目录
- 前言:
- 1.re.serach
- 1.1例子:
- 2.re.match
- 2.1示例1:
- 2.2 示例2:
- 3.re.findall
- 3.1 示例
- 4.re.fullmatch
- 4.1 示例1:
- 4.2 示例2:
- 5.re.split
- 5.1 示例1:
- 5.2 示例2:
- 5.3 示例3:
- 6.re.sub
- 6.1 示例:
- 7.re.compile
- 7.1 示例:
- 8 总结
前言:
在python中使用的是re模块对正则表达式提供支持,下面我来讲解一些日常中比较常用的几种正则表达式的方法,希望对各位日常的工作中有帮助。
常见的正则表达式的操作:
\d
匹配任何十进制数字,相当于[0-9]。
示例:\d+ 匹配一个或多个连续的数字。
\D
匹配任何非数字字符,相当于[^0-9]。
\w
匹配任何字母数字字符,包括下划线,相当于[A-Za-z0-9_]。
示例:\w+ 匹配一个或多个字母数字字符或下划线。
\W
匹配任何非字母数字字符,不包括下划线,相当于[^A-Za-z0-9_]。
\s
匹配任何空白字符,包括空格、制表符、换页符等,相当于[ \t\n\r\f\v]。
\S
匹配任何非空白字符,相当于[^ \t\n\r\f\v]。
. (点)
匹配除换行符以外的任何单个字符。
[…]
匹配方括号内的任何单个字符。例如,[abc] 会匹配"a"、“b"或"c”。
[^…]
匹配不在方括号内的任何单个字符。例如,[^abc] 会匹配任何不是"a"、"b"或"c"的字符。
| (竖线)
A|B可以匹配A或B,所以(P|p)ython可以匹配"Python"或"python"。
^
匹配字符串的开始。在多行模式中,它还可以匹配每一行的开头。
$
匹配字符串的结尾。在多行模式中,它还可以匹配每一行的结尾。
*
匹配前面的子表达式零次或多次。例如,bo* 可以匹配 “b”、“bo” 或 “booo”。
+
匹配前面的子表达式一次或多次。例如,bo+ 可以匹配 “bo” 或 “booo”,但不会匹配 “b”。
?
匹配前面的子表达式零次或一次。例如,bo? 可以匹配 “b” 或 “bo”。
{n}
精确匹配 n 次前面的子表达式。例如,o{2} 不能匹配 “Bob” 中的 “o”,但能匹配 “food” 中的两个 o。
{n,}
匹配前面的子表达式至少 n 次。
{n,m}
匹配前面的子表达式至少 n 次,但不超过 m 次。
有需要详细了解的可以看re的官方文档:
re正则表达式操作
1.re.serach
该方法会根据传入的正则去扫描整个字符串,若能找到对应的子字符串,则返回该Match对象,否则返回None。这里返回的Match对象保存的是从左到右匹配到的第一个子字符串的信息。
re.search(pattern, string, flags=0)
1.1例子:
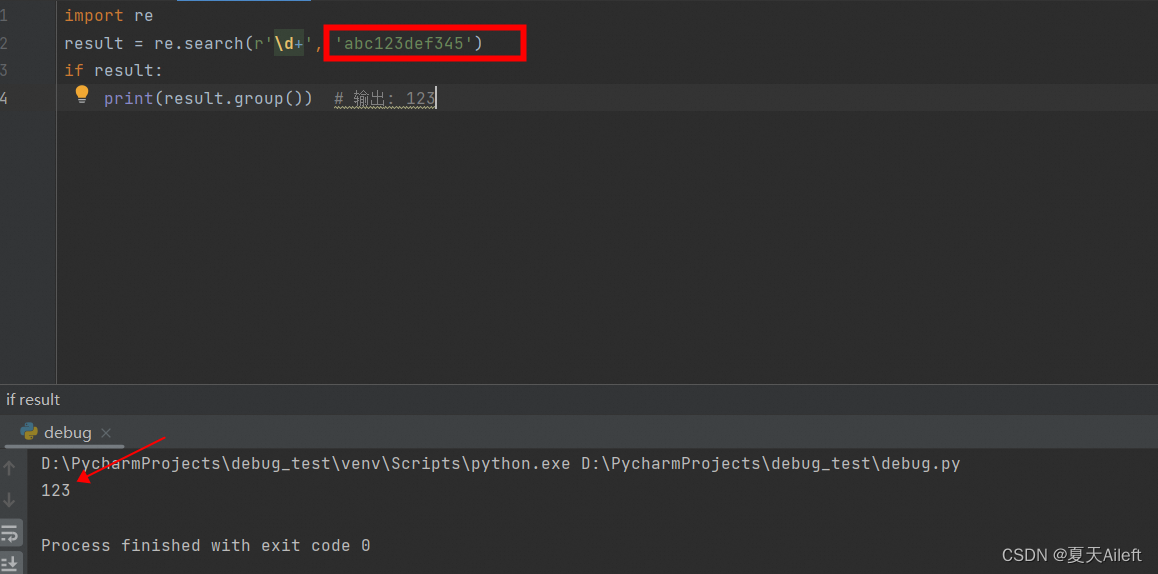
import re
result = re.search(r'\d+', 'abc123def')
if result:
print(result.group()) # 输出: 123
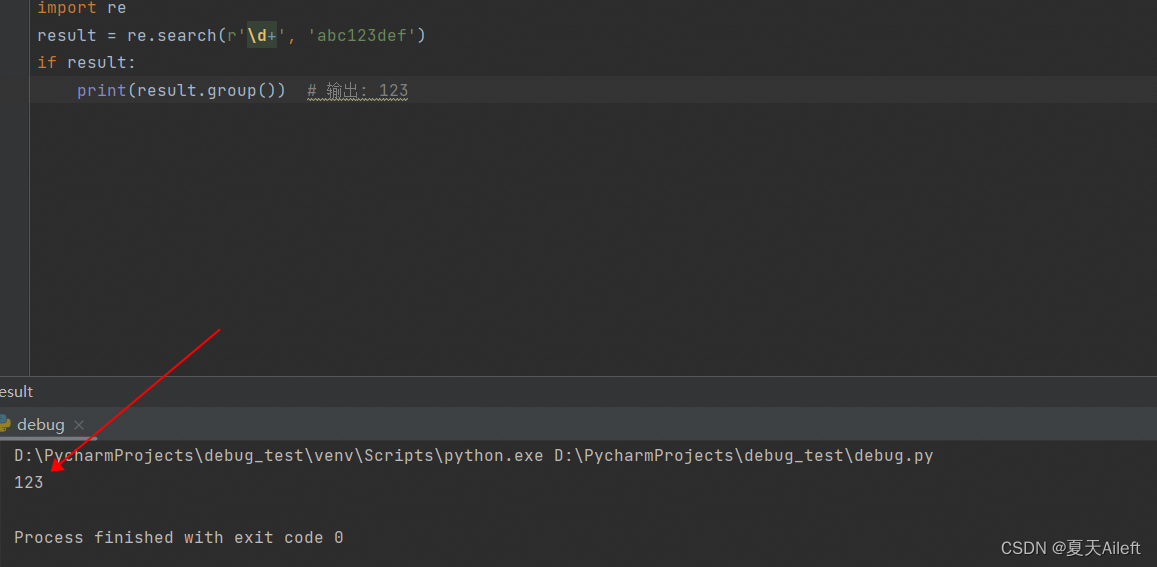
注意:下图显示 re.serach 这里他只会匹配从左到右第一个连续的数字,第二个不会匹配到
2.re.match
这个方法从字符串的开始处进行匹配,如果匹配成功,返回一个匹配对象;失败则返回None。
re.match(pattern, string, flags=0)
pattern 表示传进来的正则表达式
string 表示被匹配的字符串
flags 正则表达式匹配的模式
2.1示例1:
import re
result = re.match(r'\d+', '123abc')
if result:
print(result.group()) # 输出: 123

2.2 示例2:
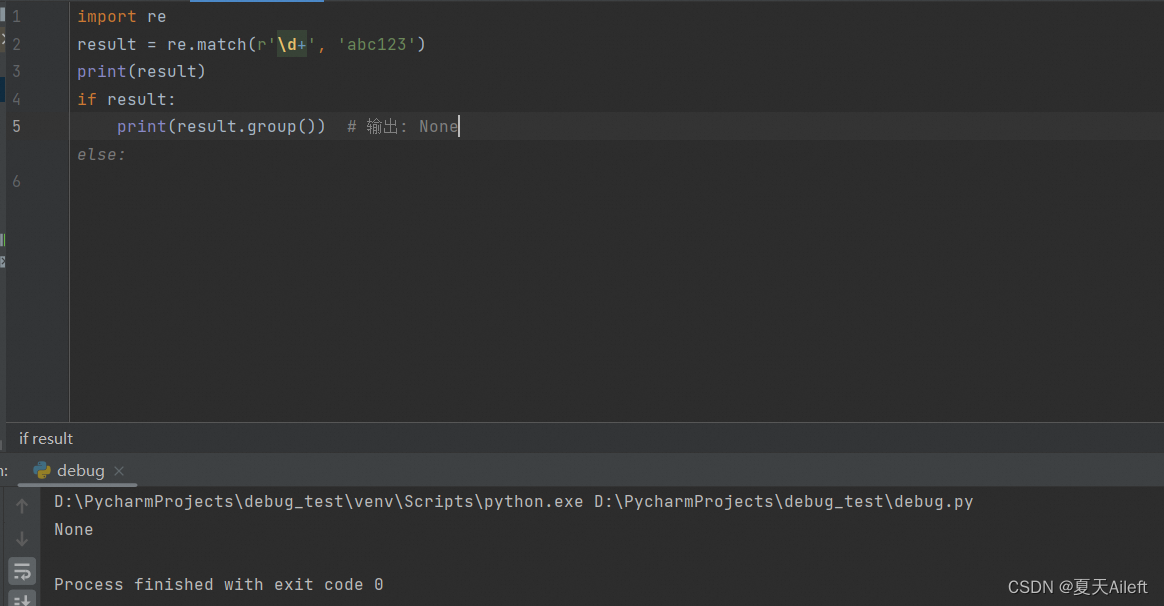
import re
result = re.match(r'\d+', 'abc123')
print(result)
if result:
print(result.group()) # 输出: None
Match对象是一个包含关于搜索和结果的信息的特殊类型的对象。为了获取实际匹配的字符串,你需要调用Match对象的.group()方法。.group()方法返回模式匹配的子串。
Match对象的.group()方法可以接受一个或多个参数(称为group numbers)。如果没有提供参数,.group()方法默认返回第0组,即整个匹配的字符串。
示例:
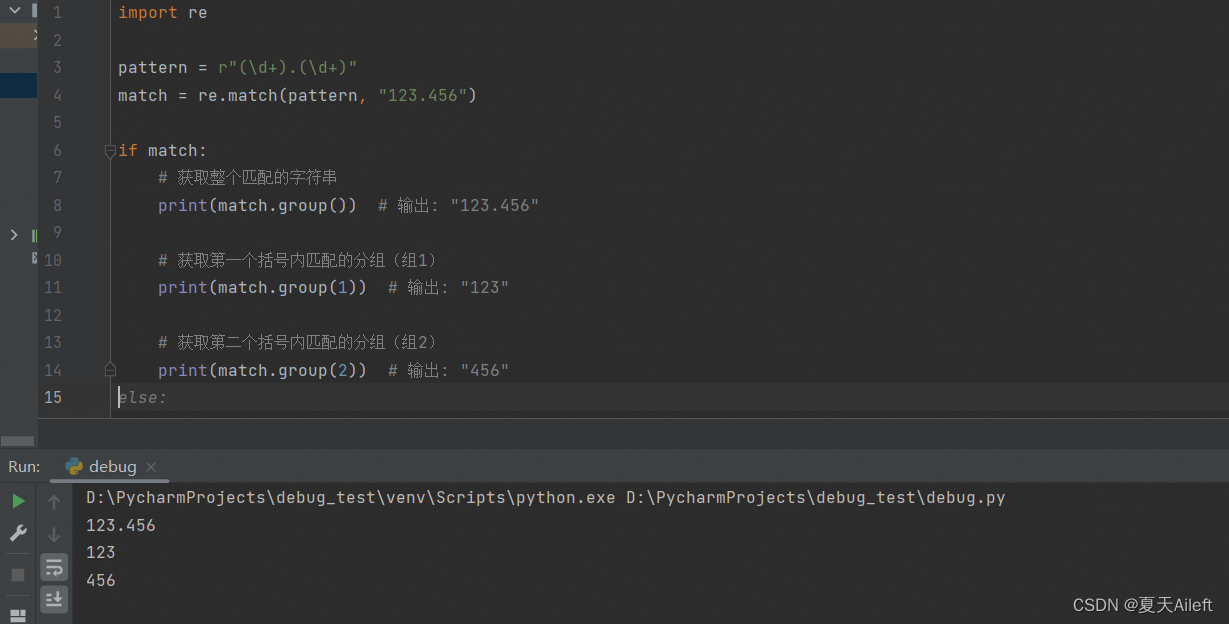
import re
pattern = r"(\d+).(\d+)"
match = re.match(pattern, "123.456")
if match:
# 获取整个匹配的字符串
print(match.group()) # 输出: "123.456"
# 获取第一个括号内匹配的分组(组1)
print(match.group(1)) # 输出: "123"
# 获取第二个括号内匹配的分组(组2)
print(match.group(2)) # 输出: "456"
在上面的例子中,我们使用了两组括号来创建两个分组:
(\d+) 第一个分组匹配一个或多个数字。
(\d+) 第二个分组再次匹配一个或多个数字。
当我们调用.group()方法时:
.group() 或 .group(0) 返回整个匹配的字符串,即"123.456"。
.group(1) 返回第一个分组匹配的字符串,即"123"。
.group(2) 返回第二个分组匹配的字符串,即"456"。
3.re.findall
找到字符串中所有非重叠匹配的列表。意思就是
pattern 没有捕获组的话,该方法会返回所有匹配结果的list
pattern 包含一个或多个捕获组的话,list保存的结果是这些捕获组的匹配结果,且list里面的各项都是一个tuples
re.findall(pattern, string, flags=0)
3.1 示例
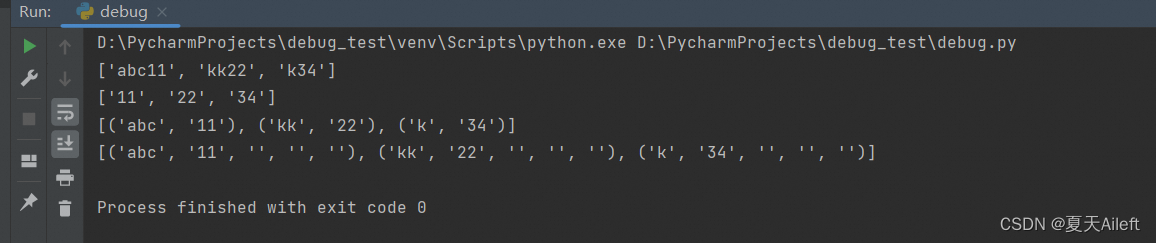
import re
result=re.findall(r"[a-z]+\d+","abc11kk22k34")
print(result)
# 匹配一个或多个小写字母 [a-z]+ 后面跟一个或多个数字 \d+。
# 输出: ['abc11', 'kk22', 'k34'] 因为它匹配了连续的字母和数字的组合。
result=re.findall(r"[a-z]+(\d+)","abc11kk22k34")
print(result)
#这个模式类似于第一个,但是这次数字部分被括号 (\d+) 包围,这意味着使用括号的分组功能。
# 在 findall 方法中,当模式包含分组时,只有分组内的内容会被返回。
# 输出: ['11', '22', '34'] 这是因为只有分组中的数字被返回。
result=re.findall(r"([a-z]+)(\d+)","abc11kk22k34")
print(result)
# 这个模式有两个分组 ([a-z]+) 和 (\d+),分别匹配一系列字母和数字。
# 由于有两个分组,findall 会返回包含每个分组匹配的元组列表。
# 输出: [('abc', '11'), ('kk', '22'), ('k', '34')] 每对括号内的匹配分别作为元组的元素。
result=re.findall(r"([a-z]+)(\d+)()()()","abc11kk22k34")
print(result)
# 这个模式现在包含两个有效的分组 ([a-z]+) 和 (\d+),以及三个空的分组 ()()()。
# 空的分组不会捕获任何内容,但它们仍然作为结果的一部分出现。
# 输出: [('abc', '11', '', '', ''), ('kk', '22', '', '', ''), ('k', '34', '', '', '')]
# 每个匹配现在都返回一个包含两个有效匹配和三个空字符串的元组。
4.re.fullmatch
该方法需要整个字符串跟正则完全匹配才会返回一个Match对象,否则返回None
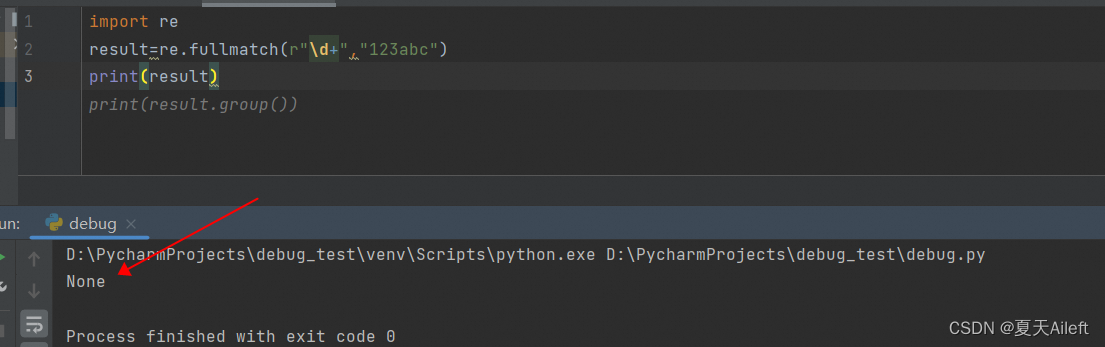
4.1 示例1:
这里需要完全匹配字符串是数字
import re
result=re.fullmatch(r"\d+","123abc")
print(result)
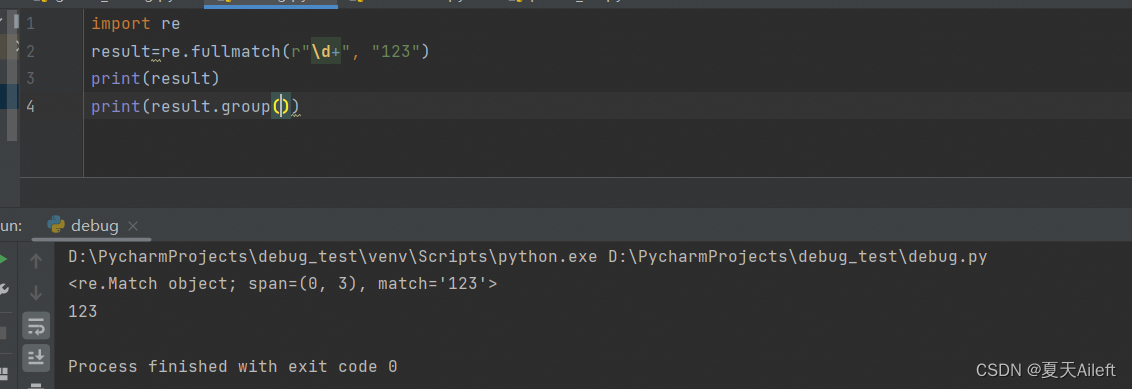
4.2 示例2:
import re
result=re.fullmatch(r"\d+", "123")
print(result)
print(result.group())
5.re.split
re.split(pattern, string, maxsplit=0, flags=0)
pattern: 这是用于分割字符串的正则表达式模式。字符串会在匹配这个模式的所有地方被分割。
string: 这是需要被分割的输入字符串。
maxsplit (可选): 这个参数指定了分割的最大次数。默认值为0,表示不限制分割次数,即分割可以在每次匹配到模式时发生。如果maxsplit被设置为一个正整数n,那么分割会在前n次匹配到模式之后停止,剩余的字符串会作为列表的最后一个元素返回。
flags (可选): 这个参数允许你指定正则表达式的一些额外选项,如忽略大小写(re.IGNORECASE)、多行模式(re.MULTILINE)等。默认值为0,表示没有特殊标志。
如果pattern没有捕获组的话,则按照正则分割后,返回一个list结果集;如果pattern里面包含捕获组的话,list结果集里面包含捕获组获取到的内容
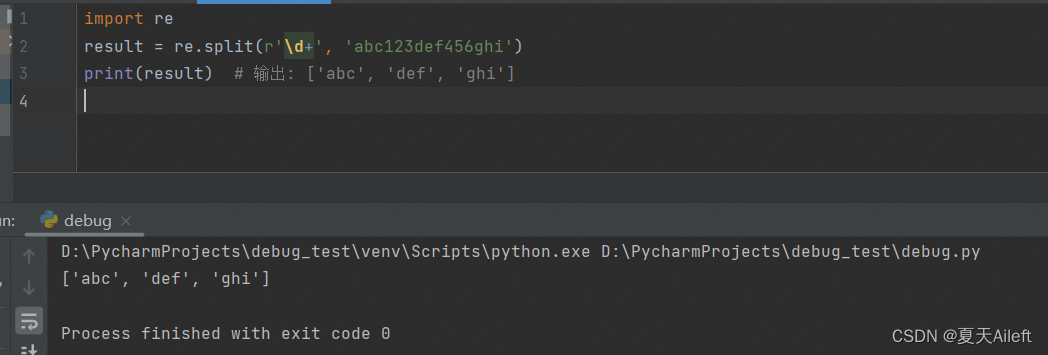
5.1 示例1:
import re
result = re.split(r'\d+', 'abc123def456ghi')
print(result) # 输出: ['abc', 'def', 'ghi']
5.2 示例2:
不带 maxsplit:
import re
result = re.split(r'\d+', 'one1two2three3four4')
print(result)
输出:

5.3 示例3:
带有 maxsplit:
import re
result = re.split(r’\d+', ‘one1two2three3four4’, maxsplit=2)
print(result)
输出:

在这个例子中,由于maxsplit被设置为2,所以分割只在前两次匹配到数字时发生,剩余的字符串(‘three3four4’)作为列表的最后一个元素返回。
6.re.sub
re.sub(pattern, repl, string, count=0, flags=0)
pattern: 一个字符串或者一个预编译的正则表达式对象(通过 re.compile 创建)。这是你想要在原始字符串中查找的正则表达式模式。
repl: 替换匹配项的字符串或者一个函数。如果是一个字符串,任何正则表达式中的分组引用(如 \1, \2 等)都会被匹配项中对应的分组替换。如果是一个函数,它应该接受一个匹配对象作为参数,并返回一个用来替换的字符串。
string: 要进行搜索和替换操作的原始字符串。
count (可选): 一个表示替换次数的整数,默认为0,表示替换所有匹配项。如果指定了这个参数,则最多替换 count 次匹配。
flags (可选): 正则表达式标志,例如 re.IGNORECASE、re.MULTILINE 等。这些标志用于修改正则表达式的行为。默认为0,表示没有标志被设置。
这个方法的作用是字符串替换,其中,rep1可以是字符串,也可以是一个方法。
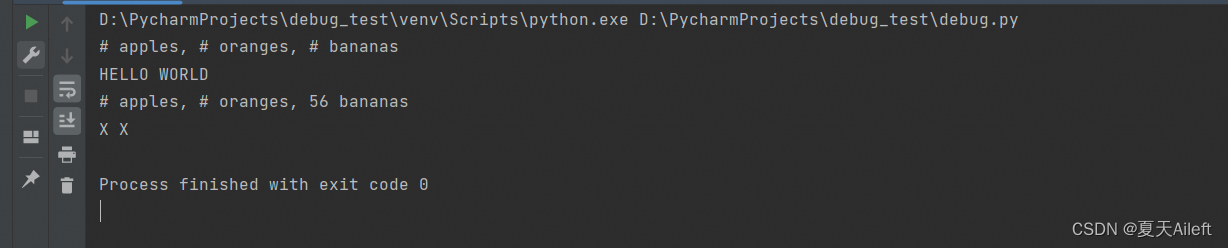
6.1 示例:
import re
# 替换所有数字为 #
result = re.sub(r'\d+', '#', "12 apples, 34 oranges, 56 bananas")
print(result) # 输出: "# apples, # oranges, # bananas"
# 使用函数来替换匹配项
def to_upper(match):
return match.group().upper()
result = re.sub(r'[a-z]+', to_upper, "hello world")
print(result) # 输出: "HELLO WORLD"
# 替换前两个匹配项
result = re.sub(r'\d+', '#', "12 apples, 34 oranges, 56 bananas", count=2)
print(result) # 输出: "# apples, # oranges, 56 bananas"
# 使用标志忽略大小写
result = re.sub(r'[a-z]+', 'X', "Hello World", flags=re.IGNORECASE)
print(result) # 输出: "X X"
输出结果:
7.re.compile
编译正则,返回一个Pattern对象。 这样做的目的是可以重复使用该正则模式对象
pattern: 正则表达式字符串,即你希望编译的模式。
flags (可选): 正则表达式标志,可以改变正则表达式的行为。常见的标志包括:
re.IGNORECASE 或 re.I: 使匹配对大小写不敏感。
re.MULTILINE 或 re.M: 影响 ^ 和 $ 的行为。^ 匹配每一行的开始,$ 匹配每一行的结束,而不仅是整个字符串的开始和结束。
re.DOTALL 或 re.S: 使.(点)特殊字符匹配任何字符,包括换行符。
re.UNICODE 或 re.U: 根据Unicode字符属性数据库使 \w, \W, \b, \B, \d, \D, \s 和 \S 起作用。
re.ASCII 或 re.A: 使 \w, \W, \b, \B, \d, \D, \s 和 \S 只匹配ASCII字符。
re.LOCALE 或 re.L: 使 \w, \W, \b, \B, \s 和 \S 受当前区域设置的影响(不推荐使用,因为re.UNICODE通常是更好的选择)。
re.VERBOSE 或 re.X: 允许你通过忽略空白和添加注释来编写更易读的正则表达式。
7.1 示例:
import re
# 编译一个正则表达式对象
pattern = re.compile(r'\d+', flags=re.IGNORECASE)
# 使用编译后的对象进行匹配操作
match = pattern.match("123abc")
if match:
print(match.group()) # 输出: 123
# 使用编译后的对象进行搜索操作
search = pattern.search("abc123def")
if search:
print(search.group()) # 输出: 123
# 使用编译后的对象进行查找所有匹配项的操作
findall = pattern.findall("123abc456def")
print(findall) # 输出: ['123', '456']
输出

8 总结
re.search, re.match, 和 re.findall 是Python中用于正则表达式匹配的三个不同的函数,它们有着不同的用途和行为。下面是每个函数的作用、相似之处和不同之处:
re.search(pattern, string, flags=0)
作用: 在字符串中查找第一个匹配正则表达式pattern的位置。
返回: 如果找到匹配,返回一个Match对象;如果没有找到匹配,则返回None。
行为: re.search会扫描整个字符串,直到找到一个匹配项。
re.match(pattern, string, flags=0)
作用: 从字符串的开始处检查是否有匹配正则表达式pattern的内容。
返回: 如果字符串开始的字符匹配正则表达式,返回一个Match对象;如果不匹配或匹配不是在字符串的开始处,返回None。
行为: re.match仅在字符串的开始处进行匹配检查。
re.findall(pattern, string, flags=0)
作用: 查找字符串中所有匹配正则表达式pattern的非重叠匹配项。
返回: 返回一个列表,包含所有匹配项的字符串。如果正则表达式中包含了一个或多个捕获组,将返回一个元组列表。
行为: re.findall会扫描整个字符串,并返回所有匹配的完整列表。
相同点
它们都是re模块提供的函数,用于执行正则表达式匹配。
它们都可以接受flags参数,该参数可以改变正则表达式的行为(如忽略大小写等)。
它们都从左到右扫描字符串进行匹配。
不同点
re.match只在字符串的起始处检查匹配,而re.search在整个字符串中搜索第一个匹配项。
re.findall返回的是一个列表,包含所有的匹配项,而re.match和re.search返回的是Match对象。
如果正则表达式包含捕获组,re.match和re.search返回的Match对象可以通过.group()方法访问各个捕获组,而re.findall将直接返回一个包含捕获组内容的元组列表。




![[Vue3] 配置 Pinia 并存储、读取、修改数据 | 集中式状态(数据)管理](https://img-blog.csdnimg.cn/direct/8a049d8f49e04f0184ca537b55c7edac.png)