初探机器学习
“两只手”代表的是人工智能可以做的两大类任务,即预测与决策。
“四条腿”则代表支撑人工智能的四大类科学技术,包括搜索、推理、学习和博弈。
非参数化模型(nonparametric model):与参数化模型相反,非参数化模型并非由一个具体的参数向量来确定,其训练的算法也不是更新模型的参数,而是由具体的计算规则直接在模型空间中寻找模型实例。
机器学习的底层是数理统计,其基本原理是,相似的数据拥有相似的标签。
让不同的机器学习模型的给定任务下达到相同的泛化能力,需要的训练数据量往往也是不同的。这背后的原因是,不同的机器学习模型对特定数据模式的归纳偏置(inductive bias)不同。所谓归纳偏置,就是指模型对问题的先验假设,比如假设空间上相邻的样本有相似的特征。归纳偏置可以让模型在缺乏对样本的知识时也能给出预测,对某类数据的归纳偏置更强的模型能够更快地学到其中的模式。例如神经网络模型对同分布域的感知数据的归纳偏置就很强,处理图像和语音的模式识别任务效果非常好;而树模型对混合离散连续的结构化数据的归纳偏置很强,对于银行表单数据和医疗风险的预测效果很好。可以说,归纳偏置就是机器学习模型的天赋。
在机器学习中,较为常用的矩阵范数是弗罗贝尼乌斯范数(Frobenius norm),简称F范数,定义为矩阵每个元素的平方之和的平方根
第一,凸函数不一定在所有点可导(可求梯度)。但我们在机器学习中遇到的大多数函数,都可以通过合理规定不可导点的导数来尽量弥补这一缺陷。
第二,凸函数不一定存在极值点。
第三,存在全局唯一极小值点的不一定是凸函数
习题
1.错误。不满足绝对齐次性,ax不改变非零元素个数,但是乘a会改变

2.C、D错误。C:(Ax)y是向量乘向量,是一个数;A(xy)是矩阵乘数,是一个矩阵。D:-|x|
3.违反三角不等式,考虑x=(2,0),y=(0,2),则
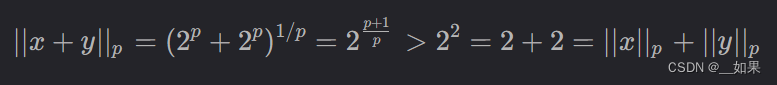
4.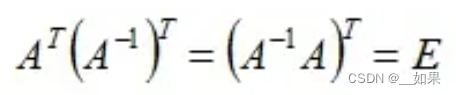
5.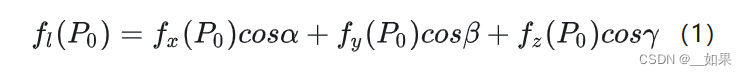

6.
7.
8.略