文章目录
- 背景
- 开发环境
- 启动链路
- 问题排查
- pdb调试
- 给文件加共享锁
- 查看进程fd
- strace追踪堆栈
- <br />
- GDB调试python
- 安装gdb和python-dbg
- python-dbg和python版本
- 编译python3.9的dbg文件
- gdb调试
- pytorch多进程卡死问题
- 多进程的fork和spawn模式
- 其他解决方式
- 使用fastapi自带的backgroudTask
- 使用多线程模式
- 个人建议
- 使用celery多进程队列
- 启动两个镜像
- 总结
- 补充问题
- multiprocess多进程使用cuda的问题
- 多次调用multiprocessing.set_start_method的问题
- 解决方案
背景
由于一些原因,打算把点云算法的三维重建和定位打到一个docker镜像里面,统一对外提供服务接口。
算法嘛,需要加载比较大的模型文件,使用多核CPU,使用GPU等资源,因此一开始是打算使用多进程的方式去响应接口请求。
然后就有问题了,启动子进程去三维重建,直接卡死。。
开发环境
ubuntu22.04
python: 3.9
pytorch: 1.13.1
gunicorn+fastapi
启动链路
- 使用gunicorn启动fastapi服务
- 初始化空间定位算法,加载算法模型。初始化三维重建。
- 请求三维重建接口,使用fastapi的multiprocessing开启子进程响应。
- 问题:子进程读取三维重建模型卡死。
问题排查
推测是可能遇到了文件锁的东西,导致进程等待。具体需要排查原因。
pdb调试
遇事不决,可问春风(debug)。第一时间就上pdb,结果pdb到卡住的地方就报错了,报错如下:
File "/usr/local/lib/python3.9/bdb.py", line 88, in trace_dispatch
return self.dispatch_line(frame)
File "/usr/local/lib/python3.9/bdb.py", line 113, in dispatch_line
if self.quitting: raise BdbQuit
bdb.BdbQuit
ERROR:rokidloc_server:reconstruct failed, reason:
# 解释
bdb是pdb的底层库,用于提供断点、单步等功能。该错误消息 "bdb.BdbQuit" 通常出现在
调试器退出时。由于断点、单步等操作是通过向代码中注入信号来完成的,
在程序卡住或被无限循环阻塞时,这些信号无法恰当的注入或被接收处理,
pdb 所在的环境可能变得不可靠或不一致,调试器就会自动退出以防止进一步的问题。
这个博客 在 Python 中使用 GDB 来调试 转载_python gdb-CSDN博客里面也提到了,卡住的进程无法通过pdb进行调试,可以考虑使用GDB调试python程序。
行吧,小趴菜一个。。
给文件加共享锁
一开始总以为是文件锁导致的,就去给读取模型文件的部分加共享锁,读完就释放,如下:
model_path = self.config['weight_path']
with open(model_path, 'rb') as f:
try:
fcntl.flock(f, fcntl.LOCK_SH) # 共享锁定
state_dict = torch.load(f)
finally:
fcntl.flock(f, fcntl.LOCK_UN) # 释放锁
然而并没有什么卵用。
查看进程fd
那么是否可以查看进程fd,看看是否打开了模型文件呢?确认下是否是读取模型文件导致的卡住。
ls -l /proc/pid/fd
# 结果没有看到直接打开模型文件的path
lrwx------ 1 root root 64 Mar 23 18:09 0 -> /dev/pts/1
lrwx------ 1 root root 64 Mar 23 18:09 1 -> /dev/pts/1
l-wx------ 1 root root 64 Mar 23 18:09 10 -> 'pipe:[51968331]'
lr-x------ 1 root root 64 Mar 23 18:09 11 -> 'pipe:[51968350]'
l-wx------ 1 root root 64 Mar 23 18:20 12 -> 'pipe:[51968350]'
# 查看pid启动了多少个子线程
ps -T -p 256
PID SPID TTY TIME CMD
256 256 pts/1 00:00:09 gunicorn
256 289 pts/1 00:00:00 iou-sqp-3015093
256 291 pts/1 00:00:00 gunicorn
256 292 pts/1 00:00:00 gunicorn
256 293 pts/1 00:00:00 gunicorn
256 294 pts/1 00:00:00 gunicorn
256 295 pts/1 00:00:00 gunicorn
256 296 pts/1 00:00:00 gunicorn
256 297 pts/1 00:00:00 gunicorn
256 298 pts/1 00:00:00 gunicorn
# 298就是持有private的锁进程,查看298对应的fd
ls -l /proc/298/fd
# 依然看不到有明确的打开模型文件,不清楚到底卡哪里了
ok,还是失败。
strace追踪堆栈
查看初始化的进程信息
strace -f -p 256
strace: Process 256 attached with 10 threads
[pid 298] futex(0x7fa1f0001200, FUTEX_WAIT_BITSET_PRIVATE|FUTEX_CLOCK_REALTIME, 0, NULL, FUTEX_BITSET_MATCH_ANY <unfinished ...>
[pid 297] futex(0x561186395444, FUTEX_WAIT_PRIVATE, 1064, NULL <unfinished ...>
[pid 296] futex(0x561186395444, FUTEX_WAIT_PRIVATE, 1064, NULL <unfinished ...>
[pid 294] futex(0x561186395444, FUTEX_WAIT_PRIVATE, 1064, NULL <unfinished ...>
[pid 293] futex(0x561186395444, FUTEX_WAIT_PRIVATE, 1064, NULL <unfinished ...>
[pid 292] futex(0x561186395444, FUTEX_WAIT_PRIVATE, 1064, NULL <unfinished ...>
[pid 295] futex(0x561186395444, FUTEX_WAIT_PRIVATE, 1064, NULL <unfinished ...>
[pid 256] epoll_pwait(18, <unfinished ...>
[pid 291] futex(0x561186395444, FUTEX_WAIT_PRIVATE, 1064, NULL <unfinished ...>
# 解释
strace输出的这行信息表示,这条命令表示线程正在等待内存地址0x561186395444上的
futex的值变为1064,在此情况发生之前,这个线程会被阻塞。
FUTEX_WAIT_BITSET_PRIVATE: 这是等待操作。它会让调用进程睡眠,直到另一进程使用
FUTEX_WAKE 操作来唤醒它。
_PRIVATE 后缀表示这个锁只能被同一进程中的其他线程所见,不能被其他进程的线程所见。
查看卡住的进程信息
strace -f -p 135
strace: Process 135 attached
futex(0x555989b08d84, FUTEX_WAIT_PRIVATE, 1064, NULL
# 解释
线程正在等待一个 futex 的值变为 1064。如果在无限等待期间 futex 的值不发生变化,那么线程将一直阻塞。
Futex是什么呢?参考:Futex系统调用,Futex机制,及具体案例分析-CSDN博客
简单来说,Futex是一种用户态和内核态混合的同步机制,一种轻量级的锁。而strace查看的出现的futex是代表进程被挂起等待唤醒。
问题是两个进程都等待唤醒,那就有问题了,表现上就是卡住了。
GDB调试python
安装gdb和python-dbg
参考:使用gdb调试Python程序-CSDN博客
- 查看python-dbg 是否和gdb结合起来了: /usr/share/gdb/auto-load/usr/bin/
- 可以手动设置gdb的auto-load : 参考:https://docs.python.org/3/howto/gdb_helpers.html
- 进入gdb,执行: 参考:https://www.lyyyuna.com/2018/01/01/python-internal4-lldb/
1.gdb python3.10
2.set args test.py
3.run
- gdb -p pid 查看python的堆栈。
- py-bt 查看python堆栈,py-list查看python代码
嗯,看起来很简单,然而实际上立马就遇到了坑。
python-dbg和python版本
python-dbg是gdb可以调试python的关键。而python-dbg和python版本是要一一对应的。
博主python版本是3.9,ubuntu22.04默认的python版本是3.10,就导致安装的python-dbg也是3.10的,因此调试失败。
编译python3.9的dbg文件
- 去github下载cpython,切换到3.9版本,按照自己的python版本来
- 执行编译
1. ./configure --with-pydebug --enable-optimizations
2. make install
3. 根目录看到生成了python, python-gdb.py
4. 默认编译完成之后,会把python复制到/usr/local/bin/
注意: 查看是否把python-gdb.py或者python3.9-gdb.py给copy到/usr/local/bin/下
如果没有copy的话,需要我们手动copy。
cp /xxx/cpython/python-gdb.py /usr/local/bin/python3.9-gdb.py
5. 安装完gdb, 设置gdb的启动配置文件:
vim ~/.gdbinit
add-auto-load-safe-path /usr/local/bin/python3.9-gdb.py
6. gdb python
(gdb) info auto-load
gdb-scripts: No auto-load scripts.
libthread-db: No auto-loaded libthread-db.
local-gdbinit: Local .gdbinit file was not found.
python-scripts:
Loaded Script
Yes /usr/local/bin/python3.9-gdb.py
- 运行python程序,通过gdb查看堆栈
1. ps aux 查看python程序的pid
2. gdb 调试pid : gdb -p pid
3.进入之后,py-bt查看堆栈,py-list查看python程序代码。例如:
(gdb) py-list
39 loop = events.new_event_loop()
40 try:
41 events.set_event_loop(loop)
42 if debug is not None:
43 loop.set_debug(debug)
>44 return loop.run_until_complete(main)
45 finally:
46 try:
47 _cancel_all_tasks(loop)
48 loop.run_until_complete(loop.shutdown_asyncgens())
49 loop.run_until_complete(loop.shutdown_default_executor())
(gdb)
gdb调试
- gdb直接运行python程序: 参考:https://blog.51cto.com/u_16175509/6890013
1.gdb python
2.run test.py
3.b test.py:4
4.continue
- gdb调试在运行中的python程序,也就是通过pid调试
- gdb进去之后,查看当前代码卡在哪了,如图可以看到是44行
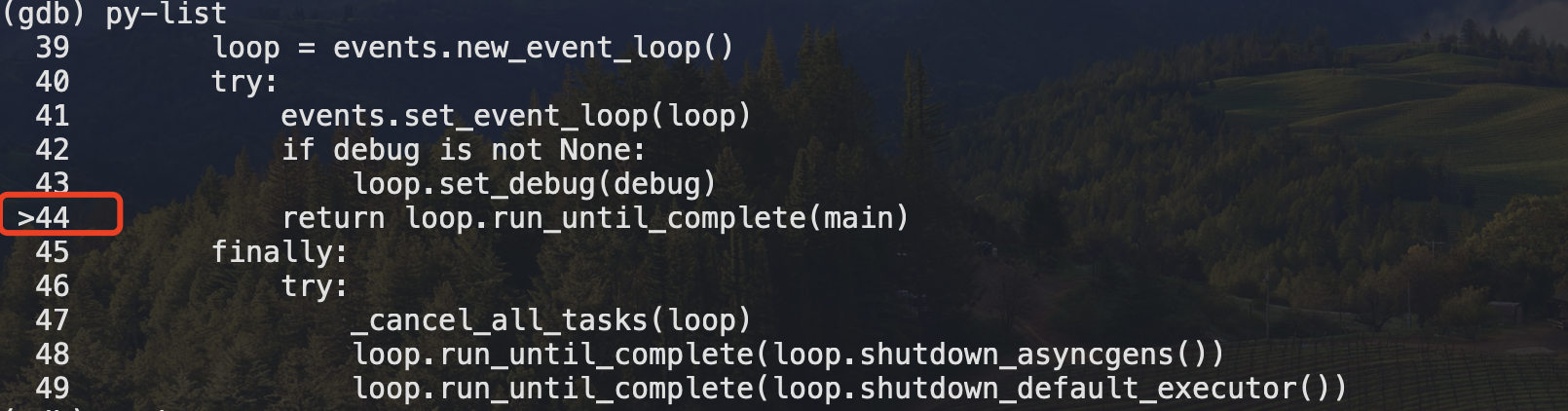
- 查看python的堆栈
- 这个堆栈表示了 Python 应用在 Gunicorn 服务器下的运行路径。
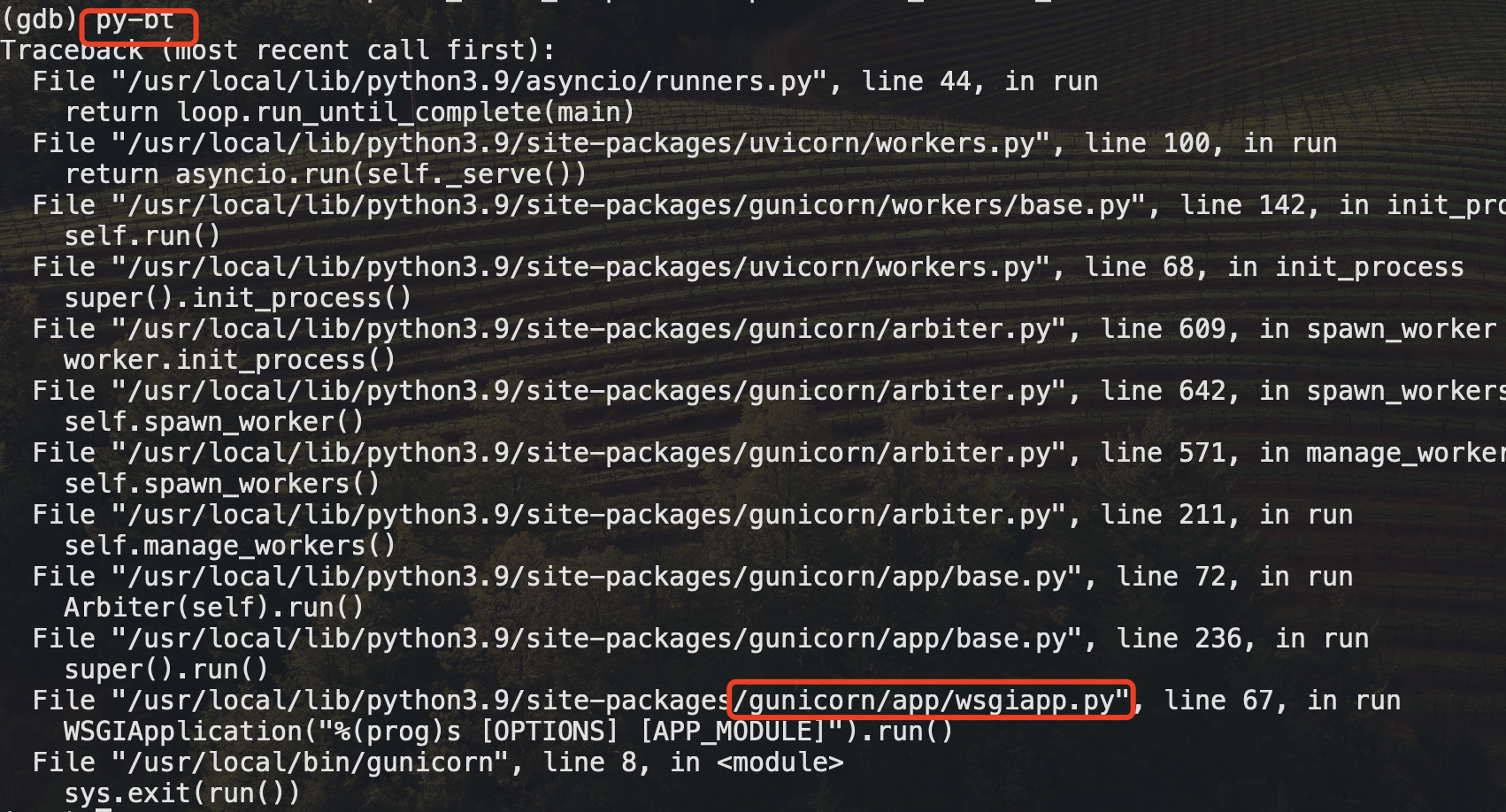
- 查看阻塞进程
- 看报错是pytorch加载模型的报错,加载参数失败,那么要么是模型问题,要么是pytorch版本的问题了。
- gdb进去之后,查看当前代码卡在哪了,如图可以看到是44行
猜测是pytorch的数据加载问题。ok,那就查查pytorch。
pytorch多进程卡死问题
参考:https://blog.csdn.net/kelxLZ/article/details/114591236
- 查看程序是否使用openMp,可以看到是用到了
lsof -p 104 | grep libgomp
gunicorn 104 root mem REG 0,54 168721 9362919 /usr/local/lib/python3.9/site-packages/torch/lib/libgomp-a34b3233.so.1
gunicorn 104 root mem REG 0,54 298776 9185138 /usr/lib/x86_64-linux-gnu/libgomp.so.1.0.0
- 咨询了算法同学,他们在训练的时候,也遇到过这种问题,一般的解决方案是:
# 子进程启动方法设置成spawn模式
torch.multiprocessing.set_start_method('spawn')
- python官网给出的三种进程启动方法
根据不同的平台, multiprocessing 支持三种启动进程的方法。这些 启动方法 有
spawn
父进程会启动一个全新的 python 解释器进程。 子进程将只继承那些运行进程对象的
run() 方法所必需的资源。 特别地,来自父进程的非必需文件描述符和句柄将不会被继承。
使用此方法启动进程相比使用 fork 或 forkserver 要慢上许多。
可在Unix和Windows上使用。 Windows上的默认设置。
fork
父进程使用 os.fork() 来产生 Python 解释器分叉。子进程在开始时实际上与父进程
相同。父进程的所有资源都由子进程继承。请注意,安全分叉多线程进程是棘手的。
只存在于Unix。Unix中的默认值。
forkserver
程序启动并选择 forkserver 启动方法时,将启动服务器进程。 从那时起,每当需要
一个新进程时,父进程就会连接到服务器并请求它分叉一个新进程。 分叉服务器进程是
单线程的,因此使用 os.fork() 是安全的。 没有不必要的资源被继承。
可在Unix平台上使用,支持通过Unix管道传递文件描述符。
在 3.8 版更改: 对于 macOS,spawn 启动方式是默认方式。 因为 fork 可能导致
subprocess崩溃,被认为是不安全的,查看 bpo-33725 。
- 更改成spawn启动,问题解决。
- spawn创建子进程很慢,只能用于耗时不敏感的程序
- spawn会导致有些全局变量无法使用,需要传入进去
多进程的fork和spawn模式
具体的概念就不说了, 主要是看一下通过这两种模式,启动的子进程是什么样子的,父子关系如何。
# apt install psmisc : 方便查看pid的tree
-- fork模式
ps aux
root 88 85 0 21:32 pts/1 00:00:00 /usr/local/bin/python3.9 /usr/local/bin/gunicorn --config=configs/gunicorn.conf.py server.service:app
root 89 88 40 21:32 pts/1 00:00:10 /usr/local/bin/python3.9 /usr/local/bin/gunicorn --config=configs/gunicorn.conf.py server.service:app
root 135 89 1 21:32 pts/1 00:00:00 /usr/local/bin/python3.9 /usr/local/bin/gunicorn --config=configs/gunicorn.conf.py server.service:app
# pstree -p -T 88
gunicorn(88)---gunicorn(89)---gunicorn(135)
pid=88是gunicorn主进程
pid=89是gunicorn的工作worker进程
pid=135是multiprocess fork出来的子进程
---- spawn模式
ps aux
root 59 0.0 0.0 30788 26540 pts/1 S+ 21:16 0:00 /usr/local/bin/python3.9 /usr/local/bin/gunicorn --config=configs/gunicorn.conf.py server.ser
root 60 3.0 1.5 4664492 1026576 pts/1 Sl+ 21:16 0:10 /usr/local/bin/python3.9 /usr/local/bin/gunicorn --config=configs/gunicorn.conf.py server.ser
root 104 0.0 0.0 13468 11612 pts/1 S+ 21:17 0:00 /usr/local/bin/python3.9 -c from multiprocessing.resource_tracker import main;main(36)
root 105 672 1.2 6657676 799780 pts/1 Sl+ 21:17 31:51 /usr/local/bin/python3.9 -c from multiprocessing.spawn import spawn_main; spawn_main(tracker_
pid=104: 第一个进程是资源追踪器 (resource tracker)。资源追踪器的目的是保证当一个程序结束时,其创建的所有资源,如临时文件,都能被正确地清理掉。
pid=105: 第二个进程是实际的子进程,它是通过 spawn 启动方法创建的。在 spawn 模式下,一个全新的Python解释器进程被启动,
主程序的所有代码都需要在这个新的进程中重新导入。
# pstree -p -T 59
gunicorn(59)---gunicorn(60)-+-python3.9(104)
`-python3.9(105)
pid=59是主进程
pid=60是worker进程
pid=104是spawn的监控进程
pid=105是spawn模式启动的子进程
最明显的差别就是spawn启动的子进程是新的python解释器,有点6。
其他解决方式
其实发现程序有bug之后,第一时间就用其他方式解决掉了。这里也记录一下其他的解决方案,供大家参考。
使用fastapi自带的backgroudTask
- backgroundTasks可以完成任务
- 问题在于,无法控制,无法做优雅退出
使用多线程模式
from concurrent.futures import ThreadPoolExecutor
- 可以完成任务,htop发现也能用到多核
- 一样的问题,无法监控状态和优雅退出
个人建议
使用celery多进程队列
使用fastapi + celery的方式,参考:https://derlin.github.io/introduction-to-fastapi-and-celery/03-celery/
这种方式更适合做大型的服务,通过任务队列保证数据安全,通过flower来监控进程状态。
flower参考: https://medium.com/featurepreneur/flower-celery-monitoring-tool-50fba1c8f623
启动两个镜像
三维建图和空间定位都需要用到多核和GPU资源,多线程模式启动更好一些,因此可以考虑部署两个镜像。这也是docker一直主张的原则,粒度尽量小,指责单一,内聚。
总结
当发现这个问题之后,很快就通过多线程的方式暂时解决掉了,依然可以用到多核资源。只是遇到问题不应该退缩,也要把握住每一个解决难题的机会。
出于这种心理,一步步排查最终锁定问题,知其然知其所以然,才能有的放矢的解决根本问题。排查问题的路上也学习了不少东西,值得记录下来。
end
===== 20240327补充 =====
补充问题
multiprocess多进程使用cuda的问题
RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the 'spawn' start method
解决方案,设置进程启动方式为spawn即可。
多次调用multiprocessing.set_start_method的问题
File "/usr/local/lib/python3.9/multiprocessing/context.py", line 243, in set_start_method
raise RuntimeError('context has already been set')
RuntimeError: context has already been set
文档上有解释:参考:https://docs.python.org/zh-cn/3.9/library/multiprocessing.html#multiprocessing.set_start_method
设置启动子进程的方法。 method 可以是 ‘fork’ , ‘spawn’ 或者 ‘forkserver’ 。
注意这最多只能调用一次,并且需要藏在 main 模块中,由 if name == ‘main’ 保护着。
解决方案
a. 如果使用spawn模式,那么只是把multiprocessing.set_start_method放到文件顶部是不够的,每次copy进程都会执行一次。解决方案就是加force参数:
import multiprocessing as mp
# 第二个参数为True
mp.set_start_method('spawn', True)
以上方案虽然解决了报错,但感觉并不完美,强扭的瓜不甜。
b. 通过context设置进程启动方法
import multiprocessing as mp
ctx = mp.get_context('spawn')
ctx.Process()
完美解决这个问题。每次启动子进程,通过上下文去获取进程的启动method,后续启动子进程延续即可。