c语言中的小小白-CSDN博客c语言中的小小白关注算法,c++,c语言,贪心算法,链表,mysql,动态规划,后端,线性回归,数据结构,排序算法领域.https://blog.csdn.net/bhbcdxb123?spm=1001.2014.3001.5343

给大家分享一句我很喜欢我话:
知不足而奋进,望远山而前行!!!
铁铁们,成功的路上必然是孤独且艰难的,但是我们不可以放弃,远山就在前方,但我们能力仍然不足,所有我们更要奋进前行!!!
今天我们更新了编译和链接内容,
🎉 欢迎大家关注🔍点赞👍收藏⭐️留言📝
前言:
在日常的应用程序开发过程中,我们很少需要关注软件的编译和连接过程,特别是对于常用的集成开发环境visual studio,它将编译和链接的过程封装起来,一步完成,称为“构建”。
但是在这样的开发过程中,我们往往依赖于集成开发环境的强大,而忽略了软件的运行机制和机理,导致对程序中的很多莫名其妙的错误无从下手,程序运行时的性能瓶颈分析也让我们束手无策,如果我们能够深入了解软件运行背后的机理以及支撑软件运行的各种平台和工具,那么解决这些问题相对来说就比较容易了。接下来让我们一起了解软件编译与链接的过程。
一、预处理
预处理过程主要处理那些源代码文件中的以“#”开始的预编译指令。比如”#include”,”#define”等,主要处理规则如下:
(1)将所有的”#define”删除,并且展开所有的宏定义。因为宏定义是直接展开的,所以我们在定义运算符相关宏时,切记要带上括号,避免导致歧义。
(2)处理所有的条件预编译指令,比如“#if“,”#ifdef“,”#elif”,“#else”,”#endif”
(3)处理“#include”预编译指令,将被包含的文件插入到该预编译指令的位置,注意:这个过程时递归进行的,也就是说被包含的文件可能还包含其它文件。当程序项目较大时,由于头文件包含较多,会导致编译速度减慢,此时可以从头文件的包含着手解决,避免包含无用的头文件,以及重复包含问题。
(4)过滤所有的注释“//“和”/**/“中的内容
(5)添加行号和文件名标识,比如#2“hello.c“ 2,以便于编译时编译器产生调试用的行号信息,及用于编译时产生的编译错误和编译警告时显示行号。
(6)保留所有的#pragma编译指令,程序编译时编译器需要使用到。
(7)处理预定义宏,在不同的编译器中,会有一些常用的预定义宏,比如__FILE__,__FUNCTION__,__LINE__。
(8)预处理不做任何语法检查,不仅是因为它不具备语法检查功能,也因
为预处理命令不属于 C/C++ 语句(这也是定义宏时不要加分号的原因),语法
检查是编译器要做的事情。
通过以下命令可以对源文件进行预编译操作,编译后的文件扩展名是.ii。
二、编译
编译过程就是把与预处理完的文件进行一系列词法分析,语法分析,语义分析及优化后生成相应的汇编代码文件。可以通过以下命令进行编译(注意大写S):
gcc –S hello.i –o hello.s
经过编译后的.s文件中是汇编代码,可以直接打开查看其内容:
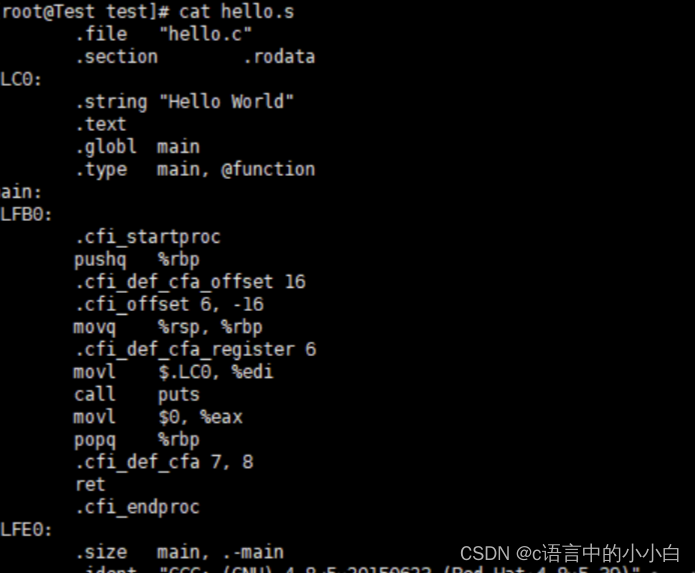
究竟编译器做了什么?从最直观的角度来讲,编译器就是将高级语言翻译成机器语言的一个工具。比如用C/C++语言写的一个程序,可以通过编译器将其翻译成计算机可以执行的指令以及数据,编译的过程一般分为六步:扫描(词法分析),语法分析,语义分析,源代码优化,代码生成和目标代码优化。整个过程如图所示:
2.1词法分析:
array[index] = (index + 5) * (2 + 7);

词法分析产生的记号一般可以分为以下几类:关键字,常数,运算符,标识符。在识别记号的同时,扫描器也完成了其它工作:比如将标识符存放到符号表,将数字和字符串常量存放到文字表等,以备后续步骤使用。
对于C/C++语言,走到词法分析这一步时,宏替换以及文件包含已经在预处理中处理完毕。
2.2语法分析:

在语法分析的同时,很多运算符号的优先级和含义也被确定下来了。比如乘法表达式比加法表达式的优先级高。另外有些符号具有多重含义,比如 * 在C语言中可以表示乘法表达式,也可以表示指针取内容的表达式,所以语法分析阶段必须对这些内容进行区分。如果出现了表达式不合法,比如各种括号不匹配、表达式中缺少操作符等,编译器就会报告语法分析阶段的错误
2.3语义分析:
语义分析是由语义分析器来对表示的语法层面进行的分析,但是它并不了解这个语句是否真正有意义。比如C/C++中对两个指针做乘法运算是没有意义的,但是这个语句在语法上是合法的;比如同样一个指针和浮点数做乘法运算是否合法等。编译器所能分析的语义是静态语义,也就是编译期可以确定地语义,与之对应地动态语义就是只有在运行期才能确定的语义。
静态语义通常包括声明和类型的匹配,类型的转换。比如当一个浮点型的表达式赋值给一个整型的表达式,这其中包含了一个浮点型到整型的准换过程,语义分析就负责完成这个步骤。比如将浮点数赋值给指针时,语义分析会发现这个类型不匹配(整型时可以赋值给指针的),编译器就会报错。
动态语义一般指在运行期出现的语义相关的问题,比如将0作为除数是一个运行期语义错误。
经过语义分析阶段后,整个语法树的表达式都被标上了类型,如果有些类型需要做隐式转换,语义分析程序会在语法树中插入相应的转换节点。上秒描述的语法树在经过语义分析阶段后变化如图所示:
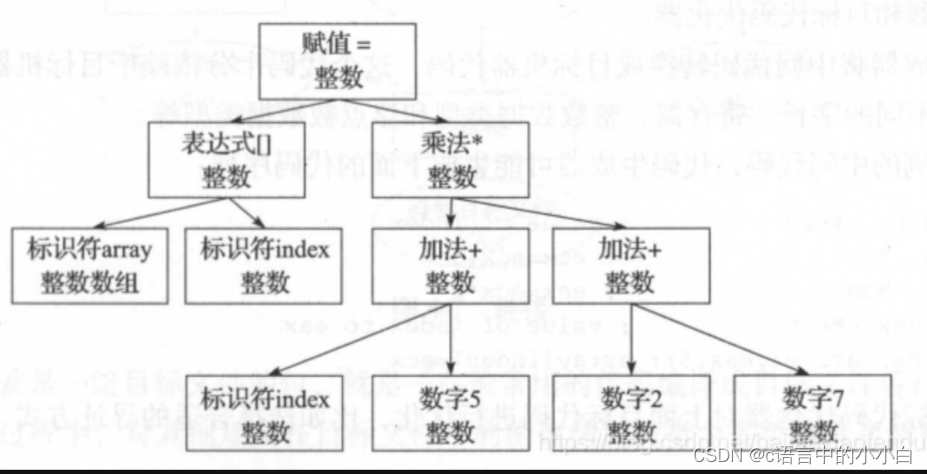
2.4中间语言的生成:
现代的编译器有着很多层次的优化,往往在源代码级别会有一个优化过程。这里所描述的源码级优化器在不同编译器中可能会有不同的定义或者一些其它差异。源代码优化器会在源码级别进行优化,在上例中,我们可以发现,(2+7)这个表达式可以被优化掉,因为它的值在编译期就可以确定,优化后的语法树为:
我们看到(2+7)这个表达式被直接优化成9。由于直接在语法树上进行优化比较困难,因此源代码优化器往往先将整个语法树转换成中间代码,它是语法树的顺序表示,已经非常接近目标代码了。但是中间代码一般跟目标机器和运行时的环境是无关的,比如不包含数据的大小,变量的地址和寄存器的名称等等。中间代码在不同的编译器中有着不同的形式,此处不再详细介绍。
中间代码使得编译器可以被分为前端和后端:前端负责产生机器无关的中间代码,后端负责将中间代码转换成目标机器代码。这样对于一些跨平台的编译器而言,它们可以针对不同的平台使用同一个前端和针对不同机器平台的数个后端。
2.5目标代码的优化:
源代码级优化器产生中间代码标志着下面的过程都是由编译器后端来完成的:代码生成器和目标代码优化器。
代码生成器将中间代码转换为与机器相关的目标机器代码,这个过程依赖于目标机器的结构,因为不同机器的字长,寄存器,整数数据类型,浮点数数据类型都不一样(很简单的例子:32位操作系统和64位操作系统,指针变量所占字节数分别为4字节和8字节)。比如常用的GCC编译器就几乎支持所有的CPU平台,当然这也导致它的指令生成过程更为复杂。
最后目标代码优化器对转换后的目标代码进行优化,比如选择合适的寻址方式,位移来代替乘法运算,删除多余的指令等。
经过了词法分析,语法分析,语义分析,源代码优化,目标代码生成和目标代码优化,编译器经过这么多步骤,终于将源代码编译成目标代码。但是上述目标代码中index和array的地址还没有确定,如果现在把目标代码使用汇编器编译成真正能够在机器上执行的指令,那么index和array的地址是从哪里来的呢,如果它们定义跟上述源码在同一个编译单元内,那么编译器可以为它们分配空间,确定地址,但是如果index和array是定义在其它的程序模块中呢?
事实上,定义其它模块的全局变量和函数在最终运行时的绝对地址都要在最终链接时才能确定。所以现代的编译器可以将一个源代码文件编译成一个未链接的目标文件(比如gcc中通过gcc –c hello.c 会生成hello.o文件),然后由连接器将这些目标文件链接起来形成最终的可执行文件(gcc hello.o)。
三、链接
把每个源代码模块独立地编译,然后按照需要将它们进行“组装”,这个组装地过程就是链接。链接地主要内容就是把各个模块之间相互引用地部分(包括函数和变量)都处理好,使得各个模块之间能够正确地衔接。
从原理上讲,链接地工作无非就是把一些指令对其他符号地址地引用加以修饰,链接主要包括了地址和空间分配,符号决议和重定位这些步骤,
举一个简单的例子:比如我们在模块main.c中使用另一个模块func.c中的函数foo(),我们在main.c模块中每一处调用foo函数的时候都必须确切知道foo的函数地址,但是由于每个模块都是单独编译的,在编译器编译main.c的时候它并不知道foo函数的地址(但是由于编译的预处理阶段,是将头文件全部替换的,因此编译单独编译main模块是没有问题的),所以暂时把这些调用foo的指令的目标地址搁置,等待最后链接的时候由连接器去将这些指令的目标地址进行修正。
Mov1 $0x2a, var
这条指令就是给这个var变量赋值0x2a,由于比在编译目标文件B的时候,编译器并不知道变量var的目标地址,所以在这种情况下,编译器将这条mov指令的目标地址设为0,等待链接器在将目标文件A和B链接起来的时候再将其修正。假设A和B链接后,变量var的地址确定下来为0x100,那么链接起会把这个指令的目标地址修改成0x100。这个地址修正的过程叫做重定位,每个要被修正的地方叫一个重定位入口(在编译过程中报错,找不到函数的入口,那就是因为在链接时找不到该函数的地址)。
四、总结:
本期我们讲了关于计算机程序的编译与链接,希望对大家有所帮助!