论文题目:Deconstructing Denoising Diffusion Models for Self-Supervised Learning
原文链接:https://arxiv.org/html/2401.14404v1
本文是对何凯明老师的新作进行的详细解读,其中穿插了一些思考,将从以下四个方面对这篇工作进行一个详细的介绍:

对早期工作的概括
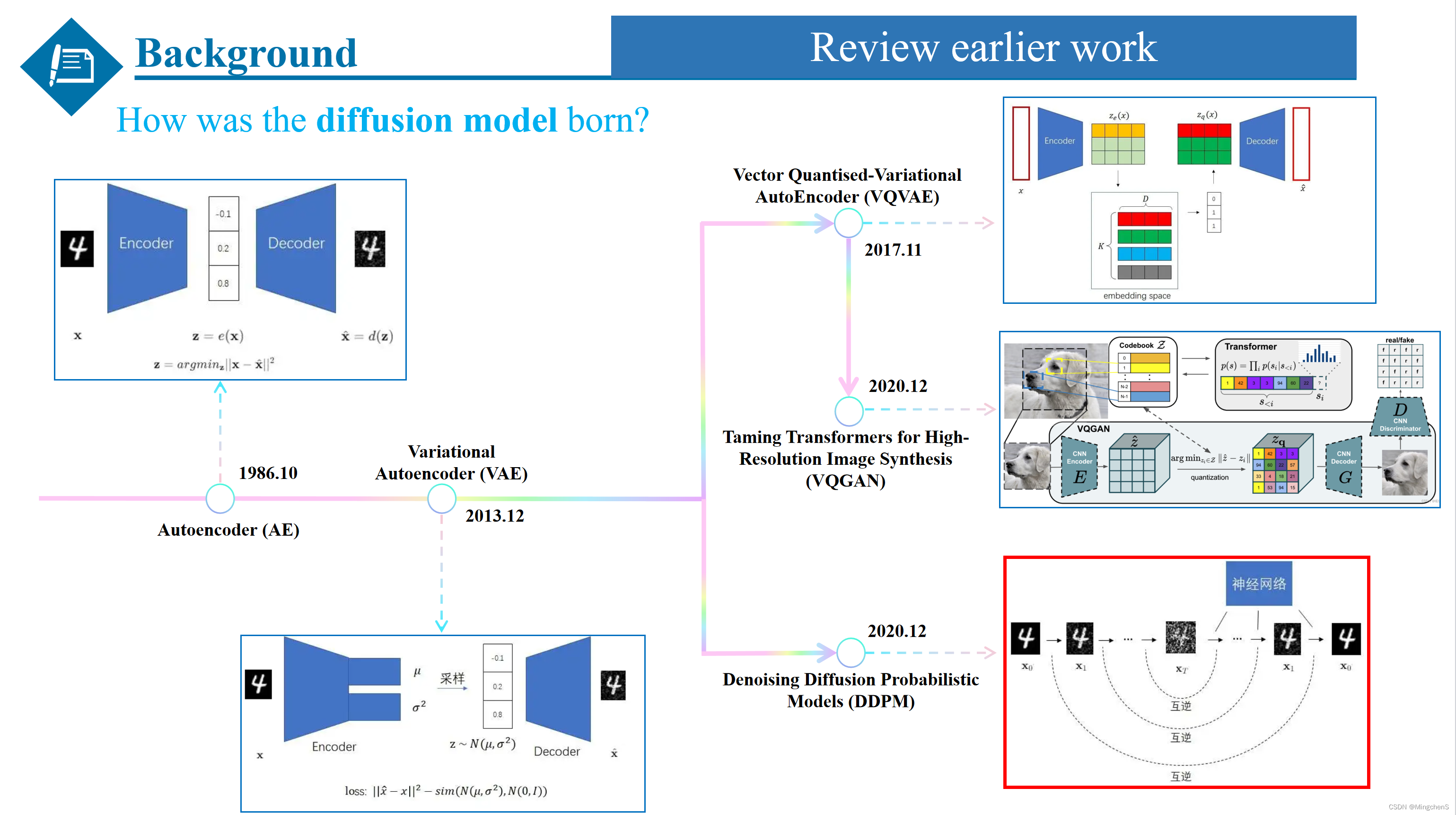
AE
为了更加清楚全面的介绍扩散模型,我们首先要从自编码器谈起,自编码器由一个编码器和一个解码器组成,通过编码器对图像进行编码,然后通过解码器再解码成原来的图像,优化目标也非常简单:编码再解码后的重建图像应该和原图像尽可能一致,即二者的均方误差应该尽可能小。我们不需要给图片打上标签,整个训练过程是自监督的。所以我们说,整套模型是一个自编码器(Autoencoder,AE)。
VAE
但是,AE生成效果并不好,会有过拟合现象,这导致AE的解码器只认得训练集里的图片经编码器解码出来的压缩数据,而不认得随机生成的压缩数据,进而也无法达到图像生成的要求。于是尝试着对AE进行改进,变分自编码器(Variational Autoencoder, VAE) 就是其中的代表。第一点改进是VAE让编码器的输出不再是一个确定的数据,而是一个数据的分布。这样的话,VAE就不能死记硬背了,必须要找出数据中的规律。VAE的第二项改动是多添加一个学习目标,让编码器的输出和标准正态分布尽可能相似,相当于对学习到的分布增加了一个约束,让编码器学习到的分布更加接近于标准正态分布。这样,VAE的误差函数由两部分组成:原图像和重建图像的重建误差、编码器输出和标准正态分布之间的误差。
VQVAE
但是问题又来了,VAE生成的图像还是比较模糊。也诞生了许多对VAE进行改进的模型,其中一条改进路径是VQVAE,由于VAE的编码器得到的分布不是很好学,而是一个codebook代替了,codebook可以理解为一个聚类的中心(通常为8192),这样就把特征量化了,而不是从分布里采样的一个随机的东西,优化起来就相对容易。
VQGAN
VQGAN是一个改进版的VQVAE,它将感知误差和GAN引入了图像压缩模型,把压缩图像生成模型替换成了更强大的Transformer。凭借这些改动,VQGAN方法能够生成高质量的高清图片。并且,通过把额外的约束条件(如语义分割图像、文字)输入进Transformer,VQGAN方法能够实现带约束的图像生成。(回过头来看看,之前的研究者们一直在可控和多样性的图像生成之间做权衡,一直没能找到一种可控生成而又保证多样性的图像生成方法)。
DDPM
另一条路径就是我们今天要讲的主角扩散模型 Diffusion Model,VAE之所以效果不好,很可能是因为它的约束太少了。VAE的编码和解码都是用神经网络表示的。神经网络是一个黑盒,我们不好对神经网络的中间步骤施加约束,只好在编码器的输出(某个正态分布)和解码器的输出(重建图像)上施加约束。**能不能让VAE的编码和解码过程更可控一点呢?**于是DDPM就诞生了,相当于对神经网络进行细致的分解,拆分成了1000步加噪和去噪的过程,相比只有两个约束条件的VAE,DDPM增加了更多的约束条件。
扩散模型的发展
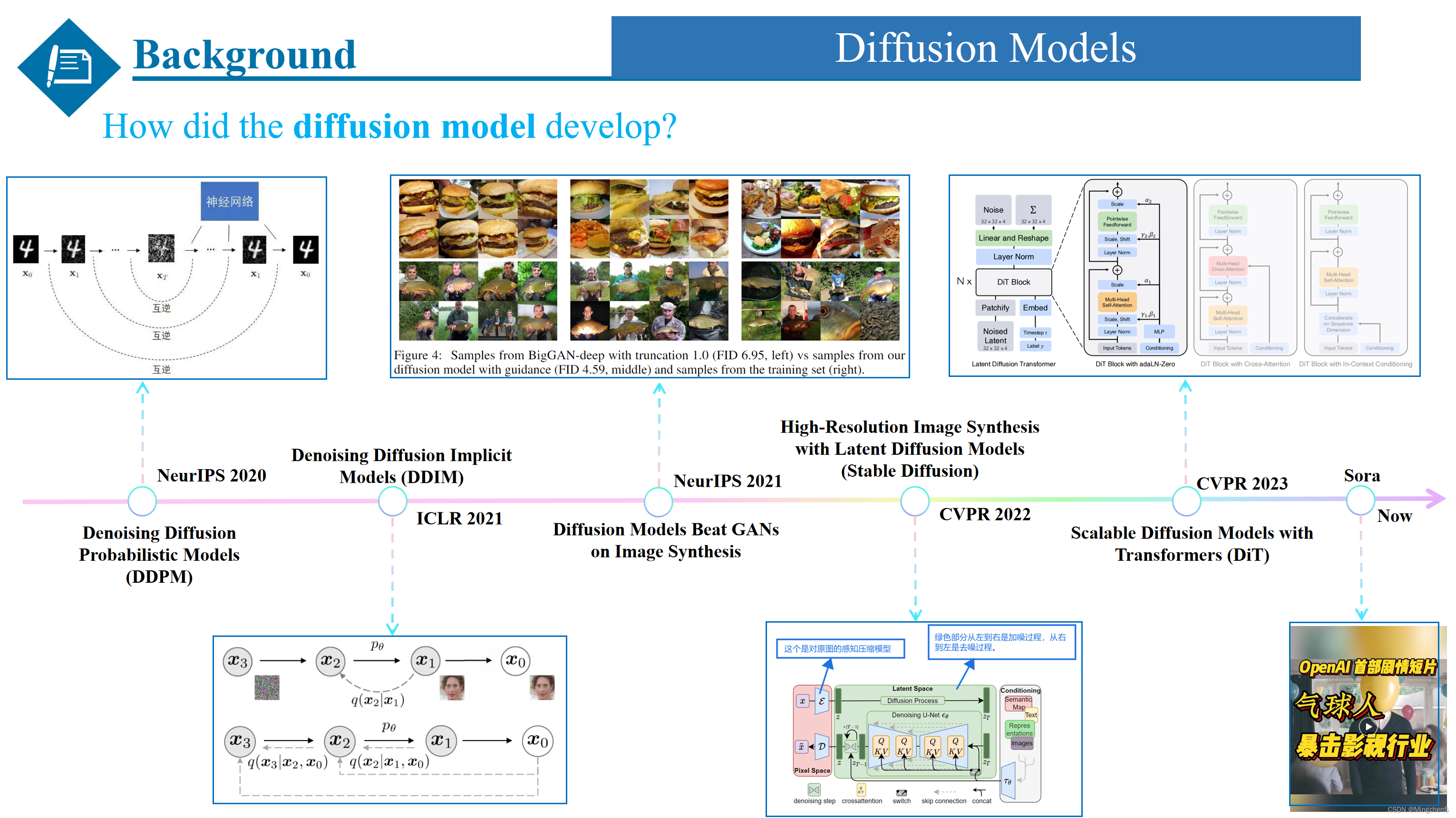
DDPM
至此,向大家简单的介绍了一下扩散模型是如何诞生的,当然介绍的只是最原始的扩散模型DDPM,下面我同样按照这种时间线的方式介绍一下扩散模型是如何发展的。同时由于时间和空间的原因,我只介绍几个具有代表性的工作。最开始的扩散模型是刚才我们提到的发表在NeurIPS 2020的DDPM,它需要一千步的加噪和去噪的过程,加噪的过程加的是噪声,去噪的过程预测的也是噪声。
DDIM
而后发表在ICLR2021上的DDIM是一种更有效的迭代隐式概率模型,但相比DDPM,将diffusion model 提速了50倍!
Diffusion Models Beat GANs on Image Synthesis
接下来就是NeurIPS 2021的这篇Diffusion Models Beat GANs on Image Synthesis ,这篇文章看题目就知道是第一次扩散模型打败GAN的图像生成方法,其主要思想是把模型加大加宽,变得又大又复杂,同时提出一种根据步数做归一化的方式,最重要的是在这篇工作中提出了一种classifier guidance的方法去引导模型的训练,classifier guidance相当于增加了一个分类的分支,利用分类的梯度,去引导扩散模型的训练。
Stable Diffusion
随后呢就是发表在cvpr2022的大名鼎鼎的Stable Diffusion,它提出了一种叫做隐扩散模型(latent diffusion model, LDM)的图像生成模型。这篇工作相当于集成了前面一些列模型的优点,它首先用编码器把图像压缩,再用DDPM生成压缩图像,同时保留了VQGAN的一些基本的结构。这样在保证图像生成质量的同时,降低了模型的复杂度。
DiT & sora
而后来发表在CVPR2023上的DiT在Stable Diffusion的基础上进行改进,是第一个完全基于transformer架构的扩散模型,而不再使用U-net架构,同时也是现在大火的sora模型的核心技术。
Motivation

本文的Motivation很简单,目的就是探索扩散模型的表征能力,为了实现这一目标,本文的核心思想是对扩散模型进行解构,通过大量的娓娓道来的实验,将他一步一步的朝着经典的去噪自编码器的方向前进。而这个经典的去噪自编码器的是2008年的一篇技术报告,就是为了探索去噪自编码器的表征能力。
方法和实验

DDM -> DAE
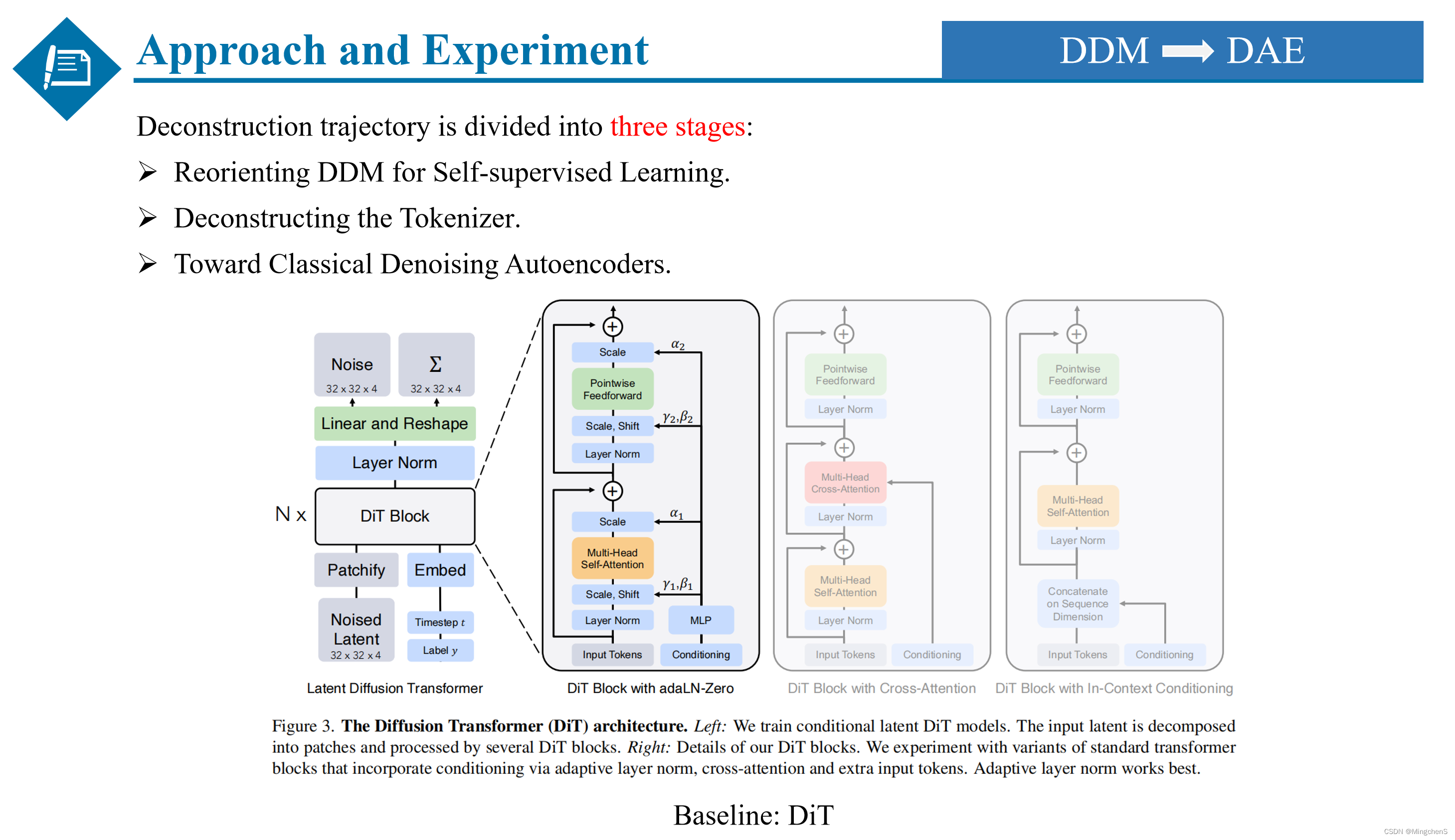
下面是本文的方法和实验部分,具体的重构过程分为三个阶段,第一阶段是让扩散模型朝着自监督学习的方向迈进,第二阶段是重构了扩散模型的Tokenizer,尝试了不同的映射结构,而第三呢就是通过一系列的模型修改,让现在的扩散模型更像经典的去噪自编码器。
同时本文的Baseline选取的是应用比较广泛的DiT结构,因为DiT是基于Transformer的扩散模型结构,可以与其他的基于自监督的Transformer模型进行公平的比较,比如MOCO和MAE,同时DiT是干净的encoder和decoder的结构,而U-Net存在encoder和decoder之间的skip connections,不方便对网络进行修改。同时DiT的训练速度比基于U-Net的扩散模型方法更快,泛化性更好。
Reorienting DDM for Self-supervised Learning
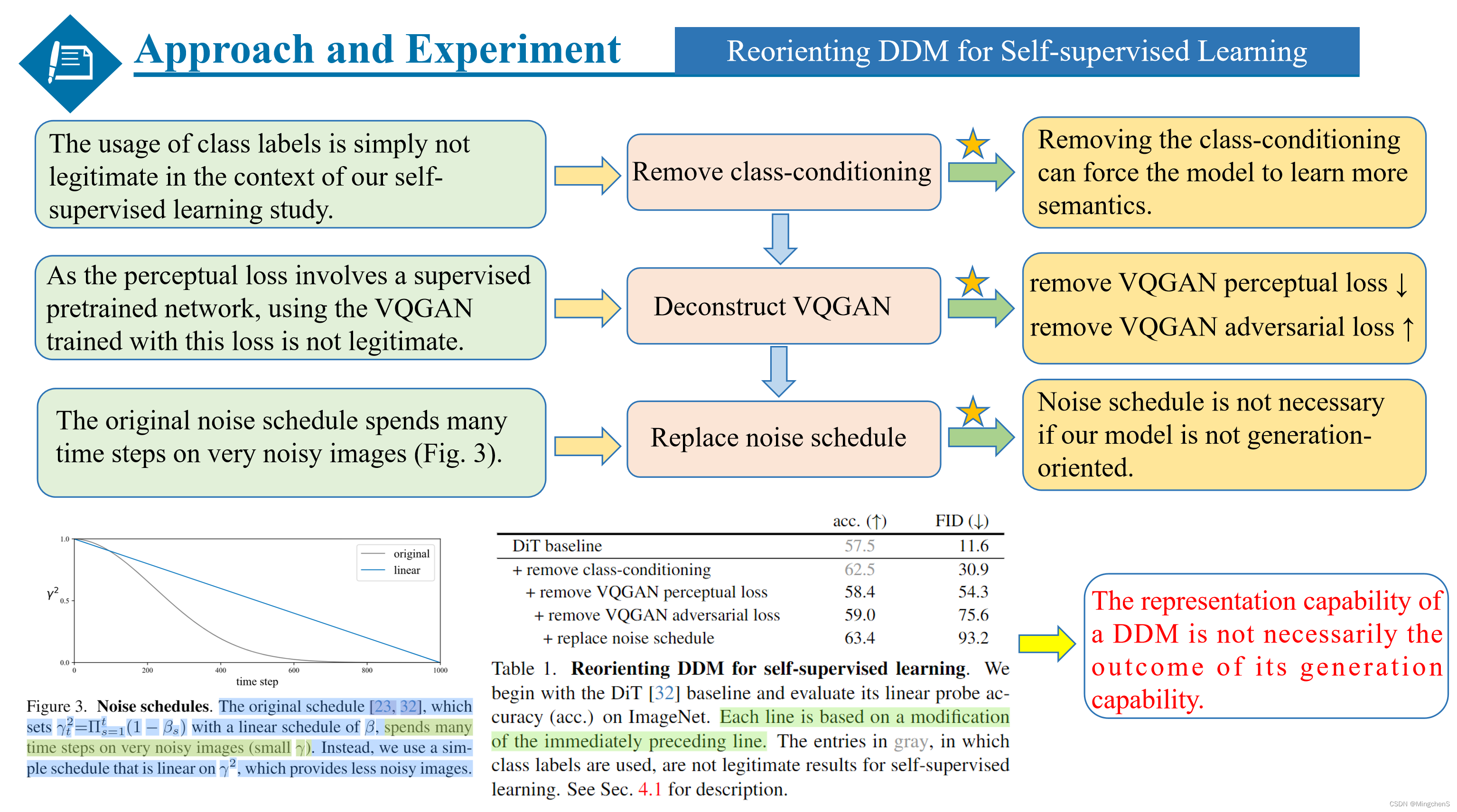
第一阶段是让扩散模型朝着自监督学习的目标迈进,本文在这里做了三点改动,第一由于类别标签的使用违背了自监督学习的规则,所以去掉了类别条件。
第二是由于DiT的基本结构是延续VQGAN设计的,他的感知loss是有监督的,所以去掉了感知loss,同时为了简化模型,也去掉了对抗loss。
第三点由于本文的目的是探究扩散模型的表征能力,作者认为不需要对图像加过多的噪声,于是简化了加噪的策略。可以从Table1的结果看出,随着对扩散模型的改进,模型的表征能力得到了提升,而模型的生成能力降低的比较明显。同时也是得出了一个非常重要的结论:扩散模型的表征能力和生成能力是没有一个必要性的关系的。也就是说模型的表征能力强,并不意味着模型的生成能力强,反之亦然。
Deconstructing the Tokenizer

第二阶段是对Tokenizer的重构,作者在这里尝试了不同的Tokenizer,其中包括基于卷积的VAE,基于Patch的只用一个线性层的VAE,基于patch的只用一个线性层的AE,以及基于patch的PCA的方式去实现Tokenizer。最后也是尝试了像素级别的Tokenizer,只是对patch内的所有像素进行一个恒等映射之后flatten一个向量。同时作者也是发现了两个比较有趣的结论: 第一是Tokenizer映射到的潜在维度对扩散模型的表征能力是至关重要的,而且他们遵循一个基本的变化趋势。第二是基于像素的Tokenizer的方式不如基于patch的效果好。
Toward Classical Denoising Autoencoders

第三个阶段是朝着经典的去噪自编码器的方向迈进,同样也是在扩散模型的基础上进行了一系列的操作,包括预测原始的数据而不是噪声,去除对input的 scaling操作等等,都会对扩散模型的表达能力产生一定的影响,其中比较有趣的一点是作者出于好奇,彻底改变了加噪策略,只加一步的single-level噪声,与之前的multi-level noise相比只降低了3%的准确率,由此证明了扩散模型的表征能力主要是由去噪的过程决定的,并不是加噪的过程。作者分析multi-level noise就相当于一个数据增强,并不是扩散模型表征能力的关键因素。
分析和比较
下面是本文的一些分析和比较。

去噪效果可视化

首先是对去噪的定性结果的一个可视化效果图,可以发现本文只用简单的PCA作为Tokenizer,同时去掉了大量的冗余的组件之后,依然能达到比较好的一个去噪的效果。
实验对比

接下来是与其他的自监督模型的一个定量的比较,第一是作者发现去噪自编码器与MAE一样,对数据增强并不敏感,这一点与基于对比学习的自监督模型有很大的区别。
第二是对模型尺度的一个消融实验,展现出了与MAE类似的结果,都是模型越大性能越好。
第三是发现基于自编码器的自监督模型不如基于对比学习的自监督模型的效果好,尤其是在模型比较小的时候差距最为明显。
第四是对预训练之后的模型进行微调,展现了DAE的强大的表征能力。
我的一点思考和启发

问题1:MAE和DAE之间有什么区别?
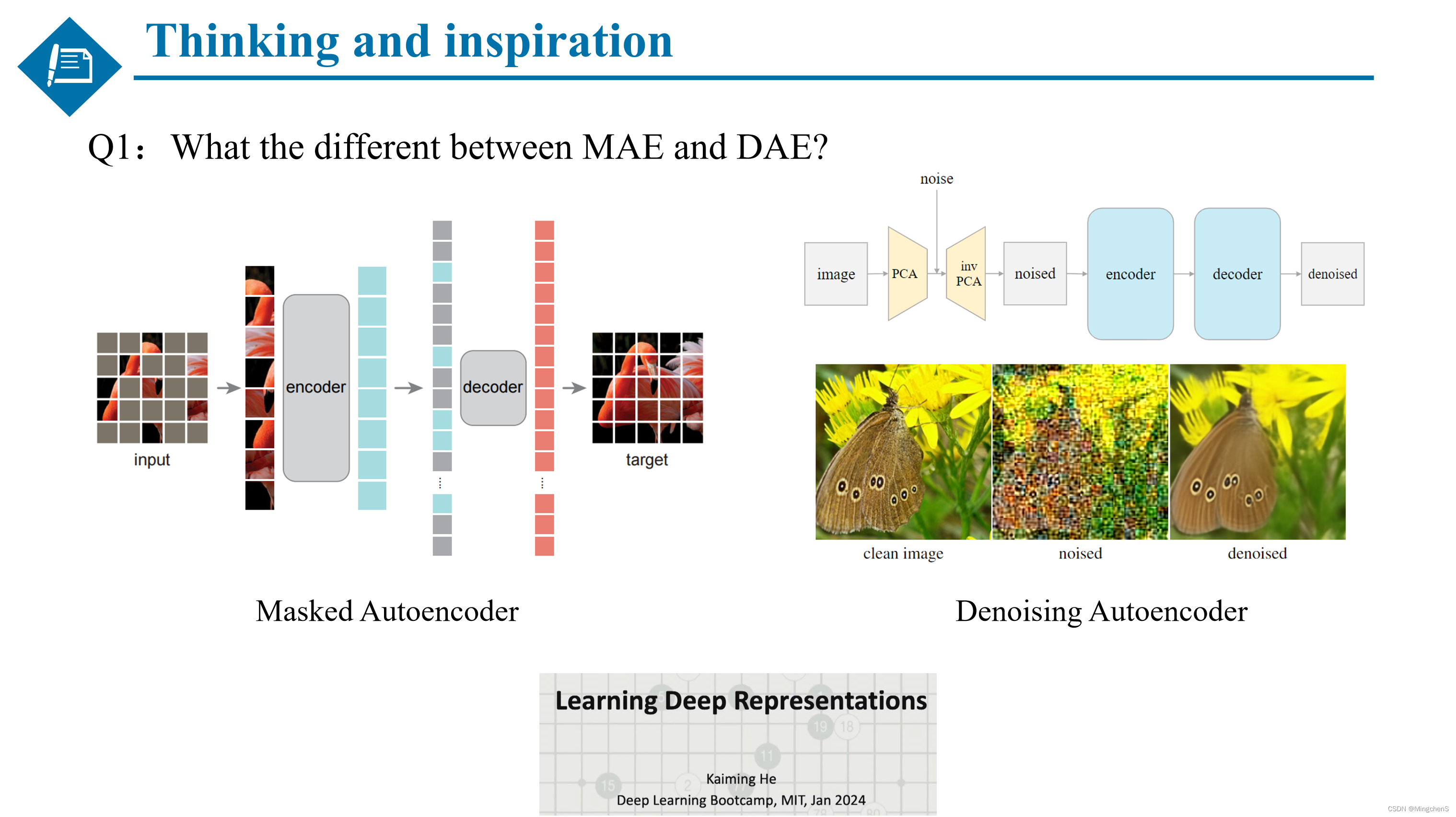
他们之间有相同点也有不同点,相同点都是采用自监督的方式去学习图像的表征,都采用patch的方式对图像进行处理,都是将遮挡或者加噪的图像恢复成原始的图像,同时展现出了相似的性能。区别在于一个是遮挡整个的patch,一个是在每个patch上加噪。(比较有意思的是,在Transformer如火如荼的时候有了MAE,在扩散模型如火如荼的时候有了DAE)同时在这里推荐何恺明老师加入MiT的第一堂课,他的第一堂课的主题刚好就叫做,学习深度表征。
问题2:这篇文章的idea是从哪里来的?
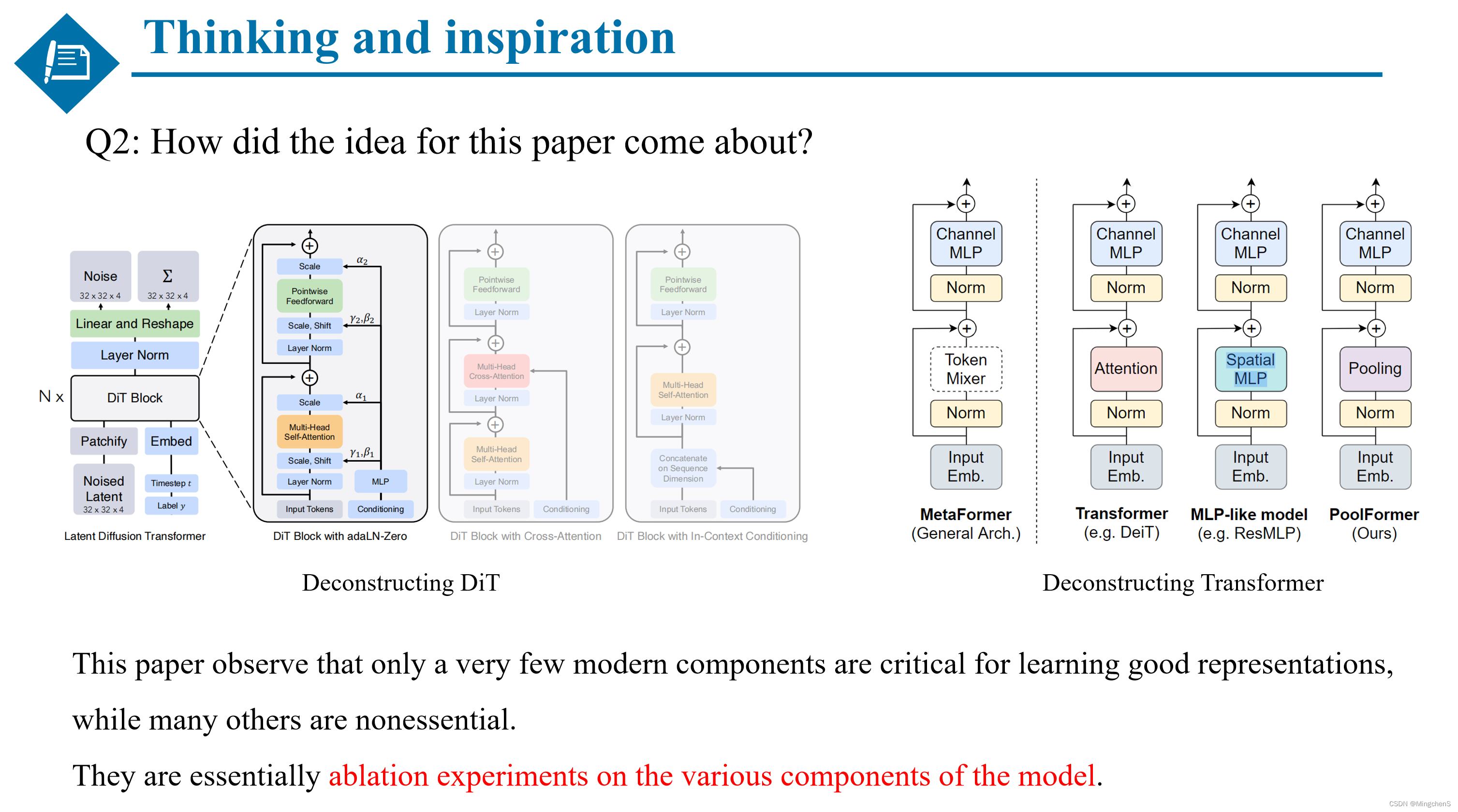
当我初次看到这篇工作的时候,实际上我觉得本文所做的工作跟新加坡国立大学的颜水成老师发表在CVPE2022的那篇 metaformer 的基本思想是非常类似的。本文是对扩散模型的解构,而metaformer是对transformer的解构,证明了一些组件是至关重要的同时也证明了一些组件是冗余的。他们本质上都是对模型各个组件的娓娓道来的消融实验,两篇文章的写作风格非常值得借鉴。
问题3:扩散模型的表征能力和生成能力之间的关系是什么?
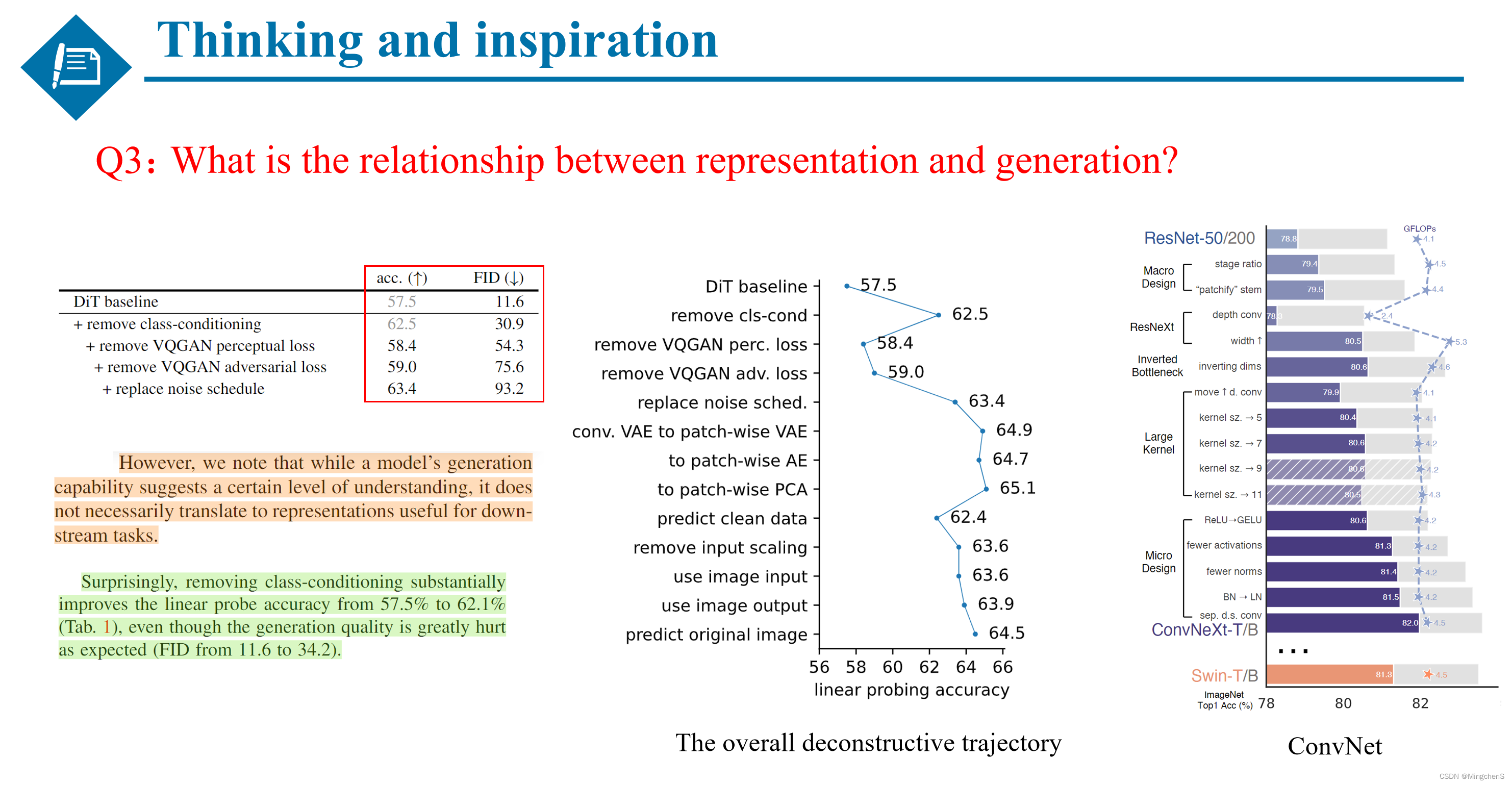
最后一个问题是比较开放性的问题,扩散模型的表征能力和生成能力之间的关系是什么?
通过本文的大量实现发现,似乎模型的表征能力和生成能力并没有直接关系,甚至二者之间是相互排斥的,这有点不符合我们通常的认知。也就是说,现在大火的一类的扩散模型(比如sora),可能并不理解图像的语义,仍然能生成逼真的、多样性的图像。那么是不是说,机器生成图像的方式与人类所理解的生成图像的方式或许是相差甚远的?所以,**sora真的理解了现实世界吗?**我们该如何解释扩散模型呢?扩散模型的滥用会不会存在潜在的风险?是值得我们进一步深究的。
(最后分享一下本文的作图风格,本文的作图风格与谢赛宁大神的ConvNet中画图风格是一致的,我觉得很漂亮).
参考资料:
https://mp.weixin.qq.com/s/AGsMelnrHxI1cv9lmabxEg 对扩散模型的详细介绍
https://www.spaces.ac.cn/archives/6760 VQ-VAE的简明介绍:量子化自编码器
https://mp.weixin.qq.com/s?__biz=MzkyMTM0Mjc3NA==&mid=2247485628&idx=1&sn=f0d5b9e6aad411b5a8f9979936aa1327&chksm=c1844ee5f6f3c7f3c8f69a080bb35d9c37a695dbb057b7418a9325844ed91491a44ea2fb568a&scene=21#wechat_redirect 轻松理解 VQ-VAE:首个提出 codebook 机制的生成模型
https://mp.weixin.qq.com/s/5nYdRg7G-mKGXfNxV5_WZQ 对VQGAN的介绍,代码讲解非常好 。
https://mp.weixin.qq.com/s/3fqLktVA2MIsjB7a0eM0sg 一文弄懂 Diffusion Model
https://spaces.ac.cn/archives/9119 生成扩散模型漫谈,是一个系列。(苏神的文章)
https://mp.weixin.qq.com/s/AGsMelnrHxI1cv9lmabxEg 对Stable Diffusion 的解读,包络原理和代码,是一个系列的文章。
https://zhuanlan.zhihu.com/p/639540034 对DDIM的原理性分析。
https://zhuanlan.zhihu.com/p/641013157 对DiT的介绍。
https://blog.csdn.net/u012193416/article/details/126108145 对DALLE的介绍。
https://mp.weixin.qq.com/s/ScHjSd_JtcZKD2cJxWuavg 对sora的介绍。
参考文献: