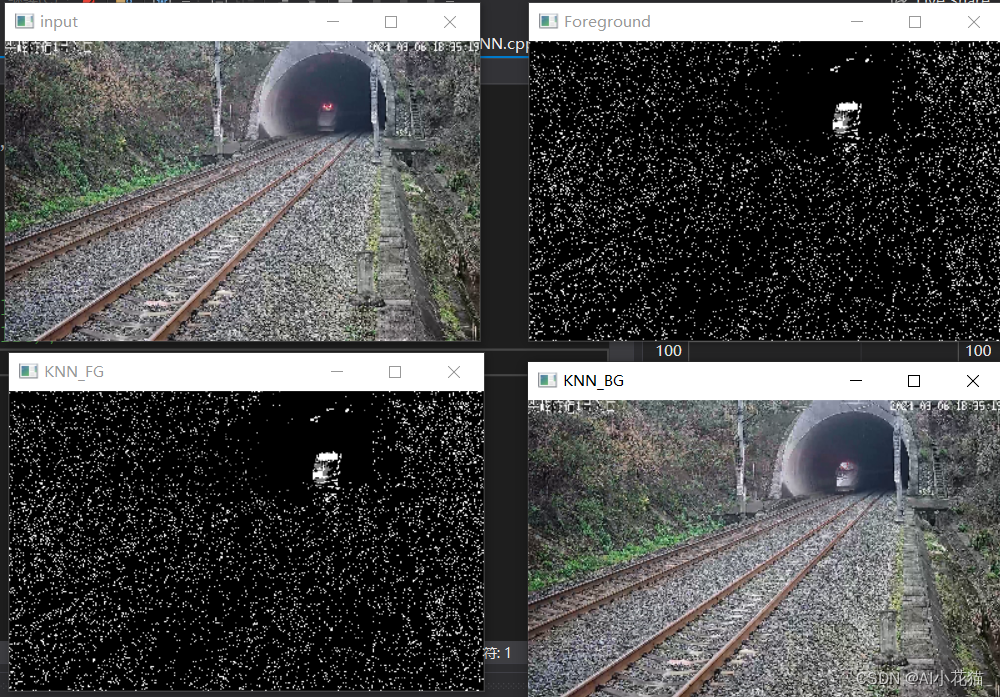
分布式锁的使用场景
-
资源竞争控制:多个客户端同时访问共享资源时,可以使用分布式锁来控制资源的并发访问,防止多个客户端同时对同一资源进行修改造成数据不一致的问题。
-
避免重复操作:在分布式环境中,可能会出现多个客户端同时执行某个操作,为了避免重复执行某个操作,可以使用分布式锁来确保只有一个客户端能够执行操作,其他客户端需要等待。
-
限流控制:可以使用分布式锁来限制某个操作的并发执行数量,从而避免系统过载或资源耗尽的情况。
抢券场景
/**
* 抢购优惠券
* @throws InterruptedException
*/
public void rushToPurchase() throws InterruptedException {
//获取优惠券数量
Integer num = (Integer) redisTemplate.opsForValue().get(“num”);
//判断是否抢完
if (null == num || num <= 0) {
throw new RuntimeException(“优惠券已抢完");
}
//优惠券数量减一,说明抢到了优惠券
num = num - 1;
//重新设置优惠券的数量
redisTemplate.opsForValue().set("num", num);
}

正常的执行情况:
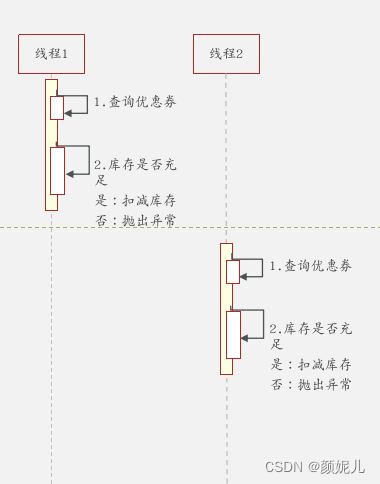
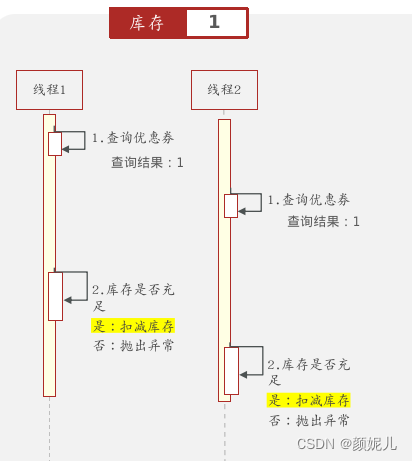
由于线程可以是交替执行的,所以可能出现以下情况——导致超出库存数量:
使用synchronized(属于JVM的本地锁)对资源进行加锁:
public void rushToPurchase() throws InterruptedException {
synchronized (this) {
//查询优惠券数量
Integer num = (Integer) redisTemplate.opsForValue().get("num");
//判断是否抢完
if (null == num || num <= 0) {
throw new RuntimeException("商品已抢完");
}
//优惠券数量减一(减库存)
num = num - 1;
//重新设置优惠券的数量
redisTemplate.opsForValue().set("num", num);
}
}
针对单体项目,并且只启动了一台服务,则该方式是有效的,运行过程如下图所示:
但是在实际项目中,为了支持并发请求,会把服务做成集群部署——同一份代码部署在多台服务器上,如图:
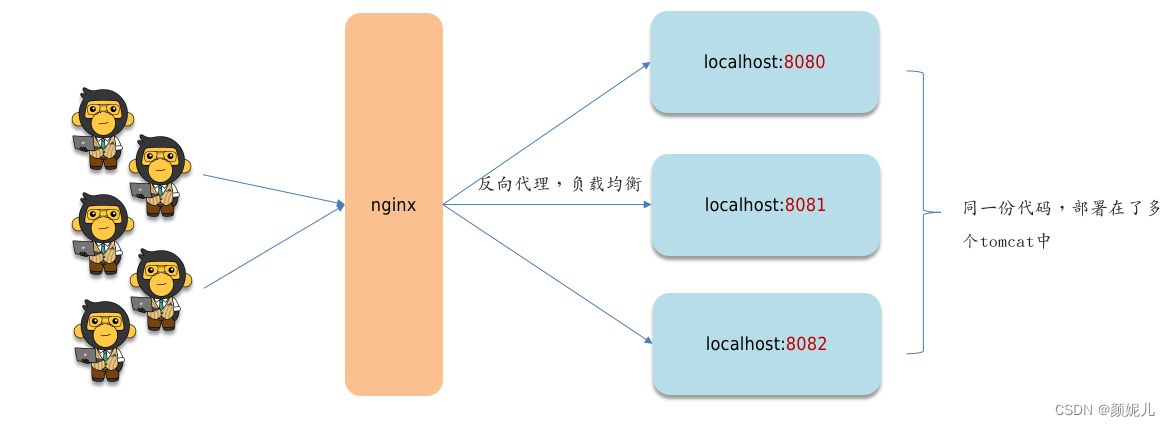
因此,可能会出现如下情况:
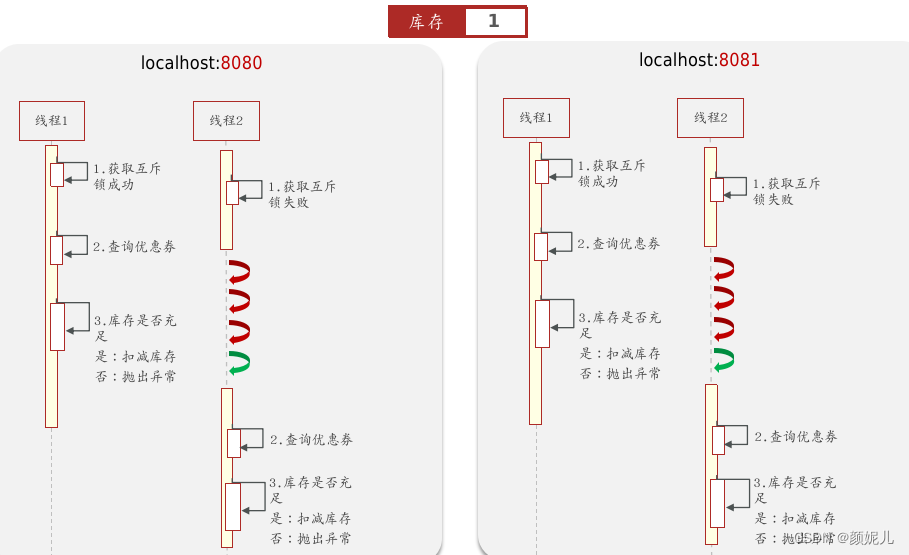
出现以上情况,是因为我们添加的synchronized,属于JAM的本地锁,每个服务器都有各自的JVM,它只能解决同一个JVM下的线程互斥。
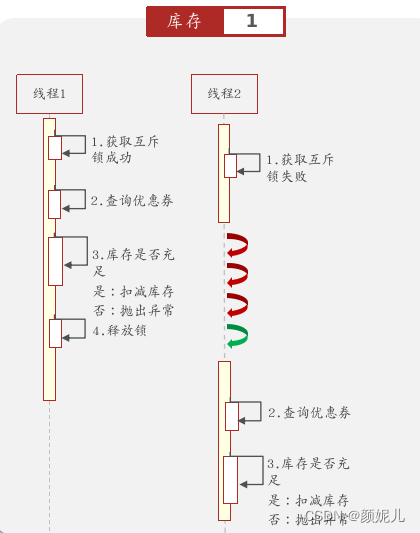
采用分布式锁:
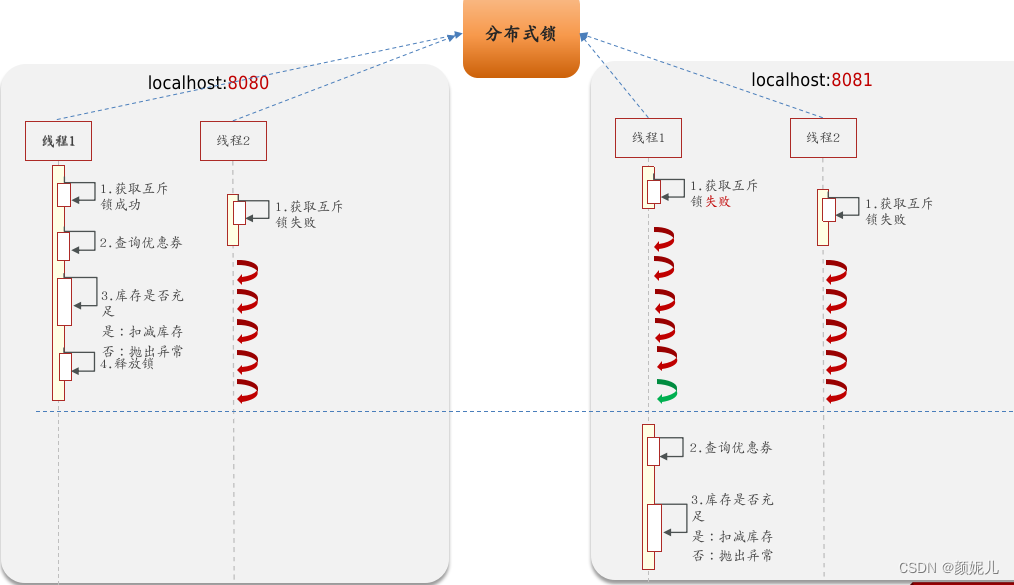
上图的流程为:首先,8080的线程1尝试获取分布锁,获取锁后,分布式锁中会添加记录“线程1”,证明该线程已经持有锁了,随后执行自己的业务代码;若8081的线程1想要获取分布式锁,此时就会失败,会进入阻塞状态;当8080的线程1执行结束后,8081的线程1才能获取分布式锁,然后执行自己的业务逻辑。
Redis分布式锁
Redis实现分布式锁主要利用Redis的setnx命令。setnx是SET if not exists(如果不存在,则 SET)的简写。
- 获取锁
# 添加锁 # lock表示锁(key)的名称 # value表示key的值 # NX是互斥 # EX是设置超时时间 # 注意:可以用两条语句分别设置NX和EX(两条命令不能保证原子性);但写在一条命令中执行,可以保证原子性 # 若不设置过期时间,可能会出现死锁问题,分析如下图所示。 SET lock value NX EX 10 - 释放锁
# 释放锁,删除即可 DEL key
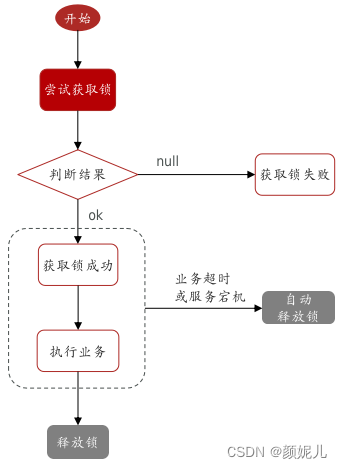
上图中,某一个成功获取锁之后,在执行代码的过程中发生了业务超时或服务宕机,若未设置过期时间,则分布式锁就无法被释放,其他进程就一直不能获取到资源,发生死锁现象。
由上引申出——Redis实现分布式锁如何合理的控制锁的有效时长?(即,出现到达设置的超时时间时,业务还没执行结束)
答:根据业务执行时间预估(但是该方式不太靠谱,万一出现抖动或网络卡顿,都会导致执行时间变慢,这个时间是不好控制的)或 采取给锁续期(创建一个新的线程用于监控,若业务执行时间较长时,就增加这个当前业务线程持有锁的时长——通过redisson实现)。
redisson实现的分布式锁——执行流程
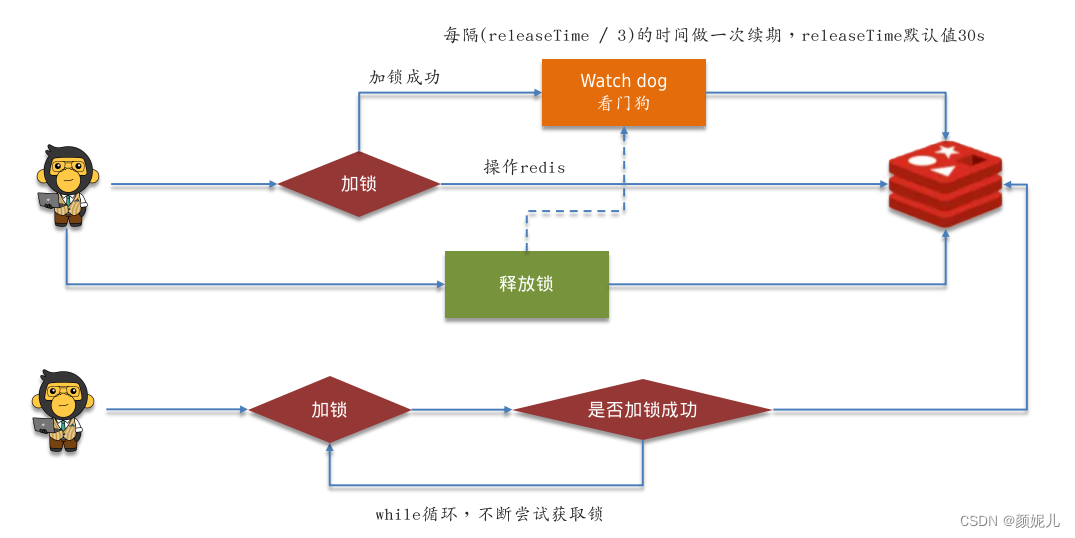
redisson的使用代码:

注意:若设置了第2个参数——当前锁自动释放时间,就不会有watch dog的监听了,因为redission任务如果能够控制锁的失效时间,就没有做续期的必要了;若设置为-1或不设置值,才有监听。
lua脚本的最大作用——能够调用redisson命令来保证多条命令执行的原子性。
redisson实现的分布式锁——可重入
可重入: 指的是可以允许同一个线程多次获取同一个锁而不会造成死锁的情况。
public void add1() {
RLock lock = redissonClient.getLock("templock");
boolean isLock = lock.tryLock();
//执行业务
add2();
//释放锁
lock.unlock();
}
public void add2() {
RLock lock = redissonClient.getLock("templock");
boolean isLock = lock.tryLock();
//执行业务
// 释放锁
lock.unlock();
}
根据上述代码执行的情况,若add2()中的锁获取成功,则说明该锁是可重入的;若未获取成功,则说明该锁是不可重入的。
redisson实现的分布式锁是可重入的,它是根据线程ID来进行判断的。
可重入分布式锁的实现方式一般是通过在锁的持有信息中记录当前线程的标识以及获取锁的次数。当同一个线程再次获取锁时,会增加锁的获取次数,而释放锁时则会递减锁的获取次数。只有当锁的获取次数减到零时,锁才会被完全释放。因此,当上述代码中,当add2()获取锁时(获取成功后,还未释放),redisson利用hash结构来记录锁的使用情况如下:

可重入的好处:
-
避免死锁:如果一个线程已经持有了锁,再次获取同一把锁时不会被阻塞,这样可以避免因为锁的重复获取而造成死锁的情况。
-
简化代码逻辑:在需要多层嵌套调用的情况下,使用可重入锁可以避免由于嵌套调用而引入额外的锁管理逻辑。线程只需要在最外层获取锁,在需要获取锁的内部方法中可以直接调用锁的方法,而不需要额外考虑锁的释放和获取。
-
提高灵活性:可重入锁允许同一个线程在持有锁的情况下多次获取锁,这意味着线程可以更加灵活地管理锁的获取和释放,从而更好地适应复杂的业务逻辑。
-
减少资源竞争:在一些需要频繁获取锁的场景下,可重入锁可以减少因为频繁获取锁而造成的资源竞争,从而提高系统的性能和吞吐量。
redisson实现的分布式锁-主从一致性:
主从集群架构是一种常见的分布式架构模式,通常用于构建高可用性和容错性的系统。在主从集群架构中,系统由一个主节点和多个从节点组成,主节点负责处理客户端的读写请求,而从节点则负责复制主节点的数据,以提供数据备份和故障恢复能力。主节点主要负责写操作,如增、删、改;从节点主要负责对外的读操作。当主节点的数据发生改变之后,就会把数据同步给从节点。
注意的是:redisson锁不能解决数据主从一致的问题。
主从不一致的情况:下图中,Java应用创建了一个分布式锁,把数据写入主节点中,然后由主节点同步数据到各个从节点:

当主节点在写入数据后,此时新的数据并未同步到从节点中,若此时主节点发生了宕机,就会在从结点中选择一个结点作为新的主节点,如下图所示:
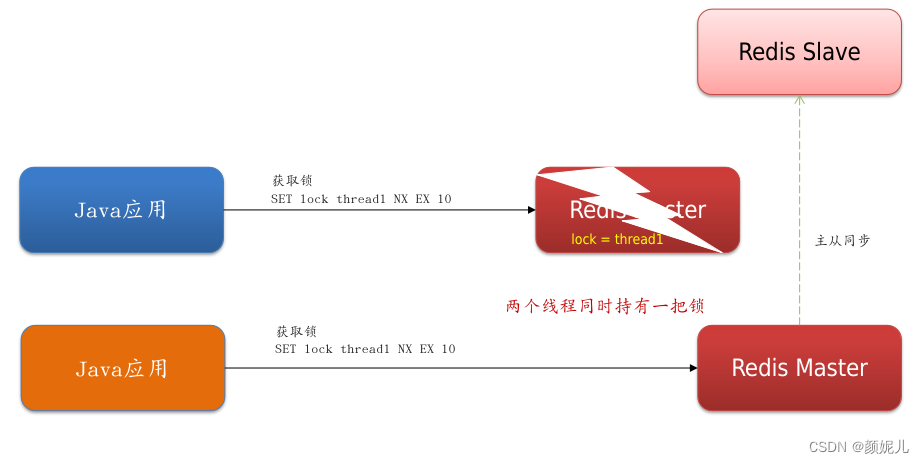
此时,若又有一个新的应用获取到分布式锁,则出现了两个线程同时持有同一把锁的情况,丧失了锁的互斥性,有可能出现脏数据的现象。
为了避免以上情况,采用RedLock算法来保证主从一致性。RedLock 算法的核心思想是通过在多个 Redis 节点上获取分布式锁,并确保大多数节点都成功获取锁才认为锁获取成功,如图所示:
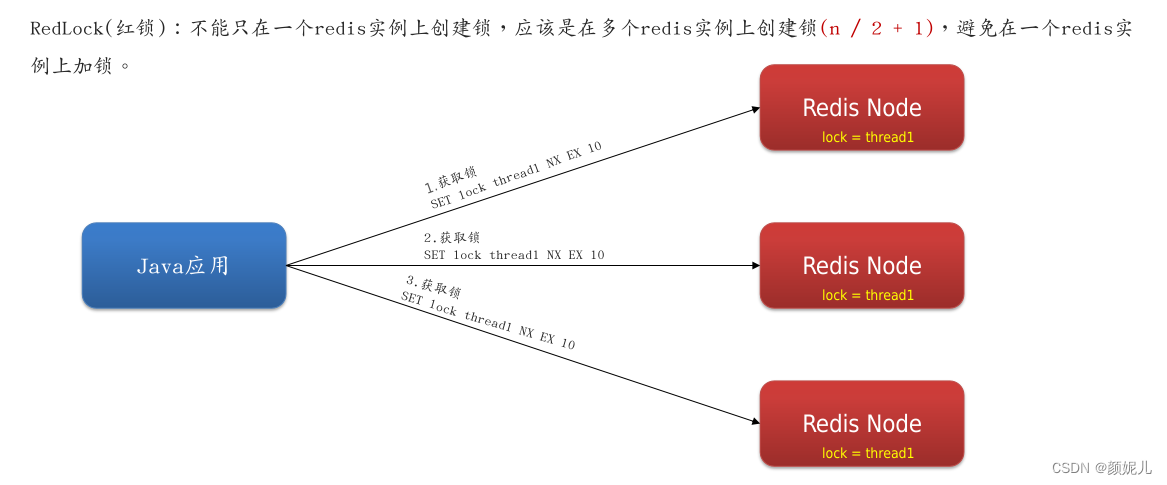
但在实际应用中,并不怎么采取RedLock方式(并且官方也不建议直接使用RedLock来解决主从一致的问题),因为需要提供多个独立redis实例,导致在高并发业务中性能很差,并且实现负责、运维繁琐。
Redis的AP思想——保证高可用性;zookeeper的CP思想——保证数据的强一致性。