1.introduction
个性化图像合成,挑战是生成能够准确保留人物的复杂身份细节的定制图像,这类任务通常称之为控ID型任务,在AI写真,虚拟试穿上都有应用,但是和虚拟试装还是有区别的,但技术路线上其实可以考虑复用。人脸ID涉及更微妙的语义,需要更高标准的细节和保真度。当前的个性化生成方法包括两类,1.需要微调的,dreambooth,textual inversion,lora;2.在推断中绕过微调,涉及构建大量领域特定数据,并为特征提取建立一个轻量级适配器,然后,该adapter利用cross-attention将这些特征整合到扩散生成过程中,ip-adapter是代表,采用跨cross-attention将文本和图像特征分离,允许将参考图像作为视觉提示注入其中。然而,这种主要依赖于clip的图像编码器的方法往往只产生弱对齐信号,无法创造高保真度的定制图像。
2.related work
2.1 ID preserving image generation
现有工作主要可根据其对inference时微调的依赖程度分为两类,1.lora,向模型中插入最少数量的新权重,然后lora需要为每个新字符单独训练,2.无优化方法,Face0覆盖了clip空间中用投影人脸嵌入代替最后三个文本标记,并使用联合嵌入作为条件来引导扩散过程。photomarker采用类似方法,但通过微调图像编码器中的transformers层的一部分来增强其提取ID嵌入的能力。FaceStudio将人脸嵌入通过线性投影集成到clip视觉嵌入和clip文本嵌入中,然后将融合的引导嵌入融合到具有cross-attention的unet中。IP-Adapter-FaceID采用了人脸识别模型的人脸ID嵌入代替clip图像嵌入以保持ID的一致性。
3.Methods
只给出一张参考ID图像,InstantID旨在生成自单一参考ID图像多种姿势或风格的定制图像,同时确保高保真度。
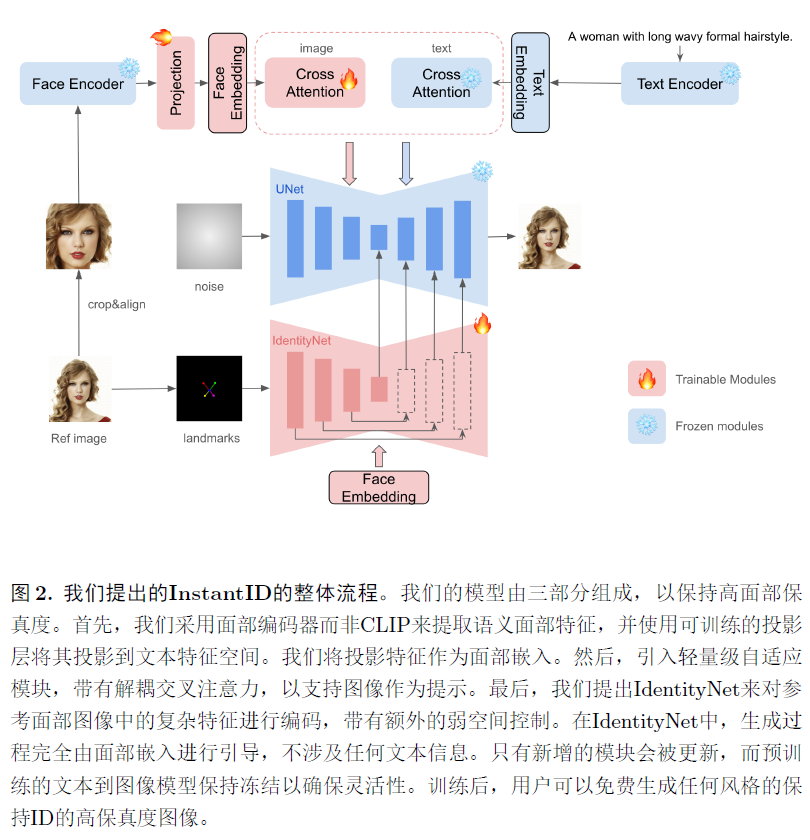
3.1 Methodology
包括三个关键组成部分:1.一种捕获文件语义脸部信息的ID嵌入;2.轻量级的adapter模块,具有解耦的cross-attention;3.IdentityNet,从参考脸部图像中编码详细特征,具有额外的空间控制。
ID embedding. Ip-Adapter,FaceStudio,Photomarker依赖于预训练的clip图像编码进行视觉提示提取,clip的固有限制在于其在弱对齐数据上进行训练,这意味着其编码特征主要捕获宽泛而模糊的语义信息,如构图,风格和颜色。这些特征可以作为文本嵌入的一般补充,但对于需要精确ID保留的任务来说,更强的语义和更高的保真度至关重要。如何有效的将身份特征注入到扩散模型中?
Image Adapter. 在预训练文本到图像扩散模型中的图像提示能力显著增强了文本提示,特别是对于那些用文本难以描述的内容,采用了一个类似于IP-Adapter的策略用于图像提示,引入一个轻量级的adapter模块,解耦的cross-attention,以支持图像作为提示,不同之处在于我们使用ID嵌入作为图像提示,而不是粗略对准的CLIP嵌入。
IdentityNet. 尽管将图像提示与文本提示结合起来,ip-adapter,但只提供了粗粒度的改进,对于保持ID生成图像是不够的,这种限制归因于预训练扩散模型的固有训练机制和属性,例如,当图像和文本提示在attention层之前连接时,模型在对扩散标记序列具有细粒度控制方面表现不佳。然而,在cross-attention中直接添加文本和图像标记会削弱由文本标记施加的控制。此外,试图增强图像标记的强度以实现更高的保真度可能会无意中损害文本标记的编辑能力。
通过采用一种替代controlnet的方法来处理,通常利用空间信息作为可控模块的输入,与扩散模型中unet的设置保持一致,并在cross-attention层中包括文本作为条件元素,核心就是文本和图像都作为提示时,图像会损害文本的能力,因此单独增加了一个只有图像嵌入的unet模块。对controlnet的改进包括,1.仅使用了5个面部关键点作为条件输入,而非openpose面部关键点;2.取消了文本提示,并使用ID嵌入作为controlnet中cross-attention的条件,专注与ID相关的表示。在controlnet中空间控制是至关重要的,只用面部5个点,提供比详细关键点更普遍的约束。
3.2 Training and Inference strategies
训练中,仅优化Image Adapter和IdentityNet的参数,同时保持预训练扩散模型中参数不变,在人类主体的图像文本对上训练整个instantid,不随机丢弃文本和图像,因为已经在IdentityNet中移除了文本提示条件。
4.Experiments
在Laion-face上训练,该数据集包括5000个图像文本对,此外收集了1000w张高质量人类图像,并利用blip2自动生成注释来进一步提高生成质量,专注于单人图像,预训练的人脸模型antelopev2,检测和提取人脸图像中的人脸ID嵌入。在原始人类图像上训练,而不是裁剪过的人脸数据集,训练中,只有Image Adapter和IdentityNet中的参数被更新,而预训练的文本到图像模型保持冻结状态,基于sdxl-1.0模型,并在48块H800(80G)上进行,每块卡的bs为2.