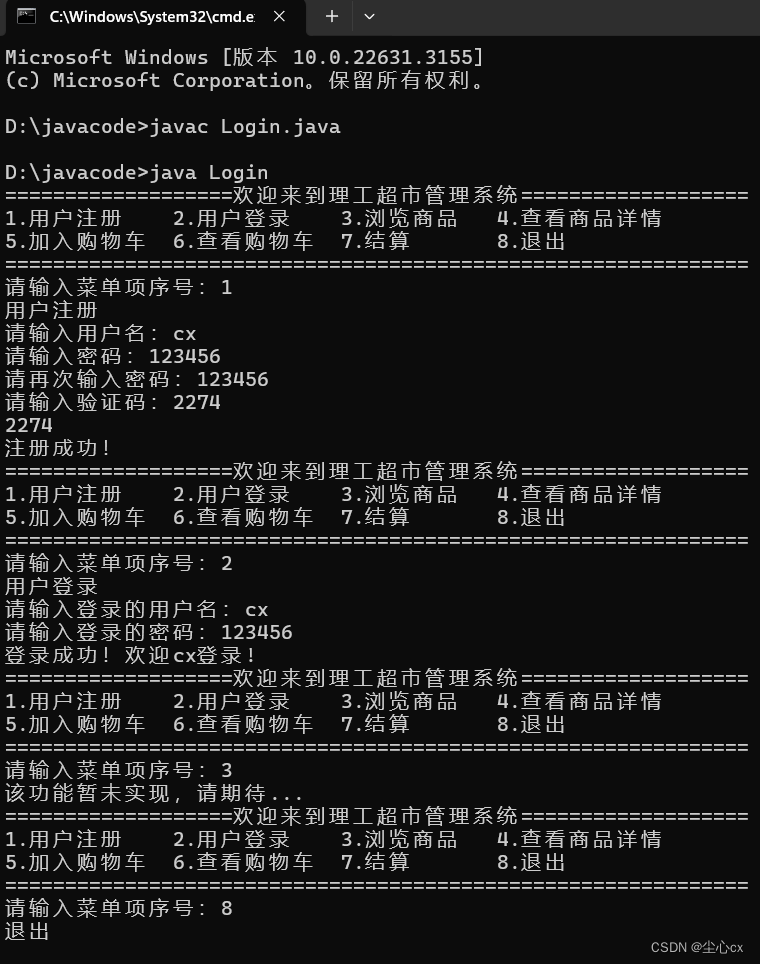
本文主要内容来自 ChatGPT 4.0
到底什么是 ETL?在数据库内部,把数据从 ODS 层加工成 DWD,再加工成 DWS,这个过程和 ETL 的关系是什么?带着这些问题,我问了一下 ChatGPT,总结如下。
数据在两个数据库之间流转时,从源端做 Extract,在目的端做 Load 操作。那么,在一个数据库内部,ETL 是怎样的?
在一个数据库内部,ETL(Extract, Transform, Load)作为数据处理的过程,同样涉及三个主要步骤:
-
Extract (提取):这一步骤涉及从数据库中提取所需的数据,这可能是来自数据库的不同表或不同行的数据。
-
Transform (转换):在这个阶段,提取出来的数据将会经过一系列转换操作,以便适合特定的业务规则和需求。这可能包括数据清洗、格式化、去重、数据合并、计算新的数据字段等。
-
Load (加载):这一步骤是将经过转换的数据重新加载回数据库的不同表、行或列中。这可能会涉及更新现有记录、插入新记录或者创建新的表来存储数据。
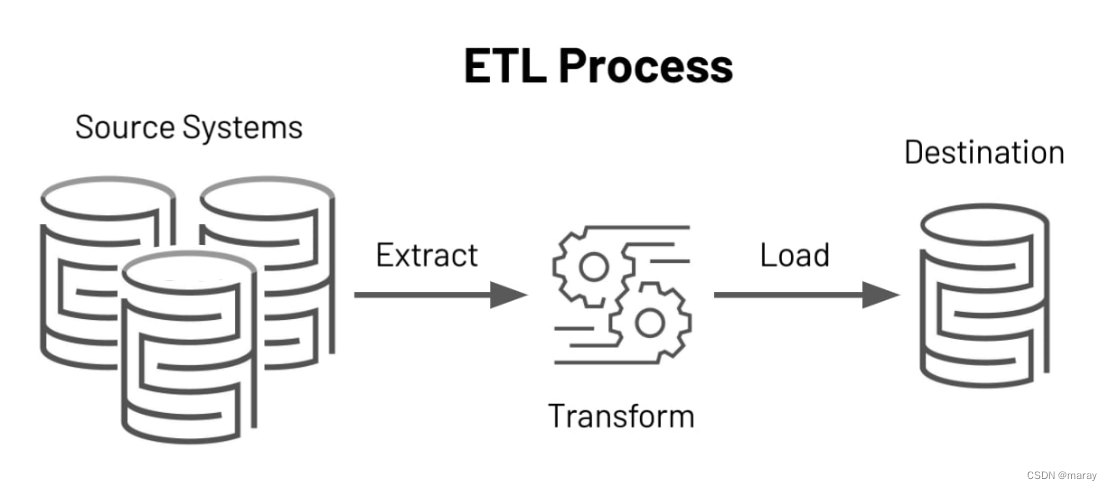
在数据库内部进行ETL的过程通常是为了数据仓库维护、报表生成、数据分析、性能优化等目的,以确保数据库中的数据是准确、一致、可用的。
数据仓库中,从上游数据起,到下游查询结果为止,数据的处理主要包含哪些步骤?
-
数据抽取:从上游系统(例如ERP,CRM,日志文件等)中抽取原始数据。
-
数据清洗:对抽取的数据进行清洗,去除不完整、不一致、重复或错误的数据。
-
数据转换:将清洗后的数据转换成数据仓库所需的格式,包括数据类型转换、计算衍生字段、进行数据聚合等。
-
数据加载:将转换后的数据加载到数据仓库中,通常是按照特定的维度和事实表结构存储数据。
-
数据存储:确定合适的存储方式和索引策略,以优化查询性能并保证数据的完整性和安全性。
-
数据管理:监控和维护数据仓库的性能,包括对数据量的管理、存储空间的优化和备份恢复策略等。
-
数据查询:利用SQL或者专门的数据查询工具对数据进行查询,获取业务所需的信息。
-
数据分析:使用数据分析工具或者BI(商业智能)工具进行深入的数据分析,提取有价值的商业洞察。
-
数据展现:将分析后的数据结果以图表、报表、仪表盘等形式展现给最终用户,以支持决策制定。
假设数据已经加载到了 ODS 层,数据从 ODS 到 DWD、DWS,这个变换过程,属于上面哪个步骤呢?
数据从ODS (Operational Data Store) 到 DWD (Data Warehouse Detail)、DWS (Data Warehouse Summary) 的变换过程,属于上面的“数据转换”步骤。在这一步,数据会经过进一步的清洗、转换和聚合,以适应数据仓库中对于数据分析和报告的需求。在转换后,数据将会被加载到相应的维度和事实表中,该过程对应的是“数据加载”的步骤。
那数据写入到 ODS 层,到 DWD 层,或者到 DWS 层,算数据加载吗?如果算的话,那和你上面说的属于“数据转换”步骤,是不是矛盾呢?我有点糊涂了,请帮我解释下,看看我哪里理解不到位
对不起造成混淆,让我来澄清。
实际上,“数据转换”和“数据加载”是数据仓库处理过程中相互联系的两个步骤,它们通常是在数据流动的不同节点交替进行的。
-
当数据写入到ODS层时,它首先会经历一个“数据抽取”过程,从源系统中抽取出来。接着可能会有一些基本的“数据清洗”和“数据转换”,确保数据质量并且符合ODS层的结构,之后进行"数据加载"到ODS层。
-
接下来,数据再经过更多的“数据转换”处理,以构建DWD层的细粒度数据模型,这里可能会涉及更加复杂的清洗、转换、数据模型的调整,以及数据的聚合。
-
完成转换之后,将这些转换后的数据“加载”到DWD层。
-
同样,从DWD层到DWS层也会经历一系列的“数据转换”(如更进一步的数据聚合、维度表的构建等),之后再进行“数据加载”到DWS层,用以支持更快速的查询和报告。
在这整个流程中,每次的“数据加载”都发生在成功完成一系列“数据转换”之后。以此来解决您提出的矛盾:事实上,“数据加载”是多个阶段的集成输出,不仅仅是发生在最终数据落地到数据仓库层面上。在数据仓库分层架构中,任何层次间的数据流动都可以被视作“数据加载”的一部分。希望这能够解释清楚这个过程。
在数仓领域,通常意义上,大家口中说的 ETL,重点是从外部数据源整合加载数据到数据库呢,还是的确就包含了外部到内部、内部反复多次转换的过程?
在数仓领域,ETL(Extract, Transform, Load)这个词汇经常被用来描述整个数据集成过程,不仅仅局限于从外部数据源整合加载数据到数据库这一阶段。它的确包含从不同的外部数据源提取数据(Extract),对数据进行清洗、转换(Transform),以及最终加载到数据仓库的目标系统(Load)这一系列连续的流程。这意味着ETL包括了外部到内部的数据处理,也包括了数据仓库内部在不同层次间的反复多次转换和数据流动的过程。
在多层架构的数据仓库中,数据可能会经过多次ETL过程——从最初的脱机数据提取,到ODS层、DWD层,直至DWS层或DM(Data Mart)层。每个层级间的数据转换和加载都可以被视作一个ETL过程的一部分。因此,当实际应用或讨论ETL的时候,我们不仅仅是在说明从源系统到目标系统的数据迁移,也包括了数据仓库内部反复多次的数据处理和整合的全过程。
谢谢!请帮我总结一下上述多轮对话,明晰 ETL 的概念和过程。
非常乐意为您总结。
ETL(Extract, Transform, Load)是数据仓库领域中的核心概念和过程,涉及从不同的数据源提取(Extract)数据,对数据进行清洗和转换(Transform),最后加载(Load)数据到数据仓库或其他目标系统。ETL不仅包括从外部系统到数据仓库的数据集成,也包括数据仓库内各个层次之间的数据处理。
具体到每个步骤:
Extract(提取):从多个源系统中提取数据,这些系统可能是数据库、文件、API接口等。
Transform(转换):转换步骤负责清洗提取出来的数据,包括数据规范化、去重、数据类型转换、业务规则应用、键值生成等,以确保数据的质量和一致性,同时整合和转换数据以符合数据仓库的结构和需求。
Load(加载):最后一步是将清洗和转换后的数据加载到目的地,可能是数据仓库的某个层次,如ODS层、DWD层、DWS层,或者最终用户可访问的Data Mart层。
ETL涵盖了以下场景:
外部数据整合到ODS层的ETL过程。
从ODS层到DWD、DWS及Data Mart层之间的ETL过程。
在任何层级内部进行的数据转换和加载。
在整个数据仓库的生命周期中,ETL是一个持续的、迭代的过程,为了响应业务需求的变更,保证数据仓库数据的时效性和准确性,ETL可能会不断优化和调整。
metaso 也给出了类似结论:https://metaso.cn/search/8460423656069017600
但是,我还是存在一些疑问,例如,我们会看到下面这样的图:
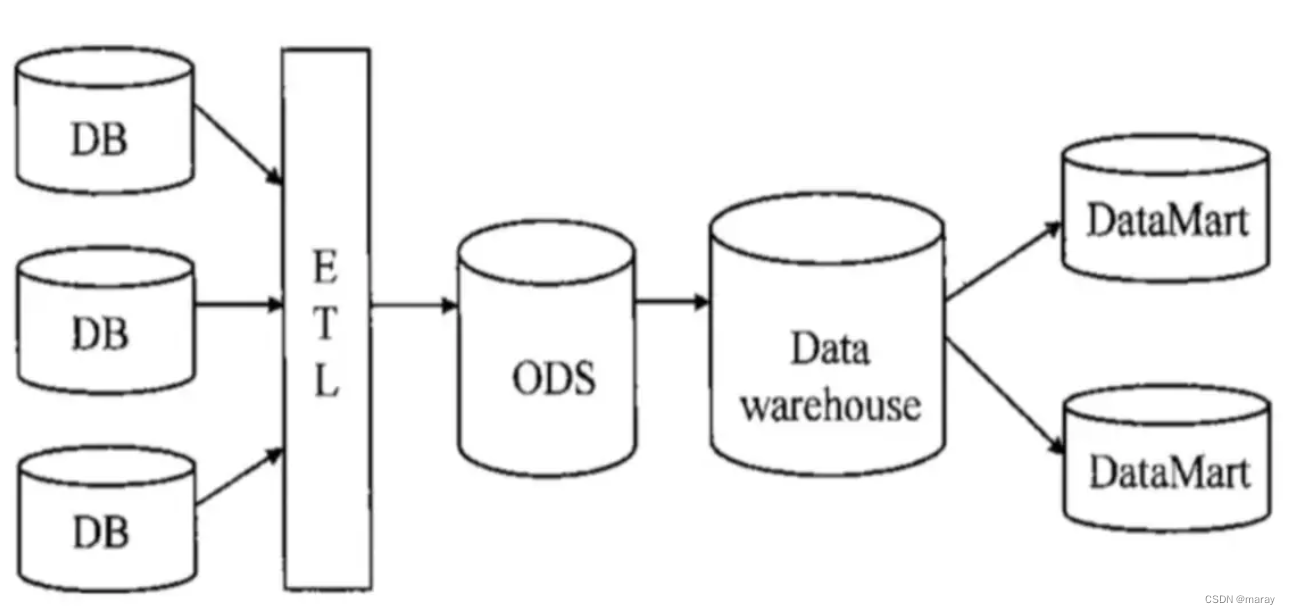
工具集是这样的:
数据抽取工具:
- kafka
- flume
- sync
数据清洗工具:
- hive/tez
- pig/tez
- storm
- spark
数据存储:
- hadoop
- hbase
- ES
- redis
任务管理:
- azkaban
- oozie
可见,关系型数据库在这里面并不是关键。