一、慢sql的危害
- 不仅对当前查询影响大,查询时间过长;
- 还对其他连接有影响,因为慢sql占用时间过长,导致其他线程,获取连接时间过长,进而导致网关超时等问题;
1.1 explian分析最主要看什么参数
一般实际慢sql,都看Extra。
1.2 创建索引的极端误解

1.3 Using intersect优化建议
- MySQL执行计划选择了单独的N个索引中的2个索引,通过Using intersect算法进行index merge操作,底层执行了两次IO访问,导致时间增长;
- 建议使用复合索引,或者单独使用单条索引通过设计计算上移避免产生索引交集;
- 有时候需要走强制索引;
- 排序的时候,假如数据不多,会在查询内存里排序,即使用到了Using filefort速度还是可以的;
- 但是,如果取出来的列过多(或者limit值过大),查询缓存有一定大小,放不下,那么就会把数据存到文件里去,存到文件里在排序就慢了。
这也就解释了这件事情:
- select 不要用*;
*是查所有列,容易造成数据量大,查询缓存装不下。
1.4 普通索引查询过程
- 找到第一条返回,还要继续找第二天返回…;
通常认为5%的时间是定位数据,95%的时间是用来取数据。
二、mysql锁
说mysql的时候,一定要区分是在service层,还是引擎层;
说锁也要区分是在service层,还是引擎层;
详情请阅读下文:mysql锁
三、大事务与死锁之间的联系
对于减少死锁的建议:
- 不要用RR(可重复读)隔离级别,用RC(读已提交)隔离级别; 因为RR有间隙锁;
大事务的危害:
- mysql的锁只有在事务结束的时候才会释放。也就是含update、insert、for update 等大事务会长期持有锁;
- 大事务会长期占有连接;
- 还会在undo日志上长期不释放;
3.1 举例说明
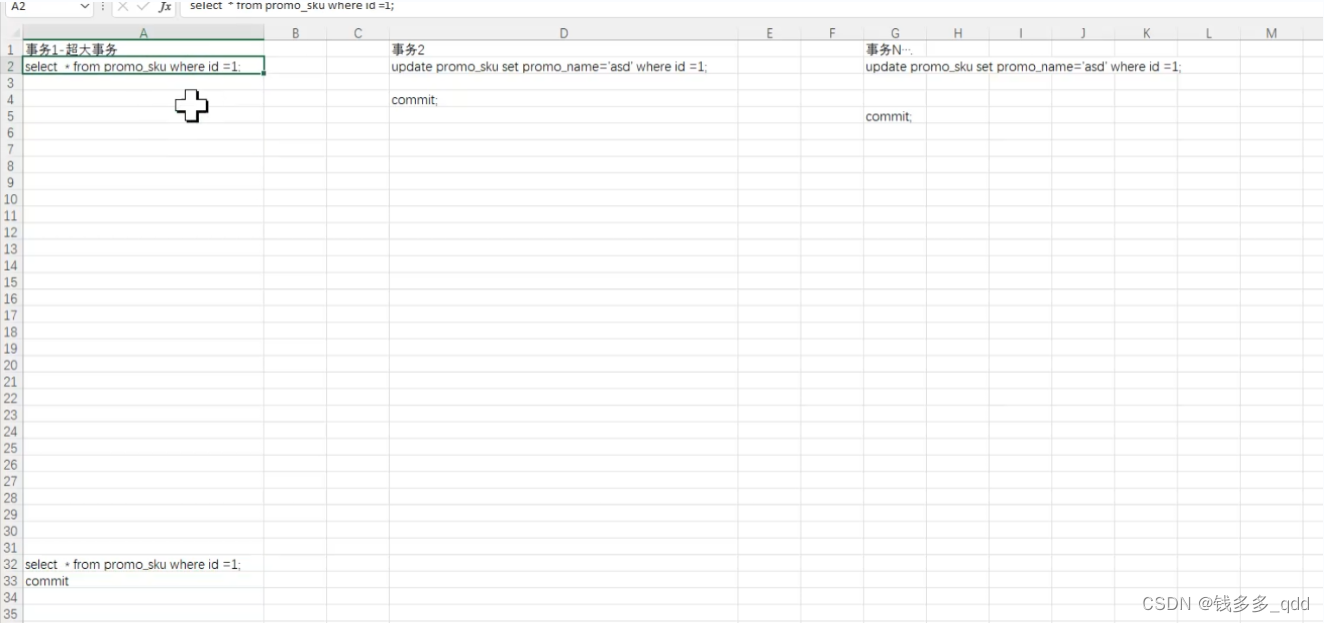
可重复读隔离级别下:
如上图,如果事务1是超大事务,最后一行是查询id=1的数据,事务二…事务N,都在更新id=1的数据,那么事务1中的select * from …会慢吗?
——会慢;
如下图:1不会慢,2会慢:
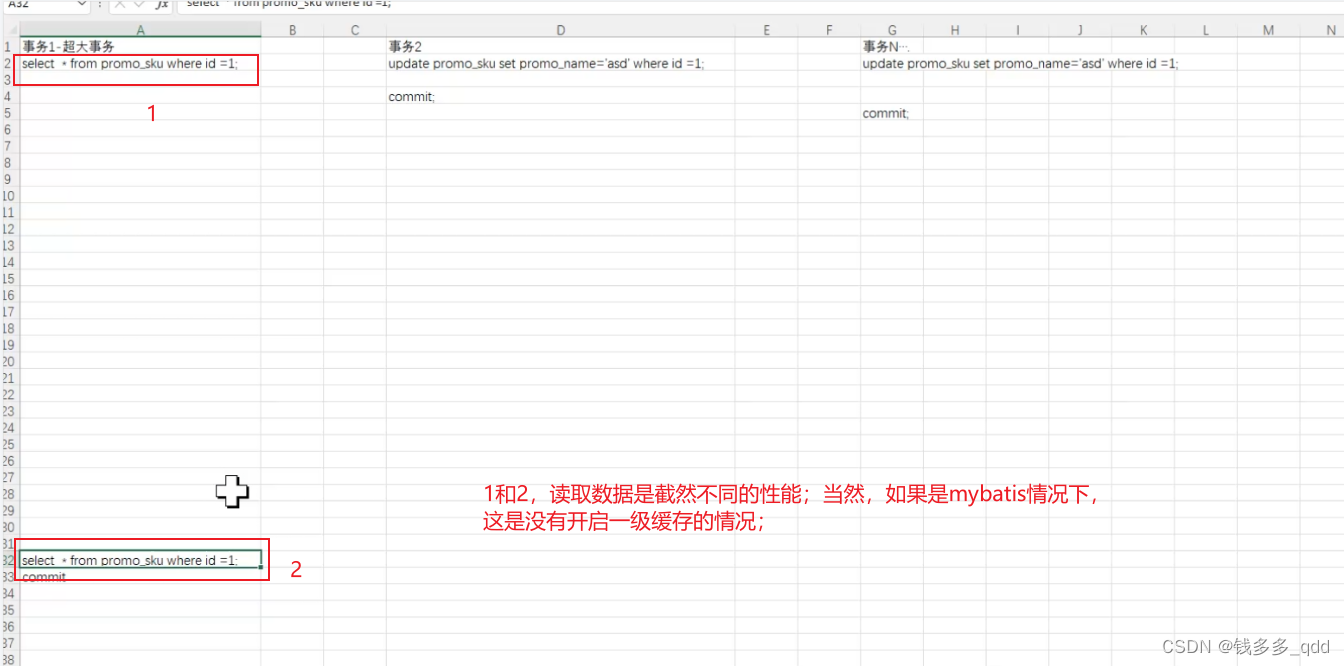
3.2 为什么会慢(可重复读隔离级下)
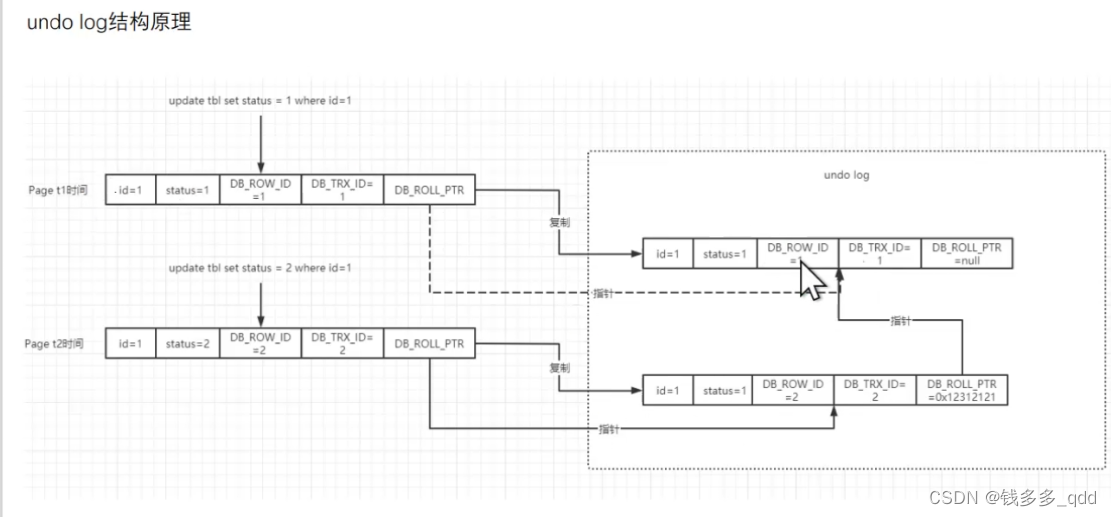
每个事务开始的时候,都会维护一个视图。这个视图记录了每一行的变化点,假设事务1是从t1时间开始记的,有变化就记。
事务2从t2时间开始记。
…事务N…,一直往后记。
那事务1查找id=1的值的过程是怎样的?
——不是说查找完索引再找值就结束了。而是上undo 日志从后往前推,一直推到t1事务的视图,所以 是可能产生慢sql的。
读已提交不会有上面情况;