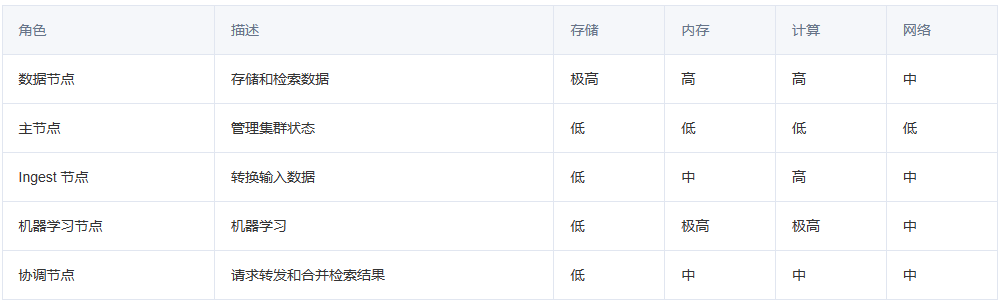
文件fd
- 输出重定向除了用dup2()改变数组下标外,还可以用命令来完成

所有的命令执行,都必须有操作系统将其运行起来变成进程,然后根据>>, <<来判断是输入重定向,还是输出重定向。
缓冲区
- 之所以有缓冲区,是为了提高效率的。就类比快递一样,如果你送一个东西给北京的朋友,那么你自己过去给他,成本太大了,所以有快递之后,你只需要将你要送的东西,给快递,那么之后的事就不用你来管了,快递公司会帮我寄到指定的地点。缓冲区也是如此
- 我们把从缓冲区里的数据拷贝到指定区域,这个过程叫刷新
- 缓冲区的本质就是一块内存区域,作用是来提高效率,其实就是用空间换时间。

- 我们所说的缓冲区其实跟内核中的缓冲区是没有关联的,尽管内核中确实有,我们所说的只是语言层面的缓冲区比如C语言自带的缓冲区
为什么要在语言层面设置一个缓冲区
- 我们要明白,调用系统调用是有成本的,是消耗时间的。所以说在语言层面设置一个缓冲区,可以有效地减少我们调用系统调用的次数。也就是说我们在使用fwrite函数的时候,fwrite并不是直接使用write的系统调用,而是先向语言的缓冲区写入,等缓冲区满后,再调用write,写到系统的缓冲区中。
- 语言层面的缓冲区有三种刷新方式:
-
- 无刷新,无缓冲
-
- 行刷新,比如显示器,
-
- 全刷新,全缓冲。对于普通文件而言,只有把缓冲区写满,才会调用系统调用,写入系统内部。至于从系统缓冲区写入到磁盘的这个过程,则是由操作系统决定的。
- 除了上面的三个默认的刷新方式,还有两种刷新方式,分别是强制刷新和进程退出的时候自动刷新。
缓冲区在C语言的什么位置呢
int main()
{
FILE* fp = fopen("log.txt", 'w');
return 0;
}
-
如上代码所示,在我们每次打开文件的时候,都会用一个FILE*指针来接收,其实FILE是一个结构体,里面集成了缓冲区,还有文件描述符fd
-

-
对于上述代码所呈现出来的现象,是因为当我们向显示器进行打印时,采用的刷新方案是行刷新,意味着在fork()之前,C语言缓冲区的内容就已经被刷新到系统缓冲区中了,所以无论是使用系统调用还是C语言的函数,都只是把C语言缓冲区刷新一次到系统缓冲区中。但是向文件进行打印时,采用的刷新方式是全缓冲,也就是在fork()之前的C语言函数调用,实现的都只是向C语言的缓冲区进行打印,在fork()之后又创建了一个子进程,与父进程的状态是一样的,缓冲区中依旧有由于C语言函数调用而存在的数据,当进程结束时,两个相同内容的缓冲区都会由于进程的关闭而进行自动刷新,也就会向系统缓冲区中刷新两次。
int main()
{
int a = 100;
printf("%d", a);
scanf("%d", &a);
return 0;
}
- 缓冲区除了提高效率的作用,还起到格式化的作用,如上代码所示,当我们使用printf()函数时,将变量a打印到显示器上,但是显示器是字符设备,所以是把整形变量变成字符形式,送到缓冲区上,然后再打印到显示器上。当我们使用scanf()函数时,从键盘读取数据到变量a中,但是a是整形,所以先从键盘读取数据到缓冲区,然后在scanf()函数内部变成整形,再传给变量a。