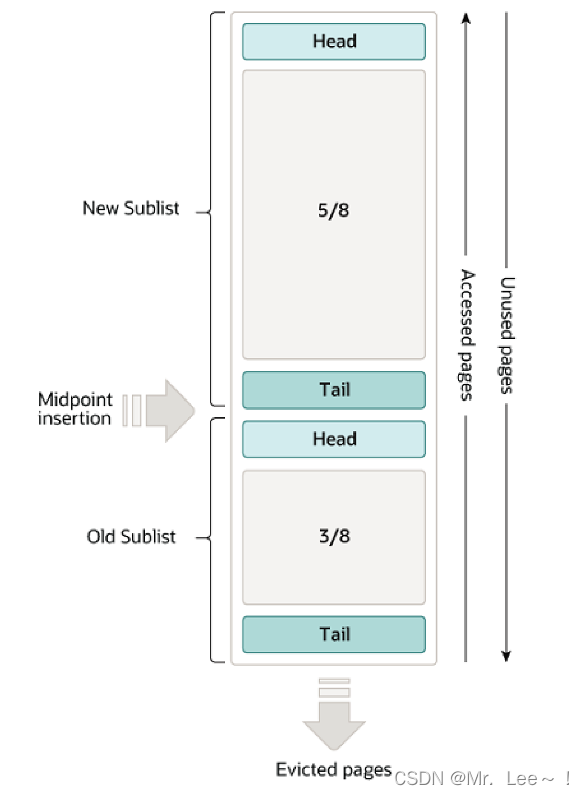
- buffer pool:缓存表和索引数据;采用 LRU 算法(如下图)让 Buffer pool 只缓存比较热的数据。
- change buffer:缓存辅助(二级)索引的数据变更(DML 操作),change buffer 中的数据将会异步 merge 到 buffer pool 中。
- free list 组织 buffer pool 中未使用的缓存页;flush list 组织 buffer pool 中的脏页,也就是待刷盘的页;lru list 组织 buffer pool 中冷热数据,当 buffer pool 没有空闲页,将从 lru list 中最久未使用的数据进行淘汰。

4. 最左匹配原则
- 对于组合索引,从左到右依次匹配,遇到 > < between like 就停止匹配;
- 对于这样一个组合索引
key `name_cid_idx` ( `name`, `cid` )- 会先匹配name,都一样再匹配cid,不会直接就匹配cid
- 如果查询语句没有name只有cid只会进行全表扫描而不是走辅助索引扫描
5. 覆盖索引
- 从辅助索引中就能找到数据,而不需通过聚集索引查找;利用 辅助索引树高度一般低于聚集索引树;较少磁盘 IO。
6. 索引下推(面试经常问到)
- 为了减少回表次数,提升查询效率;在 MySQL 5.6 的版本开始推出;
- MySQL 架构分为 server 层和存储引擎层;
- 没有索引下推机制之前,server 层向存储引擎层请求数据,在 server 层根据索引条件判断进行数据过滤;
- 有索引下推机制之后,将部分索引条件判断下推到存储引擎中过滤数据;最终由存储引擎将数据汇总返回给 server 层。
7. 索引失效
select ... where A and B若 A 和 B 中有一个不包含索引, 则索引失效;- 索引字段参与运算,则索引失效;例如:from_unixtime(idx) = ‘2021-04-30’;
- 索引字段发生隐式转换,则索引失效;例如:将列隐式转换为某个类型,实际等价于在索引列上作用了隐式转换函数;
- LIKE 模糊查询,通配符 % 开头,则索引失效;例如:
select * from user where name like '%Mark'; - 在索引字段上使用 NOT <> != 索引失效;如果判断 id <> 0 则修改为idx > 0 or idx < 0;
- 组合索引中,没使用第一列索引,索引失效。
8. 索引原则
- 查询频次较高且数据量大的表建立索引;索引选择使用频次较高,过滤效果好的列或者组合;
- 使用短索引;节点包含的信息多,较少磁盘 IO 操作;比如: smallint,tinyint;
- 对于很长的动态字符串,考虑使用前缀索引;
- 对于组合索引,考虑最左侧匹配原则和覆盖索引;
- 尽量选择区分度高的列作为索引;该列的值相同的越少越好;
- 尽量扩展索引,在现有索引的基础上,添加复合索引;最多 6 个索引
- 不要 select *; 尽量只列出需要的列字段;方便使用覆盖索引;
- 索引列,列尽量设置为非空;
- 可选:开启自适应 hash 索引或者调整 change buffer;
- mysql遇到字符串和数字比较时,会自动将字符串转换为数字
9. 优化器成本分析
- MySQL 优化器主要针对 IO 和 CPU 会计算语句的成本;可能不会按照分析的原理来执行语句;
- 步骤:
- 找出所有可能需要使用到的索引;
- 计算全表扫描的代价;
- 计算不同索引执行查询的代价;
- 对比找出代价最小的执行方案;