目录
前言
算法提出背景:
贝叶斯算法特点:
一、贝叶斯定理
二、朴素贝叶斯分类模型
1、朴素贝叶斯分类模型(Naive Bayes Classifier)
2、原理
2.1 朴素贝叶斯假设
2.2条件独立性假设
2.3后验概率计算
2.4类别预测
2.5小结
3、建模应用
4、贝叶斯垃圾邮件过滤应用
三、贝叶斯网络推理
四、贝叶斯网络学习
五、总结
优点:
缺点:
应用:
博主介绍:✌专注于前后端、机器学习、人工智能应用领域开发的优质创作者、秉着互联网精神开源贡献精神,答疑解惑、坚持优质作品共享。本人是掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战,深受全网粉丝喜爱与支持✌有需要可以联系作者我哦!
🍅文末三连哦🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
前言
贝叶斯网络(Bayesian Network),也称为信念网络(Belief Network)或概率有向无环图(Probabilistic Directed Acyclic Graph,PDAG),是一种用图形表示概率模型的方法,它基于概率推断的贝叶斯定理。贝叶斯网络的背景可以追溯到 1980 年代初期,它是由一些著名的人工智能研究者如Judea Pearl、Peter Spirtes、Clark Glymour等提出和发展起来的。
算法提出背景:
贝叶斯网络的提出源于对概率图模型的研究,旨在解决不确定性推理问题。传统的概率图模型有两种主要类型:贝叶斯网络和马尔可夫网络。在贝叶斯网络中,变量之间的关系通过有向边连接来表示,而在马尔可夫网络中,变量之间的关系通过无向边连接来表示。
贝叶斯算法特点:
-
图形化表示: 贝叶斯网络使用有向无环图(DAG)来表示变量之间的依赖关系,图中的节点表示随机变量,有向边表示变量之间的因果关系或依赖关系。
-
概率推断: 贝叶斯网络基于贝叶斯定理进行概率推断,可以用来计算给定观测数据情况下变量的概率分布,或者用来预测新数据的概率分布。
-
因果推理: 贝叶斯网络可以用来探索变量之间的因果关系,并进行因果推理,即根据已知的因果关系推断其他变量的状态。
-
不确定性建模: 贝叶斯网络可以有效地处理不确定性信息,允许将概率分布的不确定性纳入到推理过程中。
一、贝叶斯定理
贝叶斯定理(Bayes' theorem)是概率论中的一个基本定理,描述了在已知相关信息的情况下,如何更新对事件发生的概率估计。贝叶斯定理的数学表达如下:
其中,表示在观测到事件 B 的条件下事件 A 发生的概率,
表示在事件 A 发生的条件下事件 B 发生的概率,
和
分别表示事件 A 和事件 B 的先验概率。
贝叶斯定理可以解决以下类型的问题:
1. 后验概率计算:已知事件 B 发生的条件下,事件 A 发生的概率是多少?
2. 先验概率更新:当观测到事件 B 发生后,如何更新对事件 A 发生的先验概率?
3. 概率推断:已知事件 A 和 B 之间的关系,如何推断事件 A 和 B 的关联程度?
贝叶斯定理的应用非常广泛,涵盖了各个领域,如机器学习、统计学、医学、金融等。在机器学习中,贝叶斯定理常用于朴素贝叶斯分类器、贝叶斯优化等算法中,用于处理分类、回归、优化等问题。在实际应用中,贝叶斯定理为我们提供了一种有效的概率推断方法,能够更好地利用先验知识和观测数据,进行准确的推断和预测。
二、朴素贝叶斯分类模型
1、朴素贝叶斯分类模型(Naive Bayes Classifier)
基于贝叶斯定理和特征独立假设的一种简单而有效的分类算法。该模型假设给定类别的特征之间是相互独立的,并且通过计算给定类别下各个特征的条件概率来进行分类。尽管朴素贝叶斯分类器存在“朴素”的假设,即特征之间是相互独立的,但在许多实际情况下,该算法仍然表现出惊人的性能。
朴素贝叶斯分类模型(Naive Bayes Classifier)是基于贝叶斯定理和特征独立假设的一种简单而有效的分类算法。该模型假设给定类别的特征之间是相互独立的,并且通过计算给定类别下各个特征的条件概率来进行分类。尽管朴素贝叶斯分类器存在“朴素”的假设,即特征之间是相互独立的,但在许多实际情况下,该算法仍然表现出惊人的性能。
2、原理
朴素贝叶斯分类模型基于贝叶斯定理,利用特征之间的条件独立性,计算给定类别下各个特征的条件概率,然后根据贝叶斯定理计算后验概率,最终确定样本所属的类别。
具体而言,假设有一个包含特征 和类别
的数据集,朴素贝叶斯分类器的计算过程如下:
2.1 朴素贝叶斯假设
朴素贝叶斯分类器假设特征之间是相互独立的,即给定类别的情况下,特征之间的条件概率是相互独立的。这个假设简化了模型的计算,并且在实际应用中通常能够取得良好的效果。
2.2条件独立性假设
基于朴素贝叶斯假设,我们可以将后验概率展开为特征之间的条件概率的乘积:
根据朴素贝叶斯假设,特征之间是相互独立的,因此可以将条件概率 展开为特征的乘积:
2.3后验概率计算
将条件独立性假设代入贝叶斯定理的表达式中,得到后验概率 的计算公式:
其中,表示类别
的先验概率,
表示在类别
的条件下特征
的条件概率,
是样本
出现的概率。
2.4类别预测
通过计算每个类别的后验概率,选择具有最大后验概率的类别作为样本的预测类别。
2.5小结
朴素贝叶斯分类器的原理基于贝叶斯定理和朴素贝叶斯假设,通过计算类别的后验概率来进行分类。虽然朴素贝叶斯假设简化了模型的计算,但在实际应用中,朴素贝叶斯分类器仍然能够取得良好的分类效果,并且具有简单高效的特点。但也因此存在明显的缺点:
- 特征独立性假设:朴素贝叶斯分类器假设特征之间是相互独立的,这在某些情况下可能不成立,导致分类性能下降。
- 处理连续特征困难:朴素贝叶斯分类器对于连续特征的处理比较困难,通常需要对连续特征进行离散化处理。
- 样本不平衡问题:当数据集中不同类别的样本数量差异较大时,朴素贝叶斯分类器的分类性能可能受到影响。
3、建模应用
生成了80000个随机样本,然后将其划分为训练集和测试集。接着使用高斯朴素贝叶斯分类器对训练集进行训练,并在训练集和测试集上进行预测。最后,使用Matplotlib库可视化了训练数据和测试数据的分类结果。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 生成随机样本
X, y = make_classification(n_samples=80000, n_features=2, n_informative=2, n_redundant=0, random_state=42)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
# 初始化高斯朴素贝叶斯分类器
nb_classifier = GaussianNB()
# 训练模型
nb_classifier.fit(X_train, y_train)
# 进行预测
y_pred_train = nb_classifier.predict(X_train)
y_pred_test = nb_classifier.predict(X_test)
# 计算准确率
train_accuracy = accuracy_score(y_train, y_pred_train)
test_accuracy = accuracy_score(y_test, y_pred_test)
print("Training set accuracy:", train_accuracy)
print("Test set accuracy:", test_accuracy)
# 可视化训练数据和分类结果
plt.figure(figsize=(12, 6))
# 绘制训练数据
plt.subplot(1, 2, 1)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=plt.cm.Paired, marker='o', edgecolors='k')
plt.title('Training Data')
plt.xlabel('Feature1')
plt.ylabel('Feature2')
# 绘制测试数据及分类结果
plt.subplot(1, 2, 2)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_pred_test, cmap=plt.cm.Paired, marker='o', edgecolors='k')
plt.title('Test Data and Classification Results')
plt.xlabel('Feature1')
plt.ylabel('Feature2')
plt.show()
执行结果:随机生成样本80000份,划分2两个样本特征,40%测试集。

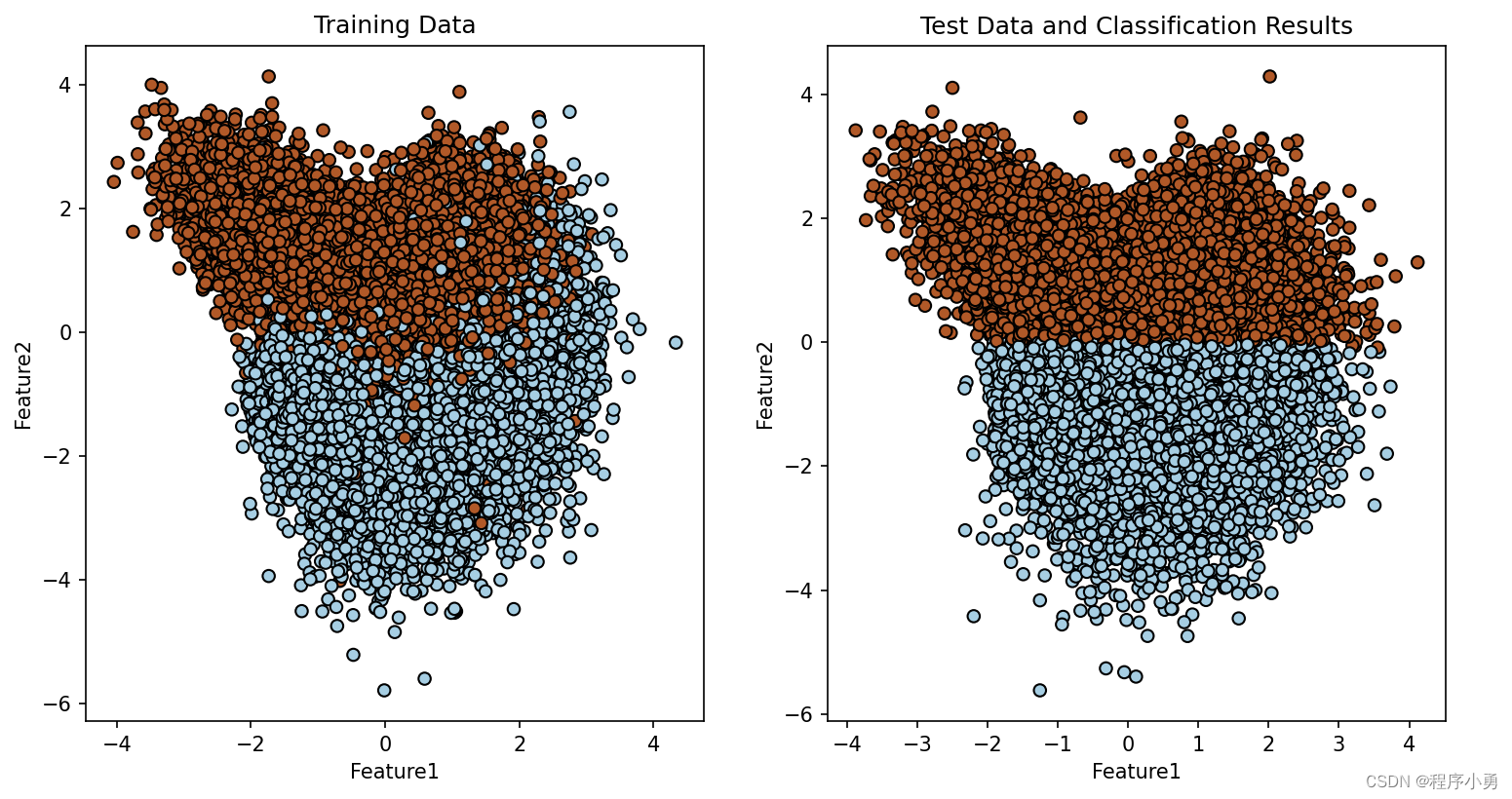
图1 可视化数据分类结果
4、贝叶斯垃圾邮件过滤应用
传统的垃圾邮件过滤方式是关键词过滤,但是这种方法过于绝对,容易出现误判的情况。贝叶斯过滤将会充分考虑关键词在正常邮件和垃圾邮件中出现的概率,可以极大降低失误率。下面我们通过一个案列来展示贝叶斯是如何过滤垃圾邮件的。
具体过程:
- 建立词汇表和训练集:首先,贝叶斯过滤器会建立一个词汇表,并将每个词语与其在垃圾邮件和正常邮件中出现的频率联系起来。为了完成这一步,需要一个已经分类好的训练集,其中包含了大量的垃圾邮件和正常邮件样本。
- 计算词语频率:通过对训练集的学习,贝叶斯过滤器可以计算出每个词语在垃圾邮件和正常邮件中出现的频率。这些频率用于后续计算每个词语在待分类邮件中出现的概率。
- 预处理待分类邮件:当有新的邮件需要分类时,贝叶斯过滤器会对该邮件进行预处理。这通常包括将邮件转化为一个特征向量,该向量包含了待分类邮件中出现的每个词语以及它们的频率。
- 计算概率:根据贝叶斯定理,贝叶斯过滤器可以计算出该邮件属于垃圾邮件和正常邮件的概率。具体来说,它会计算邮件中每个词语在垃圾邮件和正常邮件中的条件概率,并结合这些词语在邮件中的出现频率,来得出最终的分类概率。
- 自我学习功能:贝叶斯过滤器具有自我学习的功能。随着时间的推移,它收到的垃圾邮件越多,其分类的准确率通常会越高。这是因为更多的数据可以帮助过滤器更准确地计算词语的频率和概率。同时为了提高准确率,贝叶斯过滤器通常会考虑多个词语的联合概率,而不仅仅是单个词语的概率。这意味着它会考虑邮件中多个词语的组合,以更准确地判断邮件的类别。
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 随机生成5000的邮件数据
np.random.seed(42)
num_emails = 50000
emails = []
for _ in range(num_emails):
if np.random.rand() < 0.3: # 50% 的邮件是非垃圾邮件
email = ("嘿,Mika!你今天好吗?", 0)
else:
email = ("现在免费获取抽奖获取小米手机!快来!", 1)
emails.append(email)
# 提取特征和标签
X, y = zip(*emails)
# 将文本数据转换为数值特征
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(X)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化并训练分类器
classifier = MultinomialNB()
classifier.fit(X_train, y_train)
# 进行预测
y_pred = classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
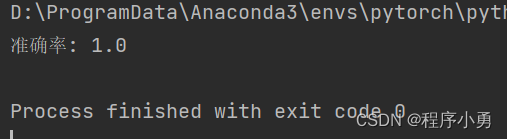
print("准确率:", accuracy)
执行结果:精确率100%
三、贝叶斯网络推理
在贝叶斯网络中,节点表示随机变量,边表示变量之间的依赖关系。推理过程是指在给定一些证据或观察值的情况下,通过贝叶斯网络计算出目标变量的后验概率分布的过程。
推理过程一般可以通过以下几种方法实现:
采样推理(Sampling Inference):通过随机抽样的方式,在贝叶斯网络中进行大量的随机采样,从而近似计算目标变量的后验概率分布。
变量消除推理(Variable Elimination Inference):通过变量消除的方式,逐步削减网络中的变量,最终计算出目标变量的后验概率分布。
精确推理(Exact Inference):对于小规模的贝叶斯网络,可以使用精确推理方法,如枚举法或动态规划,精确地计算出目标变量的后验概率分布。
近似推理(Approximate Inference):对于大规模的贝叶斯网络,精确推理可能变得困难,可以采用一些近似推理方法,如变分推断或马尔可夫链蒙特卡洛法(MCMC),来近似计算目标变量的后验概率分布。
总之,贝叶斯网络的推理过程是通过计算机算法在给定证据的情况下,利用概率论的知识来推断目标变量的概率分布。
四、贝叶斯网络学习
主要分为参数学习和结构学习两种方式。第一种参数学习(Parameter Learning),参数学习是指在已知贝叶斯网络结构的情况下,从数据中学习网络中节点的条件概率分布参数的过程。参数学习可以通过最大似然估计、贝叶斯估计等方法来实现。通过参数学习,可以利用数据来估计贝叶斯网络中每个节点的条件概率分布参数,从而使网络更符合实际数据。第二种是结构学习(Structure Learning),结构学习是指从数据中学习贝叶斯网络的结构的过程。结构学习的目标是发现最优的网络结构,使得网络能够最好地表示数据之间的依赖关系。结构学习可以通过搜索算法(如贪婪搜索、爬山算法)、约束优化方法(如评分函数、信息准则)等方法来实现。结构学习是一个复杂的问题,因为可能存在多个符合数据的网络结构,需要考虑结构的复杂性和有效性。
五、总结
优点:
- 处理复杂关系:贝叶斯网络可以有效地描述大量变量之间的复杂依赖关系。
- 引入先验知识:它允许通过引入先验知识来修正概率分布,从而提高模型的准确性。
- 预测与推断:贝叶斯网络能够进行模型的推断和预测,对未来的情况做出估计。
- 动态建模:它可以逐步加入新的变量,构建动态的模型,适应不断变化的环境。
- 直观性:贝叶斯网络的结构直观,易于理解和解释,有助于揭示变量之间的关联。
缺点:
- 计算复杂度:对于大规模数据或复杂模型,贝叶斯网络的计算复杂度较高,需要较长的计算时间。
- 先验知识的依赖:构建贝叶斯网络需要依赖先验知识。如果先验知识不准确或不完备,可能导致模型预测结果的不准确。
- 非线性关系建模困难:对于变量之间的非线性关系和交互作用,贝叶斯网络的建模可能较为困难。
- 模型可解释性:虽然贝叶斯网络的结构直观,但不同的模型结构可能产生相同的预测结果,这可能导致在某些情况下模型难以解释。
- 数据依赖性:贝叶斯网络对训练数据的依赖较强,如果数据质量不高或数量不足,可能导致模型的不准确。
- 学习过程无法迭代更新:一旦先验概率和似然函数确定,后续的训练数据无法直接影响先验概率的更新,这在面对不断变化的数据时可能是一个问题。
应用:
- 医疗诊断:利用患者的临床数据、病史等构建贝叶斯网络模型,帮助医生进行更准确的疾病诊断和预测。
- 金融风险管理:用于分析客户的信用记录、财务状况等因素,评估信用风险,制定信贷政策。
- 工业控制:用于故障诊断和设备维护,提高设备的可靠性和效率。
- 贝叶斯网络还在决策支持系统、自然语言处理、专家系统等领域发挥重要作用。



![入门指南|营销中人工智能生成内容的主要类型 [新数据、示例和技巧]](https://img-blog.csdnimg.cn/img_convert/78a11014b6cc8c56bb37aa51aa7a1a83.webp?x-oss-process=image/format,png)