大模型
大模型成为发展通用人工智能的重要途径
专用模型:针对特定任务,一个模型解决一个问题
通用大模型:一个模型应对多种任务、多种模态
书生浦语大模型开源历程
2023.6.7:InternLM千亿参数语言大模型发布
2023.7.6:InternLM千亿参数大模型全面升级,支持8K语境、26种语言。 全面开源,免费商用:InternLM-7B模型、全链条开源工具体系
2023.8.14:书生万卷1.0多模态预训练语料库开源发布
2023.8.21:升级版对话,模型InternLM-Chat-7B v1.1发布,开源智能体框架Lagent,支持从语言模型到智能体升级转换 2023.8.28:InternLM千亿参数模型参数量升级到123B
2023.9.20:增强型InternLM-20B开源,开源工具链全线升级
2024.1.17:InternLM2开源
书生浦语2.0(InternLM2)的体系
面向不同的使用需求,每个规格包含三个模型版本
按规格分类
7B:为轻量级的研究和应用提供了一个轻便但性能不俗的模型
20B:模型的综合性能更为强劲,可有效支持更加复杂的使用场景
按使用需求分类
InternLM2-Base:高质量和具有很强可塑性的模型基座,是模型进行深度领域适配的高质量起点
InternLM2:在Base基础上,在多个能力方向进行了强化,在评测中成绩优异,同时保持了很好的通用语言能力,是我们推荐的在大部分应用中考虑选用的优秀基座
InternLM2-Chat:在Base基础上,经过SFT和RLHF,面向对话交互进行了优化,具有很好的指令遵循,共情聊天和调用工具等能力
回归语言建模的本质
新一代清洗过滤技术
多维度数据价值评估:基于文本质量、信息质量、信息密度等维度对数据价值进行综合评估与提升
高质量语料驱动的数据富集:利用高质量语料的特征从物理世界、互联网以及语料库中进一步富集更多类似语料
有针对性的数据补齐:针对性补充语料,重点加强世界知识、数理、代码等核心能力

书生浦语2.0(InternLM2)主要亮点
超长上下文:模型在20万token上下文中,几乎完美实现”大海捞针“
综合性能全面提升:推理、数学、代码提升显著InternLM2-Chat-20B在重点评测上比肩ChatGPT
优秀的对话和创作体验:精准指令跟随,丰富的结构化创作,在AlpacaEval2超越GPT3.5和Gemini Pro
工具调用能力整体升级:可靠支持工具多轮调用,复杂智能体搭建
突出的数理能力和使用的数据分析功能:强大的内生计算能力,加入代码解释后,在GSM8K和MATH达到和GPT-4相仿水平
性能全方位提升
在各能力维度全面进步,在推理、数学、代码等方面的能力提升尤为显著,综合性能达到同量级开源模型的领先水平,在重点能力评测上InternLM2-Chat-20B甚至可以达到比肩ChatGPT(GPT3.5)的水平

工具调用能力升级
工具调用能够极大地拓展大预言模型的能力边界,使得大语言模型能够通过搜索、计算、代码解释器等获取最新的知识冰处理更加复杂的问题,InternLM2进一步升级了模型的工具调用能力,能够更稳定地进行工具筛选和多步骤规划,完成复杂任务
强大内生计算能力
高准确率:InternLM2针对性提高了模型的计算能力,在不依靠计算器等外部工具的情况下,在100以内的简单数学运算上能够做到接近100%的准确率,在1000以内达到80%左右的运算准确率
复杂运算和求解:依赖模型优秀的内生能力,InternLM2不借助外部工具就能够进行部分复杂数学题的运算和求解
代码解释器:更上一层楼
在典型的数学评测集GSM8K和MATH上,配合代码解释器,InternLM2都能够在本身已经较高的分数上,进一步获得提升,其中对于难度更高的MATH数据集,借助代码解释器,精度从32.5大幅提高到51.2,甚至超过了GPT-4的表现。配合代码解释器,20B模型已经能够完成一些例如积分求解等大学级别的数学题目

从模型到应用

流程

书生浦语全链条开源开放体系
数据-书生万卷:2TB数据,涵盖多种模态与任务

预训练-InternLM-Train:并行训练,极致优化,速度达到3600tokens/sec/gpu

微调-Xtuner:支持全参数微调,支持LoRA等低成本微调

部署-LMDeploy:全链路部署,性能领先,每秒生成2000+ tokens

评测-OpenCompass:全方位评测,性能可复现100套评测集,50万道题目
2023年5月1日:完成Alpha版本升级,支持千亿参数语言大模型高效评测
2023年7月6日:OpenCompass正式开源,学术评测支持最完善的评测工具之一,支持5大能力维度,70个数据集,40万评测题目
2023年8月18日:OpenCompass数据和性能对比上线,支持100+开源模型的多维度性能对比
2023年9月7日:支持多编程语言代码评测,发布稳定可复现代码评测镜像,提供多变成语言能力分析和对比
2023年10月26日:联合南京大学推出大模型司法能力评测基准,构建多层能力体系助力法律场景能力分析
2023年12月1日:发布多模态评测工具套件VLMEvalKit,支持包括Gemi、GPT-4V等商业模型评测支持
2024年1月30日:OpenCompass2.0司南大模型评测体系正式发布
应用-Lagent、AgentLego:支持多种智能体,支持代码解释器等多种工具


InternLM2技术报告网址
2403.17297.pdf (arxiv.org)
报告综述
InternLM2技术报告是由上海人工智能实验室、商汤科技、香港中文大学以及复旦大学的研究团队共同撰写。InternLM2是一个开源的大型语言模型(LLM),在多个维度和基准测试中表现出色,特别是在长文本建模和开放式主观评估方面。该模型采用了创新的预训练和优化技术,以提高性能。
报告详细介绍了InternLM2的开发过程,包括基础设施、模型结构、预训练数据、预训练设置、预训练阶段、对齐策略、评估和分析以及结论。特别强调了InternLM2在处理长文本方面的能力,以及通过监督式微调(SFT)和基于人类反馈的条件在线强化学习(COOL RLHF)策略来提高与人类指令的一致性和价值观的对齐。
报告还讨论了数据准备、模型训练、性能评估和潜在的数据污染问题。此外,报告提供了对InternLM2在不同训练阶段的模型性能的深入分析,并与现有的大型语言模型进行了比较。
(此信息由Kimi.AI生成)
介绍
自从ChatGPT和GPT-4的出现以来 (OpenAI, 2023),大型语言模型(LLMs)在学术界和工业界迅速走红。训练在数十亿令牌上的模型展现了深刻的情感理解和问题解决能力,引发了人们普遍认为AGI时代即将到来的猜测。尽管如此,开发出与ChatGPT或GPT-4相当能力的模型的道路仍然模糊不清。开源社区正在努力缩小专有LLM与开源模型之间的差距。在过去的一年里,如LLaMA (Touvron et al., 2023a;b)、Qwen (Bai et al., 2023a)、Mistral (Jiang et al., 2023)和Deepseek (Bi et al., 2024)等一些显著的开源LLM取得了显著进步。
大型语言模型的发展包括预训练、监督微调(SFT)和基于人类反馈的强化学习(RLHF)等主要阶段 (Ouyang et al., 2022)。预训练主要基于利用大量的自然文本语料库,积累数万亿的令牌。这个阶段的目标是为LLMs配备广泛的知识库和基本技能。预训练阶段的数据质量被认为是最重要的因素。然而,过去关于LLM的技术报告 (Touvron et al., 2023a;b; Bai etal., 2023a; Bi et al., 2024)很少关注预训练数据的处理。InternLM2详细描述了如何为预训练准备文本、代码和长文本数据。
如何有效地延长LLM的上下文长度目前是研究的热点,因为许多下游应用,如检索增强生成(RAG) (Gao et al., 2023)和代理模型 (Xi et al., 2023),依赖于长上下文。InternLM2首先采用分组查询注意力(GQA)来在推断长序列时减少内存占用。在预训练阶段,我们首先使用4k个上下文文本训练InternLM2,然后将训练语料库过渡到高质量的32k文本进行进一步训练。最终,通过位置编码外推 (LocalLLaMA, 2023),InternLM2在200k个上下文中通过了“寻针于干草堆”测试,表现出色。
预训练后,我们使用监督微调(SFT)和基于人类反馈的强化学习(RLHF)来确保模型能很好地遵循人类指令并符合人类价值观。我们还在此过程中构建了相应的32k数据,以进一步提升InternLM2的长上下文处理能力。此外,我们引入了条件在线RLHF(COOLRLHF),它采用条件奖励模型来协调多样但可能冲突的偏好,并通过多轮Proximal Policy Optimization(PPO)来缓解每个阶段出现的奖励作弊问题。为了向社区阐明RLHF的影响,我们还发布了预RLHF和后RLHF阶段的模型,分别命名为InternLM2-Chat-{size}-SFT和InternLM2-Chat-{size}。
我们的贡献有两个方面,不仅体现在模型在各种基准测试中的卓越性能,还体现在我们在不同发展阶段全面开发模型的方法。关键点包括
1. 公开发布性能卓越的InternLM2: 我们已经开源了不同规模的模型(包括18亿、70亿和200亿参数),它们在主观和客观评估中都表现出色。此外,我们发布了不同阶段的模型,以便社区分析SFT(规模融合训练)和RLHF(强化学习人类反馈)训练后的变化。
2. 设计具有200k上下文窗口: InternLM2在长序列任务中表现出色,(在”Haystack中的Needle”实验中)使用200k上下文几乎完美地识别出所有”针”。此外,我们分享了在所有阶段(预训练、SFT1和RLHF2 )训练长序列语言模型的经验。
3. 全面的数据准备指南:我们详细阐述了LLMs的数据准备, 包括预训练数据、 领域特定增强数据、SFT数据和RLHF数据。这些详细内容将有助于社区更好地训练LLMs。(Pre-training data, domain-specific enhancement data, SFT data, RLHF data)
4. 创新的RLHF训练技术: 我们引入了条件在线RLHF(COOL RLHF),以协调不同的偏好,显著提高了InternLM2在各种主观对话评估中的性能。我们还进行了初步的主观和客观RLHF结果的分析和比较,为社区提供了RLHF的深入理解。(RLHF:Reinforcement Learning with Human Feedback)
基础设施
InternEvo
模型训练使用高效的轻量级预训练框架InternEvo进行模型训练。这个框架使得我们能够在数千个GPU上扩展模型训练。它通过数据(Data Parallelism)、张量(Tensor Parallelism,2019)、序列(Sequence Parallelism, 2023)和管道(Pipeline Parallelism, 2019)并行技术来实现这一点。为了进一步提升GPU内存效率,InternEvo整合了各种Zero RedundancyOptimizer (ZeRO, 2020)策略,显著减少了训练所需的内存占用。此外,为了提高硬件利用率,我们还引入了FlashAttention技术(2023)和混合精度训练(Mixed Precision Training, 2017),使用BF16。当在数千个GPU上训练InternLM时,InternEvo展现出强大的扩展性能。如图所示,当8个GPU,全局批次大小为400万个令牌训练InternLM-7B时,InternEvo实现了64%的模型计算量利用率(MFU)。
当扩展到1024个GPU时,尽管保持相同的全局批次大小,InternEvo仍能维持惊人的53% MFU。这种级别的扩展性能尤其具有挑战性,因为批次大小保持不变,而随着GPU数量的增加,计算与通信的比例会降低。相比之下,DeepSpeed(2020)在使用ZeRO-1(2020)和MiCS(2022)在1024个GPU上训练InternLM-7B时,只能达到大约36%的MFU。
InternEvo在序列长度方面也表现出强大的扩展性, 支持训练不同规模的LLM, 例如在256,000个令牌的序列长度下训练InternLM-7B, 可以达到接近88%的MFU。 相比之下,DeepSpeed-Ulysses和Megatron-LM只能达到大约65%的MFU。对于更大规模的LLM,如300亿或700亿参数的模型,训练性能的提升也同样明显。

在使用InternEvo训练InternLM-7B模型时的模型浮点运算利用率
Model Structure
Transformer(Vaswani et al. (2017))由于其出色的并行化能力,已经成为过去大型语言模型(LLMs)的首选架构,这充分利用了GPU的威力(Brown et al. (2020); Chowdhery et al.(2023); Zeng et al. (2023))。LLaMA(Touvron et al. (2023a))在Transformer架构基础上进行了改进,将LayerNorm(Ba et al. (2016))替换为RMSNorm(Zhang & Sennrich (2019)), 并采用SwiGLU(Shazeer (2020))作为激活函数,从而提高了训练效率和性能。
自从LLaMA(Touvron et al. (2023a))发布以来,社区积极地扩展了基于LLaMA架构的生态系统,包括高效推理的提升(lla (2023))和运算符优化(Dao (2023))等。为了确保我们的模型InternLM2能无缝融入这个成熟的生态系统,与Falcon(Almazrouei et al.(2023))、Qwen(Bai et al. (2023a))、Baichuan(Yang et al. (2023))、Mistral(Jiang et al. (2023))等知名LLMs保持一致,我们选择遵循LLaMA的结构设计原则。为了提高效率,我们将Wk、Wq和Wv矩阵合并,这在预训练阶段带来了超过5%的训练加速。此外,为了更好地支持多样化的张量并行(tp)变换,我们重新配置了矩阵布局。对于每个头的Wk、Wq和Wv,我们采用了交错的方式,如图2所示。这种设计修改使得可以通过分割或沿最后一个维度连接矩阵来调整张量并行大小,从而增强了模型在不同分布式计算环境中的灵活性。InternLM2的目标是处理超过32K的上下文,因此InternLM2系列模型都采用了分组查询注意力(GQA)(Ainslie et al. (2023)),以实现高速度和低GPU内存下的长序列推理。

不同的权重矩阵布局导致在调整张量并行性(TP)大小时产生不同的复杂性
预训练
预训练数据
LLM的预训练过程深受数据的影响,这是一个复杂的挑战,包括处理敏感数据、涵盖广泛的知识以及平衡效率和质量。本节将描述我们为准备通用领域文本数据、编程语言相关数据以及长文本数据的处理流程。
文本数据
我们的预训练数据集中的文本数据可以根据来源分为网页、论文、专利和书籍。为了将这些来源转化为预训练数据集,我们首先将所有数据标准化为特定格式,按类型和语言分类,并以JSON Lines (jsonl)格式存储。然后,我们对所有数据应用一系列处理步骤,包括基于规则的过滤、数据去重、安全过滤和质量过滤。这最终形成了丰富、安全且高质量的文本数据集
数据处理流程

整个数据处理流程首先将来自不同来源的数据标准化,得到格式化数据(Format data)。接着,通过应用启发式统计规则进行数据筛选,获取清洗数据(Clean data)。然后,使用局部敏感哈希(LSH)方法进行数据去重,得到去重数据(Dedup data)。随后,我们采用复合安全策略过滤数据,得到安全数据(Safe data)。针对不同来源的数据,我们采用了不同的质量过滤策略,最终获得高质量预训练数据(High-quality pre-training data)。
代码数据
编程是LLM的重要技能,它支持各种下游应用,如代码辅助、软件开发和构建工具使用代理。此外,Groeneveld et al.(2024)指出,通过训练代码数据,有可能提升推理能力,因为代码通常比自然语言结构清晰、严谨且可预测。

预训练语料库中的代码数据统计
长上下文数据
处理非常长的上下文(¿32K个令牌)在研究大语言模型(LLMs)中越来越受到关注,这拓宽了应用范围,包括书籍摘要、支持长期对话以及处理涉及复杂推理步骤的任务。预训练数据是扩展模型上下文窗口的关键因素。我们遵循Lv et al. (2024)中提到的长文本预训练数据准备过程,包括额外的实验和讨论。
预训练设置
采用GPT-4的分词方法,因为其在压缩大量文本内容方面的高效性表现出色。我们的主要参考是cl100k词汇表6,它主要包含英语和编程语言的词汇,总共有100,256个条目,其中少量包含了不到3,000个中文词汇。为了优化InternLM处理中文文本时的压缩率,同时保持词汇表总大小在100,000以下,我们精心挑选了cl100k词汇表中的前60,004个词汇,并将其与32,397个中文词汇相结合。另外,我们添加了147个预留词汇,以完成选择,最终的词汇表大小符合256的倍数,从而促进高效的训练。
预训练阶段
用于预训练1.8B、7B和20B模型的总tokens量范围从2.0万亿到2.6万亿。预训练过程分为三个阶段。第一阶段,我们使用不超过4k长度的预训练语料库。第二阶段,我们加入了50%不超过32k长度的预训练数据。第三阶段,我们引入了特定能力增强数据。每个阶段,我们混合了英语、中文和代码数据。
对齐
预训练阶段为语言模型(LLMs)提供了解决各种任务所需的基础能力与知识。我们进一步对其进行微调,以充分激发其潜力,并引导LLMs作为有益且无害的人工智能助手发挥作用。(这通常被称为“对齐”阶段,包括监督微调(SFT)和基于人类反馈的强化学习(RLHF)两个阶段。)在SFT阶段,我们通过高质量的指令数据,对模型进行微调,使其能够遵循多样的人类指令。然后,我们提出了条件在线RLHF(COOL RLHF),它采用了一种新颖的条件奖励模型,能够调和不同类型的偏好,如多步骤推理准确度、有益性、无害性,并通过三轮在线RLHF来减少奖励滥用。在对齐阶段,我们保持LLMs的长序列理解能力,通过在SFT和RLHF过程中使用长序列预训练数据。
Supervised Fine-Tuning
在监督微调(SFT)阶段,我们使用了一个包含1000万条指令数据实例的 dataset,这些实例经过筛选,确保其有用性和无害性。该数据集覆盖了广泛的议题,包括一般对话、自然语言处理任务、数学问题、代码生成和函数调用等。下面的图展示了 SFT 数据主题的详细分布。为了实现对各种任务的灵活表示,我们将数据样本转换为 ChatML 格式(Cha)。7B和20B模型分别使用AdamW优化器,初始学习率为4e-5,进行了一个epoch的训练。

The distribution of SFT data instances.
COOL Reinforcement Learning from Human Feedback
强化学习从人类反馈(RLHF) (Christiano et al., 2017; Ouyang et al., 2022) 是大型语言模型领域的一种创新方法。通过整合人类反馈,RLHF创建了代理人类偏好的奖励模型,利用Proximal Policy Optimization (PPO) (Schulman et al., 2017) 为语言模型提供学习的奖励信号。这种方法使模型能够更好地理解和执行传统方法难以定义的任务。
尽管RLHF取得了成就,但在实际应用中仍存在一些问题。首先,是偏好冲突。例如,在开发对话系统时,我们期望它提供有用的信息(有益)同时避免产生有害或不适当的内容(无害)。然而,实践中这两个偏好往往难以同时满足,因为提供有用信息可能在某些情况下涉及敏感或高风险的内容。现有的RLHF方法 (Touvron et al., 2023b; Dai et al., 2023; Wu et al., 2023) 通常依赖于多个偏好模型进行评分,这也会增加训练流程中的模型数量,从而增加计算成本并降低训练速度。
其次,RLHF面临奖励作弊(reward hacking)的问题,特别是当模型规模增大,策略变得更强大时 (Manheim & Garrabrant, 2018; Gao et al., 2022),模型可能会通过捷径来获取高分,而不是真正学习期望的行为。这导致模型以非预期的方式最大化奖励,严重影响语言模型的有效性和可靠性。为解决这些问题,我们提出条件在线RLHF(COOL RLHF)。COOL RLHF首先引入条件奖励机制来调和多样化的偏好,使奖励模型可以根据特定条件动态地将注意力分配给不同的偏好,从而最优地整合多个偏好。此外,COOL RLHF采用多轮在线RLHF策略,使语言模型能够快速适应新的人类反馈,减少奖励作弊的发生。
Long-Context Finetuning
为了在微调后保持大模型的长序列理解能力,我们沿用了之前工作中的做法,即在SFT(逐句 fine-tuning)和RLHF(强化学习人类反馈)中继续使用长序列预训练数据(Xionget al., 2023)。具体来说,我们使用了两类数据:一类来自书籍的长序列文本,另一类是来自GitHub仓库的数据,通过特定方法进行连接,具体描述如下。
为了提升InternLM2的数据分析能力,我们选择了DS-1000(Lai et al., 2023)中使用的代码库作为核心,包括Pandas、Numpy、Tensorflow、Scipy、Scikit-learn、PyTorch和Matplotlib。然后,我们在GitHub上搜索引用这些核心库的超过10,000颗星的仓库,进行了与预训练相同的筛选和数据清洗过程。
对于每个仓库,我们首先采用深度优先的方法对获取的原始数据进行排序,同时生成简要描述文件内容的提示(如图所示)。接着,我们将处理后的数据按顺序连接,直到达到32,000个字符的长度。实验结果显示,长序列代码数据不仅提高了大模型的长序列理解能力,还提升了代码相关的功能。

长上下文代码数据获取过程的示例
Tool-Augmented LLMs
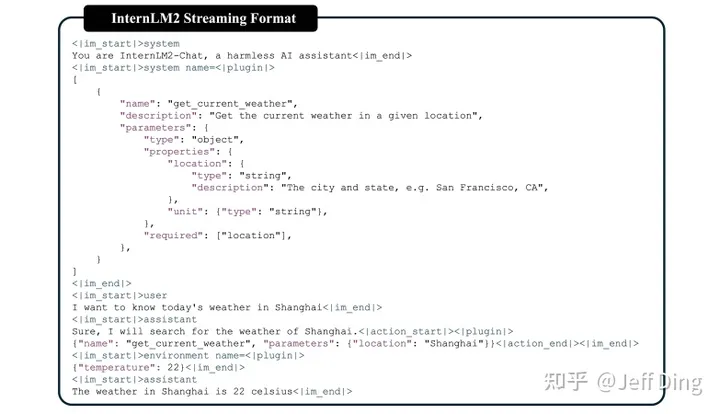
通用工具调用
我们采用经过修改的ChatML格式,通过引入“环境”角色,以支持通用工具的调用。这种修改保持了聊天场景中的格式一致性,但为模型在使用代理时提供了更清晰的信号。此外,我们定义了两个特定的关键字,即代码解释器(<|interpreter|>)和外部插件(<|plugin|>),以支持AI代理的多样化用途。这样,我们就能采用一种统一的流式格式,处理各种类型的插件扩展和AI环境,同时保持与普通聊天的兼容性。图17展示了流式聊天格式的一个具体实例。为了充分激发InternLM2的代理能力,我们将代理语料库与聊天领域对齐,并按照基础语言模型能力进行解耦,以进行精细化训练,如Agent-FLAN(Chen et al., 2024c)所述。
代码解释器
我们还通过将Python代码解释器视为使用工具学习中描述的相同模式的特殊工具,增强了InternLM2-Chat解决数学问题的能力。我们采用推理与编码交互(RICO)策略,并以迭代的硬例挖掘方式构建数据,如InternLM-Math(Ying et al., 2024)中所述。
InternLM2-Chat采用的流式格式示例





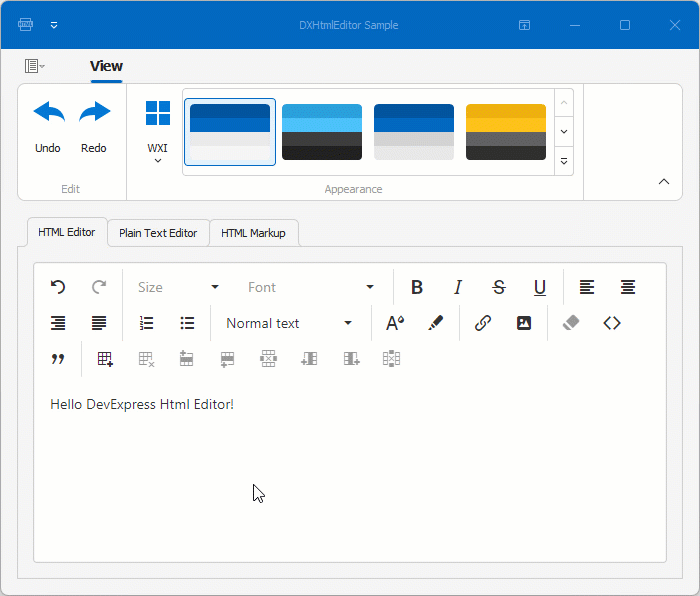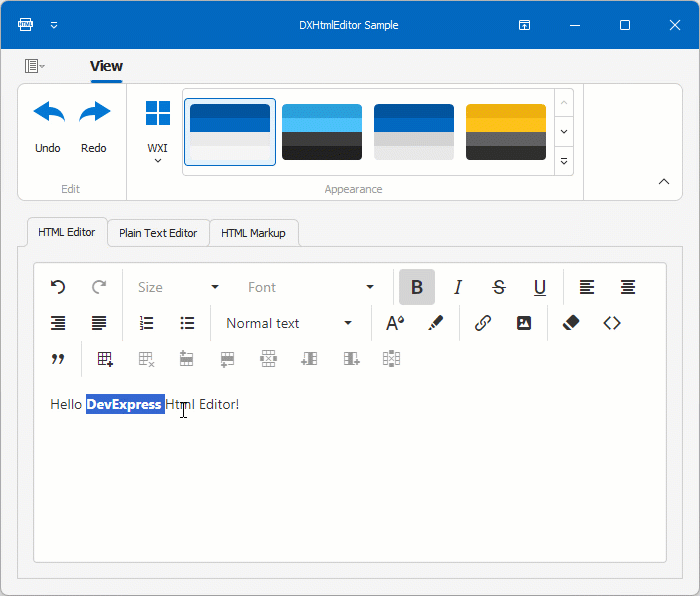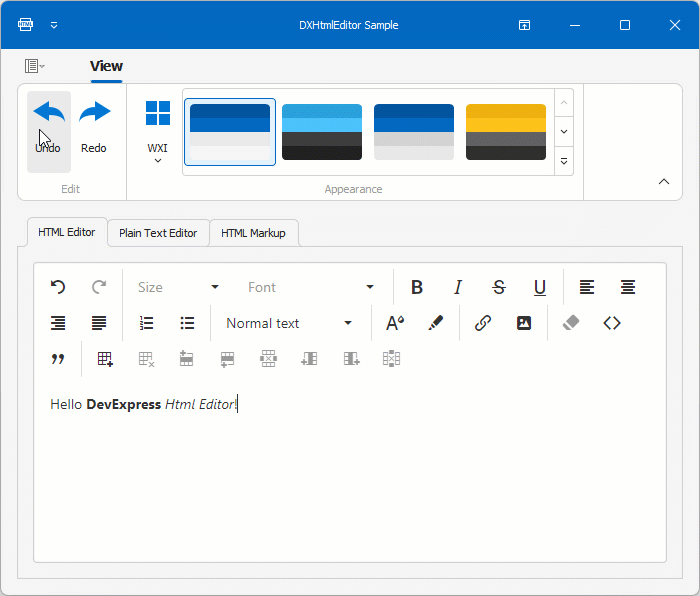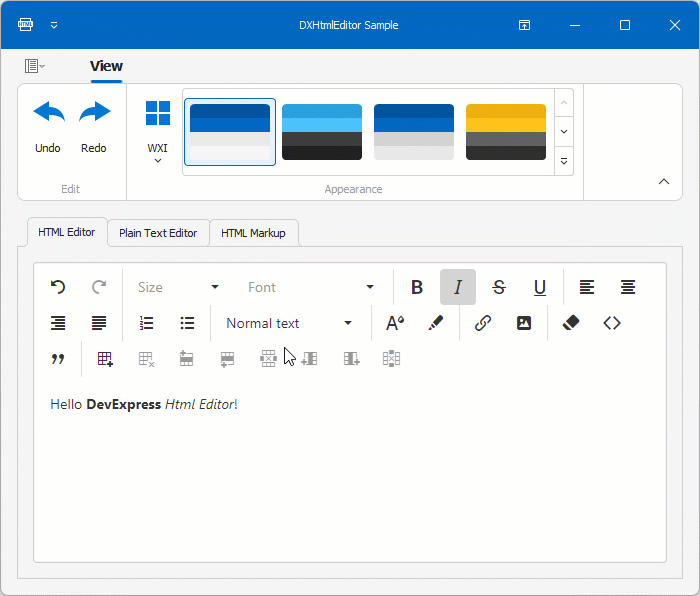

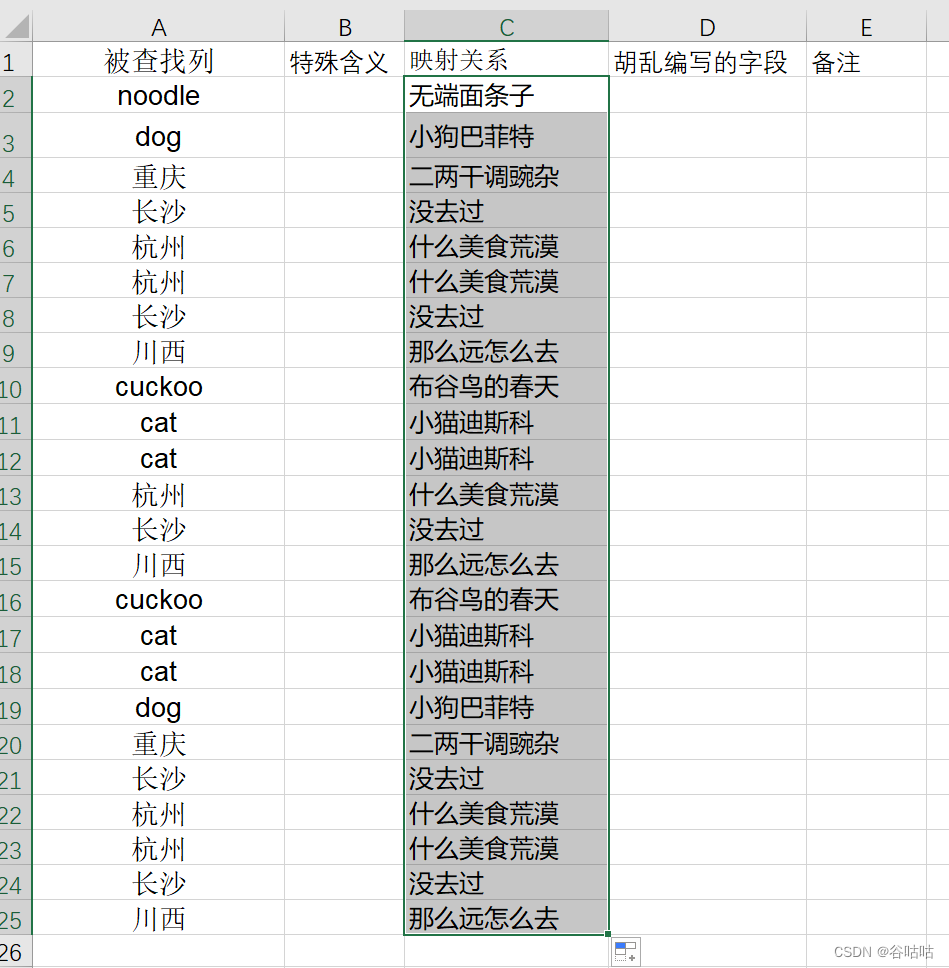
![[Flutter]环境判断](https://img-blog.csdnimg.cn/direct/b9443b429608478e8fc7829dc0094626.png)