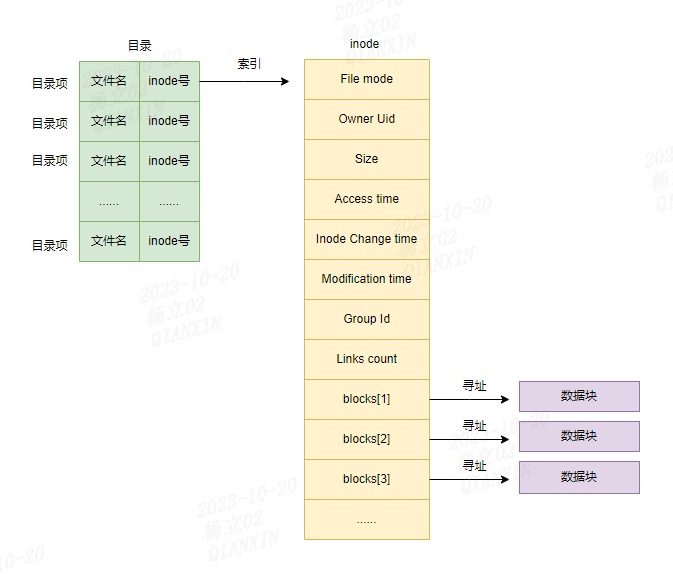
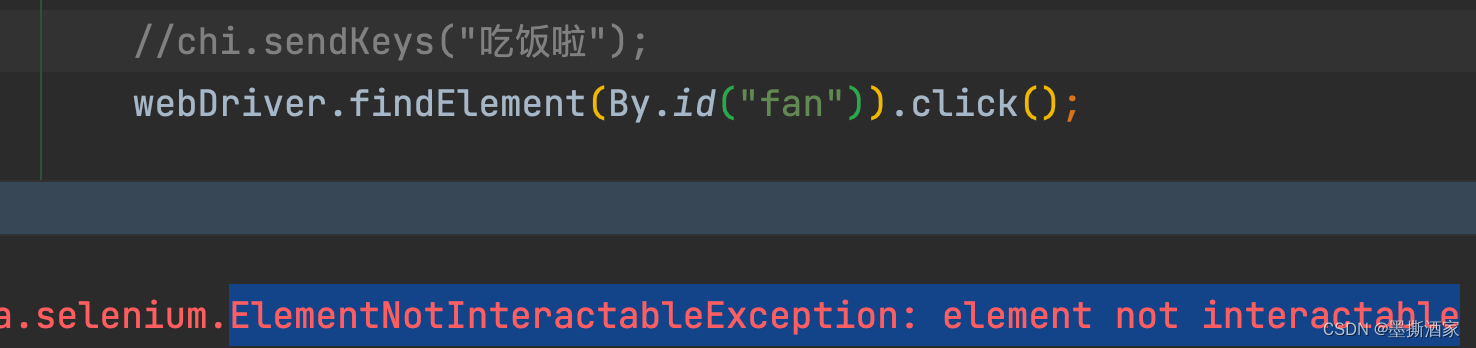
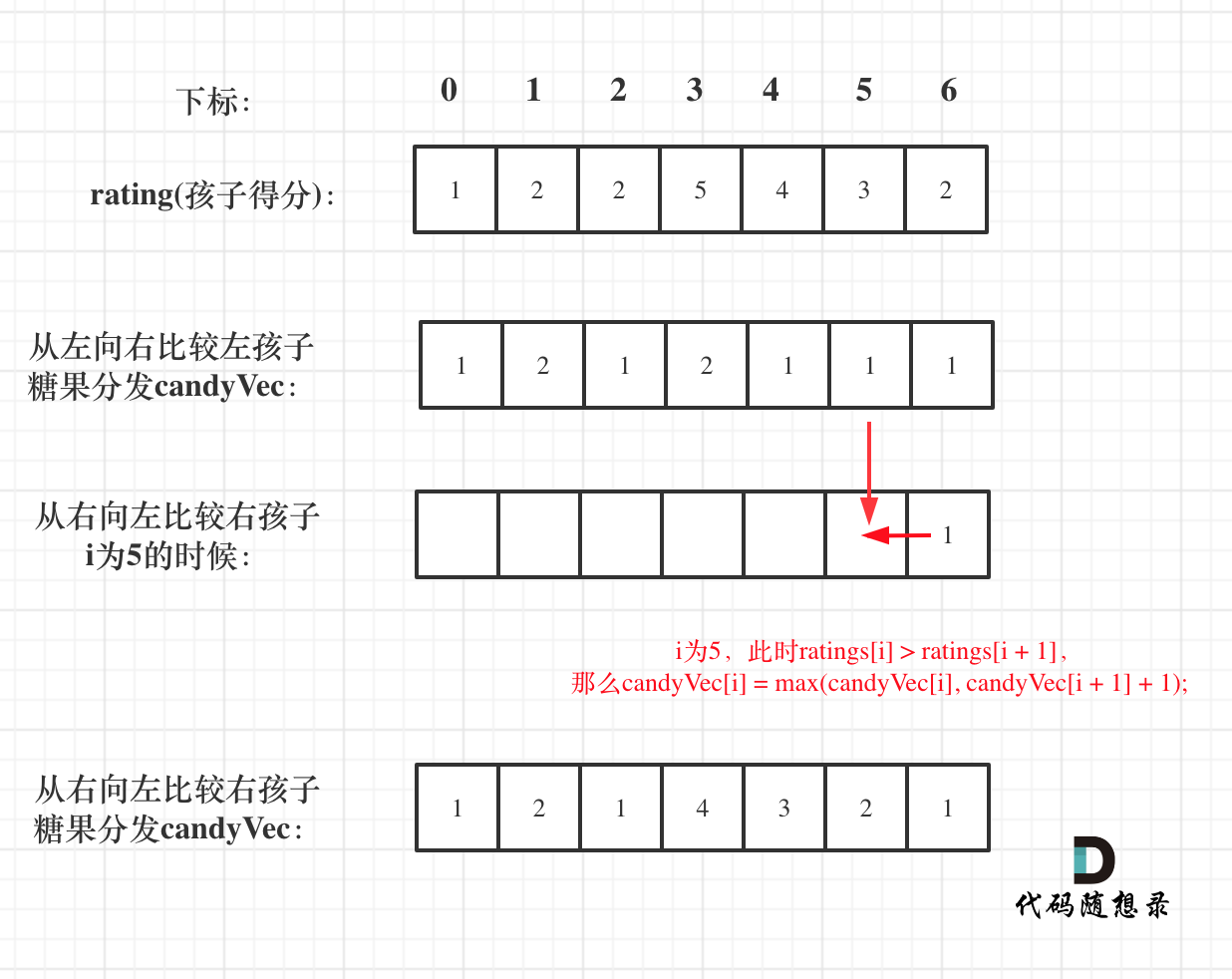
RDB的dirty计数器和lastsave属性
服务器除了维护saveparams数组之外,还维持着一个dirty计数器,以及一个lastsave属性:
- 1.dirty计数器记录距离上一次成功执行SAVE命令或者BGSAVE命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作)
- 2.lastsave属性是一个UNIX时间戳,记录了服务器上一次成功执行SAVE命令或者BGSAVE命令的时间
struct redisServer {
// ...
// 修改计数器
long long dirty;
// 上一次执行保存的时间
time_t lastsave;
// ...
}
当服务器成功执行一个数据库修改命令之后,程序就会对dirty计数器进行更新:命令修改了多少次数据库,dirty计数器的值就增加多少。
例子
- 例如。如果我们为一个字符串键设置值:
127.0.0.1:6379> SET message "hello"
OK
那么程序会将dirty计数器的值增加1。
- 又例如,如果像一个集合键增加三个新元素:
127.0.0.1:6379> SADD database Redis MongoDB MariaDB
(integer) 3
那么程序会将dirty计数器的值增加3。
- 如图所示,该图展示了服务器状态中包含的dirty计数器和lastsave属性,
说明如下:
1.dirty计数器的值为123,表示服务器在上次保存之后对数据库状态共进行了123次修改
2.lastsave属性则记录了服务器上次执行保存的时间1378270800

检查保存条件是否满足
以下伪代码z展示了serverCron函数检查保存条件的过程:
def serverCron():
# ...
# 遍历所有保存条件
for saveparam in servr.saveparams:
# 计算距离上次执行保存操作有多少秒
save_interval = unixtime_now() - server.lastsave
# 如果数据库状态的修改次数超过条件所设置的次数
# 并且距离上次保存的时间超过条件设置的时间
# 那么执行保存操作
if server.dirty >= saveparam.changes and
save_interval > saveparam.seconds:
BGSAVE()
程序会遍历并检查saveparams数组中的所有保存条件,只要有任意一个条件被满足,那么服务器就会执行BGSAVE命令。
例子
- 举个例子,如果Redis服务器的当前状态如图所示.
那么当时间来到1378271101,也即是1378270800的301秒之后,
服务器将自动执行一次BGSAVE命令,因为saveparams数组的第二个保存条件——300秒之内有至少10次修改——已经被满足。
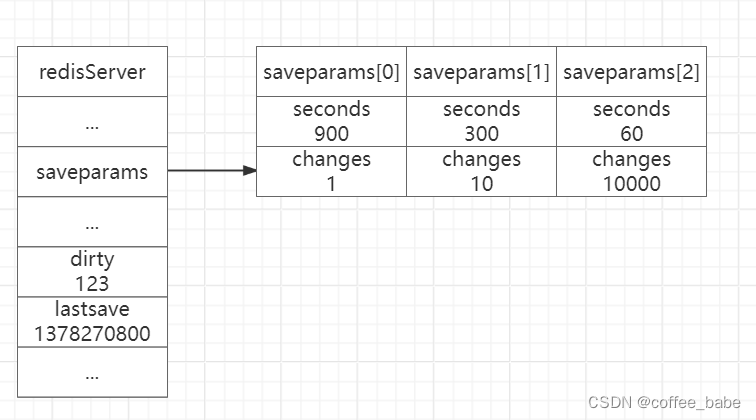
假设BGSAVE在执行5秒之后完成,那么如图所示的服务器状态将更新为如图所示。其中dirty计数器已经被重置为0,而lastsave属性也被更新为1378271106
AOF文件重写的实现
虽然Redis将生成新AOF文件替换旧AOF文件的功能命名为"AOF文件重写",但实际上,AOF文件重写并不需要对现有的AOF文件进行任何读取、分析或者写入操作,这个功能是通过读取服务器当前的数据库状态来实现的。
例子
- 举个例子,如果对服务器对list键执行了以下命令:
127.0.0.1:6379> RPUSH list "A" "B" // ["A", "B"]
(integer) 2
127.0.0.1:6379> RPUSH list "C" // ["A", "B", "C"]
(integer) 3
127.0.0.1:6379> RPUSH list "D" "E" // ["A", "B", "C", "D", "E"]
(integer) 5
127.0.0.1:6379> LPOP list // ["B", "C", "D", "E"]
"A"
127.0.0.1:6379> LPOP list // ["C", "D", "E"]
"B"
127.0.0.1:6379> RPUSH list "F" "G" // ["C", "D", "E", "F", "G"]
(integer) 5
那么服务器为了保存当前list键的状态,必须在AOF文件中写入六条命令。
如果服务器想要用尽量少的命令来记录list键的状态,那么最简单高效的办法不是去读取和分析现有的AOF文件的内容,而是直接从数据库中读取键list的值,然后用一条RPUSH list “C” “D” “E” “F” "G"命令来代替保存在AOF文件中的六条命令这样旧可以将保存list键所需的命令从六条减少为一条了
注意
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序在处理列表、哈希表、集合、有序集合这四种可能会带有多个元素的键时,会先检查键所包含的元素数量,如果元素的数量超过了redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的
值,那么重写程序将使用多条命令来记录键的值,而不单单使用一条命令。REDIS_AOF_REWRITE_ITEMS_PER_CMD常量的值为64,这也就是说,如果一个集合键包含了超过64个元素,那么重写程序会用多条SADD命令来记录这个集合并且每条命令设置的元素数量也为64个:
SADD <set-key> <elem1><elem2>....<elem64>
SADD <set-key> <elem65><elem66>...<elem128>
SADD <set-key> <elem129><elem130>...<elem192>
另一方面如果一个列表键包含了超过64个项,那么重写程序会用多条RPUSH命令来保存这个集合,
并且每条命令设置的项数量也为64个
RPUSH <list-key> <item1><item2>...<item64>
RPUSH <list-key> <item65><item66>...<item128>
RPUSH <list-key> <item129><item130>...<item192>
重写程序使用类似的方法处理包含多个元素的有序集合键,以及包含多个键值对的哈希表键
AOF后台重写
虽然AOF重写程序aof_rewrite函数可以很好地完成创建一个新AOF文件的任务,但是,因为这个函数会进行大量的写入操作,所以调用这个函数的线程将被长时间阻塞,因为Redis服务器使用单个线程来处理命令请求,所以如果由服务器直接调用aof_rewrite函数的话,那么在重写AOF文件期间,服务器将无法处理客户端发来的命令请求。
很明显,作为一种辅佐性的维护手段,Redis不希望AOF重写造成服务器无法处理请求,所以Redis决定将AOF重写程序放到子进程里执行,这样做可以同时达到两个目的:
- 1.子进程进行AOF重写期间,服务器进程(父进程)可以继续处理命令请求
- 2.子进程带有服务器进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全性。
不过,使用子进程也有一个问题需要解决,因为子进程在进行AOF重写期间,服务器进程还需要继续处理命令请求,而新的命令可能会对现有的数据库状态进行修改,从而使得服务器当前的数据库状态和重写后的AOF文件所保存的数据库状态不一致。
数据不一致问题
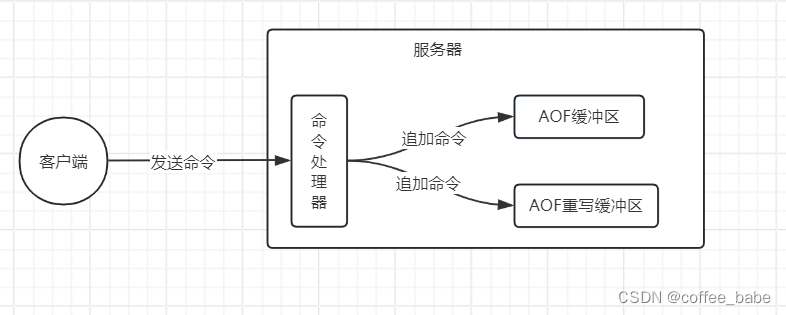
为了解决这种数据不一致问题,Redis服务器设置了一个AOF重写缓冲区,这个缓冲区在服务器创建子进程之后开始使用,当Redis服务器执行完一个写命令之后,它会同时将这个写命令发送给AOF缓冲区和AOF重写缓冲区,如图所示。。这也就是说,在子进程执行AOF重写期间,服务器进程需要执行以下三个工作:
- 1.执行客户端发来的命令
- 2.将执行后的写命令追加到AOF缓冲区
- 3.将执行后的写命令追加到AOF重写缓冲区
这样一来可以保证: - 1.AOF缓冲区的内容会定期被写入和同步到AOF文件,对现有AOF文件的处理工作会如常进行
- 2.从创建子进程开始,服务器执行的所有写命令都会被记录到AOF重写缓冲区里面当子进程完成AOF重写工作之后,它会向父进程发送一个信号,父进程在接到该信号之后,会调用一个信号处理函数,并执行以下共做:
- 1.将AOF重写缓冲区中的所有内容写入到新的AOF文件中,这时新AOF文件所保存的数据库状态将和服务器当前的数据库状态一致
- 2.对新的AOF文件进行改名,原子地(atomic)覆盖现有的AOF文件,完成新旧数据两个AOF文件的替换这个信号处理函数执行完毕之后,父进程就可以继续像往常一样接受命令请求了。
阻塞问题
在整个AOF后台重写过程中,只有信号处理函数执行时会对服务器进程(父进程)造成阻塞,在其他时候AOF后台重写都不会阻塞父进程,这将AOF重写对服务器性能造成的影响降到了最低。
例子
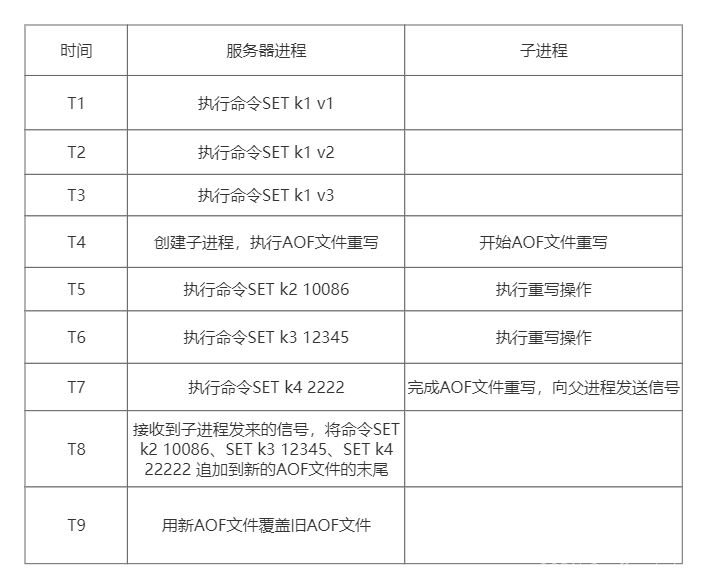
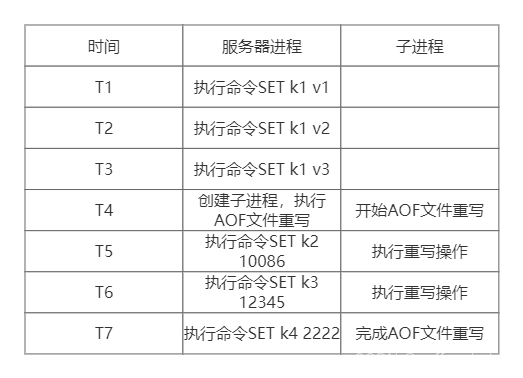
举个例子,图中展示i了一个AOF文件后台重写的执行过程:
- 1.当子进程开始重写时,服务器进程(父进程)的数据库中只有一个k1的键,当子进程完成AOF文件重写之后,服务器进程的数据库中已经多处了k2、k3、k4三个新键
- 2.在子进程向服务器发送信号之后,服务器进程会将保存在AOF重写缓冲区里面记录的k2/k3/k4三个键的命令追加到新AOF文件的末尾,然后用新的AOF文件替换旧文件完成AOF文件后台重写操作