相关文章
- 【数仓】基本概念、知识普及、核心技术
- 【数仓】数据分层概念以及相关逻辑
- 【数仓】Hadoop软件安装及使用(集群配置)
- 【数仓】Hadoop集群配置常用参数说明
- 【数仓】zookeeper软件安装及集群配置
- 【数仓】kafka软件安装及集群配置
- 【数仓】flume软件安装及配置
- 【数仓】flume常见配置总结,以及示例
- 【数仓】Maxwell软件安装及配置,采集mysql数据
- 【数仓】通过Flume+kafka采集日志数据存储到Hadoop
一、DataX 3.0概览
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
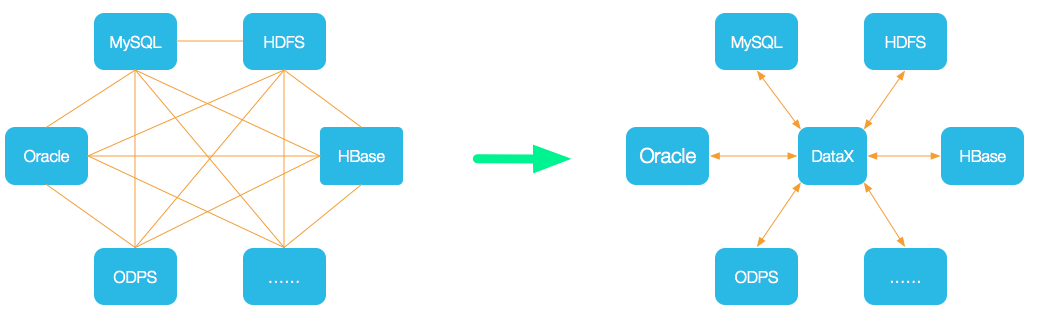
设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
Github主页地址:https://github.com/alibaba/DataX
二、DataX3.0框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

- Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
- Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
- Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
参考官方介绍
三、环境准备
准备1台虚拟机
- Hadoop131:192.168.56.131
本例系统版本 CentOS-7.8,已安装jdk1.8
关闭防火墙
systemctl stop firewalld
四、DataX安装配置
1、DataX下载安装
# 下载解压
wget --no-check-certificate https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202308/datax.tar.gz
tar -xzvf datax.tar.gz
mv datax /data/datax/
2、执行验证脚本
# 进入安装目录
cd /data/datax
# 执行验证脚本
python bin/datax.py job/job.json
执行完成后,大致输出如下结果:
任务启动时刻 : 2024-03-10 00:46:57
任务结束时刻 : 2024-03-10 00:47:07
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0
安装很简单,至此安装成功!
五、示例,从mysql同步到hdfs
1、编写job文件
输入以下命令,会生成模板文件,然后再修改
python bin/datax.py -r mysqlreader -w hdfswriter
创建文件 job/mysql2hdfs02.json,详细内容如下:
该配置文件定义了从一个 MySQL 数据库读取数据,并将这些数据写入到 HDFS 的过程。
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name","msg","create_time","status","last_login_time"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://192.168.56.1:3306/user?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai"],
"table": ["t_user"]
}
],
"password": "password",
"username": "test",
"where": "id>3"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":"id","type":"bigint"},
{"name":"name","type":"string"},
{"name":"msg","type":"string"},
{"name":"create_time","type":"date"},
{"name":"status","type":"string"},
{"name":"last_login_time","type":"date"}
],
"compress": "gzip",
"defaultFS": "hdfs://hadoop131:9000",
"fieldDelimiter": "\t",
"fileName": "mysql2hdfs01",
"fileType": "text",
"path": "/mysql2hdfs",
"writeMode": "append"
}
}
}
],
"setting": {
"speed": {
"channel": "1"
}
}
}
}
2、执行任务
python bin/datax.py job/mysql2hdfs02.json
执行结果如下:
任务启动时刻 : 2024-03-10 02:30:46
任务结束时刻 : 2024-03-10 02:30:57
任务总计耗时 : 11s
任务平均流量 : 12B/s
记录写入速度 : 0rec/s
读出记录总数 : 4
读写失败总数 : 0
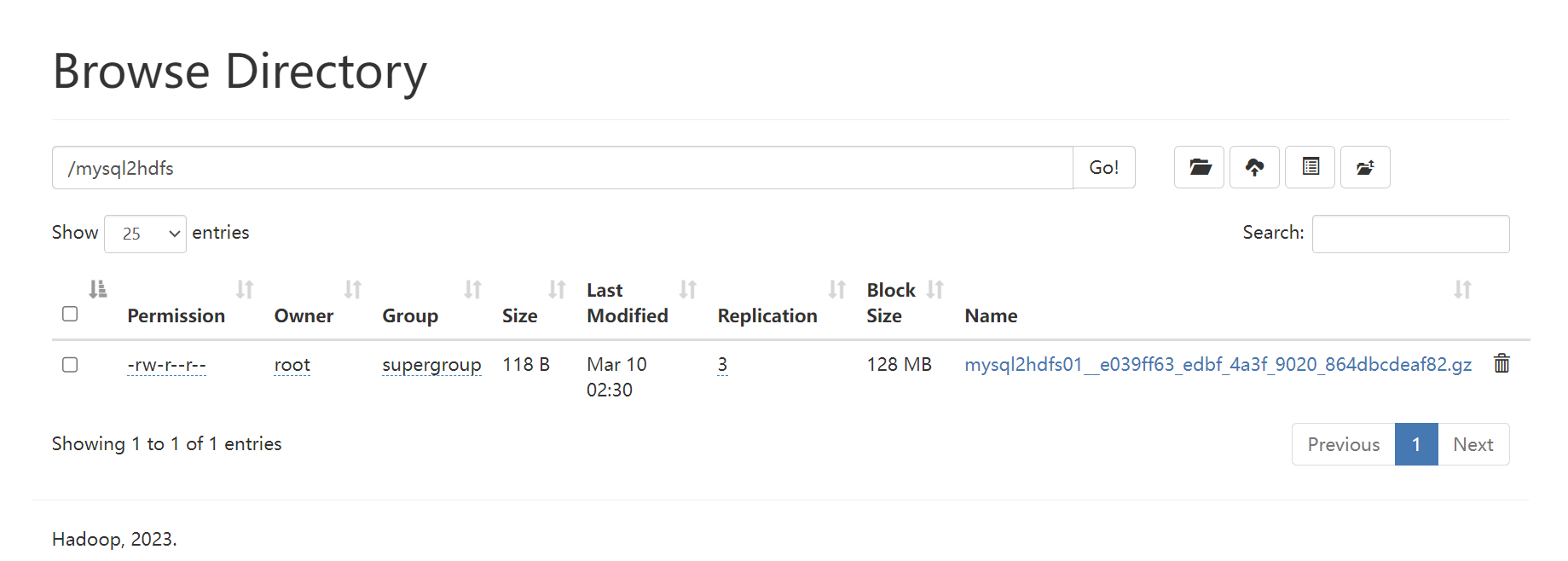
3、打开Hadoop查看,数据已经成功同步
参考
- https://github.com/alibaba/DataX/blob/master/userGuid.md