此为观看视频 4 Methods of Prompt Engineering 后的笔记。
从通用模型到专用模型,fine tuning(微调)和prompt engineering(提示工程)是2种非常重要的方法。本文深入探讨了prompt engineering的4种方法。
首先,作者回顾了大语言模型的3种用例:聊天机器人,生成摘要,检索信息。在这3个用例中,prompt engineering对于和大语言模型进行有效的沟通至关重要。prompt engineering被设计用来提出适当的问题,以从大型语言模型中获得准确可信的答案,从而避免幻觉(hallucination)。 幻觉是指你从大语言模型中得到错误的结果,因为大语言模型主要基于互联网数据进行训练,其中可能存在不一致的信息,过时的信息和误导的信息。
下面将逐一介绍4种prompt engineering方法。
RAG (Retrieval Augmented Generation)
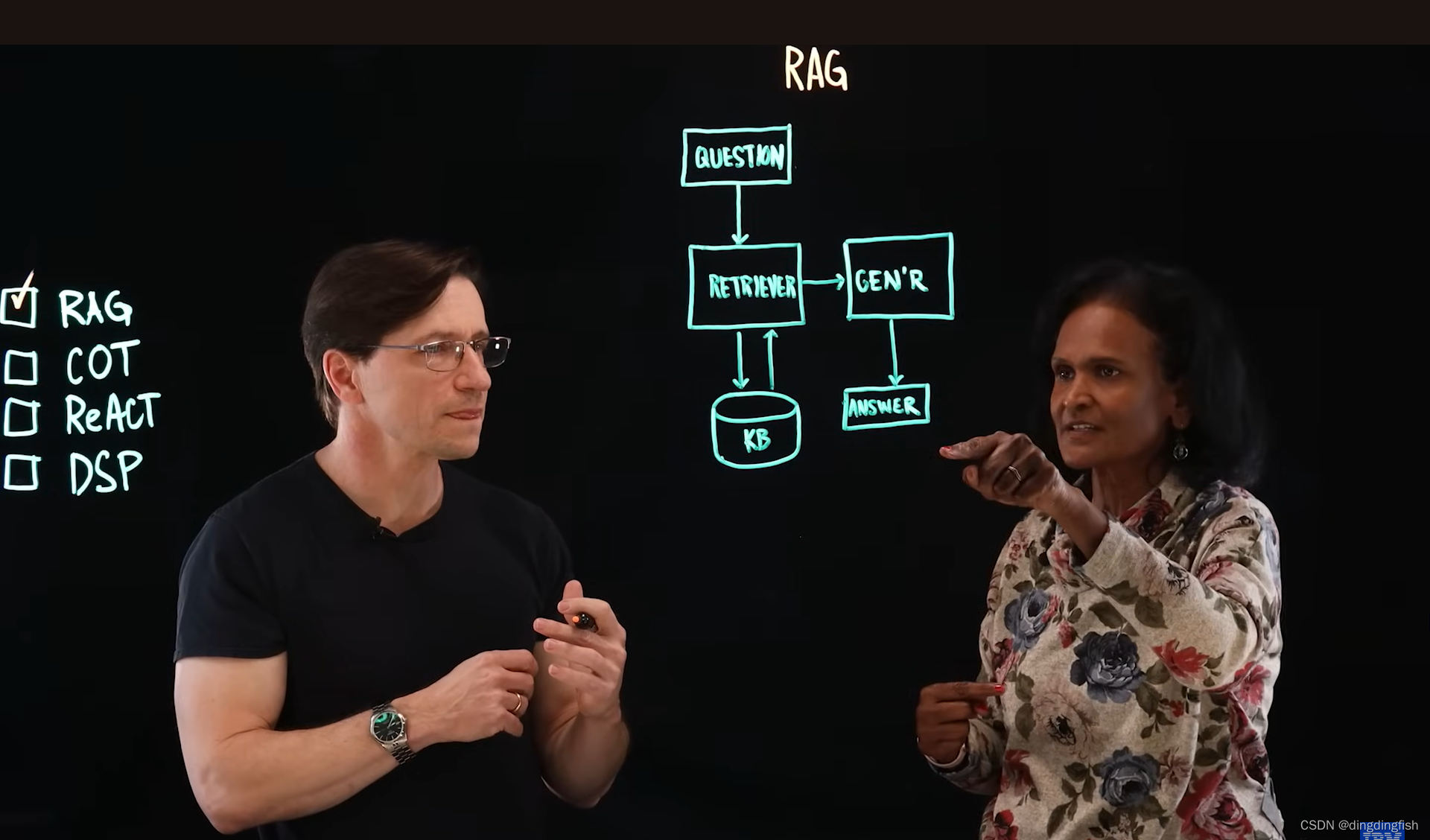
RAG就是检索增强生成,是一种将私域知识库与大语言模型集成的方案,之前在什么是RAG?中详细介绍过。RAG为模型增加了专域的知识。大语言模型是基于互联网数据训练的,他并不知道你的专域/私域信息。而我们希望将特定于行业,特定于企业的知识代入大模型,此时我们需要两个组件(看图),即检索器(Retriever)和生成(Generator)器。检索器将专域知识库的上下文带到大型语言模型的生成器,从而实现根据内容的领域特殊性来回答问题。 检索器可以像数据库搜索一样简单,确切地说,它可以是向量数据库。
例如,通过大语言模型询问一家公司特定年份的总收入,它会通过学习和互联网数据得出一个可能不准确的数字。 如果想获得准确的答案,那么就需要向领域知识库提出相同的问题。 然后大型语言模型将参考您的知识库来得出准确的答案。
在4种Prompt Engineering方法中,RAG是首选的方法。RAG的所有content grounding,就是让答案更接地气。
CoT(Chain of Thoughts)
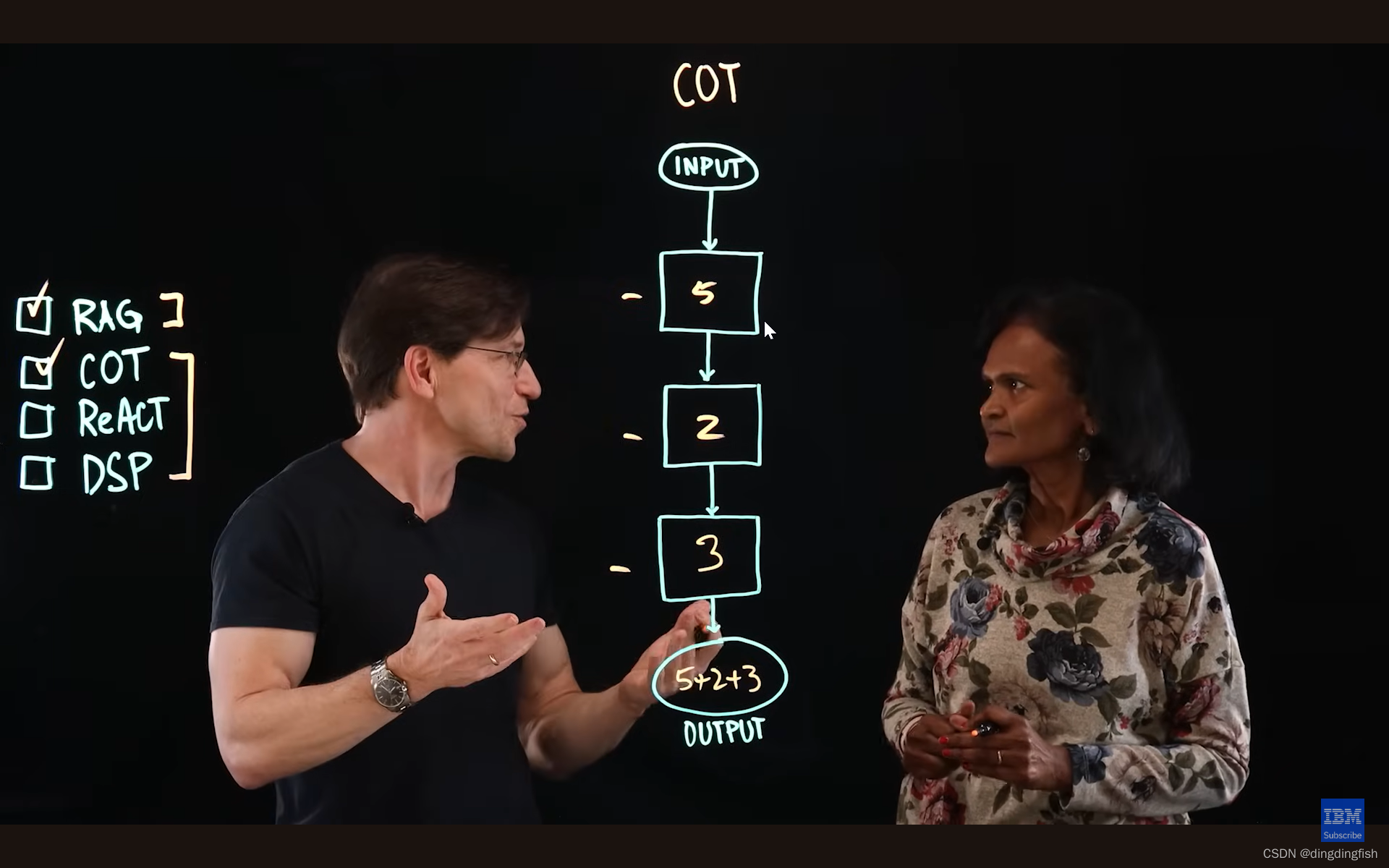
第2种方法是思想链(CoT)。大语言模型,就像一个八岁的孩子一样,也需要引导以得到正确的答案。 思维链将一个大的任务分解为小任务,然后将小任务的答案合并以得到最终答案。例如,我们想知道一家公司 2022 年的总收入,我们可以问大语言模型,给我某公司2022年软件、硬件、咨询的总收入。像图中的例子,本质上是三个独立的查询,三个独立的提示。和大语言模型沟通的方式是告知问题并解释如何分解问题。RAG是基于专域知识库优化答案,CoT是基于子问题的答案优化最终答案。
ReAct (Thought, Action, and Observation)
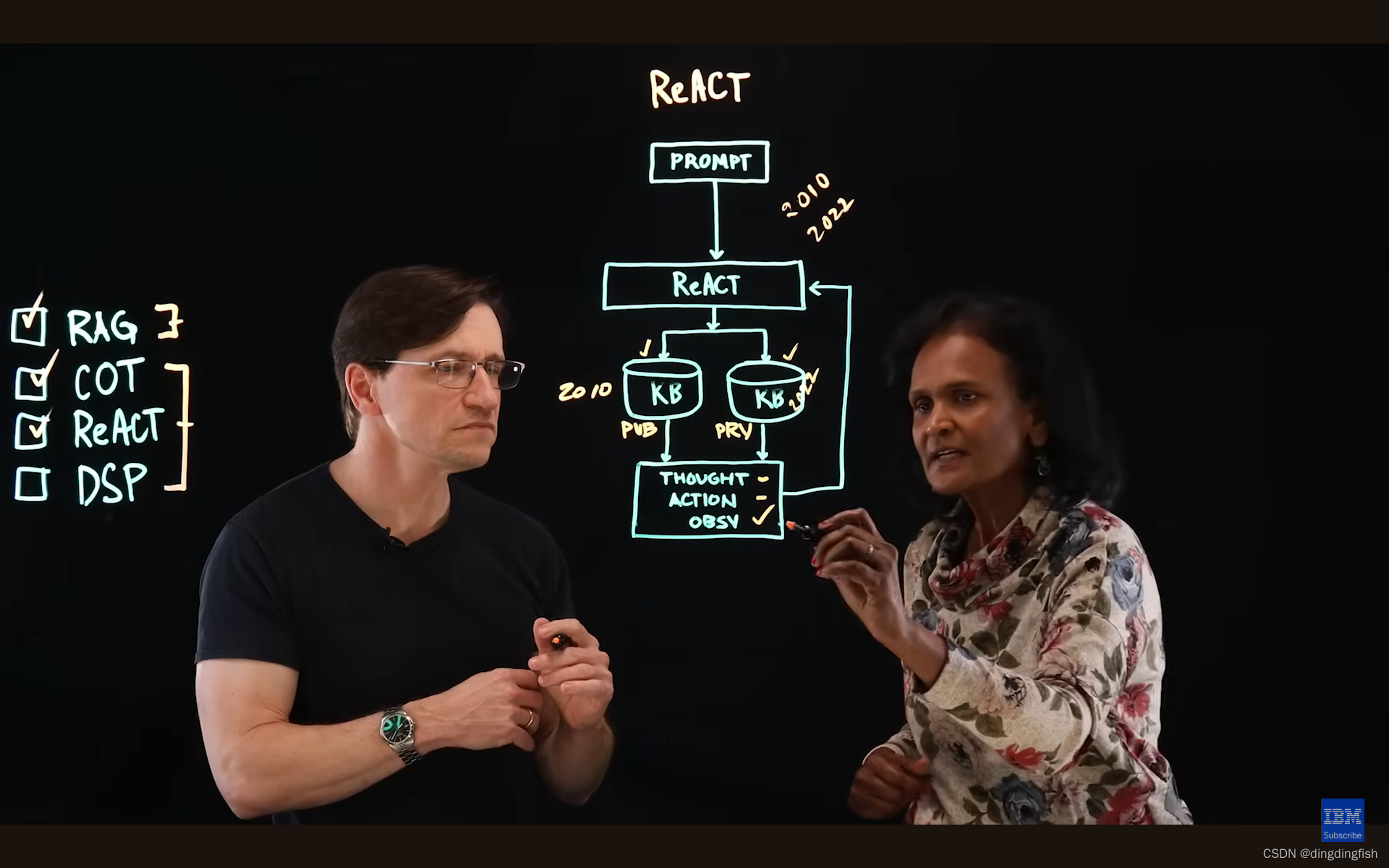
ReAct与CoT类似,也是通过一些简短的提示技巧来改进最终结果。但ReAct比COT更进一步,不仅仅推理,而且会根据所需的其他条件来采取行动。例如,私域知识库并未包含所需的答案,ReAct 方法能够实际进入公共知识库中的私有信息并收集信息,然后得出响应。因此,ReAct 的行动部分是它能够访问外部资源(公共知识库)以获取更多信息,从而得出响应。
ReAct和CoT相比,都有推理(reasoning)的部分,但ReAct多了一个行动(acting)的部分。ReAct与RAG先比,都使用了私域数据库,不同的是,ReAct可以引入公开的内容和知识库。
例如,我们查询某公司2010和2022年的总收入,私域数据库中只有2022年的数据,2010年的数据就可以在外部资源中获取。
ReAct分为3个步骤:
- thought(思考,找什么)
- action(行动,去哪里,得到什么)
- observation(观察,第2步的汇总)
DSP (Direct Stimulus Prompting)

DSP(定向刺激提示)是一种全新方式,它指明一个方向,使大型语言模型能够从任务中提取特定信息。
例如,您提出一个问题:“某公司的年收入是多少?”,但你并想要一个总的数字,而是其中具体的软件或咨询的年收入。所以你给出一个提示:“软件或咨询”。然后,大语言模型就可以从中提取软件或咨询的具体数值。这就像你试图让某人画一幅画,通过你的提升,最终的画像会越来越清晰。但需要从任务中寻找特定值时,DSP的效果非常好。