目录
- 1、算法的概念
- 1.1 举例:
- 1.2 算法的五大特性:
- 1.3 时间复杂度
- 1.4 空间复杂度
- 2、数据结构
- 2.1 内存的存储结构
- 2.2 数据结构的分类
- 2.3 顺序表存储方式
- 3、链表
- 3.1链表实现
- 3.2链表的方法
- 3.3链表增加节点
- 3.4链表删除节点
- 3.5链表总结
- 4、栈
- 4.1 栈的介绍
- 4.2 栈的代码实现
- 5、队列
- 5.1 队列的介绍
- 5.2 队列的代码实现
- 6、双端队列
- 7、数据结构与算法_排序算法
- 7.1 排序算法的稳定性
- 7.2 冒泡排序
- 7.3 选择排序
- 7.4 插入排序
- 7.5 快速排序
- 8、数据结构与算法_二分查找
- 8.1 二分查找
- 9、数据结构与算法_二叉树
- 9.1 树的概念
- 9.2 树的种类和存储方式
- 9.3 树的应用场景
- 9.4 二叉树的概念和性质
- 9.5 二叉树的广度优先遍历
- 9.6 二叉树的三种深度优先遍历
1、算法的概念
算法与数据结构作用:大大提升程序的性能。(战役中的兵法)
数据结构:存储、组织数据的方式
相同的数据不同的组织方式就是数据结构。([老王,18,男]或者{name:‘老王’,age:18,sex:‘男’})
算法:为了实习业务目的的各种方法和思路
算法独立存在,代码只是实现算法思想的方式而已。(例如穷举法,可以C语言实现也可以python代码实现)
算法概念:
1.1 举例:
若a+b+c =1000,且a^2+b ^2 =c ^2,如何求出所有abc的可能组合
#穷举法
#1,列举所有可能取值,2,判断是否满足条件
import time
start_time = time.time()
for a in range(0,1001):
for b in range(0,1001):
for c in range(0,1001):
if a**2+b**2 == c**2 and a+b+c==1000:
print('a b c:',a,b,c)
end_time = time.time()
cost_time = end_time-start_time
print(cost_time)
统计运行的时间:time.time()
1.2 算法的五大特性:
- 输入。0个或多个输入
- 输出。算法至少有1个或者多个输出
- 有穷性:算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成
- 确定性:算法中的每一步都有确定的含义,不会出现二义性
- 可行性:算法的每一步都是可行的,即每一步都能够执行有限次数完成
#方法二:在知道abc关系了,所以不用再对c遍历
import time
start_time = time.time()
for a in range(0,1001):
for b in range(0,1001):
c= 1000-a-b
if a**2+b**2 == c**2 :
print('a b c:',a,b,c)
end_time = time.time()
cost_time = end_time-start_time
print(cost_time)
实现算法程序的执行时间可以反应出算法的优劣
代码执行总时间 = 操作步骤数量*操作步骤执行时间
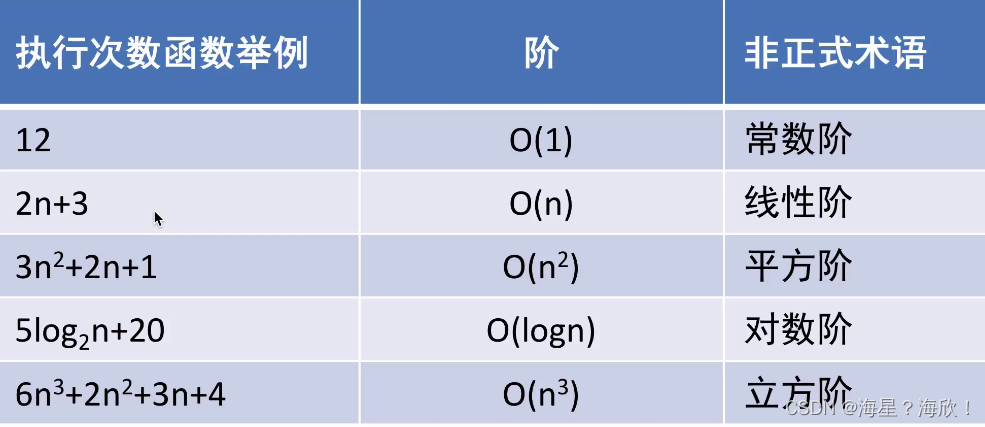
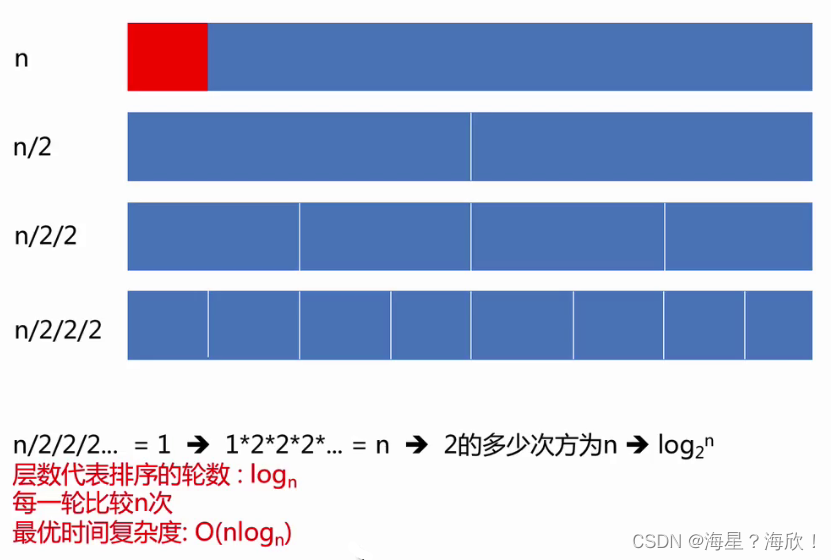
1.3 时间复杂度


时间复杂度可以表示一个算法随着问题规模不断变化的最主要趋势
衡量到算法的量级即可。大O记法
方法一的时间复杂度:T(n) = O(n^3)
方法二的时间复杂度:T(n) = O(n^2)

最优时间复杂度:算法完成工作最少需要多少基本操作。价值不大
最坏时间复杂度:算法完成工作最多需要多少基本操作。一种保证
平均时间复杂度:算法完成工作平均需要多少基本操作。一种全面评价


1.4 空间复杂度
空间复杂度:一个算法在运行过程中临时占用存储空间大小的度量
算法的时间复杂度和空间复杂度合称为算法的复杂度
2、数据结构
数据结构作用:数据结构是存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。

数据结构:静态的描述了数据元素之间的关系
高效的程序需要需要在数据结构的基础上设计和选择算法
算法是为了解决实际问题而设计的,数据结构是算法需要处理问题的载体
数据结构+算法 = 程序
2.1 内存的存储结构
内存是以字节为基本存储单位的(1024b=1kb),每个基本存储空间都有自己的地址。内存地址是连续的
整型:占4个字节
字符:1个字节
2.2 数据结构的分类
线性结构和非线性结构
线性结构:表中各个结点具有线性关系。(栈,队列等)
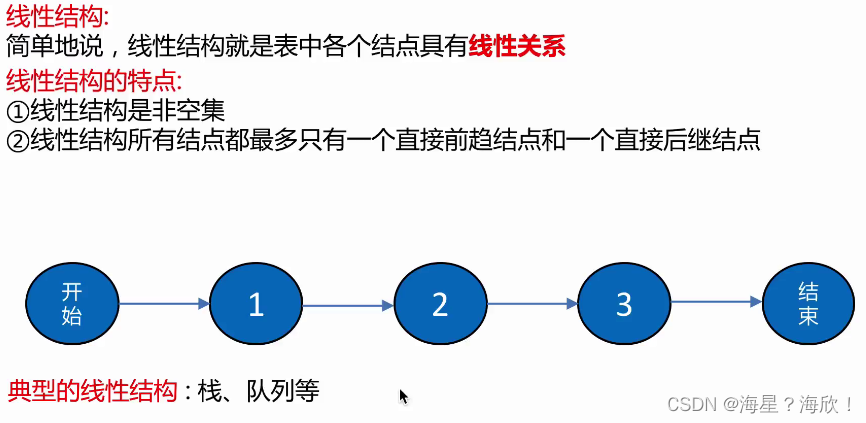
线性结构:表中各个结点具有多个对应关系。(树结构,图结构等)

2.3 顺序表存储方式
线性结构的实际存储方式,分为:顺序表和链表
顺序表:将元素顺序地存放在一块连续的存储区里,元素间的顺序关系由他们的存储顺序自然表示
链表:通过链接构造起来的一系列存储块中,存储区是非连续的。

顺序表存储数据的两种情况:一体式结构、分离式结构
顺序表的完整信息:数据区与信息区(元素存储区的容量和当前表中已有的元素个数)
顺序表删除元素:

3、链表
3.1链表实现
链表:不需要连续的存储空间
存储地址,保证了能找到下一个存储地址
顺序表是一个连续的存储空间

#链表结点实现
class SingleNode(object):
def __init__(self,item):
#item:存放元素 next:标识下一个结点
self.item = item
self.next = None
#结点
node1 = SingleNode(10)
print(node1.item)
print(node1.next)
#单链表的实现
class SingleLinkList(object):
def __init__(self,node=None):
#head:首节点
self.head=node
#链表
link1 = SingleLinkList()
print(link1.head)
link2 = SingleLinkList(node1)
print(link2.head.item) #输出10
链表:不需要连续的存储空间
实现链表:结点类;单链表类(由多个节点组成)

3.2链表的方法
链表的判空:看head是否为空
链表的长度测量:增加一个游标cur和一个计数count
链表的遍历:游标cur经过的每个元素都打印出来
#链表结点实现
class SingleNode(object):
def __init__(self,item):
#item:存放元素 next:标识下一个结点
self.item = item
self.next = None
#单链表的实现
class SingleLinkList(object):
def __init__(self,node=None):
#head:首节点
self.head=node
#判断链表是否为空
def is_empty(self):
if self.head is None:
return True
else:
return False
#获取链表长度
def length(self):
cur = self.head #游标记录当前所在位置
count = 0 #记录链表长度
while cur is not None:
cur = cur.next
count+=1
return count
#遍历链表
def travel(self):
cur = self.head
while cur is not None:
print(cur.item)
cur = cur.next
if __name__ =='__main__':
node1 = SingleNode(10)
#链表
link1 = SingleLinkList()
#判空
print(link1.is_empty())
#长度
print(link1.length())
#遍历
link1.travel()
3.3链表增加节点
三种情况:链表头部增加结点add(item)、尾部增加结点append(item)、指定位置增加结点insert(item)
1,链表头部增加结点add(item)
先新结点指向原头部
再头部head指向新结点
2,尾部增加结点append(item)
找到尾结点,让尾结点指向新结点
while cur.next is not None
cur = cur.next
cur.next = new_node
3,指定位置增加结点insert(item)
第一步:找到插入位置的前一个结点,
while count <pos:
cur = cur.next
count +=1
第二步:插入新结点
node.next = cur.next
cur.next = node
#链表结点实现
class SingleNode(object):
def __init__(self,item):
#item:存放元素 next:标识下一个结点
self.item = item
self.next = None
#单链表的实现
class SingleLinkList(object):
def __init__(self,node=None):
#head:首节点
self.head=node
#头部增加结点
def add(self,item):
#新结点存储数据
node = SingleNode(item)
node.next = self.head
self.head = node
#尾部增加结点
def append(self,item):
node = SingleNode(item)
#判断是否为空链表
if self.is_empty():
self.head = node
else:
cur = self.head
while cur.next is not None:
cur = cur.next
cur.next = node
#指定位置增加结点
def insert(self,pos,item):
#新结点
node = SingleNode(item)
if pos <=0: #头部增加新结点
self.add(item)
elif pos>=self.length(): #尾部增加新结点
self.append(item)
else:
#游标
cur = self.head
#计数
count = 0
#找到插入位置的前一个结点,
while count <pos-1:
cur = cur.next
count +=1
#插入新结点
node.next = cur.next
cur.next = node
if __name__ =='__main__':
node1 = SingleNode(10)
#链表
link1 = SingleLinkList()
#头部增加节点
link1.add(9)
#尾部增加结点
link1.append(11)
#指定位置增加结点
link1.insert(100,0)
link1.travel()
3.4链表删除节点
remove(item)删除节点
search(item)查找结点是否存在
remove()在头部找到要删除的元素:
cur = head
pre = None
while cur is not None:
if cur.item == item:
#要删除元素在头部
if cur ==head:
head = cur.next
#要删除元素不在头部
else:
pre.next = cur.next
return
#链表结点实现
class SingleNode(object):
def __init__(self,item):
#item:存放元素 next:标识下一个结点
self.item = item
self.next = None
#单链表的实现
class SingleLinkList(object):
def __init__(self,node=None):
#head:首节点
self.head=node
#删除节点
def remove(self,item):
cur = self.head #游标
while cur is not None:
if cur.item ==item: #找到了删除元素
if cur == self.head: #要删除的在头部
self.head = cur.next
else: #要删除的不在头部
pre.next = cur.next
return
else: #没找到要删除元素
pre = cur
cur = cur.next
#查找结点是否存在
def search(self,item):
cur = self.head
while cur is not None:
if cur.item ==item:
return True
cur= cur.next
return False
if __name__ =='__main__':
node1 = SingleNode(10)
#链表
link1 = SingleLinkList()
#头部增加节点
link1.add(9)
#尾部增加结点
link1.append(11)
#指定位置增加结点
link1.insert(100,0)
link1.travel()
#删除元素
link1.remove(9)
link1.travel()
#查找结点是否存在
print(link1.search(11))
print(link1.search(9))
3.5链表总结
线性结构:最多只能有一个前驱结点和一个后继结点
非线性结构:可以有多个前驱结点和一个后继结点
线性结构:顺序表、链表
顺序表:元素顺序地存放在一块连续的存储区里,元素间的顺序关系由他们的存储顺序自然表示
链表:将元素存放在通过链接构造起来的一系列存储块中,存储空间非连续

4、栈
4.1 栈的介绍
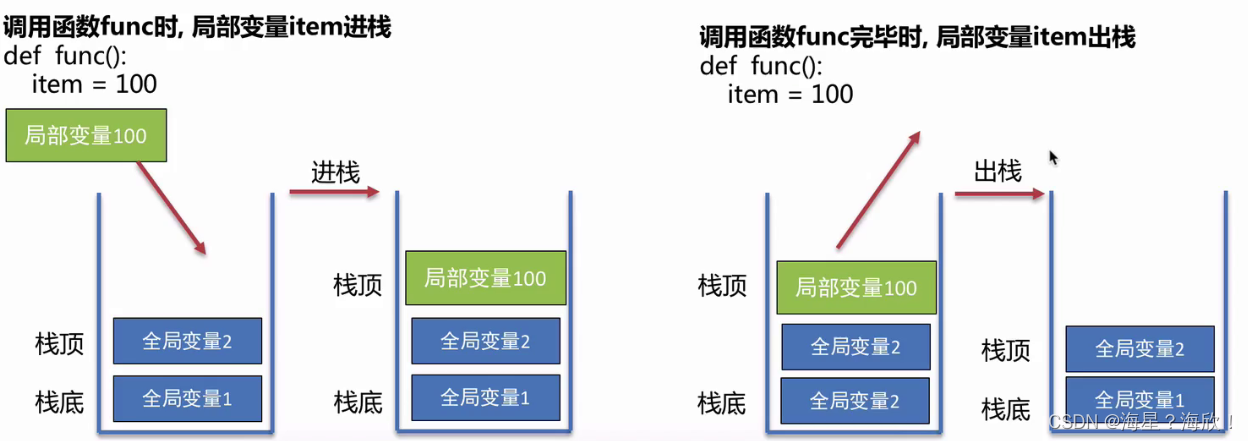
栈:运算受限的线性表,其限制是仅允许在表的一端进行插入和删除运算,这一端为栈顶,另一端为栈底。特点:先进后出
栈是计算机系统CPU结构里的一部分
栈的作用:局部变量的方便存储和及时销毁
4.2 栈的代码实现
借助链表

所以选择尾部进行增删操作
class Stack(object):
"""栈:先进后出"""
def __init__(self):
self.__items = []
def push(self):
"""进栈"""
self.__items.append(item)
def pop(self):
"""出栈"""
self.__items.pop()
def trave(self):
"""遍历"""
for i in self.__items:
print(i)
my_stack = Stack()
my_stack.push(1)
my_stack.push(1)
my_stack.push(1)
my_stack.trave() #输出1\n 2\n 3\n
#出栈
my_stack.pop()
my_stack.trave() #输出1\n 2\n
5、队列
5.1 队列的介绍
队列:一种特殊的线性表,特殊之处在于它只允许表的头部进行删除操作,表的尾部进行插入操作,是一种操作受限制的线性表,进行插入操作的端为队尾,进行删除操作的端为队头
队列的作用:任务处理类系统(多个任务发起,先存储起来,排队一个一个进行处理,起到了缓冲压力的作用)
5.2 队列的代码实现
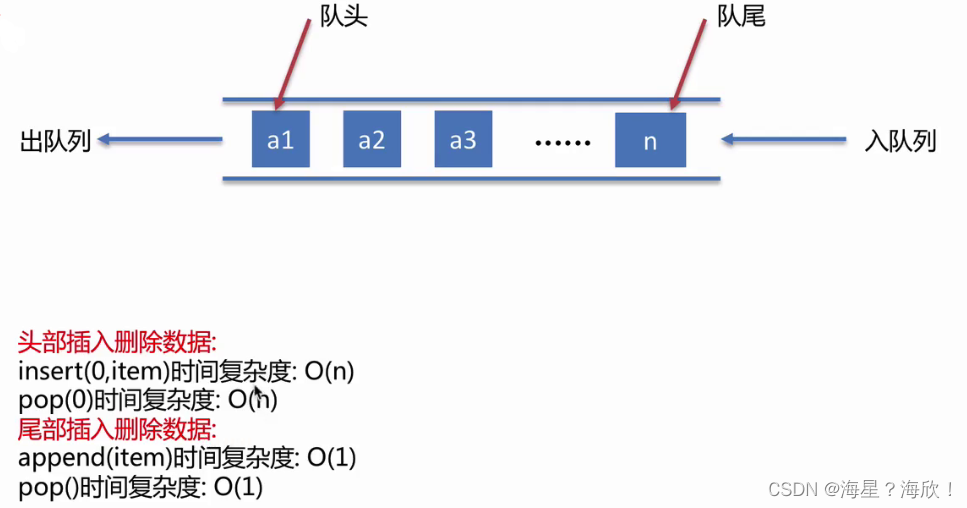
此时选择对头队尾,复杂度都一样了,o(1)+o(n)
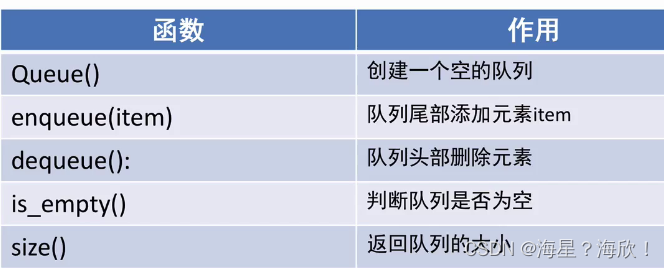
Class Queue(object):
def __init__(self):
#存储数据,线性表
self.items = []
#enqueue(item)队列尾部添加元素
def enqueue(self,item):
self.items.append(item)
#dequeue(item)队列头添加元素
def dequeue(self,item):
self.items.pop(0)
#is_empty()判断队列是否为空
def is_empty()(self):
return self.items == []
#size()返回队列的大小
def size(self):
return len(self.items)
q = Queue()
#添加数据
q.enqueue(1)
q.enqueue(2)
q.enqueue(3)
for i in q.items:
print(i) #输出:1\n2\n3\n
#删除数据
q.dequeue()
for i in q.items:
print(i) #输出:2\n3\n
print(q.is_empty())
print(q.size())
6、双端队列
双端队列:是一种具有队列和栈的数据结构。元素可以任意从两端进行插入和删除操作。

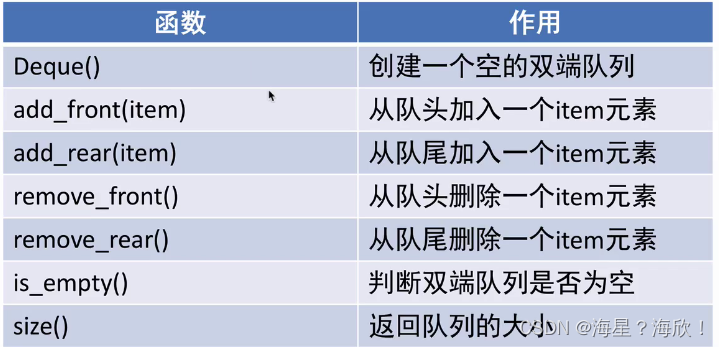
Class Deque(object):
def __init__(self):
self.items = []
def is_empty(self): #判断是否为空
return self.items == []
def size(self): #大小
return len(self.items)
def add_front(self,item): #头部添加数据
self.items.insert(0,item)
def add_rear(self,item): #尾部添加数据
self.items.append(item)
def remove_front(self,item): #头部删除数据
self.items.pop(0)
def remove_rear(self,item): #尾部删除数据
self.items.pop()
deque = Deque()
print(deque.is_empty())
print(deque.size())
#添加数据
deque.add_front(1)
deque.add_front(2)
deque.add_rear(3)
deque.add_rear(4)
for i in q.items:
print(i) #输出:2\n1\n3\n4\n
#删除数据
deque.remove_front()
deque.remove_rear()
for i in q.items:
print(i) #输出:1\n3\n
7、数据结构与算法_排序算法
7.1 排序算法的稳定性
排序:使得一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来
排序算法:如何使得这一串记录按照要求排列的方法
算法的稳定性:
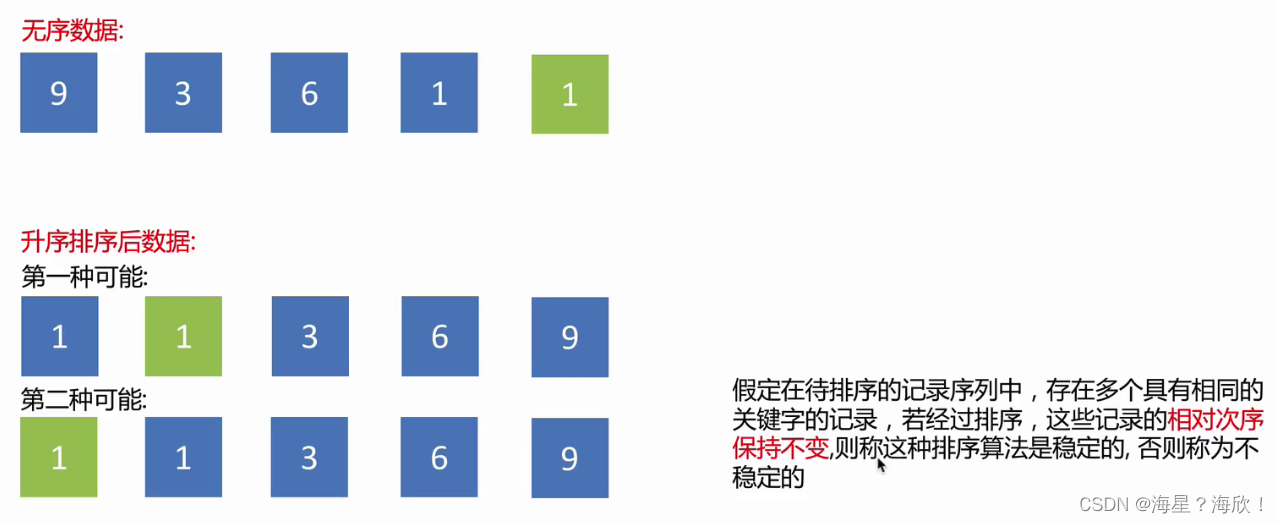
对于具有相同的关键词的记录,他们的相对次序不变,即这种算法是稳定的,否则是不稳定的
不稳定的排序算法:选择排序、快速排序、希尔排序、堆排序
稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序
7.2 冒泡排序
冒泡排序:重复地走访过要排序的元素列,依次比较两个相邻的元素,如果元素排序错误就交换过来。重复进行直到没有相邻元素需要交换为止
代码实现:
def bubble_sort(alist):
"""冒泡排序"""
n=len(alist)
for j in range(0,n-1):
count =0
for i in range(0,n-j-1): #控制每一轮的比较次数
#比较相邻两数字,不符合要求便交换位置
if alist[i]>alist[i+1]:
alist[i],alist[i+1] =alist[i+1],alist[i]
count +=1
if count == 0: #如果遍历一轮后没有数字交换,就退出循环,防止浪费资源
break
if __name__ == '__main__':
alist = [5,3,4,7,2]
bubble_sort(alist)
print(alist)
冒泡排序:
时间复杂度:o(n^2)
最优时间复杂度 :o(n) 最少也需要遍历一遍
算法稳定性:稳定算法 (if alist[i]>alist[i+1]中如果是>= ,则不是稳定算法)
7.3 选择排序
选择排序:第一次从待排序的数据元素中选出最小(大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,放到已排序的序列末尾,依次类推,直到全部排序完
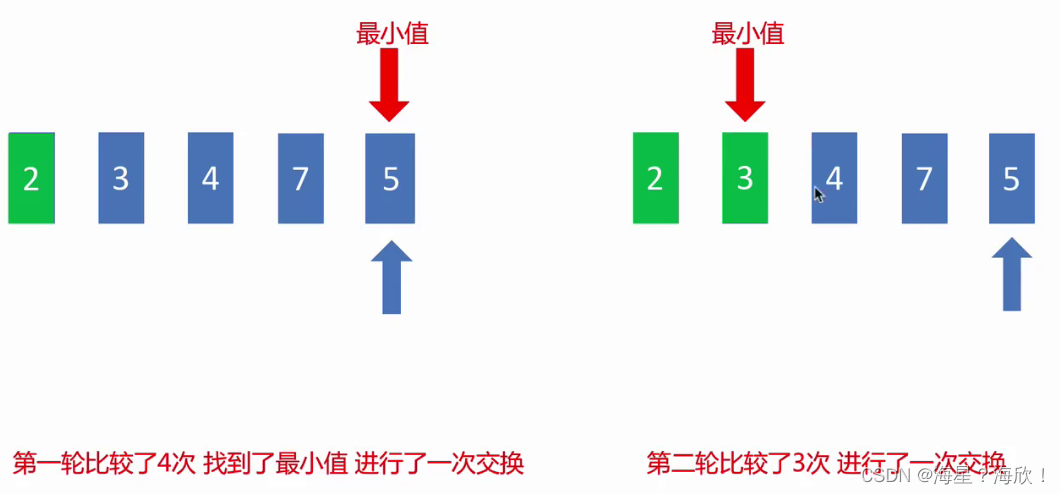
def select_sort(alist):
"""选择排序"""
n = len(alist) #列表的长度
for j in range(0,n):
min_index = j #假定的最小值下标
for i in range(j+1,n):
if alist[i] < alist[min_index]: #进行比较获得最小值的下标
min_index = i
if min_index !=j:
alist[min_index],alist[j] = alist[j],alist[min_index]
if __name__ == '__main__':
alist = [1,5,3,4,7,2]
select_sort(alist)
print(alist)
选择排序:
时间复杂度:o(n^2)
最优时间复杂度 :o(n^2)
算法稳定性:不稳定算法
7.4 插入排序
插入排序:将一个数据插入到已经排好序的有序数据中,从而得到一个新的,个数加一的有序数据,算法适用于少量数据的排序。排序时将第一个数作为有序数据
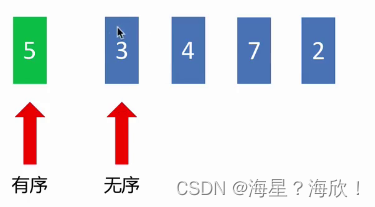
def insert_sort(alist):
"""插入排序"""
n = len(alist) #列表长度
for j in range(1,n): #控制轮数
for i in range(j,0,-1):#找到合适的位置安放我们的无序数据[j,j-1,j-2,...1]
if alist[i]<alist[i-1]:
alist[i],alist[i-1] =alist[i-1],alist[i]
else:
break
if __name__ == '__main__':
alist = [1,5,3,4,7,2]
insert_sort(alist)
print(alist)
插入排序:
时间复杂度:o(n^2) – 降序数据变成升序
最优时间复杂度 :o(n) – 原本就是升序数据
算法稳定性:稳定算法 (if alist[i]<alist[i+1]中如果是<= ,则不是稳定算法)
7.5 快速排序

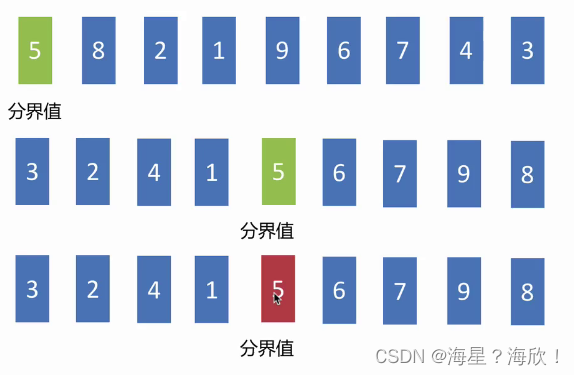
def quick_sort(alist,start,end):
"""快速排序"""
#递归的结束条件
if start>=end:
return
#界限值
mid = alist[start]
#左右游标
left = start
right = end
while left <right:
while alist[right]>=mid and left<right : #从右边开始找寻小于mid的值,归类到左边
right -=1
slist[left] = alist[right]
while alist[left]<mid and left<right:
left +=1
slist[right] = alist[left]
#循环一旦结束了,证明找到了mid应该在的位置
alist[left] = mid
#递归操作
quick_sort(alist,start,left-1)
quick_sort(alist,right+1,end)
if __name__ == '__main__':
alist = [1,5,3,4,7,2]
quick_sort(alist,0,len(alist)-1)
print(alist)
快速排序:
时间复杂度:o(n^2)
最优时间复杂度 :o(nlogn)
算法稳定性:不稳定算法
8、数据结构与算法_二分查找
8.1 二分查找
查找算法vs排序算法
二分查找:折半查找,是一种效率较高的查找方法
原理:将数组分成三部分,依次是中值前,中值,中值后,将要查找的值与中值进行比较,若小于中值则在中值前找,大于中值则在中值后面找
二分查找的要求:必须采用顺序存储结构,必须按照关键字大小有序排列
递归版本:
def binary_search(alist,item):
"""二分查找"""
#数列长度
n = len(alist)
#递归的结束条件,一定要记得写
if n==0:
return False
#中间值
mid = n//2 ##除出来取整,5//2=2
if item == alist[mid]:
return True
else item <alist[mid]:
return binary_search(alist[0:mid],item) #用递归,return返回过来
else item <alist[mid]:
return binary_search(alist[mid+1:],item)
if __name =='__main__':
alist[1,2,3,4,5]
print(binary_search(alist,1)) #输出:True
print(binary_search(alist,100)) #输出:False
非递归版本:
def binary_search(alist,item):
"""二分查找"""
#设置起始位置,来获取中间值.起始位置不断在变
start = 0
end = len(alist) -1
while start<=end:
#获取中间值
mid = (start+end)//2
if item == alist[mid]:
return True
else item <alist[mid]:
end = mid-1
else item >alist[mid]:
start = mid+1
return False
if __name =='__main__':
alist[1,2,3,4,5]
print(binary_search(alist,1)) #输出:True
print(binary_search(alist,100)) #输出:False
二分查找:
最差时间复杂度:o(logn)
最优时间复杂度 :o(1)
9、数据结构与算法_二叉树
9.1 树的概念
数据结构分为线性结构和非线性结构
非线性结构–树等(一个结点元素可能对应多个直接前驱和多个后继)
线性结构–顺序表、单向链表等(数据元素之间存在着“一对一”的线性关系的数据结构)
树:非线性结构。用来模拟具有树状结构性质的数据集合,它是由有限个节点组成一个具有层次关系的集合。倒挂的树
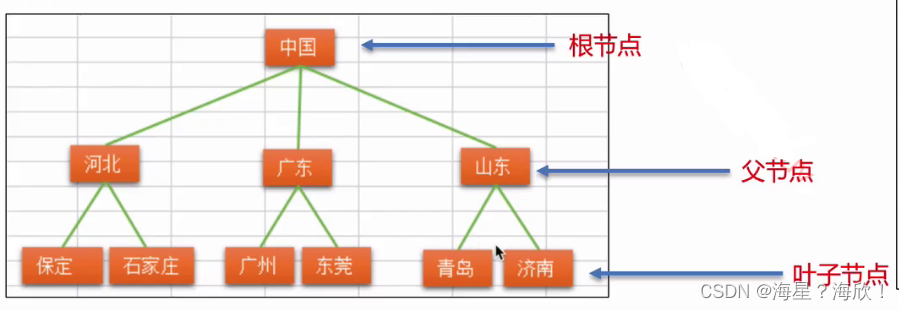
1,每个节点有零个或多个子节点
2,没有父节点的节点称为根节点
3,每一个非根节点有且只有一个父节点
4,除了根节点外,每个子节点可以分为多个不相交的子树
树的术语:

9.2 树的种类和存储方式
不同种类的树有不同的作用
- 无序树:树中任意节点之间没有顺序关系,无序树又称自由树
- 有序树:树中任意节点之间有顺序关系
有序树:霍夫曼树(用于信息编码)、B树、二叉树
二叉树:每个节点最多含有两个子树的树
二叉树的种类:
-
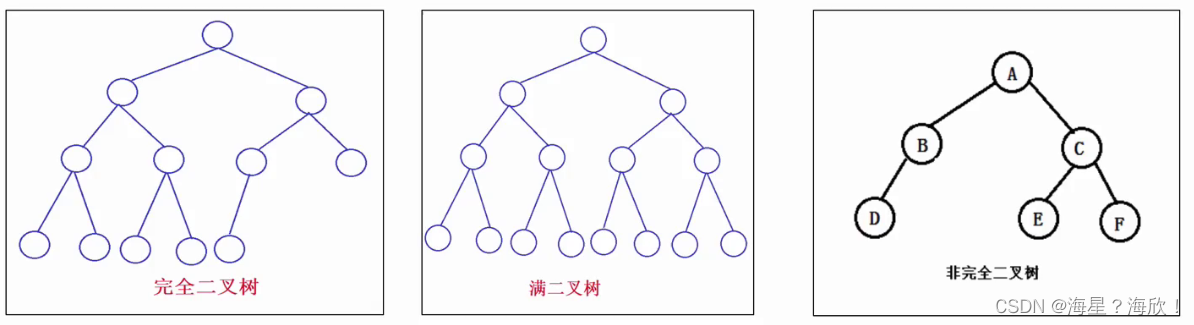
完全二叉树:对于一颗深度为d(d>1)的二叉树,除d层外,其他各层的节点数目均已达到最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树为完全二叉树。其中满二叉树是所有叶节点都在最底层的完全二叉树
-
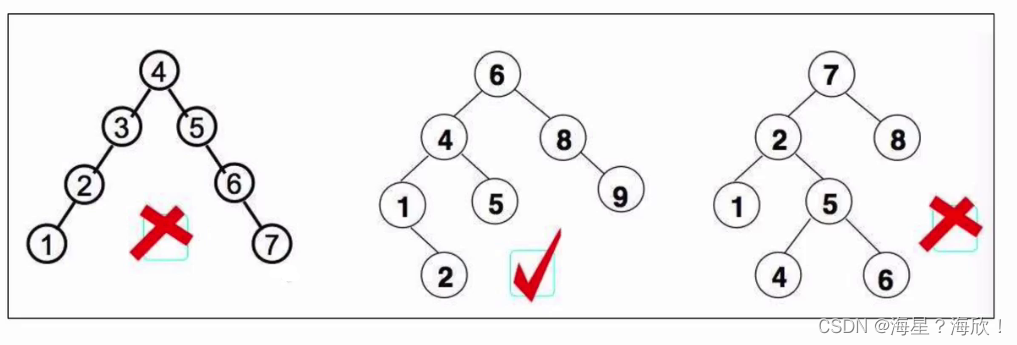
平衡二叉树:当且仅当任何节点的两个子树的高度差不大于1的二叉树
-
排序二叉树:又称二叉查找树,有序二叉树。满足对任何节点,若左子树不空,则左子树上所有节点的值均小于它的根节点的值。若右子树不空,则右子树上所有节点的值均大于它的根节点的值。
排序二叉树包括空树
二叉树的存储:顺序存储、链式存储
-
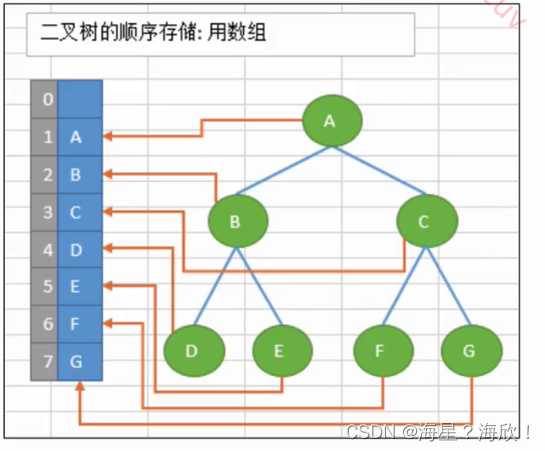
顺序存储:将数据结构存储在固定的数组中,在遍历速度上有一定的优势,但所占空间大,是非主流二叉树的存储方式
-
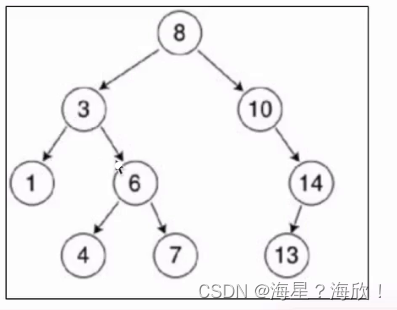
链式存储:由于对节点的个数无法掌握,常见树的存储表示都转换为二叉树进行处理,子节点个数最多为2
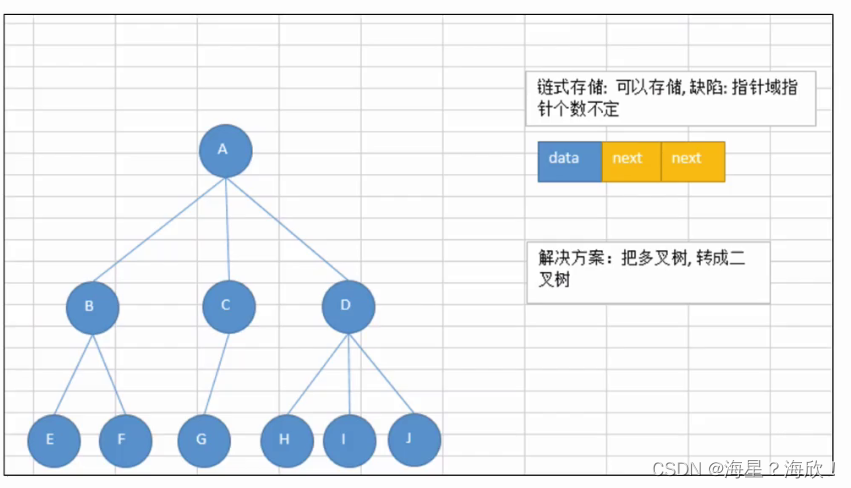
二叉树的常用存储方式:链式存储(每个结点有两个指针域)
9.3 树的应用场景
- xml、html等,编写他们的解析器时,要用到树
- 路由协议使用了树
- MySQL数据库索引
- 文件系统的目录结构
- 很多AI算法,例如决策树
数据库索引:
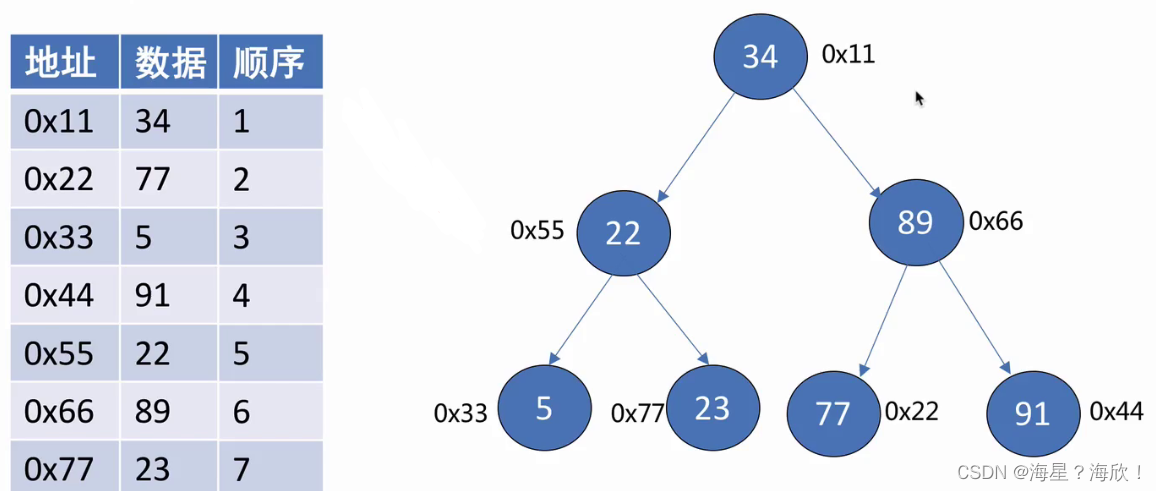
若没有索引,时间复杂度为O(n),加上索引后,类似二分查找,时间复杂度变为o(logn)
9.4 二叉树的概念和性质
二叉树:每个节点最多有两个子树的树结构

性质3:叶节点即终端节点,性质3给出了叶节点数与度数为2 的节点总数之间的关系
性质4即性质2求反
性质5:
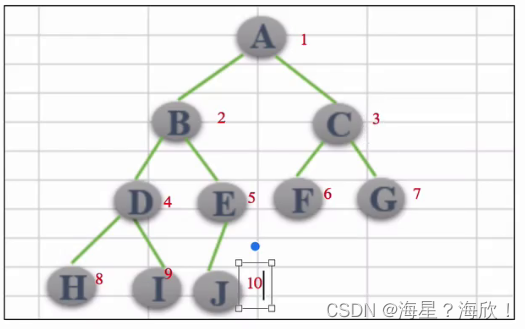
9.5 二叉树的广度优先遍历
完全二叉树的代码实现:
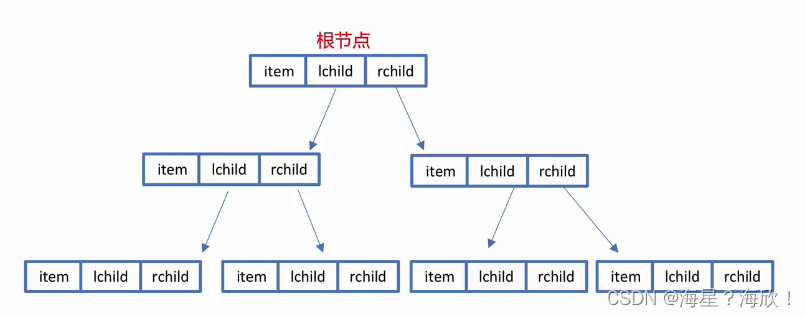

广度优先VS 深度优先:
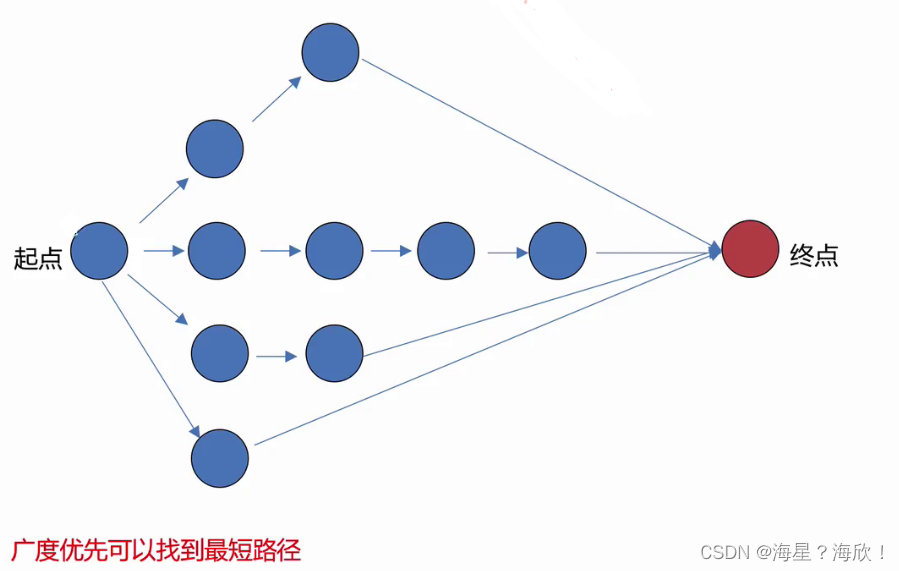
广度优先遍历代码:
Class Node(object):
"""节点类"""
def __init__(self,item):
self.item = item
self.lchild = None
self.rchild = None
Class BinaryTree(object):
"""完全二叉树"""
def __init__(self,node=None):
self.root = node
def add(self,item): #添加节点
if self.root == None:
self.root = Node(item)
return
queue = []
#从尾部添加数据
queue.append(self.root)
while True:
#从头部取出数据
node = queue.pop(0)
#判断左节点是否为空
if node.Lchild == None:
node.lchild = Node(item)
return
else:
queue.append(node.lchild)
if node.rchild == None:
node.rchild = Node(item)
return
else:
queue.append(node.rchild)
def breadh_travel(self): #广度优先遍历
if self.root == None:
return
#列表
queue = []
queue.append(self.root) #添加数据
while len(queue)>0:
node = queue.pop(0)#取出数据
print(node.item,end="")
#判断左右子节点是否为空
if node.lchild is not None:
queue.append(node.lchild)
if node.rchild is not None:
queue.append(node.rchild)
if __name__ == '__main__':
tree = BinaryTree()
tree.add("A")
tree.add("B")
tree.add("C")
tree.breadh_travel()
9.6 二叉树的三种深度优先遍历
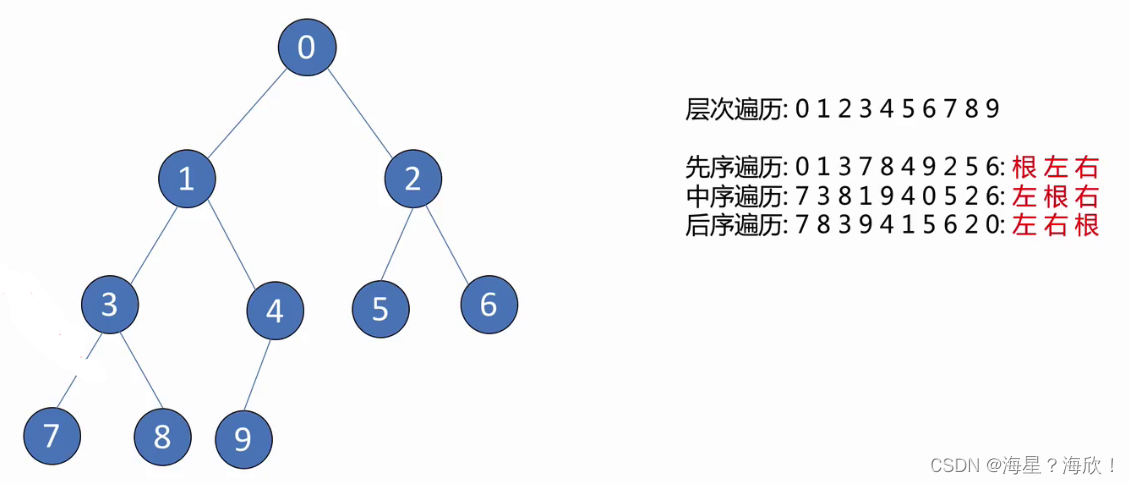

Class Node(object):
"""节点类"""
def __init__(self,item):
self.item = item
self.lchild = None
self.rchild = None
Class BinaryTree(object):
"""完全二叉树"""
def __init__(self,node=None):
self.root = node
def add(self,item): #添加节点
。。。。省略,见上一个代码
def preorder_travel(self,root):
"""先序遍历 根左右"""
if root is not None:
print(root.item,end="")
self.preorder_travel(root.lchild)
self.preorder_travel(root.rchild)
def inorder_travel(self,root):
"""中序遍历 左根右"""
if root is not None:
self.inorder_travel(root.lchild)
print(root.item,end="")
self.inorder_travel(root.rchild)
def postorder_travel(self,root):
"""后序遍历 左右根"""
if root is not None:
self.postorder_travel(root.lchild)
self.postorder_travel(root.rchild)
print(root.item,end="")
if __name__ == '__main__':
tree = BinaryTree()
tree.add("0")
tree.add("1")
tree.add("2")
tree.add("3")
tree.add("4")
tree.add("5")
tree.add("6")
tree.add("7")
tree.add("8")
tree.add("9")
tree.preorder_travel(tree.root) #输出:0137849256
print()
tree.preorder_travel(tree.root) #输出:7381940526
print()
tree.preorder_travel(tree.root) #输出:7839415620
print()