torch.cuda.OutOfMemoryError
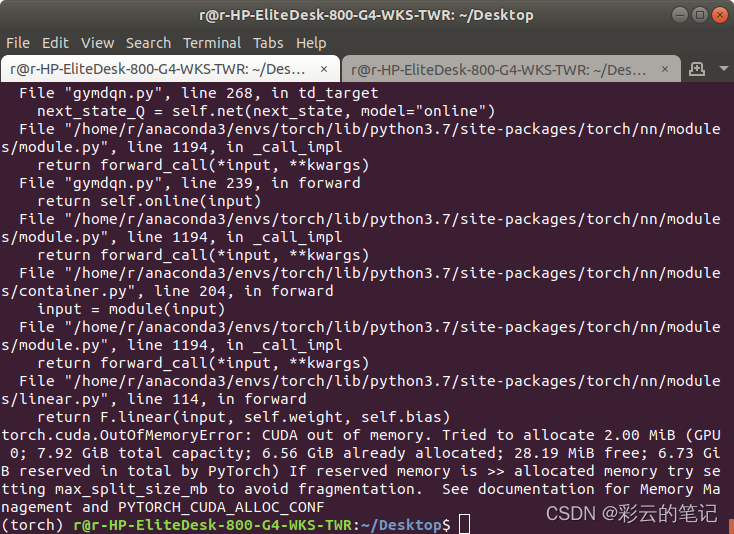
before:
self.memory = deque(maxlen=50000)
after:
self.memory = deque(maxlen=500)
ok....
pytorch模型提示超出内存cuda runtime error(2): out of memory - pytorch中文网
看到这个提示,表示您的GPU内存不足。由于我们经常在PyTorch中处理大量数据,因此很小的错误可能会迅速导致程序耗尽所有GPU; 好的事,这些情况下的修复通常很简单。这里有几个常见检查事项包括:
一、不要在循环训练中累积历史记录。
默认情况下,涉及需要求导/梯度gradients变量的计算将保存在内存中。计算中避免使用这些变量,例如在跟踪统计数据时,这些变量在循环训练中将超出你内存。相反,您应该分离变量或访问其基础数据。
有时,当可微分变量可能发生时,它可能并不明显。考虑以下循环训练(从源代码删减):
total_loss = 0
for i in range(10000):
optimizer.zero_grad()
output = model(input)
loss = criterion(output)
loss.backward()
optimizer.step()
total_loss += loss在这里,total_loss你的循环训练中积累了历史,因为它loss是一个具有autograd历史的可微变量。你可以通过编写total_loss += float(loss)来解决这个问题。
这个问题的其他例子: 1。
二、释放你不需要的张量和变量。
如果将一个张量或变量分配给本地,Python将不会释放,直到本地超出范围。你可以通过使用del x这样的代码释放。同样,如果将一个张量或变量赋值给对象的成员变量,它将不会释放,直到该对象超出范围。如果你释放了你不需要的变量,内存收益率会提升很多。
当地人的范围可能比你想象的要大。例如:
for i in range(5):
intermediate = f(input[i])
result += g(intermediate)
output = h(result)
return output在这里,intermediate即使在h执行时依然存在,因为它在循环结束后没有释放。你使用完它以后应该使用del intermediate释放它。
三、不要在太大的序列上运行RNN。
通过RNN反向传播所需的内存量与RNN的长度成线性关系; 因此,如果尝试向RNN提供一个时间太长的序列,则会耗尽内存。
这个现象的技术术语是基于时间的反向传播,关于如何实现截断的BPTT有很多参考资料,包括单词language model example; 截断由本论坛帖子中repackage描述的函数处理 。
四、不要使用太大的线性图层。
线性图层nn.Linear(m, n)使用O(nm)内存:也就是说,权重的内存需求与特征的数量成正比。通过这种方式来超出你的内存是非常容易的(并且记住你至少需要两倍的权重,因为你还需要存储梯度。)
原创文章,转载请注明 :pytorch模型提示超出内存cuda runtime error(2): out of memory - pytorch中文网
原文出处: https://ptorch.com/news/160.html












](https://img-blog.csdnimg.cn/8b67be67d0914fe1975858410531041e.png)