4. gin框架源码–Engine引擎和压缩前缀树的建立
讲了这么多 到标题4才开始介绍源码,主要原因还是想先在头脑中构建起 一个大体的框架 然后再填肉 这样不容易得脑血栓。标题四主要涉及标题2.3的步骤一
也就是 标题2.3中的 粗线框中的内容
4.1 Engine 引擎的建立
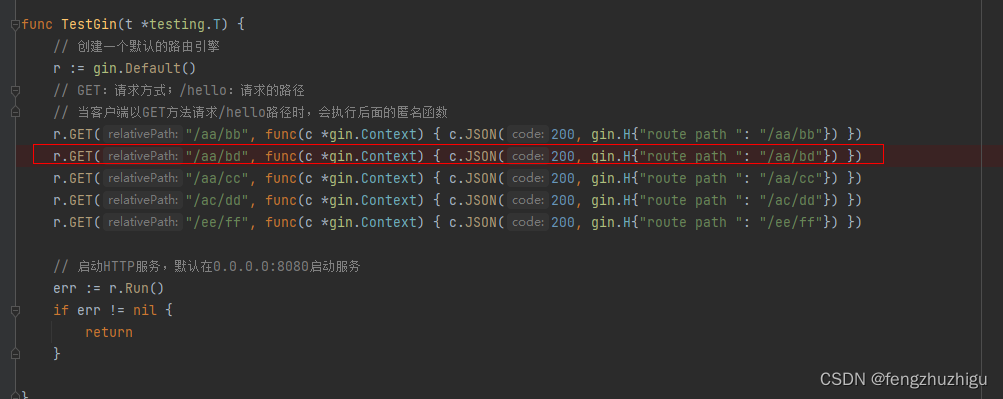
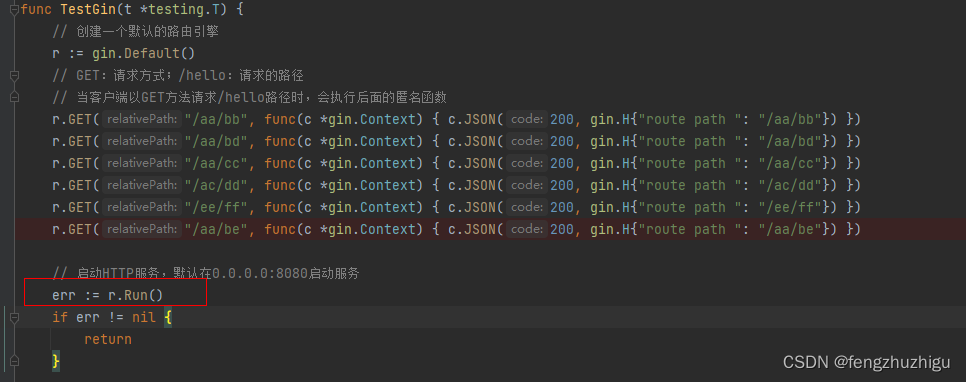
见 TestGin的第 一行 我们按图索骥 一步步深入看看 只需关注 我中文注释的属性或代码就行
r := gin.Default() // 建立一个默认的 gin 引擎实例
其中函数 Default() 代码 如下:
// Default returns an Engine instance with the Logger and Recovery middleware already attached.
func Default() *Engine {
debugPrintWARNINGDefault() // 打印 警告信息
engine := New() // 建立 engine 实例
engine.Use(Logger(), Recovery()) // 添加中间件 函数 包括 日志和panic恢复函数
return engine
}
其中 New()函数 代码如下(只关注我中文解释的参数就行):
// New 返回一个不带任何中间件函数的新的engine实例
func New() *Engine {
debugPrintWARNINGNew()
engine := &Engine{
RouterGroup: RouterGroup{ // 建立默认根路由组 也就是说 所有的 路由 都需要经过本 在前面加上 “/” 后续路由(使用Group(...)函数创建) 会在其基础上 不断叠加更新 basePath和Handlers 但其功能还是一样的
Handlers: nil,
basePath: "/",
root: true,
},
FuncMap: template.FuncMap{},
RedirectTrailingSlash: true,
RedirectFixedPath: false,
HandleMethodNotAllowed: false,
ForwardedByClientIP: true,
RemoteIPHeaders: []string{"X-Forwarded-For", "X-Real-IP"},
TrustedPlatform: defaultPlatform,
UseRawPath: false,
RemoveExtraSlash: false,
UnescapePathValues: true,
MaxMultipartMemory: defaultMultipartMemory
trees: make(methodTrees, 0, 9), // 初始化 方法树的 列表 包括 Get/Post/Delete等九中方法
delims: render.Delims{Left: "{{", Right: "}}"},
secureJSONPrefix: "while(1);",
trustedProxies: []string{"0.0.0.0/0", "::/0"},
trustedCIDRs: defaultTrustedCIDRs,
}
engine.RouterGroup.engine = engine // 将新建的 本 engine 索引付给 engine.RouterGroup.engine 方便 路由组引用 本engine的 addRoute()方法
engine.pool.New = func() any { // 初始化context池 因为涉及到大量客户端连接,所以将context池化 减少对象的创建和回收次数 可以节省内存 减少垃圾回收时间 提高效率
return engine.allocateContext(engine.maxParams)
}
return engine
}
其中 engine.Use(Logger(), Recovery()) 中 Use()函数 如下
func (engine *Engine) Use(middleware ...HandlerFunc) IRoutes {
engine.RouterGroup.Use(middleware...) // 将中间件函数 加入到 RouterGroup的参数 Handlers 列表中 作为本路由组的整体的中间函数
engine.rebuild404Handlers()
engine.rebuild405Handlers()
return engine
}
到这里 r := gin.Default() 这行代码就讲解完毕了 比较粗略 因为这部分源码不太难 主要是 完成了两件事
1: 创建了一个默认路由组,主要来存放根 路径 “/” 和 全局中间函数 包括 对日志和panic的处理
2: 初始化了一个 methodTrees 结构体 用来 保存 get/post等9种方法树的根节点 还有其他初始参数 跟本文讲解的内容关系不大 不做讲解 感兴趣的可以自己谷歌上百度两下。
到这里 默认引擎就建立起来了 。
4.2 GET方法 路由节点树的逐步建立
4.2.1 树初始化 和 第一个路由节点的建立
见 TestGin的第 二行,代码如下
r.GET("/aa/bb", func(c *gin.Context) { c.JSON(200, gin.H{"route path ": "/aa/bb"}) })
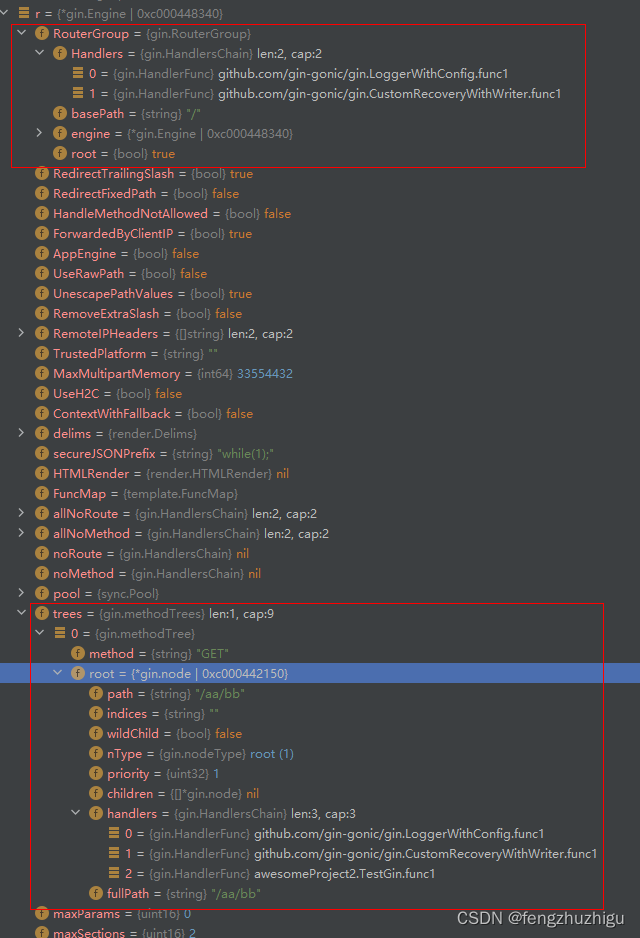
第一次建立路由树时,树是空的,所以需要经过判断建立根节点和直接将路由和函数 挂到树上。
树建立后的结构如下(handler也就是 注册的函数 在路径插入时插入,故不在图中展示,只在有特殊情况时说明。):

知道了结果,现在我们来梳理下代码:
从 r.Get 追踪下来 可见如图代码
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath) // 组的根路径(/)+用户路径(/aa/bb)
handlers = group.combineHandlers(handlers) // 组的根方法组(日志相关+panic相关)+用户注册方法(c.Json......)
group.engine.addRoute(httpMethod, absolutePath, handlers) // 构造路由树核心函数 将 absolutePath 和 handler 添加到 httpMathod 方法(Get)对应的 路由树上
return group.returnObj() // 没看懂 不过不影响 哦 不对 主逻辑 ps: 不是能力不行 写这篇代码时 有点困 没深究呢
}
接着追踪 group.engine.addRoute(httpMethod, absolutePath, handlers)
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
// 隐藏无关代码
root := engine.trees.get(method)
if root == nil { // 第一次 建立路由 会走这里 主要是 初始化 路由树的 根节点,将根节点挂载到 engine的 trees 列表中
root = new(node)
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers) // 构造路由树核心函数,将 路径(/aa/b) 和 方法(3个) 添加到路由树上 根节点是(root)
// 隐藏无关代码
}
接着追踪 root.addRoute(path, handlers)
func (n *node) addRoute(path string, handlers HandlersChain) {
fullPath := path
n.priority++ // priority 可以理解 以n为根节点的孩子节点的总个数 主要作用是 用来对 其第一层孩子节点进行重排,按照值大小倒序排列。为什么这么做呢,因为孩子节点多,说明通过这个节点的路由就多 访问就越频繁 在for循环寻找路由时 排在前面的经常被访问的节点 可以快速找到 从而可以提高效率。后续会讲解 如果有疑惑 先放着
// Empty tree
if len(n.path) == 0 && len(n.children) == 0 { // n 是上面代码中的 root ,可以看到 只有 fullPath有值,path和children都是 零值(其含义见3.3),
n.insertChild(path, fullPath, handlers) // 为root根节点补充完整参数。因为其没有孩子节点 path也为空 则可以判断是空树 所以 root节点就是第一个节点 只需补充完整其参数就行
n.nType = root
return
}
parentFullPathIndex := 0
// 以下代码是 gin框架构造路由树核心,只是初始构造路由树用不到,先排除干扰
}
接着追踪 n.insertChild(path, fullPath, handlers)
func (n *node) insertChild(path string, fullPath string, handlers HandlersChain) {
for {
// Find prefix until first wildcard
wildcard, i, valid := findWildcard(path) // 寻找通配符 本文暂时只介绍 gin框架 精髓 无通配符路由节点建立
if i < 0 { // No wildcard found //i==-1 break
break
}
// 隐藏无关代码
}
// If no wildcard was found, simply insert the path and handle 没有通配符 简单的插入 路径和handler
n.path = path // (/aa/bb)
n.handlers = handlers // 3个 (日志相关+panic相关)+用户注册方法(c.Json......)
n.fullPath = fullPath // (/aa/bb)
}
至此 第一个 节点便建立起来了,TestGin的第 二行执行完毕后,其engine结构如下图,可以看到root节点确实如分析的一般。
4.2.2 第2个路由路径插入
代码 如图
这行代码执行完毕后得到的树如图:
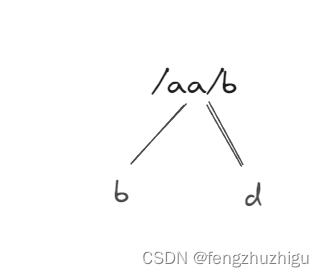
下面我们来具体分析下代码
通过代码追踪 可以看到 第二个节点建立时 跳过了 root节点初始化和 第一个节点建立的代码,来到了 addRoute函数的核心部分
接着追踪 root.addRoute(path, handlers)
func (n *node) addRoute(path string, handlers HandlersChain) {
fullPath := path
n.priority++
// 隐藏无关代码
parentFullPathIndex := 0
walk:
for {
// Find the longest common prefix.
// This also implies that the common prefix contains no ':' or '*'
// since the existing key can't contain those chars.
i := longestCommonPrefix(path, n.path) // n是4.2.1形成的第一个节点 则 n.path =/aa/bb path==/aa/bd longestCommonPrefix 函数是寻找两个字符串第一个不相同的字符的 索引 这里可以算出来 是 5。
// 这个函数的作用决定父节点是否需要被拆分, 当n.path是path的子节点时 不被拆分,否则就需要被拆分。
// Split edge
if i < len(n.path) { // 5<6 走这里 ,拆分父节点为两部分 /aa/b(根节点) 和 b(第一个孩子节点) ,下面具体讲解
child := node{ // b 孩子节点的创建
path: n.path[i:], // 将 b赋值给 path
wildChild: n.wildChild,
nType: static,
indices: n.indices, // child继承了 n的主要参数和功能
children: n.children, // 将其孩子节点赋值给 其 分裂的前缀节点
handlers: n.handlers,
priority: n.priority - 1, // 没看懂
fullPath: n.fullPath, // 全路径不变 还是/aa/bb
}
n.children = []*node{&child} // 初始化n节点,并且将 child加入到n的孩子节点中,这样 就形成了 n-->n.children-->n.children.children这样三层节点结构
// []byte for proper unicode char conversion, see #65
n.indices = bytesconv.BytesToString([]byte{n.path[i]}) // 下面是 重新给n的属性赋值
n.path = path[:i]
n.handlers = nil
n.wildChild = false
n.fullPath = fullPath[:parentFullPathIndex+i]
}
// Make new node a child of this node // 将n 的第二个节点d插入进去
if i < len(path) { // 5<6 将 新节点 d插入进去
path = path[i:] //新节点的 path参数是是 d
c := path[0] // 获取path第一个 字符,用于快速定位应该从哪一个节点向下匹配。
// '/' after param
// todo 没看懂
if n.nType == param && c == '/' && len(n.children) == 1 {
// 隐藏无关代码
}
// Otherwise insert it
if c != ':' && c != '*' && n.nType != catchAll {
// []byte for proper unicode char conversion, see #65
n.indices += bytesconv.BytesToString([]byte{c}) // 将 n的新孩子节点前缀字符加入到 indices 中
child := &node{
fullPath: fullPath,
}
n.addChild(child) // 将孩子节点添加到 n的孩子节点数组中
n.incrementChildPrio(len(n.indices) - 1) // 这里比较重要 用到了我们所说的 priority, 按照 其值 大小进行子节点倒序排序。原因前文讲过了,请自行查看。
n = child // 将 child地址 赋值给 n。
} else if n.wildChild {
// 这里是对通配符的处理,本文暂不涉及,略过。
}
n.insertChild(path, fullPath, handlers) // 完善n(child)的 path,fullPath,handlers ,insertChild函数其实就是给节点n的几个属性赋值,所以感觉起得名字有点误导。
return // 返回 到这里 第二个节点就创建好了
}
// Otherwise add handle to current node
if n.handlers != nil {
panic("handlers are already registered for path '" + fullPath + "'")
} // 如果i>=len(path) 就可能是情况 n.path==/aa/bb path==/aa/b 。则分类后 一共 两个节点 没有 d节点。 则需要将 handler和fullPath 赋值当前n节点。
n.handlers = handlers
n.fullPath = fullPath
return 返回
}
}
到这里第二个路由节点就插入进去了。
我们看下 debugger的结果
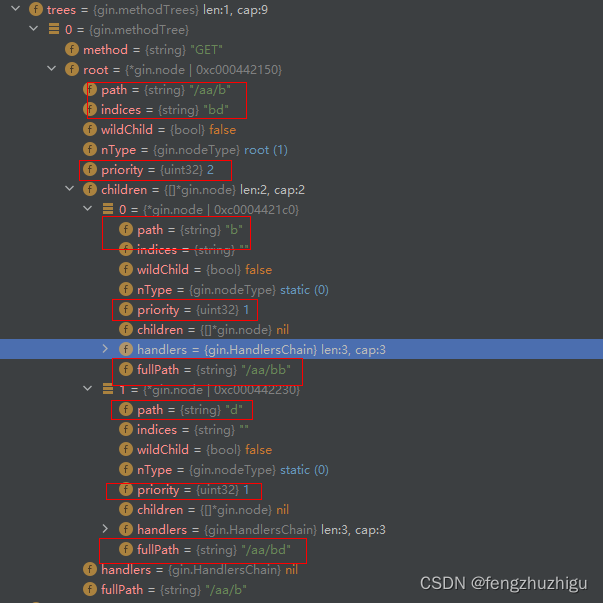
可以看到跟我们分析的是一致的。
4.2.3 第3-5个路由路径的插入
由于其 执行的动作跟 4.2.2一致,所以略过。其构建树的过程如下图
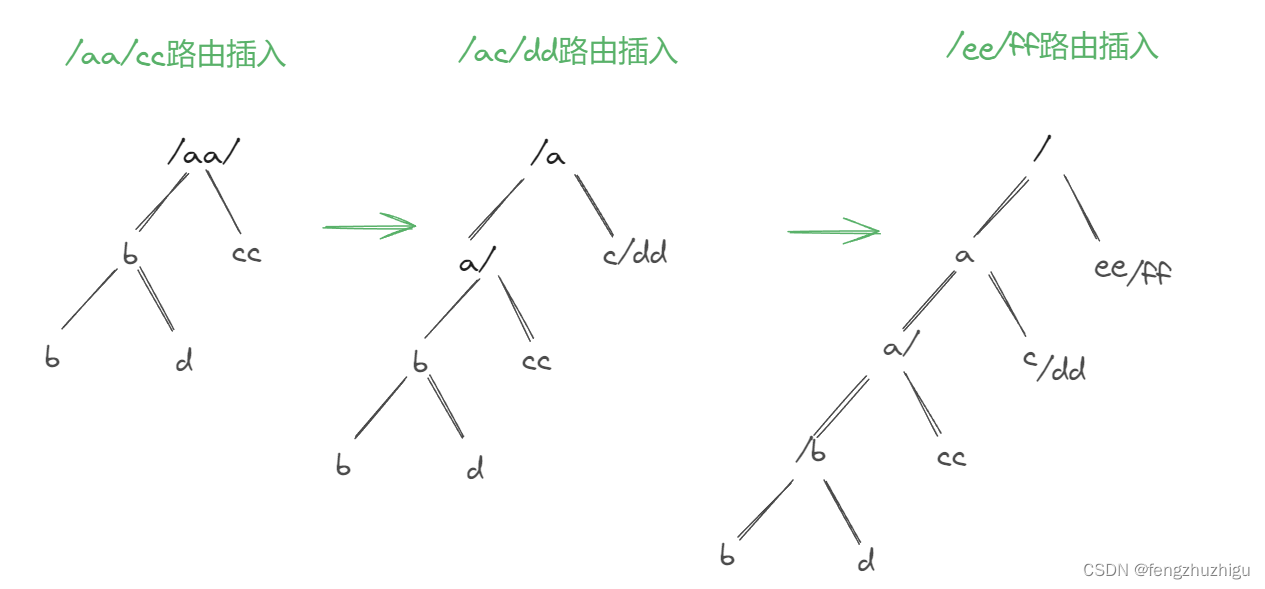
4.2.4 第6个路由的插入
4.2.1–4.2.3是正常路由的插入,一次循环就能完成。没有涉及到 addRoute() 函数的关键字 walk: 接下来 我们再引入一个路由 来触发 for 循环,添加的路由如下图

这行代码执行完毕后得到的树如图:
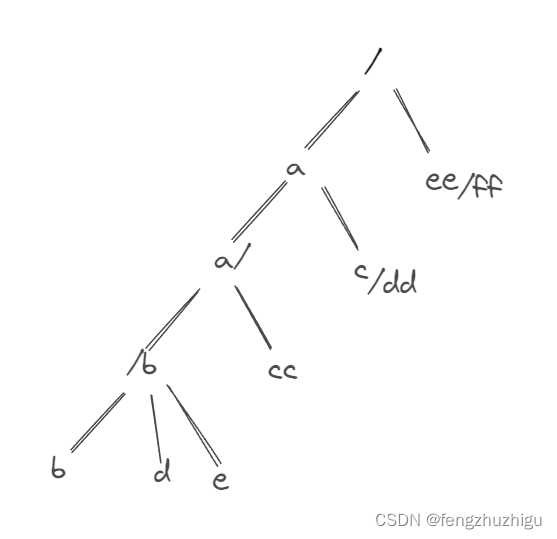
下面 我们来分析下具体的代码执行 还是直接 分析 root.addRoute(path, handlers)
第1层循环
func (n *node) addRoute(path string, handlers HandlersChain) {
fullPath := path
n.priority++
// Empty tree
// 隐藏无关代码
parentFullPathIndex := 0
// 循环第一层 沿着 树节点 向下找 则n节点 是4.2.3最右边的图 以下 n的参数都可以参考这个图来获取
walk:
for {
// Find the longest common prefix.
// This also implies that the common prefix contains no ':' or '*'
// since the existing key can't contain those chars.
i := longestCommonPrefix(path, n.path) // n.path == "/" path=="/aa/be" 如此i==1
// Split edge
if i < len(n.path) { // 不符合 跳过
// 隐藏无关代码
}
// Make new node a child of this node
if i < len(path) { // 符合
path = path[i:] // 获取 除了根节点(“/”)的 剩余部分 aa/be
c := path[0] // 将 aa/be 的 第一个字符 a 提取出来 为了 快速在 n的孩子节点定位和将c插入n的 indices中(如果没有匹配n的子节点)
// '/' after param
if n.nType == param && c == '/' && len(n.children) == 1 {
// 隐藏无关代码
}
// Check if a child with the next path byte exists
for i, max := 0, len(n.indices); i < max; i++ { // n.indices=={a,e}
if c == n.indices[i] { // 因为c==rune("a") 所以 走下面代码
parentFullPathIndex += len(n.path) // 下一个循环 中 节点的 fullPath在 全局全路径 中出现的索引。
i = n.incrementChildPrio(i) // 因为接下来的 新节点 要加入到 包含 n.children[i]节点的后续子节点中 所以其 孩子几点数(priority) 要增1,然后返回排序后的 原始的n.children[i]节点的新的索引 给 i
n = n.children[i] // 将孩子节点赋值给 n
continue walk // 从 新节点开始继续循环 见 4.2.3最右边节点的第2层最左边节点
}
}
// 隐藏无关代码
}
}
第2-3层循环跟上面代码 原理相同 可参考 4.2.3最右边节点的第2-3层
第4层循环时 n.path==“b” path==“be”
其 执行逻辑可以按照 4.2.3执行 请自行验证
至此 树节点的建立就梳理完毕了,注意只是梳理了不带通配符的路由处理逻辑,关于通配符 例如 :* 等特殊字符请自行梳理。
梳理了这么多知识点 都是属于 1.3 的圆圈1,下面我们改建立起tcp监听了。
5. net/http框架源码-- 多路复用的实现
这块核心功能对应 1.3 的圆圈2,所属代码如下图:
未完待续…
6. gin框架源码–路由匹配(压缩前缀树的查找)
7. 收尾
ps: 本人菜鸟 不太专业 如果有错还请各位大侠指出;免责声明:凡是按照本八股文去面试被怼的,本人概不承担责任;面试通过,请自行心理默念几遍博主最帅。
参考文章
https://juejin.cn/post/7263826380889915453




![YOLOv9代码解读[01] readme解读](https://img-blog.csdnimg.cn/direct/63ab14e4139c44c998d0376036c52be7.png)